Spark SQL: Relational Data Processing in Spark
Posted fansy1990
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark SQL: Relational Data Processing in Spark相关的知识,希望对你有一定的参考价值。
Spark SQL: Relational Data Processing in Spark
Spark SQL : Spark中关系型处理模块
说明: 类似这样的说明并非是原作者的内容翻译,而是本篇翻译作者的理解(可以理解为批准),所以难免有误,特注!
当然翻译也可能有误!
| Date | Contents |
|---|---|
| 2019.03.12 | First Edition |
| 2019.04.07 | Second Edition, 修改部分错误及添加批注 |
文章目录
- Spark SQL: Relational Data Processing in Spark
- Spark SQL : Spark中关系型处理模块
- Abstract(摘要)
- Keywords(关键词)
- 1 Introduction (简介)
- Background and Goals(背景和目标)
- 3 Programming Interface(编程接口)
- 4. Catalyst Optimizer(Catalyst 优化器)
- 5 Advanced Analytics Features(高级分析特性)
- 6 Evaluation(评估)
- 6.3 Pipeline Performance(管道性能)
- 7 Research Applications(研究型应用)
- 8 Related Work(相关研究)
- 9 Conclusion(总结)
- 10 Acknowldegments(致谢)
- 11 References(参考)
Abstract(摘要)
Spark SQL是Apache Spark中的一个新模块,其在Spark的函数式编程API中引入了关系型处理能力。
函数式编程 : 是种编程典范,它将电脑运算视为函数的计算。函数编程语言最重要的基础是λ演算(lambda calculus)。而且λ演算的函数可以接受函数当作输入(引数)和输出(传出值)。
简单说, 函数式编程就是函数也和值一样可以当做返回值,以及输入参数值。
关系型处理: 比如使用SQL来解决某个问题,如数据查询、统计分析等
基于在Shark上的经验,开发出了Spark SQL,而这个工具就可以使得使用Spark的开发者在可以进行关系型处理的同时(如声明式的查询,存储优化),也能调用Spark中原有的复杂的分析库(如机器学习相关算法等)。
Shark : 请查询 Hive ,Hive On Spark ,Shark的爱恨纠缠。
声明式查询:
存储优化:
和之前的系统对比,Spark SQL添加了两个主要功能:第一,通过声明式的DataFrame API使得在之前的过程型处理代码中(也就是Spark RDD API)可以很容易的加入关系型处理过程;
Spark RDD 可以理解为过程型处理的API
第二,新增了一个高度可扩展的优化器,Catalyst(此优化器通过使用Scala编程实现,并利用scala特有的特性),使用此优化器,可以很容易的添加可组合的(可以理解为可定制)规则、控制代码生成过程、定义扩展点(extension points?拓展点?)。利用Catalyst,针对现代的复杂数据分析,定制开发了很多特性(如 JSON元数据自动获取、机器学习函数调用、外部数据库联邦查询(federation?))。
machine learning types:
query federation to external databases:
我们把Spark SQL看做是一个SQL-on-Spark 以及 Spark世界的一个变革,因为Spark SQL在保持Spark编程模型优势的同时,还提供了更丰富的API以及优化机制。
Keywords(关键词)
Databases;Data Warehouse; Machine Learning; Spark;Hadoop
1 Introduction (简介)
大数据系统是一个集处理技术、数据源及存储格式技术的混合应用系统。早期类似的系统,如MapReduce(提供了一个强大但是低阶的过程化处理接口)。直接使用这种系统进行编程,一般比较复杂,而且为了得到更高的系统性能,需要用户手动进行优化。所以,很多新的系统更加倾向于提供一个更高效、用户易用的编程接口,而这种接口通常提供针对大数据处理的关系型的接口。诸如Pig,Hive,Dremel和Shark就是这样的系统,通过声明式的查询来提供更多自动化的优化。
虽然关系型系统的活跃度展示了用户更加倾向于编写声明式的查询,但是这种关系型的系统一般针对大数据应用提供的可用的操作是比较少的,同时还存在下面的问题。
- 第一,用户需要执行ETL作业,而这些作业需要多种数据源的支持(支持读取以及写入),同时这些数据源的数据可能是半结构化或非结构化的数据。这时,这些系统(指的就是上面的如Pig,Hive,Shark等系统)就需要用户自己编写额外代码。
- 第二,用户需要进行更多高级的分析。例如机器学习或图处理,但是这中操作在关系型系统中是一个非常大的挑战。事实上,我们观察到很多数据操作都会用到关系型查询及过程化处理算法。不幸的是,对于关系型和过程型这两种系统直到现在还没有一个系统可以同时具有这两种优势,这就使得用户只能选择其中的一个或另一个。
这篇论文主要介绍了我们在Spark中引入的一个新模型,Spark SQL。Spark SQL基于早前的Shark设计。而Spark SQL就可以让用户直接使用关系型和过程型处理的API,而不用二选一。
Spark SQL通过提供两个特性来缩小关系型和过程型系统之间的差距。
- 第一,Spark SQL提供一个可以处理外部数据源及Spark内置的分布式数据结构(也就是RDD)的API,叫做DataFrame。这个API和R中的data frame概念比较类似,但是当进行action操作的时候是一种懒操作(部分代码不是立即执行,而是在执行某些操作的时候才执行,可以和Pig对比),基于这种“懒操作”,Spark 引擎就可以进行关系型优化。
- 第二,为了支持大数据系统中的多种数据源及算法库的调用,Spark SQL引入了一个设计精妙的、可扩展的优化器,叫做Catalyst。Catalyst使得添加数据源、优化规则、域数据类型(如机器学习中的数据类型)更加容易。
optimization rules: 规则优化,即可以自定义优化规则;
data types for domains : 机器学习中的数据类型
DataFrame API同时提供丰富的关系型或过程型操作。它是一个结构化记录的集合,可以使用Spark的过程化API或关系型API(此种API支持多种优化)来对其进行操作。
DataFrame可以从Spark RDD转换得到,所以可以整合到现有的Spark代码中。其他的Spark组件,如机器学习库,也可以使用DataFrame作为输入或作为输出。在很多常见的情况下,DataFrame API 会比Spark 过程型API(也就是RDD API)能取得更高的性能,同时也更加易于操作。举例来说,在DataFrame中,可以使用一个SQL来完成多个聚合操作,但是如果使用函数式API(RDD API),那么就会很复杂。同时,DataFrame存储数据时,会直接使用Columnar format(列式格式),这种格式比直接使用Java/Python 类存储数据更加紧凑(也即是占用空间更小)。最后,和R或Python中的 data frame API不同的是,在Spark SQL中 DataFrame会使用一个关系型优化器来作为其处理引擎进行处理,即Catalyst(而Catalyst也是本文的重点)。
Columnar format: 列式存储;
为了在Spark SQL中支持多种数据源和分析型的作业流程,我们设计了一个拓展的查询优化器,Catalyst。Catalyst充分利用Scala语言中的特性,比如使用模式识别来实现可组合的规则(Turing-complete language:图灵完整性语言?)。
Turing-complete language: What is Turing Complete?
