深入理解Java并发编程之核心原理概念
Posted 刘镓旗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解Java并发编程之核心原理概念相关的知识,希望对你有一定的参考价值。
转载请注明出处:https://blog.csdn.net/yulong0809/article/details/79728009
前言
Java的并发时一般都会synchronized、volatile和Lock来实现同步,或者使用Java提供的一些辅助类,例如atomic和concurrent包下AtomicXXXX,ConcurrentXXX等,但是我们是否想过为什么会有这些关键字和类呢?这些关键字和类解决了什么问题?又是如何实现的呢?可能有的人会说不就是因为多线程操作吗;解决的就是并发时数据错误的问题;是通过唤醒机制实现的;但是真的就这么简单吗?显然不是的,这些涉及了大量的知识点,接下来就来梳理一下并将它们串下来。
首先我们知道多线程并发操作的目前是让程序可以更快速更高效,但并不是启动更多的线程就会执行的更快,其实为了程序可以更高效和快速,编译器和处理器也会做一些底层的操作,让我们程序在有效的时间可以更高效的执行,例如重排序,但是不管是重排序还是多线程操作都存在一些其他的问题,例如多线程之间内存可见性的问题、重排序后导致程序执行结果的错误,那么为了解决这些出现的问题,则有了这些并发的关键字和工具,但是具体是因为什么,又是如何解决的,还需要我们注意些什么,我们慢慢来分析,下面的内容是环环相扣的,希望可以按顺序看。
上下文切换
刚才上面提到了在有效的时间内可以更高效执行,其实就是上下文切换。多线程执行的时候CPU会给每个线程分配CPU时间片,时间片就是分配给各个线程的执行时间,因为时间片非常的短,所以CPU可以通过不停的切换线程,让我们错觉的认为线程是同时执行的。每次在切换之前都需要保持当前的线程状态,以便下次切换回来的时候快速的读取状态,每一次切换就叫做一次上下文切换。那么如果过多的切换上下文自然也就会影响到程序的执行效率。既然线程执行会受到时间片的限制,所以为让了让线程在有效的时间里可以执行更多的操作,编译器和处理器就会给我们的代码进行重排序,因为我们的代码在执行的时候会转变成汇编语言,所以重排序也分成编译器重排序和指令重排序,但是不管是哪种重排序都是为了更充分的利用CPU分配的时间片。
减少上下文切换的方法有如下方法:
- 无锁并发编程:多线程竞争锁的时候会引发上下文的切换,可以使用一些其他的办法来避免使用锁。
- CAS算法:又称为自旋锁,Java的Atomic包中就使用的CAS算法来更新数据。
- 尽量减少线程的数量:线程的创建和切换都是需要的时间的,线程多了来回切换的次数自然也就就更多,所以减少线程的数量也就能减少上下文的切换了。
重排序
上面说为了可以让线程更充分的利用CPU分配的时间片,就有了重排序。为什么重排序就可以让程序更效率呢?那是因为CPU执行的速度太快,而内存操作的时间没有CPU执行的速度快,举个例子,假如有一个内存操作相当的耗时,如果不进行重排序的话,可能直到时间片结束都没有处理完这一步操作,但是如果虚拟机碰到这样的操作时先暂时绕过这一步操作,先执行下一步操作这样就可以更好的利用CPU分配的时间片了,而站在硬件层面来说为了可以快速的执行,也会按照一定的规则将一系列的指令进行重排序执行。重排序的原理非常复杂,这也是为了更好的理解举得一个例子而已。再看一下如下两行代码,在真正执行的时候不一定操作1就执行在操作2的前面。既然编译器和处理器会对代码进行重排序,那么就一定会因为重排序的缘故而导致代码逻辑错误,最终的执行结果错误,所以这时就需要有一些规则来约束因为重排序而导致的错误。
