AI十行代码系列6.3D物体追踪-MediaPipe Python
Posted 朱铭德
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI十行代码系列6.3D物体追踪-MediaPipe Python相关的知识,希望对你有一定的参考价值。
【TLAIP系列简介】Ten-Lines-AI-Projects
现阶段有非常多优秀的开源的AI工程,为了有更好的可扩展性,接口往往设计得十分复杂,这需要投入一定的时间和精力来处理,对于不熟悉或者刚入门的小伙伴,这可能需要花很久。本系列设计的出发点也很纯粹,进一步降低小伙伴们挑选和使用轮子的时间,让更多小伙伴能更快地验证算法效果,算法满足效果了再扒开看看,不满意直接看下一个。有任何问题和建议欢迎随时评论,目前系列里的十行代码会按照下列方式进行:
import 关键py
1.定义好输入
2.网络初始化配置
3.开始跑并输出结果
4.可视化结果包含空格和一些必要的说明,估计正好十行。哈哈哈哈(不能再少了,再少我的强迫症就不能忍受了)。
如果遇到什么很牛逼的AI工程或者自己不想跑的但是一眼看上去效果很好的工程,欢迎留言交流哈,有空可以一并整理到这个工程,一键可运行,无繁杂使用过程。
【正文】
本文的主角依旧是谷歌大名鼎鼎的MediaPipe,主要功能是3D物体检测,相信大家之前也试过虚拟试鞋了,想要一个比较稳定的AR叠加效果,就需要检测出物体的3D pose,MediaPipe目前支持四种模型(鞋、水杯、椅子、相机)。惯例先放效果:
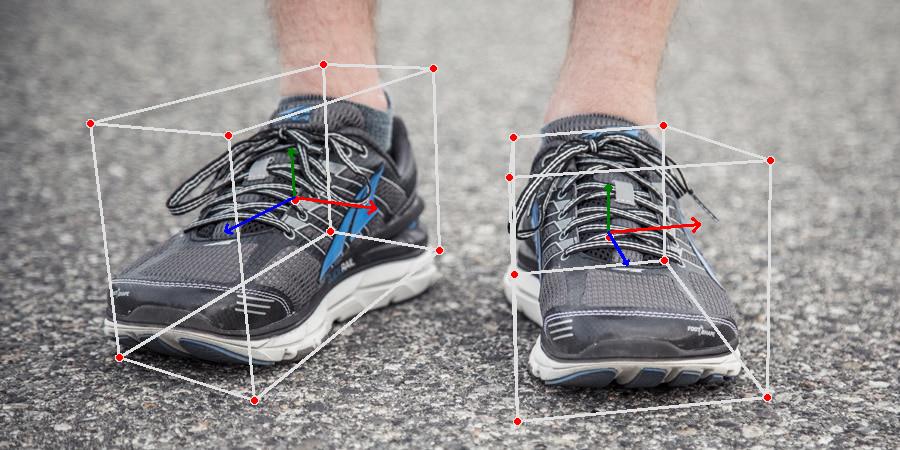

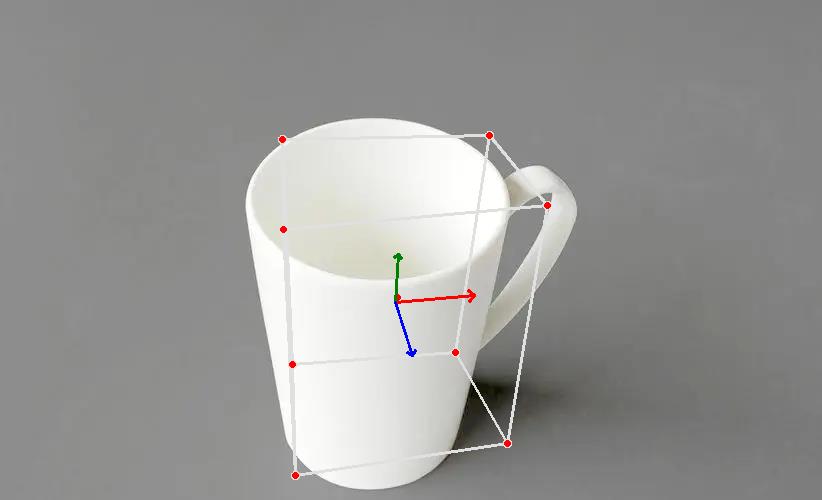


十行代码
依旧是熟悉的配方,三大块,由于涉及到四个3D检测模型,用model_name进行了区分,会自动根据name区分测试的图片(是不是很良心)。自己试的时候记得把输入改成自己的摄像头,会更直观一些,input_data = InputData(0)即可。
from utils.objectron_mediapipe import InputData, InitObjectron, ShowResult
model_name = "Shoe" # "Shoe" "Cup" "Chair" "Camera"
# 初始化输入源, file支持数字(相机)以及视频文件路径,图片路径或文件夹路径
input_data = InputData("test/imgs/" + model_name) # input_data = InputData("test/Shoe.mp4")
detect_3d_object = InitObjectron(object_name=model_name, static_mode=input_data.use_img_list)
# 获取图像以及结果的generator
run_pose_result = detect_3d_object.run_objectron(input_data.get_next_img())
# 显示结果, ESC退出,图片模式按任意键继续
ShowResult(input_data.wait_key).show_result(run_pose_result)InputData用来处理各种输入,目前兼容下列各种情况的输入(是不是很良心):
- 系统相机,输入相机编号即可,例如 InputData(file=0)
- 一个视频文件,输入视频路径即可,例如 InputData(file="test/hand_tracking.mp4")
- 一张图片,输入图片路径即可,例如 InputData(file="test/imgs/0.jpg")
- 一个包含很多图像的目录,输入目录路径即可,例如 InputData(file="test/imgs")
InitPoseTracker用来初始化网络的参数,主要参数如下:
- use_static_mode 图片模型还是视频模式,如果是图片,会先运行检测算法,否则直接追踪
- object_name用来控制3D物体模型("Shoe" "Cup" "Chair" "Camera"四选一)
ShowResult用来可视化结果
- waitkey_mode 默认1,会刷新显示视频;输入0的话会阻塞图像显示,按下任意键继续
环境配置和使用说明
配置conda(可选),注意需要使用python3.7及以上(3.6没有分割模块!)
conda create -n mediapipe python=3.7
conda activate mediapipe安装必要的依赖包
注意这里的mediapipe版本,低版本的没有这个模块
pip install opencv-python
pip install mediapipe==0.8.9.1配置好环境后,直接运行 “运行这个.py" 即可
功能代码剖析
没太多要说的,试就完事儿了。功能代码:
import cv2
import os
import mediapipe as mp
class InputData:
def __init__(self, file=0, repeat=False, repeat_step=1):
self.cap = None
self.repeat = repeat
self.repeat_step = repeat_step
self.img_list = []
self.img_id = 0
self.img_type_list = 'jpg', 'bmp', 'png', 'jpeg', 'rgb', 'tif', 'webp'
self.deal_with_input(file)
self.use_img_list = len(self.img_list) > 0
self.wait_key = 0 if self.use_img_list else 1
self.use_static_mode = self.use_img_list
def gen_img_list(self, path):
for item in os.listdir(path):
if item.split(".")[-1] in self.img_type_list:
self.img_list.append(os.path.join(path, item))
def deal_with_input(self, file):
path_valid = False
if isinstance(file, int):
# use camera
self.cap = cv2.VideoCapture(file)
path_valid = True
elif isinstance(file, str):
if os.path.isdir(file):
# use img list
self.gen_img_list(file)
if len(self.img_list) > 0:
path_valid = True
else:
print("no images in", file)
elif os.path.isfile(file):
if file.split(".")[-1] in self.img_type_list:
# only one image
self.img_list.append(file)
path_valid = True
else:
self.cap = cv2.VideoCapture(file)
if self.cap.isOpened():
print("video path is", file)
path_valid = True
else:
print("video path is not valid, path is:", file)
if not path_valid:
print("Invalid input! Use camera 0 instead!")
