流媒体技术基础-流媒体编码与协议
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了流媒体技术基础-流媒体编码与协议相关的知识,希望对你有一定的参考价值。
参考技术A各类协议详解
网页即时通信(Web Real-Time Communication),是一个支持网页浏览器进行 实时语音对话或视频对话 的API。无需安装任何插件就可以实现在网页浏览器中的实时通信。WebRTC还具备跨平台属性。
应用场景:
HttpFlv 就是 http+flv ,将音视频数据封装成FLV格式,然后通过 HTTP 协议传输给客户端。
FLV (Flash Video) 是 Adobe 公司推出的另一种视频格式,是一种在网络上传输的流媒体数据存储容器格式。
优点:可以通过 HTTP 传输,基于 HTTP/80 传输,有效避免被防火墙拦截,支持使用 HTTPS 加密传输,也能够兼容支持 android,ios 的移动端。
缺点:由于它的传输特性,会让流媒体资源缓存在本地客户端,在保密性方面不够好。因为网络流量较大,它也不适合做拉流协议。
基于 WebSocket 传输FLV,依赖浏览器支持播放FLV。 WebSocket 建立在 HTTP 之上,建立 WebSocket 连接前还要先建立 HTTP 连接。
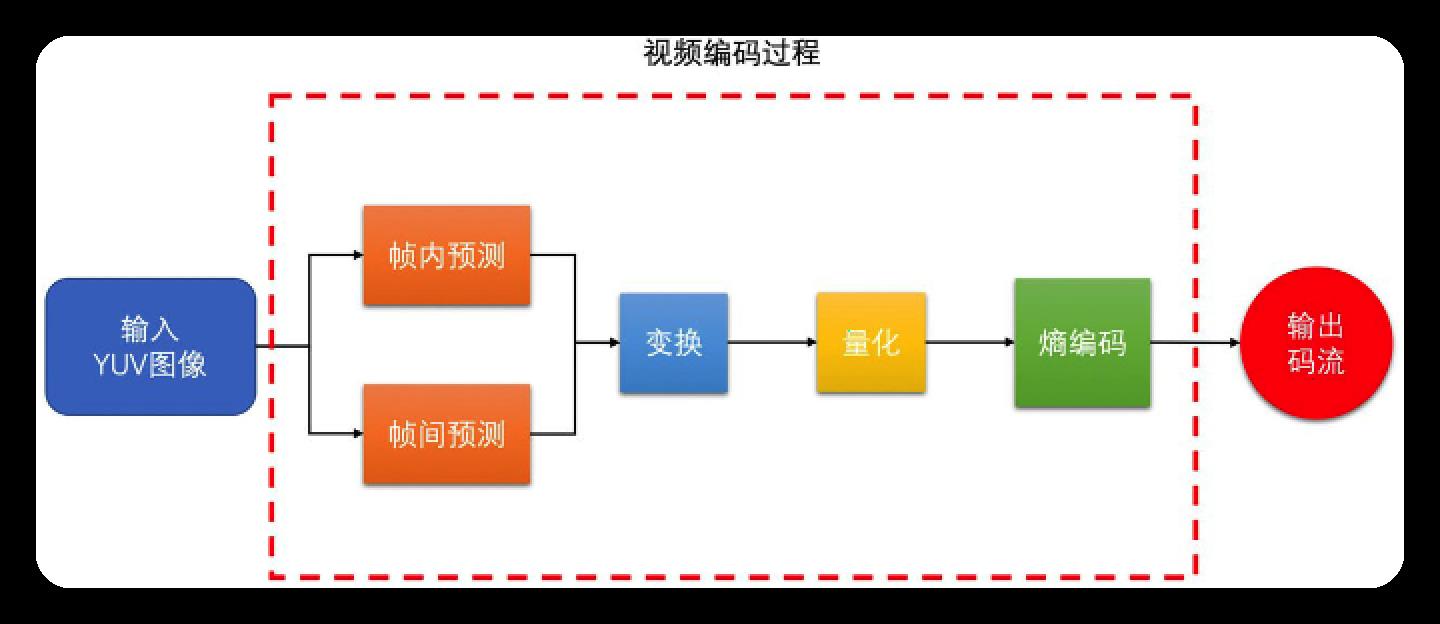
视音频编解码技术零基础学习方法
直播即互联网视音频平台直接将视频内容实时发送给用户
点播即根据用户的需要播放相应的视频节目
过程如图所示:
封装格式包含视频编码和音频编码,封装容器对音频编码和视频编码的组合方式放的很开,封装格式是不影响画质。
占用空间:BMP > PNG > JPG
音视频流媒体图像视频编码网络协议超详细介绍
文章目录
- 从参数看视频图像
- 颜色空间: YUV与RGB
- 缩放算法
- 视频编码
- 码流结构-以H264为例
- 帧内预测
- 帧间预测
- 高频视觉冗余
- RTP与RTCP网络协议
- 带宽预测
- 码控算法
- SVC可伸缩编码
- 音视频封装: MP4和FLV
- 音画同步
- 纯浏览器的视频会议方案
- 资料
从参数看视频图像

像素
像素是图像中的一个个点
分辨率
图像的分辨率指图像的大小尺寸,一般我们用像素个数表示图像的尺寸。
如720P: 1280*720; 1080P: 1920*1080; 4K: 3840 * 2160; 8K: 7680 * 4320

同一张图,用不同分辨率表示,直观感受不同:1*1只能看到像素;10*10是模糊的,100*100有了形状,1000*1000细节更清晰.
总体上: 分辨率越高, 越清晰(但注意: 通过插值算法脑补的图像,分辨率越高会越模糊)
位深
8位深图像: 是指每个像素由RGB三通道组成, RGB各占8位(1个像素共占24位即3byte), 8位可表示256个颜色, 则共可表示256^3=1677万种颜色
位深越大,能表示的颜色值越多,能更清晰展示真实世界,但每个像素占用的位数更多,存储空间更大,网络传输的流量越多
stride
跨距,是图像存储时,内存每行像素占用的空间,(即包括了内存对齐).
一般读图时一行行读,不会一列列读,故只有行的stride.
为了快速读一行像素,一般会对图像内存对齐(如16byte对齐,因一般芯片一次性读取16byte性能最高,也有32byte,甚至64byte的)
例如一张RGB图,分辨率为1278*720,若存储一行需1278*3=3834byte,但因3834无法整除16,故填6byte得到3840byte,即此图的stride为3840byte.

存储按stride=3840存,读图时跳过尾部填充像素即可,否则若将第N行的尾部无效填充像素视为第N+1行的头部有效像素的话,就会花屏:即屏幕出现N条斜线.
所以,无论读图,渲染图,存储图,均需要设置正确的stride.
帧率fps
帧率: 1秒内的图像数量, (视频其实是N帧图像组成),电影院帧率为24fps(帧/秒),监控行业25fps,声网有15,24,30fps.
帧率越高
- 对设备性能要求越高, 尤其是pipeline较长(如人脸识别,美颜算法)情况下.
- 流量越大,对带宽要求越高.
码率Kb/s,Mb/s
因视频每秒有很多图像,一般先压缩后存储,以减少磁盘占用.
但压缩后的视频,如何衡量其大小,(因为有静态视频文件,和流媒体视频),故一般通过码率衡量.
码率:1s内数据量的大小,如Kb/s或Mb/s.
- 一般可用
文件大小/文件时长计算,(因为虽然文件包括视频与音频,但音频码率相比视频小得多,可忽略)
效果: - 码率越高or压缩算法的压缩率越高or压缩速度越慢: 则视频画面越清晰,存储空间更大,传输流量越多.
- 若队清晰度要求高,可选变化码率
- 如视频内容不同时,就会产生码率变化,如
视频背景特别简单和特别复杂的情况下编码出的码率是不同的. - 编码后的码率
- 若大于固定码率,则丢失细节数据,使降低码率
- 若小于固定码率,则填充数据
- 如视频内容不同时,就会产生码率变化,如
- 若RTC场景可选固定码率
- 上例
视频背景特别简单和特别复杂的情况下,编码器对复杂背景压缩的狠,而简单背景不压缩
- 上例
颜色空间: YUV与RGB
opencv一般用BGR方式存图

因为RGB三色有相关性,不方便压缩,故视频领域一般用YUV
Y是亮度(包含了图像总体的轮廓),UV是色度(分为U分量和V分量),若一张图只有Y而无UV则为黑白图(若用RGB表示图像则黑白电视机无法播放,因为RGB三个通道都是彩色的)
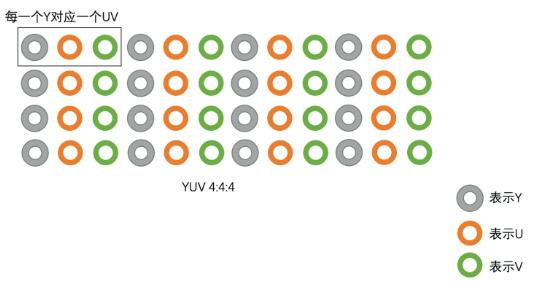
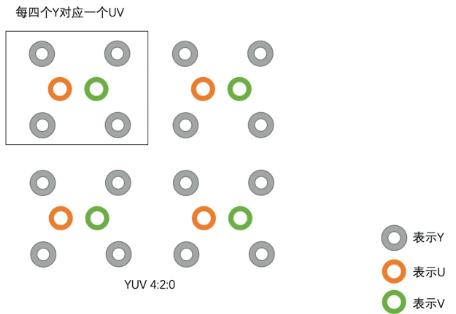
有YUV4:4:4,YUV4:2:2,YUV4:2:0这些常见类型,其中YUV4:2:0最常用.主要区别是U和V分量像素点的个数和采集方式
YUV4:4:4是1个Y有1组UV
YUV4:2:2是2个Y共用1组UV