It(指代“模式识别”?)提供了一个树转换框架,这个框架可以执行分析、计划、运行时代码生成工作。通过这个框架,Catalyst就可以获得如下的增强:
- 添加新的数据源,包括半结构化数据(如:JSON),和“smart”数据存储。(例如HBASE)
什么叫“smart” data store ? 聪明的数据存储,从后文来看,指的应该是数据在存储之前会应用过滤,这样其数据就会比较小。
- 用户自定义函数;
- 以及用户自定义的域类型,如机器学习。
函数式编程语言非常适合用来构建编译器,所以使用Scala来编写一个可拓展的优化器也就没有什么好奇怪的了。我们确实发现Catalyst能使我们更加高效、快速的在Spark SQL中增加功能,在Spark SQL 发布后,外部的开发者也可以很容易的添加一些功能,所以说Catalyst是更易用的。
在2014年3月发行了Spark SQL,现在它是Spark中最活跃的模块之一。在写这篇paper的时候,Spark是大数据中最活跃的开源项目,超过400个开发者。Spark SQL已经被应用在很多大数量级的场景中。举例来说,一个大型的互联网公司使用Spark SQL建立了一个数据处理流,可以在一个8000节点的机器上处理、分析100PB的数据。每个单独的查询,一般都会操作数十TB的数据。另外,很多用户已经开始接受Spark SQL不单单是一个SQL查询引擎,而一个整合了过程型处理的编程模型的观念。例如,Databricks Cloud的2/3的用户,其托管的服务中运行Spark任务的都是使用Spark SQL。从效率方面看,我们发现Spark SQL在Hadoop的关系型产品中是很有竞争力的。对比传统RDD 代码,它可以取得10倍性能及更好的内存效率优势。
更一般的,Spark SQL可以看做是Spark 核心(Core) API的一次重要变革。Spark 原始的函数式编程API确实太一般(general)了,
quite general : 这里说的应该是其没有提供很多标准化的操作,进而导致其能进行自动优化的方面较少。
在自动优化方面只提供了很有限的机会。Spark SQL不仅使得Spark对用户来说更易用,而且对已有的代码也可以进行优化。目前,Spark社区针对Spark SQL添加了更多API操作,如把DataFrame作为新的“ML pipeline”机器学习的标准数据表示格式,我们希望可以把这种表示扩展到Spark的其他组件,如Spark GraphX、Spark Streaming中。
此篇文章,按以下顺序进行:
- 开篇我们介绍了Spark背景以及Spark SQL要实现的目标(第二节$2)。
- 接着,介绍了DataFrame API(第三节,$3),Catalyst 优化器(第四节,$4)以及在Catalyst之上构建的高级特性(第五节,$5)。
- 在第六节对Spark SQL进行评估。
- 在第7节针对在Catalyst的一些外部研究。最后,在第八节,cover 相关工作。
Background and Goals(背景和目标)
2.1 Spark Overview(Spark概述)
Apache Spark 是一个通用的集群计算引擎,可以使用Scala,Python,Java API进行操作(当然,现在也有R的API了),其包含流处理、图处理、机器学习等模块。在2010年发布后,很快就被广泛使用(这种多种语言集成的特性和DryadLINQ类似),
DryadLINQ:Dryad和DryadLINQ是微软研究院的两个项目,用于辅助 C# 开发人员在在计算机集群或数据中心里处理大规模的数据。 百度百科
并且是最活跃的大数据开源项目。在2014年,Spark已经拥有400位开发者,并且很多发行商在其上发布了很多版本。
Spark提供了一个函数式编程API,可以操作分布式数据集(RDDs)。每个RDD是一个在集群中被分区的Java或Python的object的集合。可以使用map、filter、reduce来操作RDD,这些函数的参数也是函数,通过这些函数(map。。。)可以把数据进行转换后发往集群的各个节点。比如,下面的Scala代码主要统计text文件中包含“ERROR”的个数。
lines = spark.textFile("hdfs://...")