byte[] bytes = new byte[1024];//操作1
int a = 0;//操作2
规则一:数据依赖性
上面说编译器和处理器会为了更高效的执行会进行重排序,那么重排序后又肯定会影响代码的最终逻辑,导致结果错误。所以虚拟机就有了一些规则,第一个规则就是数据依赖性。什么是数据依赖性呢,就是说如果有两个操作同时访问一个变量,并且两个操作中有一个操作为写操作,那么就说这两个操作之间存在数据依赖性,所以就产生了三种数据依赖性的情况,如下:
- 写后读:写一个变量后,在读取这个变量,例子如下
int a = 1;//先写a
int b = a;//再读取a
- 写后写:写一个变量之后,再写这个变量,例如如下
int a = 1;//先写a
a = 2;//再写a
- 读后写:先读取一个变量,再写这个变量,例子如下
int a = b; //先读取变量b
b = 1;//再写b
如上三种情况假如进行重排序的话,那么这个代码的逻辑和结果就会产生错误了,所以编译器和处理器不会对有存在数据依赖性的两个操作进行重排序,但是这个数据依赖性仅仅针对单线程和单个处理器有效,不同的处理器和不同的线程之间的数据依赖性就不被编译器和处理器考虑了。
as-if-serial语义
as-if-serial语义的意思是:不管怎么重排序,单线程的执行结果不能被改变,编译器、Runtime和处理器都必须遵守这个语义规则。重排序是为了更高效的执行,但是重排序又必须要遵守as-if-serial语义和数据依赖性的规则,例如如下代码,它们在一定程度上可以进行重排序,但是又遵守了数据依赖性和不影响执行结果的语义。
double pi = 3.14; //A
double r = 1.0; //B
double area = pi * r * r; //C
A和C之间存在数据依赖性,B和C之间也存在数据依赖性,所以按照数据依赖性的规则C是不能被重排序到A和B的前面的,但是A和B却不存在数据依赖性,那么编译器和处理器是可以将A和B进行重排序的,而且不会影响最终的执行结果。
假设没有重排序的执行时: A - B - C = 3.14;
假设编译器按照规则重排序后: B - A - C = 3.14;
在单线程中因为编译器、Runtime和处理器都必须遵守as-if-serial语义,所以给了我们一种假象就是java程序是按照代码的顺序执行的,但是其实并不是,而是因为遵循了as-if-serial语义不能改变最终的执行结果,所以让我们误认为是按照代码顺序执行的,通过上面的例子我们知道,单线程也其实也存在一些重排序的。
Java的内存模型
上面两个规则全部都是针对单线程来说的,但是在多线程操作的时候重排序依然会存在,并且还会夹杂着数据可见性的问题,所以在多线程的情况下也存在着一些规则来防止这些问题的出现,但是在说这些规则之前必须要先来了解一下Java的内存模型。