YUV4:2:0是4个Y共用1组UV
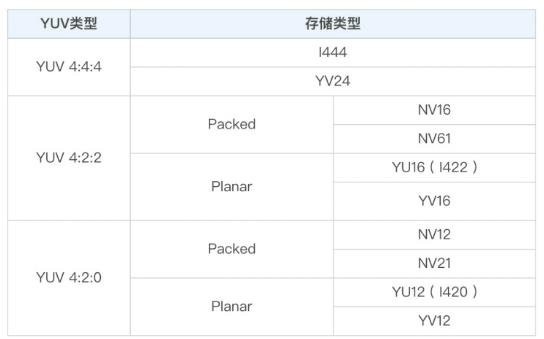
存储格式有Planar和Packed两种
Planar是先连续存所有像素点的Y,在存所有像素的的U,再存所有像素点的V
Packed是先存所以后像素点的Y,再U,V连续存储
YUV4:4:4
4*2像素的图像,的YUV4:4:4按如下存储
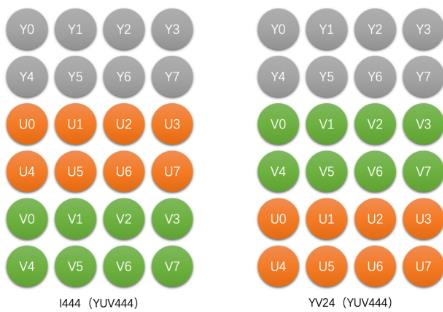
存储大小,和RGB相同,均为每个像素占3byte
YUV4:2:2
2个Y公用1组UV, 有以下4种存储方式
均以4*2像素的为例,RGB需24byte,而YUV4:2:2仅需16byte
即若为8bit位深,则RGB每个像素需3byte,而YUV4:2:2仅需2byte
YU16(或I422,YUV422P)
Planar格式,先存Y,再U,再V
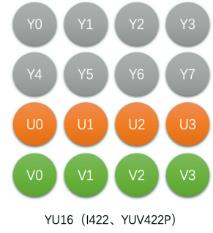
YV16(YUV422P)
Planar格式,先存Y,再存V,再存U
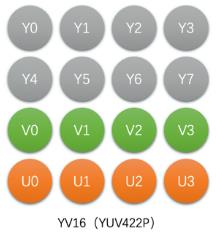
NV16(YUV422SP)
Packed格式,先存Y,再UV连续交错存

NV61(YUV422SP)
Packed格式,先存Y,再VU连续交错存储
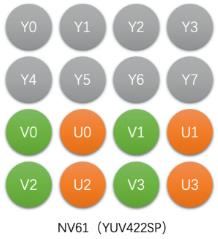
YUV4:2:0
最常见,每上下左右4个像素点共用1组UV,如下均以4*4像素的图像为例,4*4的GRB图需48byte,而YUV4:2:0仅需24byte,存储空间仅为一半
即若8bit位深,则RGB每个像素需3byte,YUV4:2:0仅需1.5byte
YU12(I420,YUV420P)
Planar格式,先存Y,再存U,再存V

YV12(YUV420P)

NV12(YUV420SP)
Packed格式,先存Y,再UV连续交错存储

NV21(YUV420SP)
Packed格式,先存Y,再VU连续交错存储

RGB与YUV转换
原图和给显示器渲染的最终图像均为RGB,但视频用YUV编码,故需转换.
FullRange的RGB取值范围均为0255,而LimitedRange的RGB取值范围均为16235.
BT709(高清)和BT601(标清)标准定义了RGB和YUV互转的规范.

YUV存储比GRB小,但会有一些色度失真(但人不敏感),故还是优点大于缺点
RGB是有相关性的, 相关性是指一幅图像在RGB格式的时候,将R、G、B三个通道分离开来当作图像来看的话,R、G、B三张图像内容几乎是一样的,只是颜色不同而已。具有相关性,
如果拿来编码的话,三张图像同等重要,而且轮廓还差不多,但颜色又不同,因此不好编码。而YUV不同,YUV中只有Y是图像的大体轮廓,没有颜色信息。U、V是颜色信息。三张图像相互独立。并且人眼对于色彩信息相比图像的轮廓信息不敏感些。我们可以缩小U、V的大小,比如YUV420中U、V只有Y的1/4大小,本身就相比于RGB图像小了一半。然后我们编码的时候Y、U、V相关性很小,可以独立编码,也很方便。
缩放算法
有3种缩放场景
- 如果视频
原始分辨率和播放窗口的大小不一致,就需要缩放.- 如电影分辨率1080P,但播放器大小为720P,则需将电影从1080P缩放到720P.
- 如点击了全屏播放按钮后播放窗口变为4K,则需将电影放大
- 在线观看视频的分辨率,在一个图像分辨率基础上缩放出多种尺寸图像,保存到多个不同分辨率的视频文件.
- RTC场景,根据网络状况实时调节视频通话的分辨率,通过缩放算法实现.
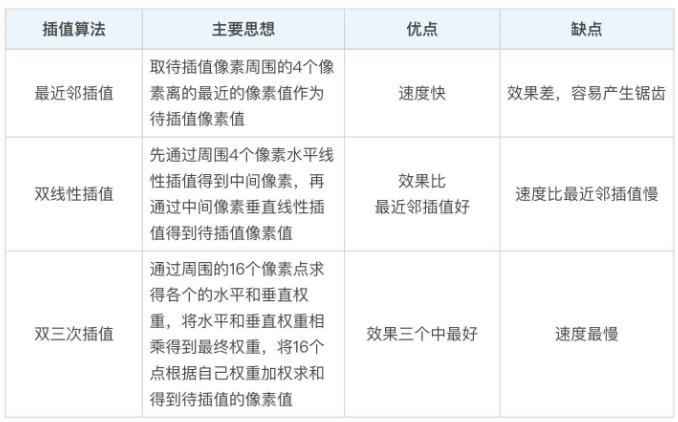
大多数缩放,通过插值算法实现,即根据周围已有的像素值+通过加权运算得到插值像素值,有最近邻插值算法,双线性插值算法,双三次插值算法等.
缩放的原理
例如从720P放大到1080P,乘宽均放大1080/720=1.5倍,目标图的(1,1)是原图的(0.67,0.67),而后者可通过对原图插值得到
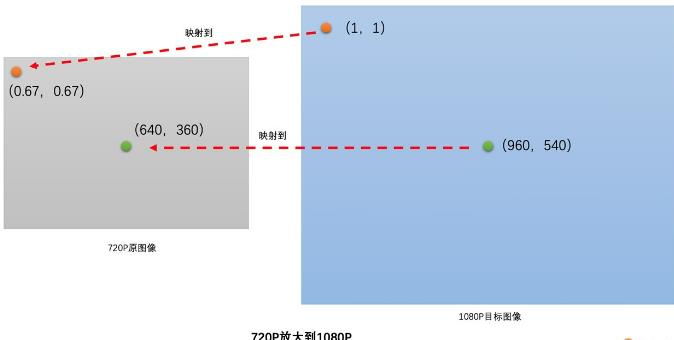
例如720P缩小到360P,长宽均缩小2倍,则目标图的(1,1)是原图的(2,2)
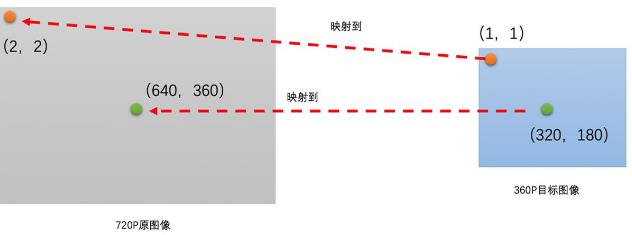
即若原图分辨率为w0*h0,需缩放到w1*h1,则将目标图像中(x,y)值映射到(x*w0/w1,y*h0/h1),在插值得到此像素值


3种插值算法
缩放和插值在RGB和YUV颜色空间均可工作,下文不会区分
最近邻插值
取周围4个像素中最近的一个, 即最近的像素点权重为1,其余3个权重为0
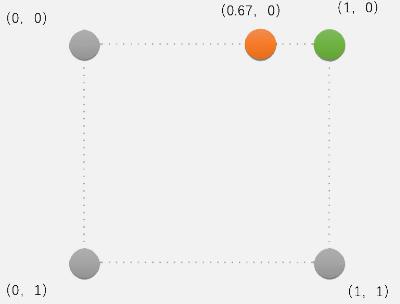
缺点:相邻的插值像素很大概率相同,如(1,0)和(2,0)的像素值相同
- 放大图像:出现块状
- 缩小图像:出现锯齿
优点:计算量很小,速度快
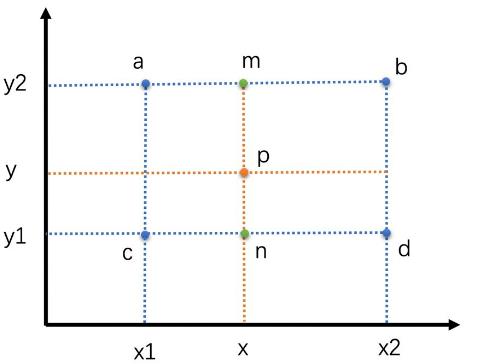
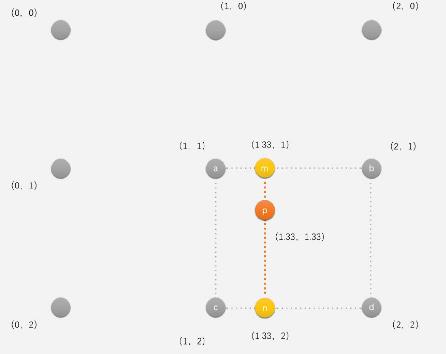
双线性插值
在两个水平方向线性插值的到m和n,再将W和H做垂直方向第三次插值得到p
即各像素以距离为权重,距离越近权重越大(即取距另一点(即距较远点的距离)为比例的分子),距离越远权重越小(即取距另一点(即距较近点距离)为比例的分子)

双三次插值(BiCubic插值)
取周围16个像素点的加权平均
基于BiCubic基函数(如下)

例如对P(1.33,1.33),对周围16个点求出16个像素值*水平权重*垂直权重,然后将16个值取算数平均.
如下例分别对(0,0),(1,2),(3,3)的水平权重和垂直权重如下



