ElasticSearcho从入门到放弃:Beats
Posted 浅弋、璃鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearcho从入门到放弃:Beats相关的知识,希望对你有一定的参考价值。
文章目录
一、Beats:
1. Beats:
Beats是一个开源代码的数据发送器, 也可以把Beats作为一种代理安装在服务器上, 这样就可以比较方便的将数据发送到ES或者logstash中; Elastic Stack提供了多种类型的Beats组件
官方网站: https://www.elastic.co/cn/downloads/beats/
| 组件名称 | 用途 |
|---|---|
| AuditBeat | 审计数据 |
| FileBeat | 日志文件 |
| FunctionBeat | 云数据 |
| HeartBeat | 可用性数据 |
| JournalBeat | 系统日志 |
| MetricBeat | 指标数据 |
| PacketBeat | 网络流量数据 |
| WinlogBeat | windows事件日志 |

Beats可以直接将数据发送到ES或者Logstash, 基于Logstash可以进一步地对数据进行处理, 然后将处理后的数据存入ES, 最后使用kibana进行数据可视化;
1.1 FileBeat简介
FileBeat专门用于转发和收集日志的轻量级收集工具; 它可以作为代理安装在服务器上, FileBeat监视指定路径的日志文件, 收集日志数据, 并将收集到的日志转发到ES或者Logstash;
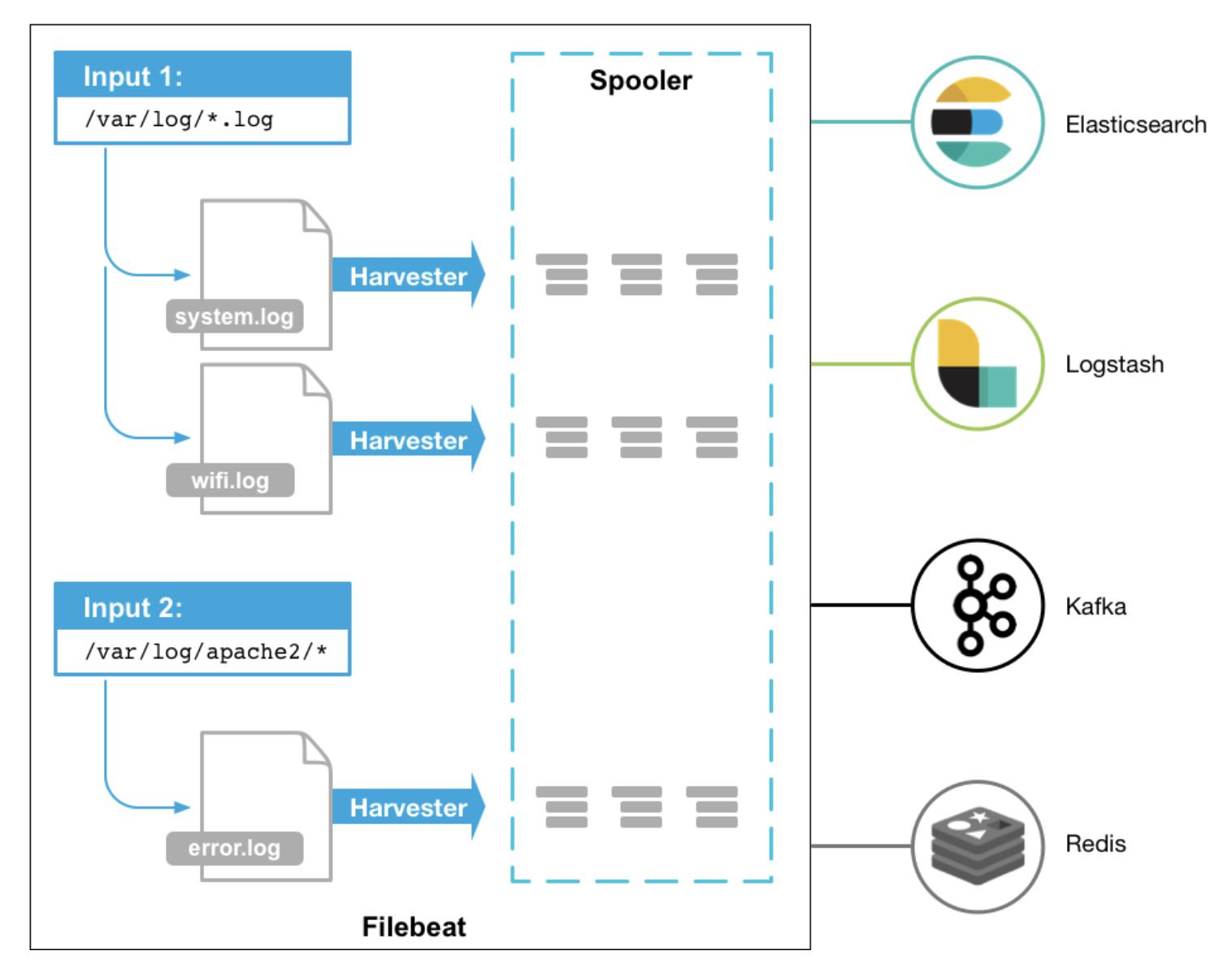
1.2 FileBeat的工作原理
启动FileBaet时, 会启动一个或者多个输入(input), 这些input监控指定的日志数据位置;
FileBeat会针对每一个文件启动一个Harvester(收割机); Harvester读取每一个文件的日志, 将新的日志发送给libbeat, libbeat将数据收集到一起, 并将数据发送给输出(output);
3. 下载及安装:
官方文档: https://www.elastic.co/cn/downloads/beats/filebeat
4. 使用fileBeat采集xxx日志到es
问题:
- 要指定FileBeat采集哪些日志, 因为FileBeat中必须知道采集存放在那里的日志, 才能进行采集;
- 采集到这些数据后, 还需要指定FileBeat将采集到的日志输出到指定的ES
4.1 配置FIleBeat
FileBeat配置文件主要分为两个部分:
- inputs
- outputs
从名字就能看出来, 一个用来输入数据, 一个用来输出数据;
4.1.1 input配置
filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
#- c:\\programdata\\elasticsearch\\logs\\*
在FileBeat中, 可以读取一个或多个数据源