errors = lines.filter(s => s.contains("ERROR"))
println("errors.count()")
上面这段代码通过读取一个HDFS文件,生成一个string类型的RDD,变量名为liens。接着,使用filter进行转换,得到一个新的RDD,叫做errors。最后,执行一个count操作,进行计数统计。
RDDs是具有容错性的,在系统中丢失的数据可以根据RDD的血缘图来进行恢复(在上面的代码中,如果有数据丢失,可以利用血缘图重新其丢失分区的父节点(如运行filter),来重建丢失的分区数据)。当然RDD也可以显式的缓存到内存或硬盘上,以此来支持循环操作,提升效率。
最后一个关于API的点是RDD执行时是lazy的(根据代码先构建一个有向无环图,然后当有执行代码时,才执行代码,类比Pig操作)。
Spark的API主要分为两大类:Transformation & Action, Transformation主要是对一个RDD进行转换操作,得到的仍然是RDD(分布式数据集),而Action会对一个RDD进行操作,但是得到的是一般数据结构(如Python 数据类型或Scala数据类型)
每个RDD代表一个计算数据集的“logical plan(逻辑计划)”,直到一个明确的输出时,Spark才执行代码,比如count操作。
count操作执行后,返回的就是一个Scala的Int类型的数据。
使用逻辑计划这样的设计方案使得Spark引擎可以做一些执行优化,例如pipeline(管道式操作、流水线式操作)操作的时候。例如,在上面的例子中,Spark会在读取HDFS文件的每行记录时,直接应用filter函数,然后进行计数,这样操作的话,避免了存储中间的结果,如lines或errors。虽然类似的优化很有用,但是这种优化也是有限的,因为Spark引擎并不知道RDD数据中的结构。
Spark不知道数据结构:指的是任意的Java或Python类,类的结构,如字段,Spark引擎是不知道的。
以及用户函数的语义。
如,用户自定义函数,会引入任意的代码,而这些代码,Spark是不知道其代表什么意义,所以也就无从优化。如果能让Spark知道这些代码执行的逻辑,比如说执行了一个filter/where操作,那么它就可以优化,所以Spark SQL里面就是把这些代码直接用一个filter的操作进行封装,用户调用的时候直接调用filter,那么Spark引擎就会知道用户执行的是一个filter操作,而不是用户自定义一个函数。
2.2 Previous Relational Systems on Spark(早期Spark上关系型系统)
我们第一次尝试在Spark上建立的关系型接口是Shark,
Shark: Shark官网,目前已经是这个样子了:
Shark has been subsumed by Spark SQL, a new module in Apache Spark. Please see the following blog post for more information: Shark, Spark SQL, Hive on Spark, and the future of SQL on Spark.
上面总结一句话,就是:Shark不再维护了,你们都去使用Spark SQL吧。
这个系统可以使得Apache Hive能够运行在Spark之上(也就是在Spark上的关系型处理接口),同时实现了一些传统RDBMS的优化,比如列式处理
列式存储:(Columnar Database By definition, a columnar database stores data by columns rather than by rows, which makes it suitable for analytical query processing, and thus for data warehouses.)
尽管Shark使得Spark在关系型处理上拥有更高的性能,但是却有三个不可回避的问题。
- 第一,Shark只能处理存储在Hive Catalog里面的数据,对于Spark程序中已经存在的数据并没有帮助(比如,在上面代码中的 errors RDD上建立关系型查询等)。
- 第二,如果使用Spark来调用Shark,那么只能通过一个SQL字符串,这对于模块化的代码是非常不方便(模块化),而且容易出错的。
- 第三,Hive优化器是为MapReduce量身定做的,很难去拓展以及添加新的特性,比如机器学习中需要用到的特殊数据类型或支持新的数据源。
2.3 Goals for Spark SQL(Spark SQL 要完成的目标)
基于Shark的经验,我们想拓展关系型处理过程,使其可以既可以处理原生RDD,同时可以支持更多的数据源。所以,针对Spark SQL,设置了如下目标;
- 提供一个更易于编程的API,同时支持原生RDD、关系型处理、及外部数据源;
- 使用现有的DBMS的技术,来提供更高的效率支持;
- 可以容易可以添加新的数据源支持,包括半结构化数据或外部数据库,适合用来做查询联邦;
query federation:查询联邦,指的是查询统一接口,如底层有多个查询,然后前端只有一个输入接口,可以查看这个解释
- 添加高级分析算法的支持,如图处理或机器学习算;
3 Programming Interface(编程接口)
在图1中可以看到,Spark SQL基于Spark,是Spark之上的一个模块。Spark SQL暴露了一个SQL接口,所以可以使用JDBC/ODBC、命令行终端或 DataFrame API (整合了 Spark支持的所有编程语言的编程接口) 来进行操作。接下来将会首先介绍DataFrame API(可以使用户同时使用过程和关系型编程代码)。同时,高级的函数也可以通过UDFs在SQL中实现,关于UDF的部分将在3.7节展开。

3.1 DataFrame API(DataFrame应用编程接口)
在 Spark SQL中使用最主要的抽象封装是: DataFrame:一个分布式的拥有元数据的数据结构。
可以理解为列名和列类型,就像数据库中的元数据信息一样的行数据集合。
一个 DataFrame和传统关系型数据库中的表等价,而且还可以像原生的分布式数据集(指RDD)一样被操作。
即 RDD API和 DataFrame是比较相似的
但是和RDD不一样的是,DataFrame会跟踪模式(Schema)的处理过程,同时支持很多能被优化的关系型操作。
DataFrame可以通过外部表(或外部数据源)创建,或从已存在的RDD(一个Java或Python的类的RDD)中创建(参见3.5节)。一旦被创建好,就可以执行很多关系型操作,如where,groupBy等,这些操作接受表达式(expressions)作为参数,这种操作和R以及Python的data frame类似。
表达式(expressions):这种表达式是一种DSL(Domain-specific language),领域特定语言:针对某一领域,具有受限表达性的一种计算机程序设计语言。DSL编程也叫声明式编程。
DataFrame也可以被看做由Row类型的RDD组成,这样就可以在其上执行类似过程型处理API了,如map操作。
最后,和传统data frame的API不同的是,Spark的DataFrame是“懒”的(lazy),这里的“懒”指的是每个DataFrame 代表一个计算某个数据集的逻辑计划,只有明确调用“输出操作”才会发生实际的计算,如save(保存)操作。这个特性使得Spark可以对DataFrame上的操作进行更多的优化。
怎么理解更多的优化,例如现在要执行一个映射,把dataframe中的某一数值列全部映射为其2倍,接着,过滤这些值,当其值对3求余为1的数字才保留,最后统计符合条件的数据个数。
针对上面的问题,一般的处理的过程就是先遍历第一遍,求得映射值,然后再针对映射值,遍历第二遍,再求得符合条件的数据,最后,遍历第三遍得到个数。
而如果使用DataFrame,那么由于在执行count的时候才会触发执行,然后根据最后的count的DataFrame的逻辑计划,可以知道map和filter,以及count都可以进行整合。所以在执行的时候,就会遍历一次数据集,同时进行映射、过滤及统计。而这就是所谓的更多的优化!