若原图中的边角像素太小(如0.5,0.5)直接用边角像素即可,不需要再插值了
视频编码
可节省存储,如1080P的电影,视频中的图常用YUV存储,帧率25fps,时长2h,若不压缩则需(1920*1080)*1.5的YUVbit*25fps*(2*3600s)=260GB
图像分为一个个宏块来编码,一般为16*16(H264,VP8),32*32(H265,Vp9),64*64(H265,VP9,AV1),128*128(AV1)
图像有数据冗余,包括如下4种
- 空间冗余:相邻
宏块的相似 - 时间冗余:帧间相似性,如若25fps则40ms就有一帧,帧间图像变化下
- 视觉冗余:人员对图像的高频信息不敏感,可移除
- 信息熵冗余:用压缩算法的方式(如zip等),使减熵
对YUV图像,以H264为例,划分为若干16*16的宏块,Y,U,V分量的大小分别为16*16,8*8,8*8,只对Y分量分析,若Y分量的16*16个像素是一个个数字,则从左上角开始之字形扫描个像素值,则可得像素串,如下

因为aaaabbbccccc可通过行程编码压缩为4a3c5b
而abcdabcdabcd可通过行程编码压缩为1a1b1c1d1a1b1c1d1a1b1c1d,为了避免此情况,需找到连续像素串,尤其最好是一串数字很小的像素串(如一串0,因为0仅需1bit存储)
那么如何将这个像素串变为有很多0的像素串呢?
减少空间冗余
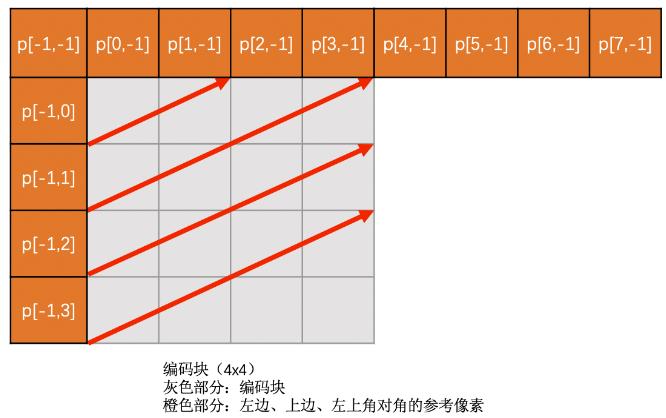
一般将编码块的左边块,上边块,左上角块,右上角块,通过将这些与编码块相邻的块通过算法得到预测块,然后将编码块与预测块做diff得到残差块,这样残差块中各像素绝对值更小(更接近0),存储占用更小.
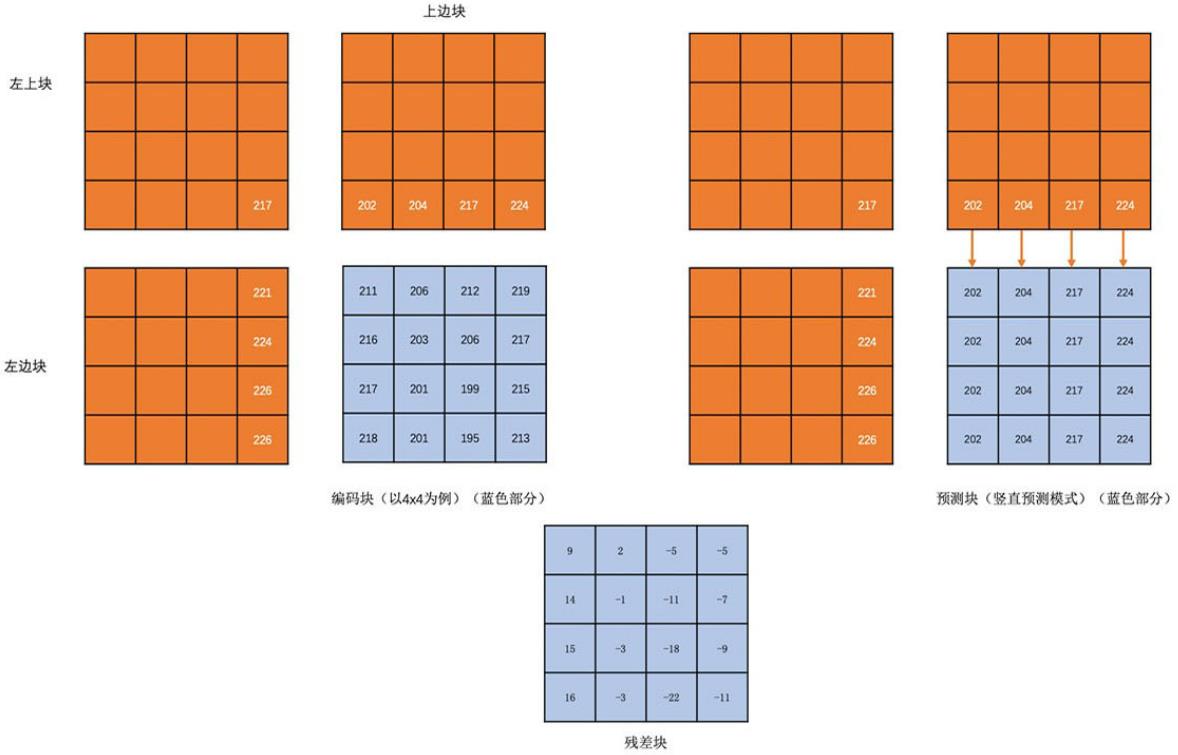
减少时间冗余
帧间预测是指,预测块所在的帧称为参考帧,预测块在参考帧的坐标值(x0,y0),与编码块在编码帧的坐标值(x1,y1),的差值(x0-x1,y0-y1)为运动矢量的残差块.在参考帧中找预测块的过程称为运动搜索.
总之, 通过时空冗余信息移除,得到的像素值更小,做行程编码更容易有高压缩率.
I帧只能镇内预测(因为I帧需要能自己独立编解码,若用帧间预测就有依赖了);B帧和P帧即可帧内也可帧间预测.
减少人眼视觉高频信息冗余: DCT变换和量化
为了分离图像的高频和低频信息,需将图像变换到频域,常用DCT变换(即离散余弦变换).在H264中,一个宏块MB为16*16(从图像的从左到右,从上到下,),我们常将其划分为16个4*4的块,然后对每个4*4的块做DCT变换得到相应的4*4的变换块.
即滤波器组由若干滤波器组成,各滤波器大小相同(如3*3,5*5或7*7的大小),各滤波器内部内容不同,左上角为低通(留下低频)滤波器,其余为高通(留下高频)滤波器(占大部分).
滤波后可仅留下低频或仅留下高频信息,的结果如下图
其中低通滤波器结果如下

其中高通滤波器结果如下

从人对原图的直观感受来看: 图像灰度变化越大的像素点,越高频(如轮廓);反之越低频(如目标内部).
低频表示图像总体样貌(一般值较大),高频表示图像中人或物的轮廓等变化剧烈之处(高频系数数量较多,但数值一般较小).下图黄色为低频,绿色为高频
量化:是指可去除大部分高频信息(即置为0),在不影响人观感的情况下,得到一连串0像素.
将变换块的系数同时除以一个值,此值即为量化步长(即编码器内部概念QStep或与之可映射的量化参数QP),得到的结果为量化后的系数.QStep越大,量化后的系数越小.且相同的QStep值,高频系数比低频系数值更小,使更容易变为0. 这样可使大部分高频系数变为0,如下图
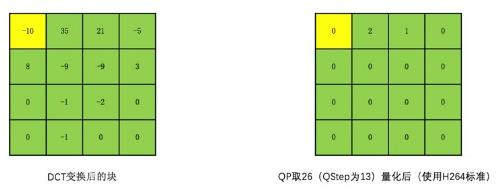
解码时,我们会将QStep乘以量化后的系数,得到变换系数(即经过量化算出的原图值);很明显变换系数和原图未经量化的变换系数不同,即有损编码. 其中QStep越大则损失越大. 而因为QStep和QP有映射, 即从编码器应用的角度看,QP越大,损失越大,画面清晰度越低;同时QP越大,被量化成0的概率越大,编码后的码流就越小,压缩就越高.
视频编码原理
目标是在熵编码时压缩率更高,希望输入到熵编码(以行程编码为例)的像素串,是一串有很多0,且最好连续为0的像素串.
为了达到此目标
- 先通过帧内预测与帧间预测去除时空冗余,得到像素值比
编码块小很多的残差块. - 再通过DCT变换,将低频与高频分离,得到变换块
- 再对变换块的系数做量化. (因为高频系数通常较小,很容易量化为0,且人眼对高频信息并不敏感)
- 故最终我们得到一串很多0,且多数情况是一串连续0的像素串,且人观感不太明显.这样
熵编码可把图像压缩为较小的数据.
编码器对比
编码标准:H264,VP8是目前主流;H265,VP9是下一代标准,AV1是VP9的下一代标准.
其中H264,H265需专利费,而VP8,VP9,AV1免费
普通产品用H264最多,WebRTC用VP8多(也支持VP9,AV1)
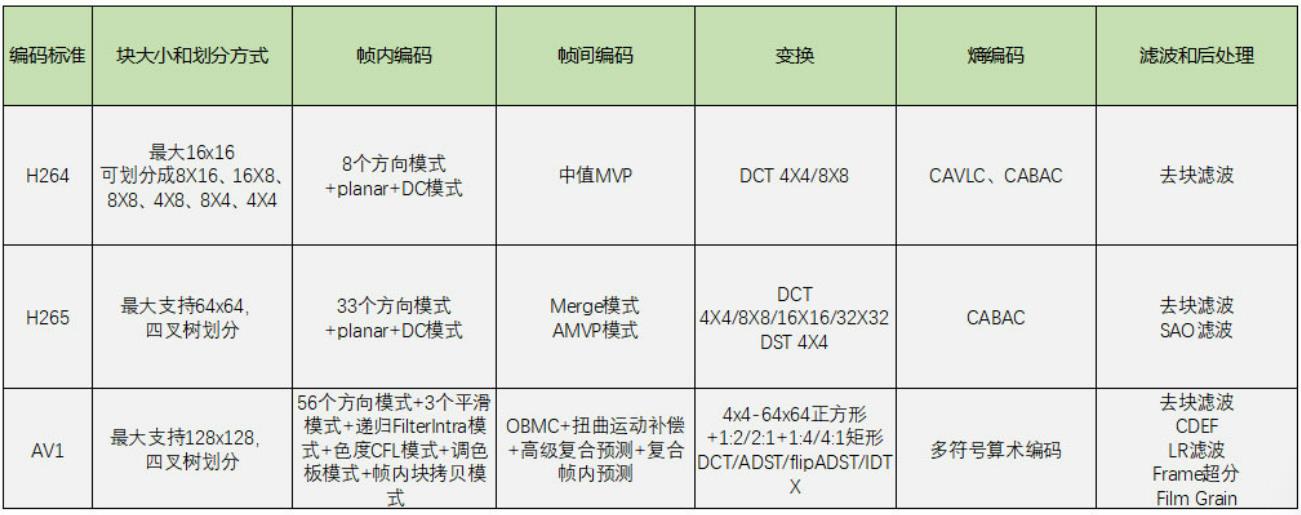
标准越新,编码块越大,块划分方式越多,编码模式越多,压缩效率越高,但编码耗时越大.