4.1.2 output配置
filebeat.yml
# ---------------------------- Elasticsearch Output ----------------------------
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["localhost:9200"]
# Protocol - either `http` (default) or `https`.
#protocol: "https"
# Authentication credentials - either API key or username/password.
#api_key: "id:api_key"
#username: "elastic"
#password: "changeme"

默认FileBeat会将日志数据放入到名称为: filebeat-%filebeat版本号&-yyyy.MM.dd的索引中;
4.2 启动FileBeat
./filebeat -c filebeat.yaml -e
4.3 采集到数据
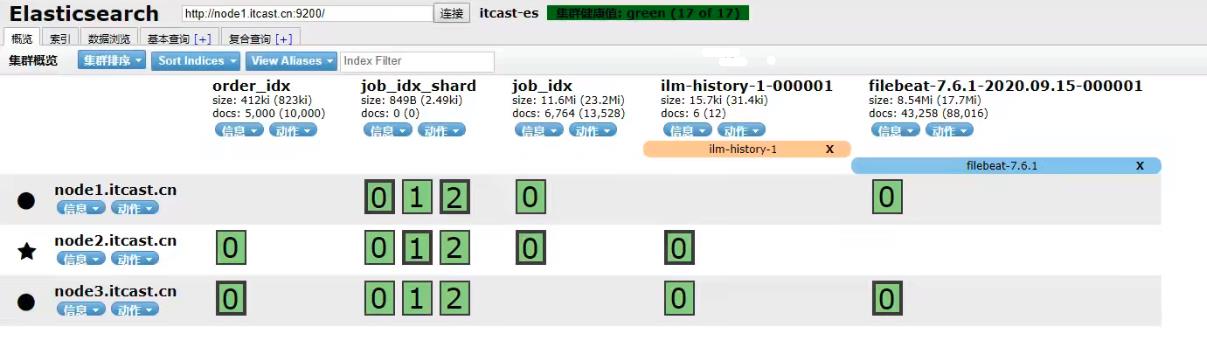
ilm: 索引生命周期管理所需要的索引;
filebeat-7.6.1: 在es中, 可以创建索引的别名, 可以使用别名来指向一个或多个索引, 因为ES中索引创建后是不允许修改的, 很多业务场景下,单一索引无法满足需求; 别名也有利于ILM索引管理生命周期;

4.4 解决多行的问题:
multiline.pattern: "^/["
multiline.negate: true
multiline.match: after
- pattern: 是一个正则表达式
- negate: 表示匹配pattern的日志就认为需要追加一行;
- match: 表示将匹配的日志追加到上一行或下一行;
5. FileBeat是如何工作的
FileBeat主要由input和harvesters组成; 这两个组件协同工作, 并将数据发送到指定的输出
5.1 input和harvesters
5.1.1 inputs(输入)
- input是负责管理harvesters和查找所有要读取的文件的组件;
- 如果输入类型是 log, input组件会查找磁盘上与路径描述相符的所有文件, 并为每个文件启动一个harvester, 乜咯输入都独立地运行;
5.1.2 harvester(收割机)
- harvester负责读取单个文件的内容, 它负责打开/关闭文件, 并逐行读取么偶个文件的内容, 将读到的内容发送给输出;
- 每个文件都会启动一个harvester;
- harvester运行时, 文件将处于打开状态; 如果文件在读取时, 被移除或重命名, filebeat将继续读取该文件;
5.3 FileBeat如何保持文件状态
- FileBeat保存每个文件的状态, 并定时将状态信息保存在磁盘的注册表文件中;
- 该状态记录harvester读取的最后一个偏移量, 并确保发送所有的日志数据;
- 如果输出(es或logstash)无法访问, FileBeat会记录成功发送的最后一行, 并在输出可用时, 继续读取文件发送数据;
- 在运行FileBeat时, 每个input的状态信息也会保存在内存中, 重启FileBeat时, 会从注册表文件中读取数据来重新构建状态;
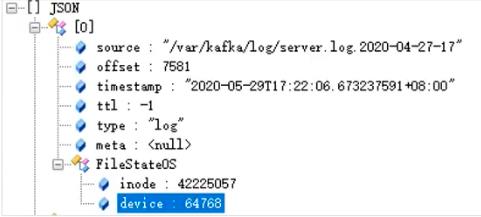
在
filebeat-xxx/data目录中有一个Registry文件夹,里面有一个data.json, 该文件中记录了harvester读取日志的offset
以上是关于ElasticSearcho从入门到放弃:Beats的主要内容,如果未能解决你的问题,请参考以下文章