self.cap = cv2.VideoCapture(0)
def get_next_img(self):
if self.use_img_list:
while self.img_id < len(self.img_list):
img = cv2.imread(self.img_list[int(self.img_id)])
self.img_id += 1 / self.repeat_step
if self.img_id >= len(self.img_list) and self.repeat:
self.img_id = 0
if img is not None:
yield img
yield None
else:
while True:
_, img = self.cap.read()
if img is None:
yield None
break
yield img
def release_cap(self):
if self.cap:
self.cap.release()
class InitObjectron:
def __init__(self, object_name='shoe', max_num_objects=5, static_mode=True):
self.objectron = None
self.static_mode = static_mode
self.max_num_object = max_num_objects
self.object_name = object_name
self.init_network()
def init_network(self):
self.objectron = mp.solutions.objectron.Objectron(static_image_mode=self.static_mode,
max_num_objects=self.max_num_object,
min_detection_confidence=0.5,
min_tracking_confidence=0.99,
model_name=self.object_name)
def run_objectron(self, get_nex_img):
while True:
img_origin = next(get_nex_img)
if img_origin is None:
yield [None, None]
break
img = cv2.cvtColor(img_origin, cv2.COLOR_BGR2RGB)
yield [img_origin, self.objectron.process(img)]
class ShowResult:
def __init__(self, waitkey_mode=1):
self.waitkey = waitkey_mode
def show_result(self, run_hand_tracking):
while True:
img, results = next(run_hand_tracking)
if img is None:
break
if results.detected_objects:
for detected_object in results.detected_objects:
mp.solutions.drawing_utils.draw_landmarks(
img, detected_object.landmarks_2d, mp.solutions.objectron.BOX_CONNECTIONS)
mp.solutions.drawing_utils.draw_axis(img, detected_object.rotation,
detected_object.translation)
# Flip the image horizontally for a selfie-view display.
cv2.imshow('MediaPipe Objectron', img)
if cv2.waitKey(self.waitkey) & 0xFF == 27:
break
实际运行结果及简单点评
目前支持的模型有四个,但能看的基本只有Shoe了(其他几个实测效果挺一般),实际体验效果也有些差强人意,想用在项目里肯定还是要自己训练模型。
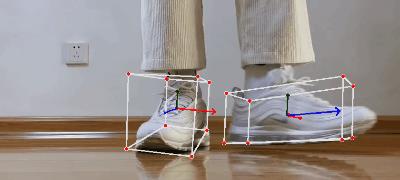
另外几个模型漏检也挺严重,精细调整下阈值会好一些,但根本上模型其实还是没达到预期的程度,pose不是很准确,可以通过这个项目了解下3D物体识别的一些链路和形式,想要比较好的效果还是需要自己着手训练,目前做不到2D检测一样通用和完善。
拓展阅读
如果看了效果想进一步尝试,可以仔细研究下面两个链接
Objectron (3D Object Detection) - mediapipe https://google.github.io/mediapipe/solutions/objectron.html
https://google.github.io/mediapipe/solutions/objectron.html
写在最后
往期TLAIP列表:
【AI十行代码系列】1.手势关键点追踪-MediaPipe Python_朱铭德的博客-CSDN博客
【AI十行代码系列】2.人体关键点定位-MediaPipe Python_朱铭德的博客-CSDN博客
【AI十行代码系列】3.人脸关键点定位-MediaPipe Python_朱铭德的博客-CSDN博客
【AI十行代码系列】4.全身关键点定位-MediaPipe Python_朱铭德的博客-CSDN博客
【AI十行代码系列】5.人像分割-MediaPipe Python_朱铭德的博客-CSDN博客
AI十行代码仓库地址(最重要的→)链接 ,后续功能也会在这里更新,欢迎提建议或需求,哈哈,本文相关所有代码和资源也可以在这里下载。
如果文章对你稍微有些帮助的话,麻烦来个三连(疯狂暗示)。
祝大家诸事顺遂~

以上是关于AI十行代码系列6.3D物体追踪-MediaPipe Python的主要内容,如果未能解决你的问题,请参考以下文章