目前支持H264,H265的硬件非常多了,AV1才刚开始
若在较差的机器编码,可用H264或VP8等速度快的编码器
若在较新机器可选H265;但H265需专利费且browser不原生支持H265,故不建议选择H265,而建议选择VP9,甚至AV1.
码流结构-以H264为例
一般用VQAnalyzer工具分析H264字段
其实就是看编码后的二进制数据怎么组织,即哪一块是一帧图像,哪一块是另一帧图像,每帧图像开头结尾是什么.
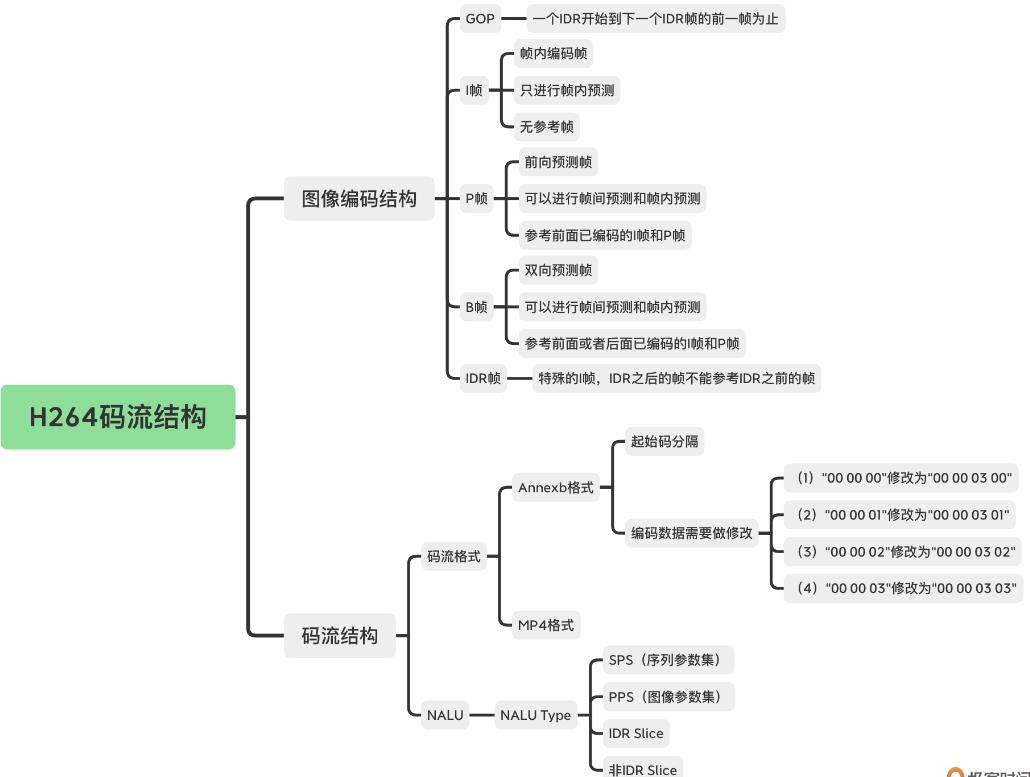
帧类型
帧间预测,依赖于其他帧.
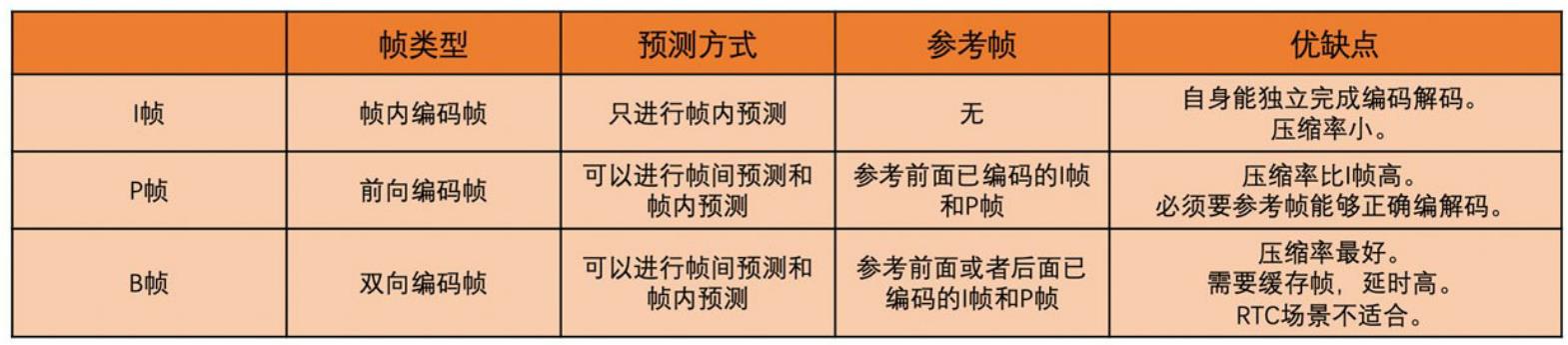
如下图,从左向右,第一个B帧参考第一个I帧和第一个P帧,第一个P帧只参考第一个I帧
因为P帧或B帧需要参考其他帧,若编码中有一个参考帧出现错误的话,则依赖它的P帧和B帧也会出错,而这些有问题的P帧(B帧实际情况作为参考帧较少,暂不讨论)又会作为之后P帧或B帧的参考帧,即错误会不断传递,为避免这种情况,有特殊的I帧:IDR帧,也叫立即刷新帧.
因H264规定,IDR帧之后的帧,不能再参考IDR帧之前的帧,故若I帧正确则可截断编码错误的传递,使之后的帧可正常编解码.
I帧分为普通I帧和IDR帧,但实际多数情况均用IDR帧.
GOP
GOP(图像组):从一个IDR帧到下一个IDR帧之间(此距离称为关键帧间隔),包含的IDR帧,普通I帧,P帧,B帧

GOP若太大,可能会在RTC场景因网络丢包而使接收端丢帧,使丢失IDR帧而解码错误,引起长时间花屏/卡顿.
GOP若太小,码率会变大.
一般RTC场景设置大,而点播场景设置小.
Slice
将一帧图像分为几个slice(每个slice分为若干16*16MB的宏块)(每个宏块可细分为不同大小的子块),各slice间独立不依赖,可并行对多个slice同时编码.
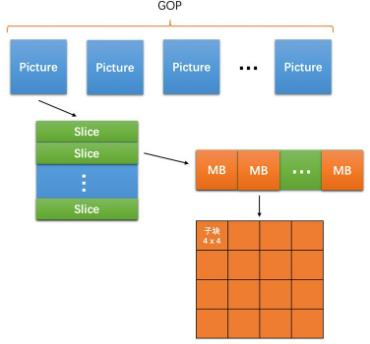
H264码流结构
码流格式
有Annexb和MP4两种
- Annexb
以4byte的00 00 00 01或3byte的00 00 01为起始码;
会将数据内容的00 00 00改为00 00 03 00
会将数据内容的00 00 01改为00 00 03 01
会将数据内容的00 00 02改为00 00 03 02
会将数据内容的00 00 03改为00 00 03 03
以防止和起始码冲突.
解码端去掉起始码后,也要将上述转换再转换回来.

- MP4dl
无起始码,用4byte做长度标识

NALU
两者码流格式差别不大,下文已Annexb格式来讲解H264码流中的NALU
视频码流中,除了I,P,B帧(以Slice形式呈现)之外,还有通用的编码参数,分为SPS序数参数集(含图像宽,高,YUV格式,位深)和PPS图像参数集(含熵编码类型,基础QP,最大参考帧数量)两种.
故H264码流如下

H264有NALU(网络抽象层单元),SPS是一个NALU,PPS是一个NALU,每个Slice也是一个NALU.每个NALU由1byte的NALU Header和若干byte的NALU Data(又由Slice Header和Slice Data(又由若干MB Data组成)组成)组成.
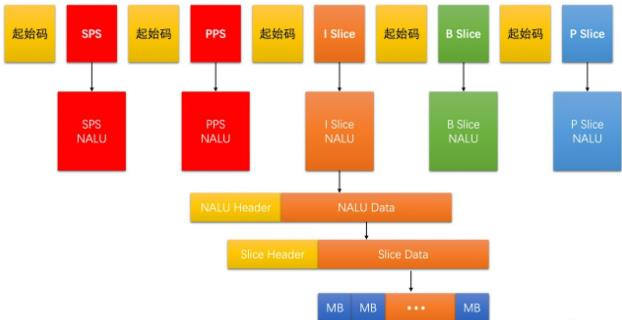
NALU Header共1byte,如下
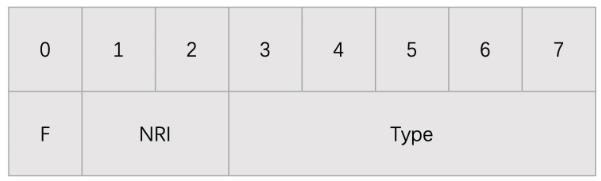
F:1bit,必须为0
NRI:2bit,可取00~11,表示当前NALU的重要性,IDR,SPS,PPS必须>0
Type:5bit,表示NALU的类型,仅区分了IDR与非IDR帧

具体的I或B或P帧类型,在Slice Header中的Slice Type可解析得到.