为了说明这种问题(指的就是上面更多的优化),下面通过代码实例来分析。下面的Scala代码中定义了一个从Hive中读取得到的DataFrame:users,并且在这个users DataFrame基础上应用where计算得到另一个young DataFrame,最后打印结果。
ctx = new HiveContext()
users = ctx.table("users")
young = users.where(users("age") < 21)
println(young.count())
在上面代码中,变量users、young都是一个DataFrame,而代码片段
users(“age”) < 21
就是一个 expression(表达式,DSL),这种表达式被被用一个抽象语法树来实现,而不是像传统Spark RDD API中使用Scala函数来实现。
这么做的好处是啥
(根据抽象语法树(AST)Spark就知道代码实际执行的是啥,而如果是一个Scala函数,Spark是没办法知道的)。
简单理解:如果使用if else来表达一个规则,并且规则中的处理逻辑写死,那么当知道if的条件时,总是可以确定执行的逻辑(抽象语法树其实简单理解就是if else);而如果现在要执行一个用户传过来的函数,那么你就不知道用户函数里面写的是啥了。
总的来说,每个DataFrame就是一个逻辑计划。当用户调用count函数时(一个输出操作),这时Spark就会根据逻辑计划来构建一个物理计划,进而计算最终结果。在这个过程中,可能会包含一些优化。例如,当数据源是一个列式存储系统时,那么在进行filter过滤时,就只需要读取age列(而不需要读取其他列,效率高),同时,在进行count时,可能只用到了索引来进行计数,而完全没有读取实际的数据。
下面,将对DataFrame进行详细介绍。
3.2 Data Model(数据模型)
Spark SQL为DataFrame选用一个基于Hive的嵌套的数据模型。其支持所有主流的SQL数据类型,如boolean,interger,double,decimal,string,data,timestamp以及复杂数据类型(非原子类型):structs(结构类型),arrays(数组),maps(键值对),unions(联合类型)。复杂类型也可以进行嵌套以实现更加有用的类型。
原子类型: 例如上面的boolean、integer等,非原子类型其实就是原子类型的组合。
和很多传统DBMSes(数据库管理系统)不同,Spark SQL为查询语言和API中的复杂数据类型提供一流的支持。同时,Spark SQL也支持用户自定义类型(在4.4.2节将会介绍)。
使用这种框架,我们可以对很多数据源或不同格式数据进行非常精确的数据定义.
(model data,model这里应该是动词)
这些数据源或格式包括Hive,传统数据库,JSON,原生Java、Scala、Python类。
3.3 DataFrame Operations(DataFrame常用操作)
用户可以在DataFrame上使用DSL(领域特定语言,参考上面)进行一系列关系型操作,就像R中的data frames以及Python中的Pandas一样。DataFrame支持常见的关系型操作,包括projection
Projection:(是一种操作,直译为投影,可以理解为一种数据展现,比如这种操作的一个select,其实就是查询,查询就会有结果,而这个结果就是原始数据的“投影”,可以这样理解)
filter(过滤操作,如where操作),join和aggregations(聚合操作,如groupBy)。这些操作都使用表达式(expression),由于这些表达式都是由有限的DSL组成的,所以Spark可以知道每个表达式的结构。例如,下面的代码计算每个department中female employee(女雇员)的个数。
employees
.join(dept, emplyees("deptId") === dept("id"))
.where(employees("gender") === "female")
.groupBy(dept("id"), dept("name"))
.agg(count("name"))
在这段代码中,employees是一个DataFrame,employees(“deptId”)是一个代表deptId列的表达式。基于表达式(Expression)可以进行很多操作,然后返回的仍然是表达式。例如,包含常见的比较操作(如 === 代表相等测试,> 代表大于)和算数操作(如+,-)。表达式也支持聚合操作,如count(“name”)。所有这些操作建立了一个表达式的抽象语法树(AST,Abastrct Syntax Tree),而AST接下来就会被Catalyst进行优化。这就和传统Spark API使用任意的Java,Scala,Python代码的函数进行传递不一样,因为函数传递会导致这些函数里面的具体操作对于Spark执行引擎来说是不透明的,所以也就说不上什么优化了。如果想查看上面代码中具体API,可以查看Spark官网。
除了关系型的DSL之外,DataFrame也可以被注册成为一个临时表,进而,就可以使用SQL来进行查询。下面的代码就是一个示例:
users.where(users("age") < 21)
.registerTempTable("young")
ctx.sql("select count(*) , avg("age") from young")
这种SQL注册表的方式,在某些场合(如聚合操作中)可以很方便的进行操作,且表意清晰,同时可以使得程序通过JDBC/ODBC来访问数据。通过在catalog中注册临时表的DataFrame,仍然是非固化的视图,所以在后续的SQL以及原始DataFrame 表达式中仍然有优化的空间。
unmaterialized views : 暂译为非固化视图。简单理解,虽然DataFrame可以注册成一个临时表,但是这个表就是一个简单的视图,比如要进行计算的时候,还是会从一开始进行计算。例如,要查看这个临时表的前两行,那么会先计算DataFrame,然后在取出前两行。而如果是固化的视图(固化的应该叫表),那么直接取出前两行即可,不需要进行计算。
