AlexNet-《1》-论文
Posted xiaobai_xiaokele
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AlexNet-《1》-论文相关的知识,希望对你有一定的参考价值。
AlexNet-《1》-论文
DeepLearning
architecture
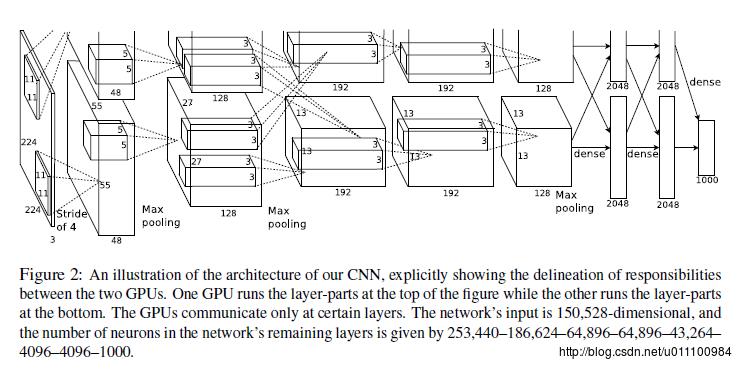
这个网络一共包含了8层,其中有5个卷积层,3个全连接层。
关键技术
1:ReLU Nonelinearity
之前标准激活函数都是tanh( f(x)=tanh(x) )以及sigmoid( f(x)=(1+e−1)−1 ),但是这种saturating nonlinearity比none-saturating nonlinearity在训练的时候梯度下降的慢。使用ReLU要快几倍。
2:多GPU
因为单独的GTX只有3G内存,装不下1.2million的训练样本,所以使用了双GPU。基本上是每个GPU一半的neuron,小技巧:GPU只在某些特定层才通信,意思就是第三层使用的是第二层的所有kernel map,但是第四层使用的只有在同一个GPU的第三层的那些kernel map。选择连接方式对于交叉验证来说是一种挑战,但是这能够更精确的训练通信的数量并且跟计算量有关。
3:Local Response Normalization
虽然ReLU并不要求input normalization,来防止saturating。但是local normalization能够促进generalization.
aix,y
表示在位置
(x,y)
实施kernel
i
之后计算得到的neuron的activity,然后进行ReLU,response-normalized activity
4:Overlapping Pooling
标准的pooling是没有overlapping的,但是为了更精确,使用了overlapping的pooling。
5:Overall Architecture
网络一共包含了8层,前5个是卷积层,后面3个全连接层,最后一个全连接层的输出到1000softmax,生成一个1000类的分布。
第2,4,5卷积层都只和存在在同一个GPU上的前一层的kernel map相连接。全连接层和前一层的全部neuron相连接。response-normalization层连接在第1,2卷积层之后,Max-pooling层连接在两个response-normalization层之后,以及第5卷积层之后。ReLU应用在每个卷积层以及全连接层。
第1卷积层对224x224x3的input应用96个11x11x3的kernel,stride为4(这个距离是kernel map的neighboring neuron的receptive field中心的距离)。第2卷积层对第1卷积层的输出(进行了response-normalized,pooled)应用256个5x5x48的filter,第3,4,5卷积层相互连接,层之间没有intervening pooling或者normalization层。第3卷积层有384个3x3x256的filter应用于第2卷积层的输出(进行了response-normalized,pooled)。第4卷积层有384个3x3x192个filter,第5卷积层有256个3x3x192filter,每个全连接层有4096个neuron。
Reducing Overfitting
1:Data Augmentation
最简单通用的从数据方面降低overfitting的方法就是使用label-preserving transformation来进行人工扩大数据集。使用了两种不同的数据增强方式:一种是进行image translation以及horizontal reflection,从256x256的图像中提取随机的224x224的patch(以及他们的horizontal reflection),并且用这些patch进行training,test的时候也进行了这样的操作。第二种方式是改变RGB通道的intensity,在train set上对RGB像素值进行PCA,对每一个训练图像,增加多个找到的主成分并且幅值和对应的特征值与高斯变量的乘积成比例。
2:Dropout
在前两个全连接层进行dropout。
后面会再分析代码。
以上是关于AlexNet-《1》-论文的主要内容,如果未能解决你的问题,请参考以下文章