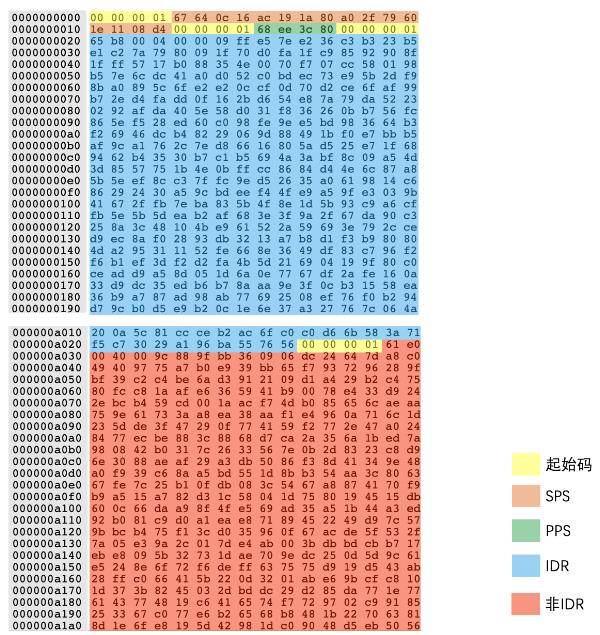
下面是实际码流例子
多slice时如何判断拿几个slice是同一帧?

Slice Heder的first_mb_in_slice表示当前Slice的第一个宏块MB在当前编码图像中的序号
- 若=0,则
当前Slice的第一个宏块是一帧的第一个宏块,即当前Slice是一帧的第一个Slice - 若!=0,则代表
此Slice不是一帧的第一个Slice,继续用同样方式向后找,知道=0为止就代表新的一帧开始了. - 可通过
SliceHeader[0] & 0x80 == 1,判断first_mb_in_slice==0
如何从SPS中获取图像宽高
编码端需要通过设置分辨率,告诉编码器:图像的宽高
解码器部不需要设置分辨率,可从SPS中计算得出如下指标
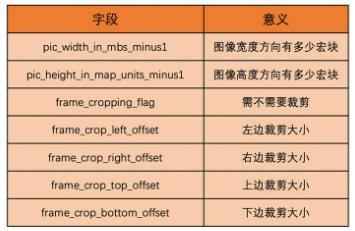
并按如下公式算出分辨率

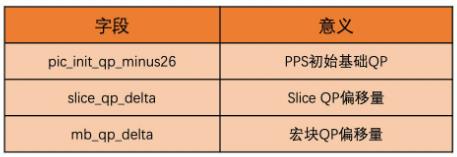
如何得到PQ值
PPS中有全局基础QP(字段是pic_init_qu_minux26),当前序列中所有依赖该PPS的Slice共用此基础QP,各Slice在此基础上用Slice Header中的slice_qp_delta字段调整偏移值. H264允许在宏块级别对QP做进一步精细化调节.

帧内预测
帧内,相邻像素的亮度色度相近,且是逐渐变化而不会突变,故有空间相关性.
我们通过已编码的像素值解码重建成重建像素来做参考像素,再去预测待编码的像素值
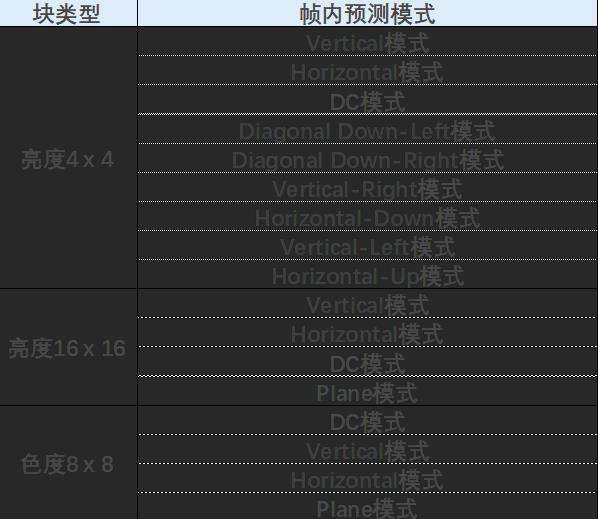
不同块大小的帧内预测模式
H264的宏块为16*16,YUV4:2:0的亮度块为16*16(可继续划分为16个4*4的子块), 色度块为8*8,亮度块和色度快是分开独立预测的(即亮度块参考已编码亮度块的像素,色度块参考已编码色度块的像素).
所以实际帧内预测时,分为如下3种:4*4亮度块预测,16*16亮度块预测,8*8色度块预测
4*4亮度块的帧内预测
有8种方向模式和1种DC模式
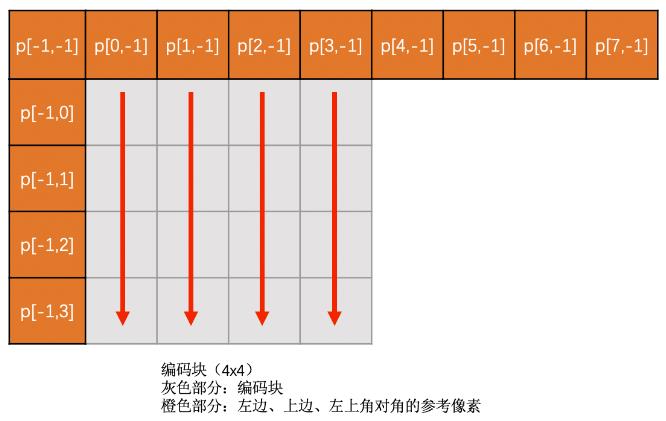
- Vertical模式
当前编码亮度块的各列像素值,都是复制上边已编码块的最下面一行的对应位置的像素值.
得到的预测块同一列的像素值相同
只有在上边块存在时,此模式才可用

-
Horizontal模式

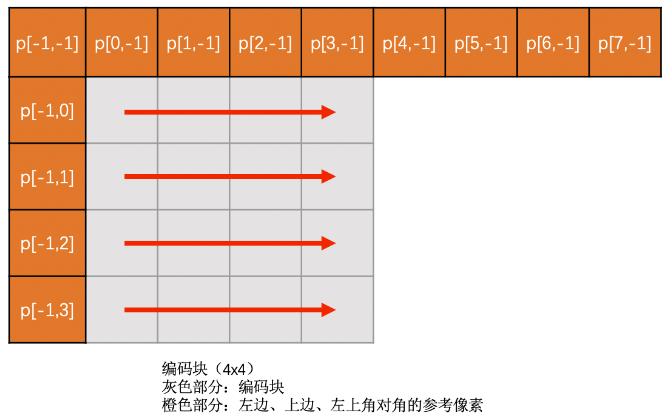
-
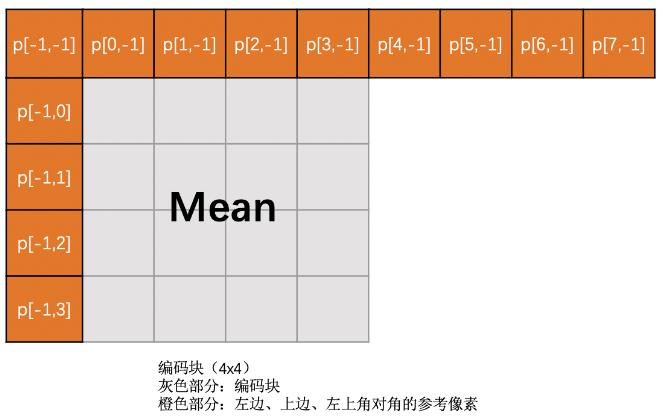
DC模式
当前编码块的各像素值,是上边已编码块的最下面那一行和左边已编码块右边最后一列的所有像素值的平均值.
即DC预测块内各像素值都相同

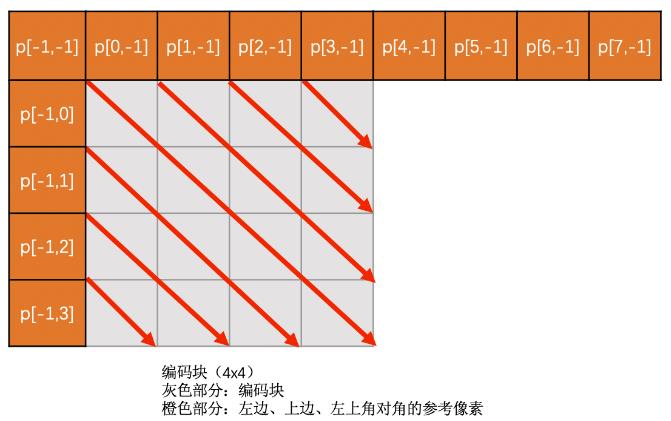
- Diagonal Down-Left
上边块和右边块的像素通过插值得到,若上边块和右边块不存在则该模式无效


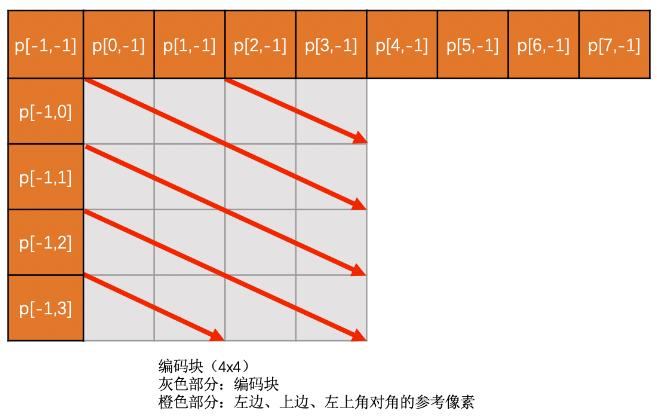
- Diagonal Dwon-Right
上边块,左边块,左上角对角的像素通过插值得到,若此三者有一个不存在则该模式无效