Java虚拟机为了屏蔽硬件和操作系统之间的内存访问差异和提高程序的运行速度,定义一种Java抽象的内存模型(Java Memory Mode,JMM),即主内存和工作内存,这个内存模型主要用来定义程序中变量的访问规则。包括对象的实例字段、静态字段、和数组元素,不包括局部变量和方法参数,因为局部变量和方法参数是存储在栈中的,属于线程私有,并不是线程共享的。这里说的内存模型和Java的内存区域不是一个概念,不要混淆,内存模型只是虚拟机的一种抽象表现。如果硬要对照的话,那么主内存可以简单理解成主要对标堆内存和方法区,因为这两者是线程共享的区域。而工作内存可以简单理解为Java栈内存,因为栈内存属于线程私有,但是还是建议不要这样理解。为什么说不是一个概念,其实因为主内存是直接对应硬件物理内存的,而为了让程序运行的更快速,所以虚拟机会将一些数据缓存在工作内存中,简单说线程在运行的时候如果操作了一些共享变量,其实这些变量只是主内存的副本,然后会在某个特定的时间回写到主内存中,例如下图。
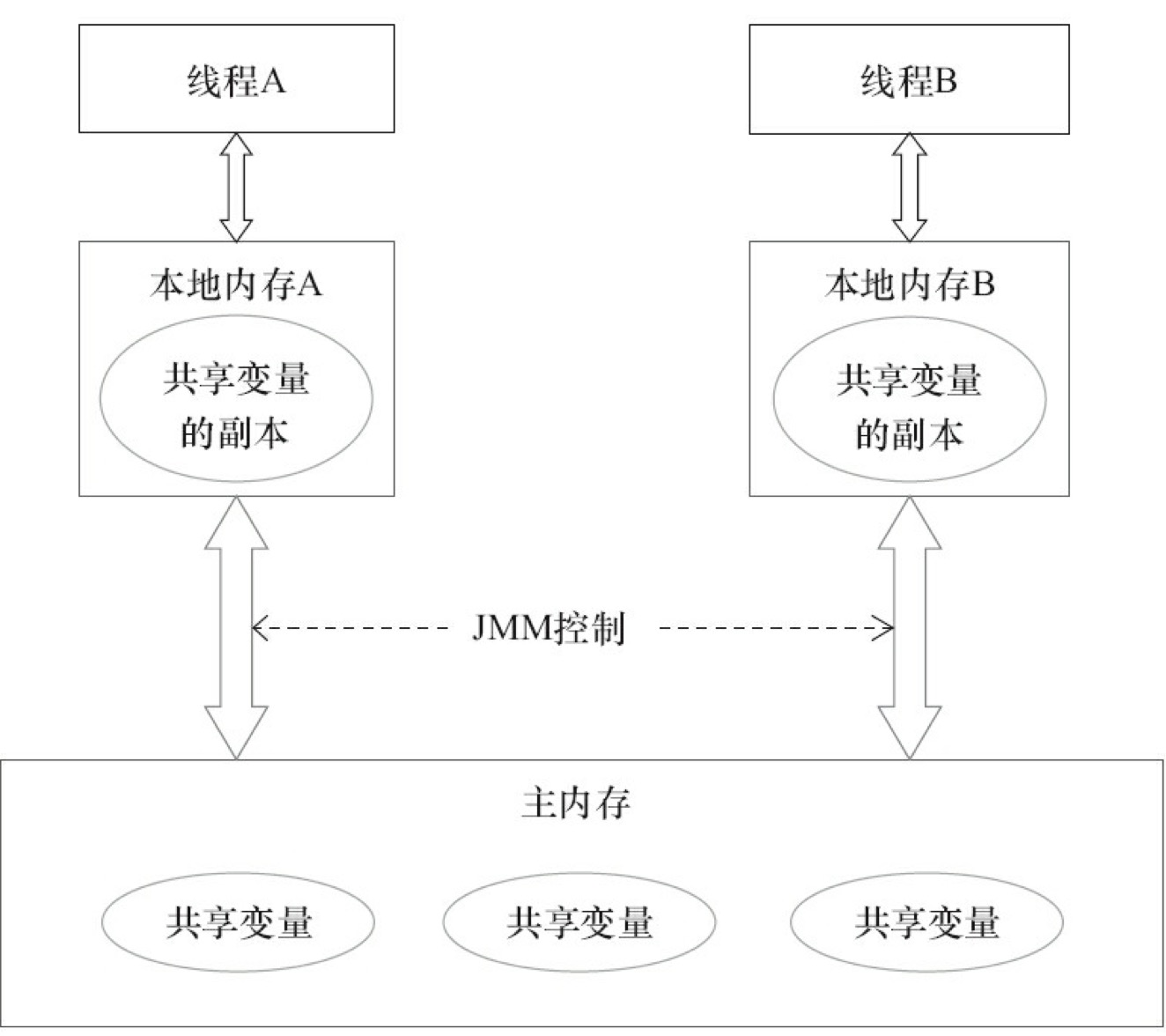
多线程操作存在的问题
这里有两个存在的问题:
第一是重排序导致的问题,如果代码被重排序了,那么就可能导致这个程序的最终结果错误,例如下面的代码,假设有两个线程A和B,A线程访问writer方法,同时B线程访问reader方法,因为writer方法中两步操作没有数据依赖性,所以可以被重排序,那么假设被重排序了,如果代码先走了第2步,这时线程被切换到B,那么这时B线程看到flag=true,但是A线程中还没有开始a=1的写入,那么这短代码最终的结果就是错误。:
class Test
int a = 0;
boolean flag = false;
public void writer()
a = 1; // 1
flag = true;//2
Public void reader()
if (flag) //3
int i = a * a;//4
第二是数据可见性的问题,在介绍Java内存模型的时候,说到多线程操作的时候如果操作了共享变量会在工作内存中存储主内存的数据副本,并且在某个特定的时间将数据刷新到主内存中。那么这里就有问题了,在“某个特定时间”到底是什么时间,说白了就是我们没法把控这个时间点。
那么上面分析出了多线程情况下出现的两个问题,所以为了解决这两个问题就引出了Java的另一个规则:happens-before。
happens-before(先行发生原则)
在Java的内存模型中,会使用happens-before的概念来描述内存可见性的问题。如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间就必须存在happens-before关系,这里说的两个操作可以是单线程,也可以是不同的多线程之间。简单点说就是如果操作A happens-before B,其意思就是说,在发生操作B之前,操作A产生的影响都能被操作B观察到,“影响”包括修改了内存中共享变量的值、发送了消息、调用了方法等,它与时间上的先后发生基本没有太大关系。happens-before观念是Java非常核心概念,因为它是判断数据是否存在竞争、线程是否安全的主要依据。
举个例子:
假设有三个线程分别执行如下三行代码
int i = 1; //A线程执行
int j = i; //B线程执行
i = 2; //C线程执行
现在假设 A线程 happens-before B线程,那么就可以保证B线程执行后j的值一定等于1,意思就是上面说的B线程观察到了A线程中操作产生的影响。
再假设现在同样还是 A线程 happens-before B线程,但是这时C线程发生在A线程和B线程之间运行,而且B线程和C线程之间不存在happens-before,那么当B线程最后执行后的值就不能确定了,这时j的值有可能是1,也有可能是2,那么也就可以说他们不具备线程安全性。