但是,DataFrame也可以被固化,将在3.6节讨论。
3.4 DataFrames versus Relational Query Languages(DataFrame和关系型查询语言)
虽然,在表面上来看,DataFrame和如SQL或Pig一样提供关系型查询语言的操作,但是由于Spark SQL可以整合入多种编程语言中,所以对于用户来说,Spark SQL会非常易于使用。例如,用户可以把代码分解成Scala,Java,或Python的函数,并把DataFrame传到这些函数中,以此来建立一个逻辑计划,同时仍然可以在整个逻辑计划中享有Spark的优化(当执行输出操作时就会进行优化)。类似的,开发者可以使用控制结构,像 if 语句 或 循环语句 来构建任务。 一个用户提到DataFrame的API是非常简明的,它的声明式特性就和SQL一样,但是DataFrame可以对中间结果进行命名,体现出构建计算以及进行调试的便捷性。
为了简化在DataFrame中的编程,DataFrame会在API中提前分析逻辑计划(比如识别expression(表达式)中的列名是否在给定的表中,或给定的列数据类型是否是正确的(可以理解为是否和数据库中是匹配的)),但是其执行仍然是lasy的。所以,Spark SQL 会在用户输入一行非法的代码的时候就报错,而不是等到执行的时候。这种处理对于用户来说,同样是一个减负的操作(好过处理一下子处理一个大的SQL,此处的做法就是把大SQL进行分解)。
3.5 Querying Native Datasets(查询原生数据集)
真实业务流程经常从很多异构的数据源中抽取数据,接着使用很多不同的分析工具或算法来对数据进行分析。为了能够和过程型Spark代码互通(就是Spark RDD API),Spark SQL允许用户可以直接从RDD来构造DataFrame。Spark SQL 可以通过反射自动得到元数据(Schema)信息
Schema : 元数据信息,如、列信息、列名,列类型等)。
在Scala或Java中,数据类型信息通过JavaBeans或Scala的Case class获取。在Python中,Spark SQL 对数据集进行抽样,然后动态的去匹配,进而获取元数据信息
动态获取,就是先看能否转换为double,然后看能否转换为int,最后才是string,基本就是这种思想。
举例来说,在下面的Scala代码中定义了一个DataFrame(从RDD[User]转换而来)。Spark SQL 自动的识别了列名(如“name”和“age”)以及其对应的数据类型(string,int)。
case class User(name:String, age:Int)
// create an RDD of User objects
usersRDD = spark.parallelize(List(User("Alice",22),User("Bob",19)))
// view the RDD as a DataFrame
usersDF = usersRDD.toDF
在底层实现上,Spark SQL会创建一个指向RDD的逻辑数据扫描操作。这个操作会被编译成一个可以接触原始对象的字段(原始对象就是指的User类)的物理操作。需要注意的是,这种操作和传统的ORM(类关系映射)是非常不一样的。ORM系统一般在把整个类转换成不同的格式的时候会引起很大的转换消耗。但是,Spark SQL却可以直接就地操作字段,所以可以根据每个查询需要的字段来进行提取。
查询原生数据集的特性(直接访问类的字段)使得用户可以在现有的Spark代码中执行关系型操作的优化。
说白了,就是在原RDD的代码中引入Spark SQL的优化机制。
同时,如果用户想把RDD和一个外部的结构化数据源进行合并,那也会非常简单。例如,可以把users RDD(上一个代码)和Hive中的一个表合并:
views = cxt.table("pageviews")
usersDF.join(views,usersDF("name") === views("user"))
3.6 In-Memory Caching(缓存)
就像之前的Shark一样,Spark SQL也可以使用列式存储在内存中缓存热数据.
hot data,经常使用的数据一般称为热数据)。
和Spark原生的缓存机制
原生缓存指的是使用RDD API进行缓存,直接把数据作为JVM类存储。
不同的是,使用列式存储系统进行缓存可以减少一个量级的内存占用空间,因为Spark SQL应用柱状压缩方案(columnar compression schemes),比如字典编码及行程编码(run-length encoding:行程编码(Run Length Encoding,RLE), 又称游程编码、行程长度编码、变动长度编码 等,是一种统计编码。主要技术是检测重复的比特或字符序列,并用它们的出现次数取而代之。)缓存技术对于迭代查询,特别是对于机器学习中的迭代算法非常有用。在DataFrame中,可以直接调用cache()函数来进行缓存。
关于缓存的实现方案,有兴趣的可以深入了解下,这里只是简单翻译,并没有拓展。
3.7 User-Defined Functions(用户自定义函数)
用户自定义函数(UDFs)是对数据库系统的一个很重要的拓展。比如,mysql中使用UDFs来提供对JSON数据的支持。一个更高阶的例子是MADlib的UDFs的使用,它可以在Postgres 或其他数据库中实现学习算法。但是,数据库系统一般需要使用不同的编程环境(比如Postgres里面使用Java来开发UDF,而本身使用的是Postgres的环境,也就是不能直接使用Postgres SQL的环境来实现UDFs)来实现这些UDFs。Spark SQL中的DataFrame API却可以不需要额外的编程环境,就可以直接实现UDFs,同时还不用复杂的打包、注册操作过程。这也是该API的一个重要的特性。
在Spark SQL中,UDFs可以通过Scala,Java或Python函数来注册生成,稍后,这些函数会在Spark底层转换为对应的Spark API来实现。例如,给定一个机器学习模型中的model的变量,可以把其预测函数重新注册成一个UDF:
val model: LogisticRegressionModel = ...