- Vertical-Right
上边块,左边块,左上角对角的像素插值得到,若此三者有一个不存在则该模式无效


- Horizontal-Down
上边块,左边块,左上角对角,插值
- Vertical-Left
上边块,右边块最下面一行,插值

- Horizontal-Up
左边块插值
16*16亮度块的帧内预测
Vertical,Horizontal,DC,Plane4种模式
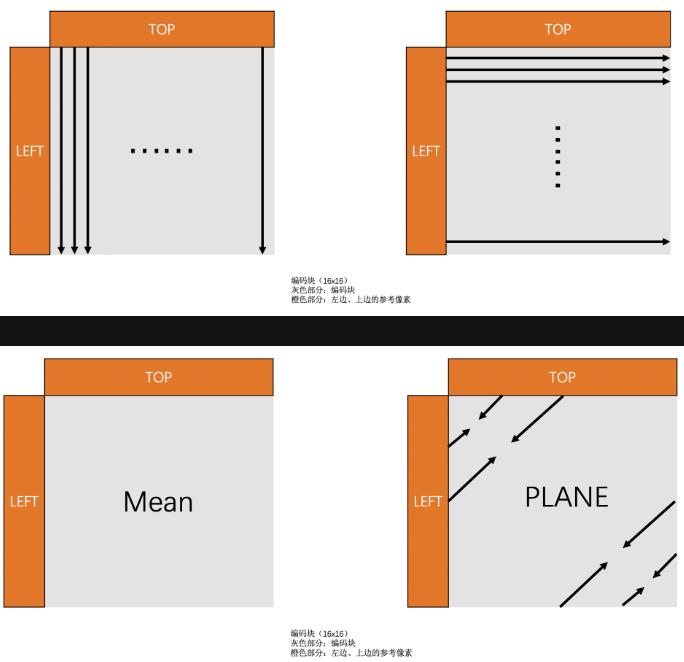
其中前三种和4*4亮度块预测类似,Plane预测块的各像素值都是将上边预测块的最下面一行,和左边已编码块最右边一列,计算得到
8*8色度块帧内预测
Vertical,Horizontal,DC,Plane4种模式
帧内预测模式的选择
这是编码器的内部实现机制,总体思路如下
对1个16*16块,用4种16*16预测模式,和9种4*4预测模式,计算出预测块,和实际待编码块相减得到残差块,由如下3种方案比较得到最优预测模式
- 残差块各像素值绝对值之和(称为cost),最小即最优
- 对残差块做Hadamard变换,变换到频域后再求绝对值之和(称为cost),最小即最优
- 对残差块做DCT变化量化熵编码,得到
失真大小和编码后的码流大小,通过率失真优化(一般会使QP值适中,在失真和码流大小间平衡,找到一定码率下,失真最小的模式,作为最优预测模式)来选择最优模式
H264标准中, 视频的第一帧的第一个块的左和上都是空,没法预测,所以设置成了一个约定值128,方便编码。这边找个几个264的码流,第一个I帧的第一个4*4 子块的yuv 预测值全都是128
帧间预测
可有单个或多个参考帧,本文以单参考帧为例,且以P帧为例
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2GVXQZ8W-1666778673995)(https://note.youdao.com/yws/res/125526/WEBRESOURCEe3f043ea5dfa18287b759122bd1016e0)]
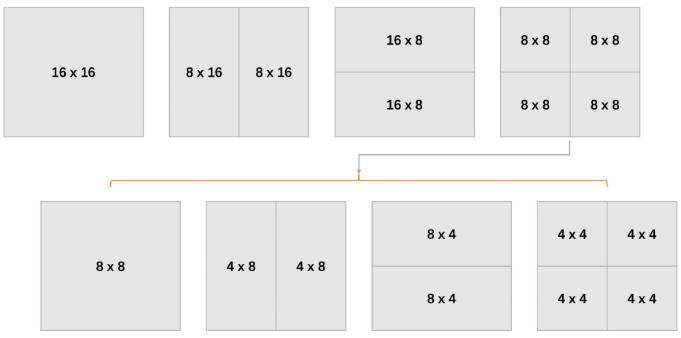
块大小
多种块划分类型,如下
YUV4:2:0中色度块宽高都是亮度块的一半
参考帧和运动矢量
一般RTC场景,P帧所有块都参考同一个参考帧,且会根据当前编码帧的前一帧做参考(因为和前一帧的像素变化是最小的,用运动矢量表示位置变化)

从(32,80)移动到(80,80),我们将运动矢量(-48,0)编码到码流中,解码时解出运动矢量,即可在参考帧中找到预测块,再解码出残差,恢复出的图像块=残差块+预测块
虽然人眼可看出上图中小车在两幅图中的位置,并找到相似块作为预测块,但编码器怎么找到预测块呢?它又没有眼镜,这就通过运动搜索实现.
运动搜索
在参考帧中找到一个块(称为预测块),使和编码块的差距(可用残差块的像素绝对值之和表示,称为SAD)最小.
- 全搜索算法: 比如当前编码块为
16*16,则我们去参考帧中找若干16*16的块得到若干残差块,选残差块最小的.
搜索算法中,每个搜索的点,都是搜索块左上角像素点.
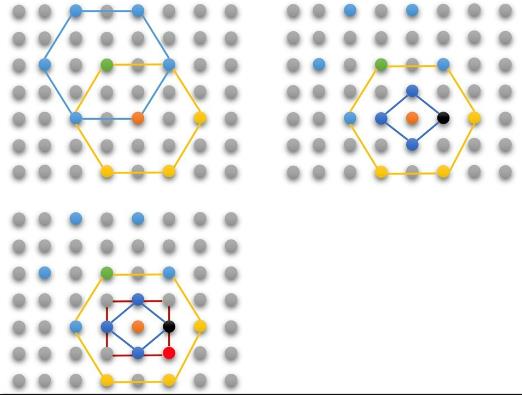
钻石(菱形)搜索算法
以菱形模式寻找, 以起始点为菱形中心点, 将该中心点左上角的16*16块作为预测块,求残差块的SAD;
并对菱形4个角做同样操作,得到SAD
5个点中,最小的SAD值对应的就是当前最佳匹配点
若当前最佳匹配点为菱形中心点则结束;若反之则以当前最佳匹配点位中心继续搜索直到找到为止.
如下图,以绿点(起点)为中心点,和旁边菱形4点相比,得到最佳匹配点位橙点,因非中心点故继续
再以橙点为中心,搜旁边菱形4点,得到最佳匹配点为橙点,因为是中心点故搜索完毕

六边形搜索算法
若最佳匹配点为六边形中点,则以该点为中心的菱形和正方形,各进行一次精细化搜索,找到中心点,菱形的4个顶点,正方形的4个顶点这9个点中SAD值最小的点为最佳匹配点.
亚像素插值
为了解决残差块有零头像素的问题,使残差块!=0,使压缩效率不完美而引入的方案
如下图运动矢量出来是(-48.25,0),但只能表示为(-48,0),故解码时通过运动矢量与I帧算出的预测帧有偏差,就是为了解决此问题引入的方案.
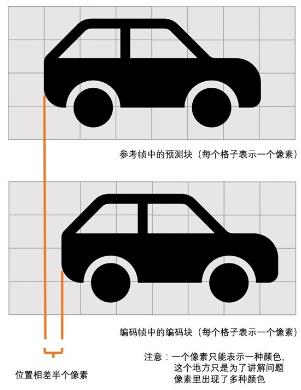
如下图,整像素插值得到半像素,半像素插值得到1/4像素,下图灰色为整像素,黄色为水平半像素,橙色为垂直半像素,绿色为中心半像素
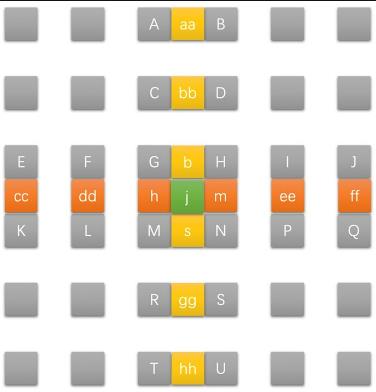
红色为1/4像素点
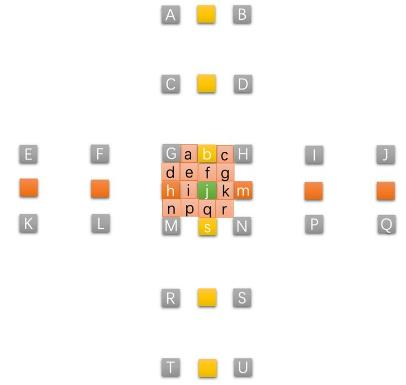
这样就可表示上文提到的(-48,25,0)的运动矢量了,就可在解码时得到正确精确的预测位置
实际上,我们用整像素运动搜索完毕后, 再做一次亚像素精度运动搜索,得到最佳整像素运动矢量(a0,b0),最佳半像素运动矢量(a1,b1),最佳1/4像素运动矢量(a2,b2),则最终的运动矢量(a,b)计算公式如下

即(a,b)=4(a0,b0)+2(a1,b1)+(a2,b2)
运动矢量预测算法和编码
运动矢量不是直接像编码块一样编码到码流的,而是先用周围相邻运动矢量预测出预测运动矢量(称为MVP),将当前运动矢量与MVP的残差称为MVD,然后编码到码流的
解码端,用同样的运动矢量预测算法得到MVP,从码流中解码出运动矢量残差MVD,则MVP+MVD可得运动矢量.
运动矢量预测算法步骤如下