以上的例子就是happens-before的意思。Java内存模型中规定了8条happens-before的规则,这8条规则是Java本身就存在的,无需任何其他的同步操作,可以在编码中直接使用。但是如果两个操作之间的关系不在如下8条规则中,或者无法从如下8条中推倒出来的话,那么Java就不能保证他们的顺序性,也就是说不能保证最后结果的正确性。
程序顺序规则:一个单独线程中的每个操作,happens-before 与 该线程中的任意后续操作,或者说写在前面的代码 happens-before 写在后面的代码,准确地说,应该是控制流顺序而不是程序代码顺序, 因为要考虑分支、循环等结构。
监视器锁规则:对一个锁的解锁,happens-before 与随后对这个锁的加锁。
volatile变量规则:对一个volatile变量的写操作,happens-before 与后续任意对这个volatile变量的读操作。
线程启动规则:Threadd对象的start()方法,happens-before 与该线程中的任意操作。
线程终止规则:线程中的所有操作都 happens-before 于对此线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值等手段检测 到线程已经终止执行。
线程中断规则:对线程interrupt()方法的调用happen—before 于被中断线程的代码检测到中断时事件的发生。
对象终结规则:一个对象的初始化完成(构造函数执行结束)happens-before 于它的finalize()方法的开始。
传递性:如果操作A先行发生于操作B,操作B先行发生于操作C,那就 可以得出操作A先行发生于操作C的结论。
下面再深入的理解一下happens-before原则 和 时间顺序的区别,看一下如下的例子
private int value = 0;
public int get()
return value;
public void set(int value)
this.value = value;
假设有两个线程A和B分别执行get和set方法,在时间上B线先执行set(2),然后A线程再执行get方法,那么A线程最终的执行结果一定是2吗?答案是不一定,因为我们对照上面8条规则,发现没有一条符合我们value变量的操作,所以我们说A线程和B线程之间就不存在happens-before关系,所以Java内存模型也不能保证B线程对value的操作可以对A线程可见。
看了上面的几个例子可能朦胧的有点认为A happens-before B 意思就是A会在B之前执行,但是其实并不是的,来看一个例子。
int a = 1; //A
int b = 2; //B
假设只有一个线程执行上面两行代码,那么根据happens-before规则的第1条规则那么A happens-before B,但是根据数据依赖关系来看A和B不存在数据依赖,那么编译器和处理器就可能会对A和B进行重排序,并且重排序后不会影响最终的执行结果,重排序后那么B就会先在A之前执行,所以说不能单纯认为A happens-before B 就是A会先执行。happens-before 规则中说到A happens-before B并不要求A一定要在B之前执行,只要求前一个操作对后一个操作可见,并要求前一个操作按顺序在第二操作之前。可能最后一句有点绕嘴,但是细细的想想就是上面给出的例子一个意思。
以上是关于深入理解Java并发编程之核心原理概念的主要内容,如果未能解决你的问题,请参考以下文章