ctx.udf.register("predict",(x:Float,y:Float) => model.predict(Vector(x,y)))
ctx.sql("SELECT predict(age,weight) FROM users")
UDFs被注册后,就可以通过JDBC/ODBC来给其他商业智能工具调用。UDFs除了可以处理标量数据外,也可以处理整个表(通过提供表名即可,就像在MADLib中的一样),同时,也可以使用分布式的Spark API,其实就是Spark Core API,所以也就可以为SQL用户提供更多高级的分析函数。最后,UDF函数定义和查询引擎都是使用通用的语言(如Scala或Python)来编写的,所以用户可以使用标准工具来进行debug(调试,如使用IntelliJ IDEA或Eclipse、PyCharm工具来调试等)。
上面的例子说明了一个在流程化处理中的通用例子。例如,如果需要用到关系运算或高级分析函数处理的场景,那么在SQL中来实现是很复杂的。但是,DataFrame API可以无缝的整合这些函数。
4. Catalyst Optimizer(Catalyst 优化器)
为了实现Spark SQL,我们基于函数式编程语言Scala设计了一个新的增强优化器,Catalyst。Catalyst的增强设计有两个目的。第一个,我们希望能在Spark SQL中很容易的添加新的优化技术及特性,特别是解决多种大数据问题(比如,半结构化数据和高级分析主题)。第二,我们想让外部开发者帮我们扩展优化器
一时没有想到好的翻译
(
for example, by adding data source specific rules that can push filtering or aggregation into external storage systems, or support for new data types.)
Catalyst 不仅支持基于规则的优化,也支持基于成本(运行耗时等)的优化。
虽然之前已经引入过可拓展的优化器,但是需要复杂的特定领域语言(domain specific language)来表达规则。同时,需要一个“优化器编译器”来把规则转换为可执行代码。这造成了很大的学习曲线和维护负担。
(也就是别人修改或维护比较难)。
相对的,Catalyst使用Scala标准的语言特性来开发,如pattern-matching(模式匹配)。这样,开发者不管是构建规则或者编写Spark代码,都可以只使用Scala语言来完成。
即不需要引入额外的语言,如 DSL。
函数式编程语言天生就适合用来构建编译器,所以Scala也就很适合用来构建Catalyst。尽管如此,在我们看来,Catalyst仍然是第一个质量很高并且使用Scala这种函数式编程语言实现的查询优化器。
Catalyst的核心包含一个用来表示抽象语法树以及应用规则来操作AST的通用库。在这样的框架基础上,我们创建了很多特定的库用来处理:
-
关系型查询操作(如,表达式,逻辑查询计划等);
-
一些可以处理查询执行的不同阶段的规则,查询执行的阶段有:分析,逻辑优化,物理计划;
-
代码生成(会编译部分查询,并生成Java二进制代码)。
关于代码生成,我们使用了Scala另外的一个特性,quasiquotes。
quasiquotes: quasiquotes官网解释
TODO : 举个例子
它可以使得程序在运行时生成代码很简单(通过组合表达式,实际指的是可以直接用字符串来代替代码)。最后,Catalyst提供多个公共的拓展接口,包括外部数据源和用户自定义类型。
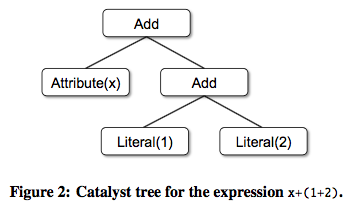
4.1 Trees(树结构)
在Catalyst中最重要的数据类型就是由一系列节点构成的树结构。每个节点包含一个节点类型,同时包含零个或多个子节点。如果要定义新的节点类型,在Scala中,可以通过继承TreeNode class来实现。这些类是不可变的,可以使用函数式转换(transformations)来操作这些类。
简单来说,假设我们有下面三个类,每个类代表一个节点类型。接着,就可以使用这三个节点类来构建一个非常简单的表达式。
- Literal(value:Int): 常量类;
- Attribute(name:String): 输入row的一个属性,如“x”;
- Add(left:TreeNode,right: TreeNode) : 两个表达式的和;
row 可以参考DataFrame转换为RDD时的Row
使用这些类就可以构建表达式树:比如,构建表达式x+(1+2)的树,可以使用下面的Scala代码来构建(参考图2):
Add(Attribute(x), Add(Literal(1)), Literal(2))
4.2 Rules(规则)
规则可以理解为一个函数,可以把一个树转换生成另外一个树,所以可以使用规则来操作树。
TODO 下段有待加强。
While一个规则可以在其输入的树上运行任意的代码(这里的树指的是一个Scala的类),最常使用的方式是使用一系列的模式匹配来找到以及替换具有特定结构的子树。
模式识别(pattern matching)是很多函数式编程语言都具有的一个特性,可以从可能的嵌套的代数数据类型(algebraic data type)结构中找到匹配的值。在Catalyst中,trees(树结构)提供transform方法,可以应用模式识别函数来递归的遍历树中的所有节点,这样就可以针对每个节点来匹配与之对应的结果或模式。例如,可以使用如下的方式实现常量之间的加法:
tree.transform
case Add(Literal(c1), Literal(c2) => Literal(c1+c2))
把上面的函数应用到 表达式x+(1+2)树上就会生成一个新的树x+3.这里的‘case’关键字是Scala标准的模式识别语法格式,‘case’可以匹配object的类型或者使用给定的名称进行匹配来提取值(比如这里的c1,c2)。
传给transform的模式识别表达式是一个partial function
partial function:偏函数。Scala 偏应用函数是一种表达式,你不需要提供函数需要的所有参数,只需要提供部分,或不提供所需参数。参考 Scala 偏应用函数
也就是表达式只需要匹配所有可能的输入树的一部分(也可以理解为一个节点)即可。Catalyst会测试一个给定的规则以确定可以应用到树中的哪个部分,同时在不匹配的时候会自动的跳过或者遍历其子树。这个特性意味着规则只会针对匹配树应用优化,而对不匹配的则不应用。
所以,这些规则不需要作为新的操作符添加到系统中。(说的意思就是,这些规则是类似一个plugin,可以随插随用,而不需要改动系统的代码)。
原文为:Thus, rules do not need to be modified as new types of operators are added to the system. TODO:上面翻译的准确性待验证。
在同一个transform调用中规则可以同时匹配多个模式,所以实现多个转换匹配将会非常简单,如下:
tree.transform
case Add(Literal(c1), Literal(c2)) => Literal(c1 + c2)
case Add(left, Literal(0)) => left
case Add(Literal(0), right) => right
事实上,可能需要多次应用规则才能完整的转换一个树。Catalyst 把规则进行分组,称为批操作(batches),同时针对每个批处理递归执行,直到到达一个固定的点,这个点就是当再次应用规则的时候,树不会再次改变。
Runing rules to fixed point means that each rule can be simple and self-contained, and yet still eventually have larger global effects on a tree.