特殊的帧间模式:SKIP模式
若运动矢量MVP对应的MVD为(0,0)且残差块都为0,则当前编码块模式为SKIP,则压缩率特别高
如P帧的静止部分,前后两帧无变化,则运动矢量直接为0,而且残差块像素值本身因为无变化而基本为0,只有少部分噪声引起的较小的值(且经过量化后都变为了0),那么这种该图像中的静止部分,或图像中的背景部分大多数时候都是SKIP模式.
帧间模式的选择
包括参考帧的选择,运动矢量的确定,块大小的选择,是否为SKIP模式的判断,共4个部分
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l6HKEL4Z-1666778674004)(https://note.youdao.com/yws/res/125522/WEBRESOURCEb7c201e5b105e42bcbaa9407ff639d87)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GAWZ9z9a-1666778674005)(https://note.youdao.com/yws/res/125524/WEBRESOURCEf7279aff9ed00f33c81d3e2b50297924)]
高频视觉冗余
通过DCT变换和量化可去除视觉冗余
常规视频编码中的DCT变换和量化
DCT变换
- DCT变换: 即离散余弦变换, 可将空域信号(即肉眼可见的图)转为频域(即数据), 并可较好的去除相关性. 视频压缩算法基本都用含此步骤.
- 图片经DCT变换,低频信息集中在左上角,高频信息分散在其他位置.
- 通常图片的高频信息多但幅值小,主要描述图片边缘信息.
- 因人眼对高频信息不敏感, 故可将图片经DCT变换到频域后,移除部分高频信息,从而压缩图片信息量.
DCT变换是无损,可逆的. 可将图片从空域经DCT变换到频域, 也可将频域经DCT反变换到空域. - 一维DCT变换公式如下:其中
f(i)为第i个样点的信号值,N为信号样点的总个数

- 二维DCT变换公式如下:其中
f(i,j)为第(i,j)位置的样点的信号值,N为信号样点的总个数

图像是二维信号,需用二维DCT变换的,实际编码经常用两个一维DCT变换代替.
因先经过帧内预测,帧间预测,得到了残差块, 再经过DCT变换.
宏块是16*16(如下图),而DCT变换通常宏块的在4*4子块上进行, 其可用如下公式表示

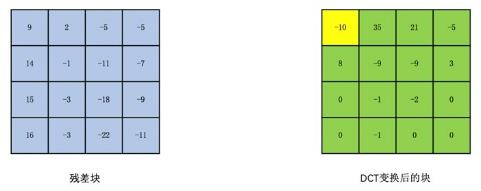
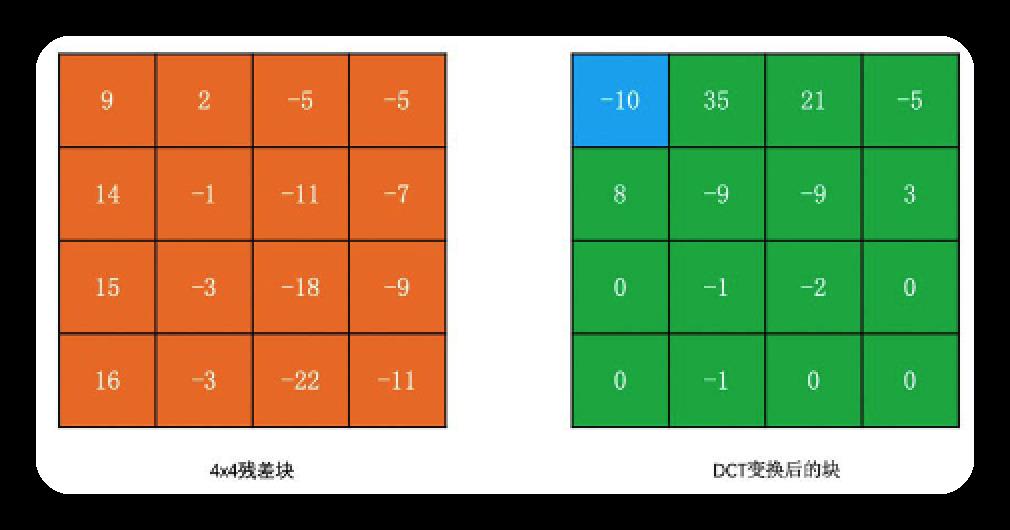
下例以4*4的残差块子块为例看DCT变换的过程,我们称左上角为DC系数,其他为AC系数
残差块如下

对此残差块用公式如下

DCT变换的结果如下
Hadamard变换
从DCT变化公式可知用了cos函数,即涉及浮点运算,而浮点运算较慢.
故一般通过Hadamard变换提升计算性能, 其公式如下

量化
量化: 将图像变到频域后,对AC系数和DC系数都量化,因AC系数较多但幅值较小, 故AC系数更大概率变为0,故可去除一些AC系数,使图像被压缩.
公式如下

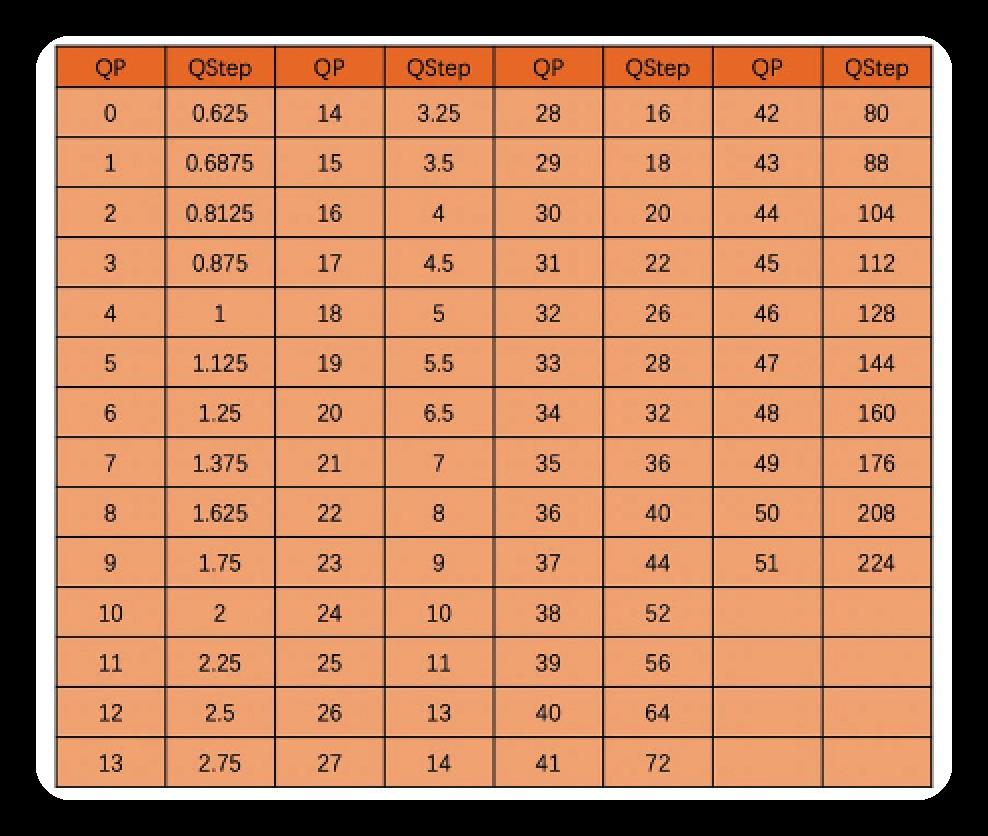
量化过程中,最重要的是QStep(可和用户一般用的QP一一映射,H264的QP和QStep映射表如下)
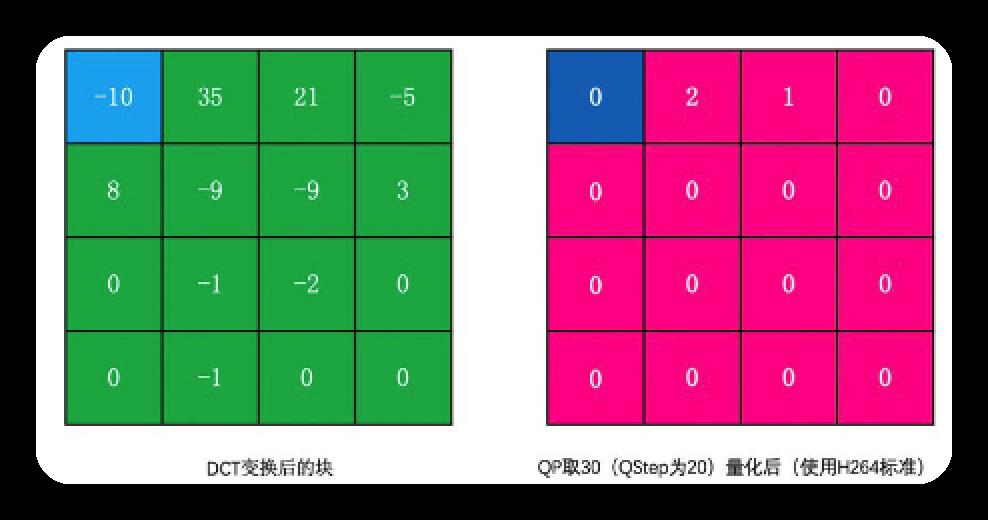
通常QStep若大,则AC系数和DC系数被量化为0的概率越大,则压缩率越高,信息丢失越多;
- 若太大则有一个个块状效应,严重时像马赛克
- 若太小则压缩率小,码流大
例子如下
H264中的DCT变换和量化
H264为了减少在不同机器上浮点运算的漂移误差, 将DCT变换改为整数变换, 将DCT变换中的浮点运算与量化两个过程合并, 这样只有一次浮点运算.
常规DCT变换如下