->
应用规则到一个固定点指的是每个规则是简单的及自包容的,同时最终仍然可以对树产生一个更大的全局的效果。
更大的全局的效果? TODO
在上面的例子中,重复应用就可以得到一个更大的树,如(x+0) +(3 + 3).
举另外一个例子,第一个批处理可能会分析表达式,同时为每个属性匹配并分配类型,而第二个批处理就可以使用这些分配好的类型进行常量整合(就是先合并常量项)。执行每个批处理后,开发者也可以对新生成的树执行完整性检查(例如,检查是否所有的属性都匹配到了类型,这些完整性检查也可以通过递归的来实现)。
最后,规则的条件和规则的实体可以包含任意的Scala代码。这个特性使得Catalyst比领域特定语言(domain specific language)不仅在优化器上更具优势,同时也保持了针对简单规则简洁性。
根据我们的经验,对不变的树应用函数式转换操作可以使得整个优化器很容易进行推导及调试。函数式转换也可以使得在优化器中很容易实现并行处理,尽管我们还没有利用这个特性进行优化。
4.3 Using Catalyst in Spark SQL(在Spark SQL中使用Catalyst优化器)
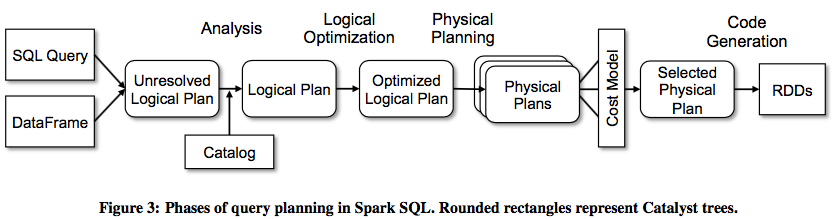
在Catalyst中,一般的树转换框架可以使用四个步骤来实现(如图3所示):
- 通过分析逻辑计划来替换引用;
- 优化逻辑计划;
- 物理计划;
- 代码生成(编译部分查询代码到Java二进制);
在物理计划阶段,Catalyst可能生成多个计划,同时会根据成本来比较这些计划并选择某个计划。
成本: 通过某些手段可以评估计划执行的耗时,以此来择优选取计划。
其他三个阶段都是完全基于规则的。每个阶段使用不同的树节点类型,Catalyst内含表达式、数据类型、逻辑、物理操作符相关的库。接下来详细描述着四个阶段。
4.3.1 Analysis (分析阶段)
Spark SQL最开始是一个待计算的关系表达式,这个表达式要么是从一个SQL解析器中得到的抽象语法树(AST,abstract syntax tree),要么是通过DataFrame API得到的。不管是怎样得到的,待计算的关系表达式都可能包含仍未解析的属性引用或其他关系表达式。
例如,在如下的SQL中 :
SELECT col FROM sales
如果我们不查看表sales的话,那么对于col列的类型我们是不知道,甚至我们都不知道col列名是否是一个合法的列名。一个未被解析的属性指的是还不知道该属性的数据类型或者该属性不能匹配输入表的字段(或者别名)。
Spark SQL中使用Catalyst规则以及Catalog引用(可以理解为元数据信息,有所有表的相关信息)来跟踪所有数据源中的表,以此来解析其出现的属性信息。所以,最开始,会构建一个“未解析的逻辑计划(unresolved logical plan)”树,这个树包含未绑定的属性及数据类型,接着会应用规则来解析,具体如下:
- 在catalog中根据名字查找关系(此处的关系可以理解为表);
- 映射列,如列名 col,to the input provided given operator’s children;
- 确定哪些属性是一样的,同时给他们一个唯一的ID(后面会针对表达式进行优化,如col=col,可以防止同样的属性被解析多次,降低效率)
- 通过表达式推断类型(propagating and coercing types through expressions),例如:针对表达式1 + col,如果想知道这个表达式的数据类型,那么就需要先知道col的类型,然后尽可能的把该表达式的数据类型转换成“正确”的类型。
最后,该分析器(analyzer)的实现代码大约有1000行。
4.3.2 Logical Optimization(逻辑优化阶段)
在逻辑优化阶段,会对逻辑计划应用标准的基于规则的优化,包括
- 常量合并(constant folding);
- predicate pushdown(谓词下推?简而言之,就是在不影响结果的情况下,尽量将过滤条件提前执行。);
- projection pruning(映射修剪?);
- null propagating(空传播?它将空的源值直接转换为空的目标值);
- 布尔表达式简化;
- 其他规则。
一般来说,在很多的情况下添加规则都非常简单。比如,当已经在Spark SQL中添加了一个固定精度的DECIMAL类型,那么如果要对DECIMAL进行小精度的聚合操作,如SUM或AVG操作,那么仅仅使用12行代码就可以写一个规则来实现这样的需求。其过程如下:先把其转换为一个unscaled 64-bit LONGs,接着对其进行聚合操作,得到结果后,再次转换即可。一个简单的版本实现如下(只实现了SUM操作):
object DecimalAggregates extends Rule[LogicalPlan]
/** Maximum number of decimal digits in a Long */
val MAX_LONG_DIGITS = 18
def apply(plan: LogicalPlan): LogicalPlan =
plan transformAllExpressions
case Sum(e @ DecimalType.Expression(prec, scale))
if prec + 10 <= MAX_LONG_DIGITS =>
MakeDecimal(Sum(LongValue(e)), prec + 10, scale)
另外一个例子,LIKE表达式可以通过12行类似的规则来进行优化,可以简单的使用String.startsWith或String.contains来实现正则中的简单判断。在规则中可以使用任意Scala代码使得这种优化在简洁性上远远超过了使用模式识别来匹配子树结构的方式。
而逻辑优化规则的实现代码有近800行左右。
4.3.3 Physical Planning(物理计划)
在物理计划阶段,Spark SQL根据一个逻辑计划,使用与Spark执行引擎匹配的物理操作符来生成一个或多个物理计划。接着,使用成本代价模型来选择一个计划。目前,根据代价模型的优化器只用在了Join操作上:针对比较小的DataFrame,Spark SQL使用broadcast join。
broadcast join : 使用Spark中的一个端到端的广播工具类来实现。
这个框架支持广泛的基于代价模型的优化,但是,一般情况下代价都需要对整个树递归地应用规则来进行评估,所以将来会实现更多的基于代价模型的优化算法。
物理执行器也可以进行基于规则的物理优化,比如在一个map函数中直接应用pipelining projections(管道投影?)或者过滤。另外,它可以把逻辑计划中的操作放入到支持predicate或者projection pushdown的数据源中执行(效率更高,等于是直接使用数据源的引擎,少了一层转换)。
predicate : 断言
projection pushdown: 谓词下推
在 4.4.1中会介绍这些数据源相关的API。实现物理计划规则的代码有将近500行。
4.3.4 Code Generation(代码生成)
最后一个查询优化阶段包含需要在每个机器上运行的生成的Java二进制代码。因为Spark SQL经常操作内存中的数据集(这个操作是CPU受限的),所以,我们想支持代码生成,以此来加速执行。
这里对比的地方是:1. 使用转换来调用要执行的任务;2. 通过代码生成要执行的任务; 所以如果有速度提升,那么就是直接生成代码,然后执行任务,其耗时更少。
尽管如此,一般的代码生成引擎构建都比较复杂,基本上相当于一个编译器了。Catalyst基于Scala语言的一个特殊的特性,“quasiquotes”(把字符串替换为代码的特性),使得代码生成更加简单。Quasiquotes允许在Scala中使用代码构建抽象语法树(AST),构建的抽象语法树会被传给Scala编译器,进而在运行时生成二进制代码。我们使用Catalyst来转换一个SQL表达式代表的树到AST,以此来使用Scala代码对该表达式进行评估(可以理解为执行SQL表达式),进而编译和执行生成的代码。
举个简单的例子,在4.2节中引入的Add操作、Attribute、Literal树节点,可以使用这些简单的树节点来构造这样的一个表达式:
(x+y)+1.
如果没有代码生成,这样的表达式就会针对数据的每行进行操作,也就是从Add,属性,常量构成的树的根节点开始,往下遍历,这就会造成大量的分支和virtual function(虚拟函数?)的调用,从而降低执行的效率。如果使用代码生成,那么就可以编写一个函数来把某个固定的表达式树转换成一个Scala的AST,如下:
def compile(node: Node): AST = node match
case Literal(value) => q"$value"
case Attribute(name) => q"row.get($name)"
case Add(left, right) =>
q"$compile(left) + $compile(right)"
以q开头的字符串就是quasiquotes,意味着尽管这些看起来像字符串,但是他们会被Scala编译器在编译的时候转换成表示AST树的代码。Quasiquotes可以使用“$”符号连接变量或其他AST树。例如,Literal(1)在Scala AST树中直接转换为1,而Attribute(“x”)可以转换为row.get(“x”)。所以,类似Add(Literal(1), Attribute(“x”))的AST树就会生成1+row.get(“x”)的Scala表达式。
Quasiquotes在编译的时候会进行类型检查,以确保AST或字符串能被正确的替换(这个功能比字符串的拼接更加的实用,同时,它可以直接生成Scala的AST而不是在执行时还需要Scala转换器进行转换)。此外,它们是高度可组合的,因为每个节点代码生成规则不需要知道其子节点生成的树是怎么样子的。最后,如果Catalyst没有对其进行优化的化,生成的代码仍可以被Scala编译器进行表达式级别的优化。图4对比了使用Quasiquotes生成的代码效率和手动优化的代码效率。
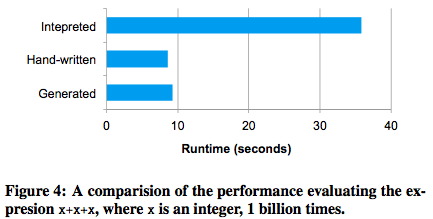
我们发现使用quasiquotes来进行代码生成整个逻辑很清晰,所以就算是新的参与者也可以很容易的针对新的表达式类型添加规则。Quasiquotes也可以在原生Java类型上工作的很好,当访问Java类中的字段时,可以生成一个直接字段的访问,而不是拷贝类到一个Spark SQL中的Row,然后使用Row的方法来访问某个字段(所以其效率高)。最后,因为我们编译的Scala代码可以直接调用我们的表达式解释器,所以虽然整合表达式的代码生成式评估(code-generated evaluation)和直译式评估(interpreted evaluation)不复杂,但是我们还没有对这块进行代码生成。
最后,Catalyst的代码生成器实现一共有700行左右代码。
4.4 Extension Points(扩展点)
Catalyst针对可组合的规则设计使得用户或第三方可以很容易的进行拓展。开发者可以针对执行阶段的查询优化器的多个阶段添加多批次规则,只要他们遵守一定的规则(如保证在分析阶段,所有的变量都得到解析等)
以上是关于Spark SQL: Relational Data Processing in Spark的主要内容,如果未能解决你的问题,请参考以下文章