H264中, 通过下述推导变为整数变换

只用点乘左边的公式,即得到H264的变换公式如下

用上文的残差块例子,经H264的DCT整数变换, 结果如下
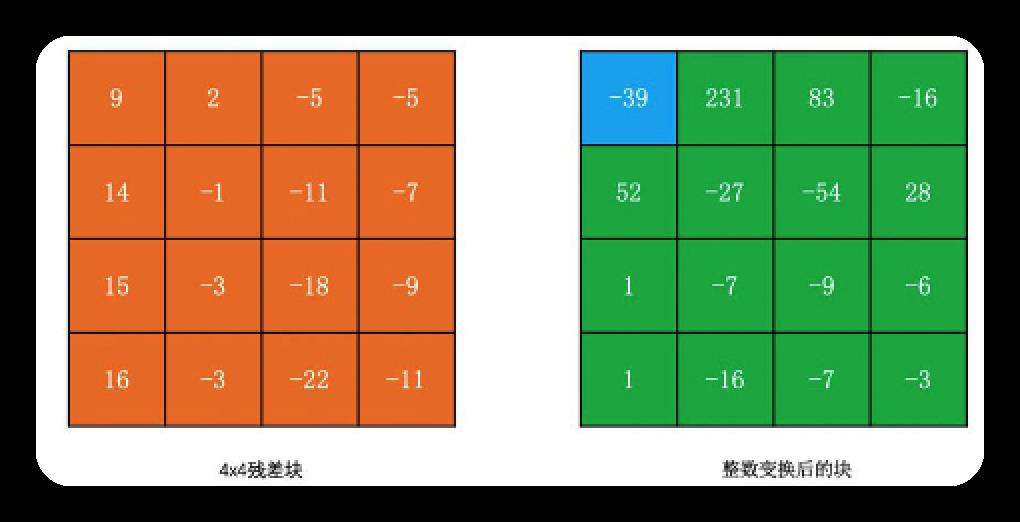
因为上述点乘右边的公式被拿出来了,故将此部分合并到H264的量化环节了

其中MF一般查表可得,表格如下. 其中QP>5时用QP=QP%6查表.
经上文整数变换后,再量化后的结果如下
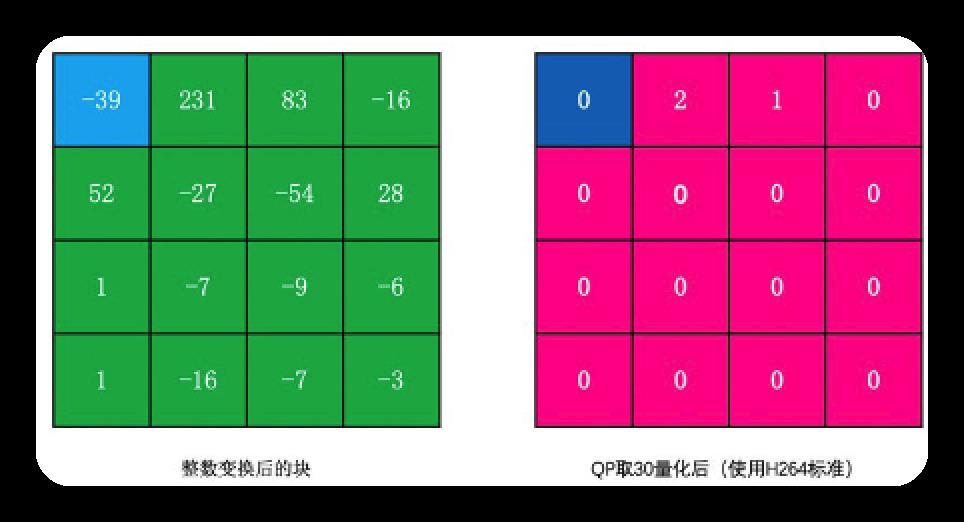
可知虽H264的DCT变换和常规DCT变换公式不同,但结果相同,符合预期.其实是实现方式不同.
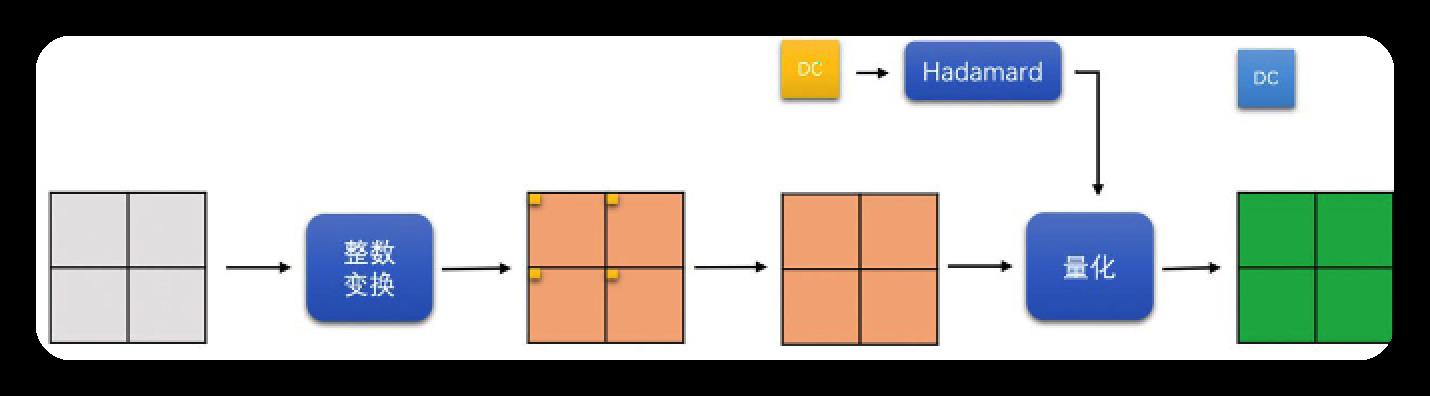
H264各模块的DCT变换和量化过程
- 亮度
16*16的帧内预测块
划分为16个4*4的小块,做整数变换,变换后将16个4*4小块的DC系数拿出来,组成1个4*4的DC块,再对此4*4的DC块做Hadamard变换, 最终再量化.
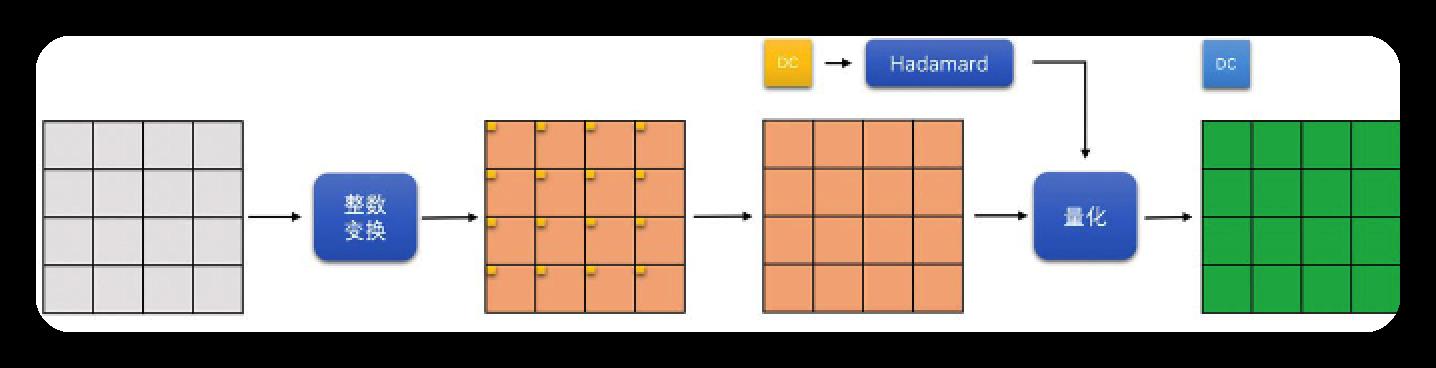
- 其他模式亮度块
除亮度16*16帧内预测块之外的其他亮度块,都直接划分为4*4的块做整数变换,再量化.
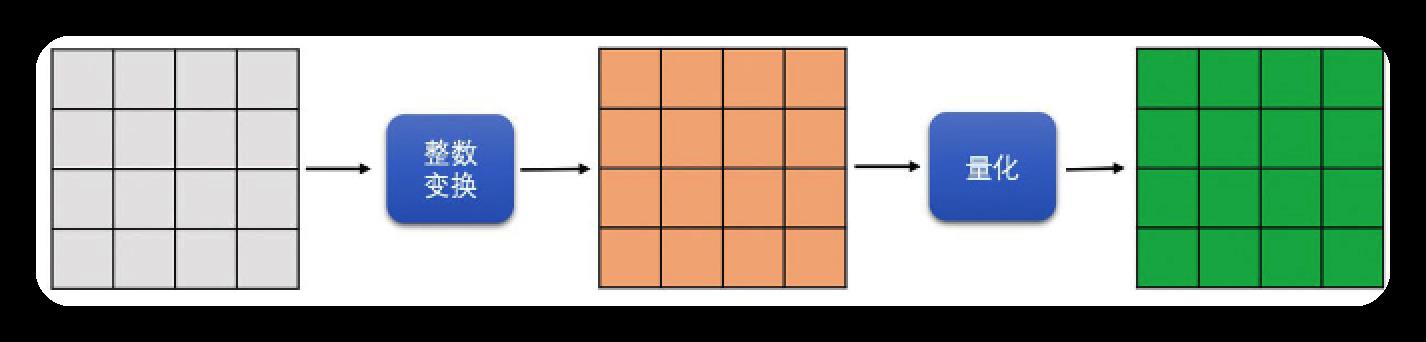
- 色度块
YUV420的图像, 色度块是8*8, 先将8*8色度块划分为4个4*4小块做整数变换, 再将变换后4个小块的DC系数拿出来, 组成2*2的DC块, 再对此2*2DC块做Hadamard变换, 再量化.
小结

RTP与RTCP网络协议
怎么把码流打包成一个个数据包,发到网络上,且在发送过程中避免网络拥塞
RTP协议
为什么要打包成RTP包, 是因为接收端解码, 不仅需要原始码流, 还需额外信息: 如使用的编码方式(H264/H265/VP8/VP9/AV1),和视频的播放速度; 且可网络带宽预测和拥塞控制.
包头如下


若只负责传输RTP包,不需要管RTP有没有丢包,不需要管是否有网络拥塞;因为若用TCP传输则其会负责丢包与拥塞.
但一般TCP适合传文本和文件,不适合音视频,故一般用UDP
为了用UDP,实现丢包和拥塞,则需要RTCP
RTCP协议
是辅助配合RTP协议的, 两者一起工作.
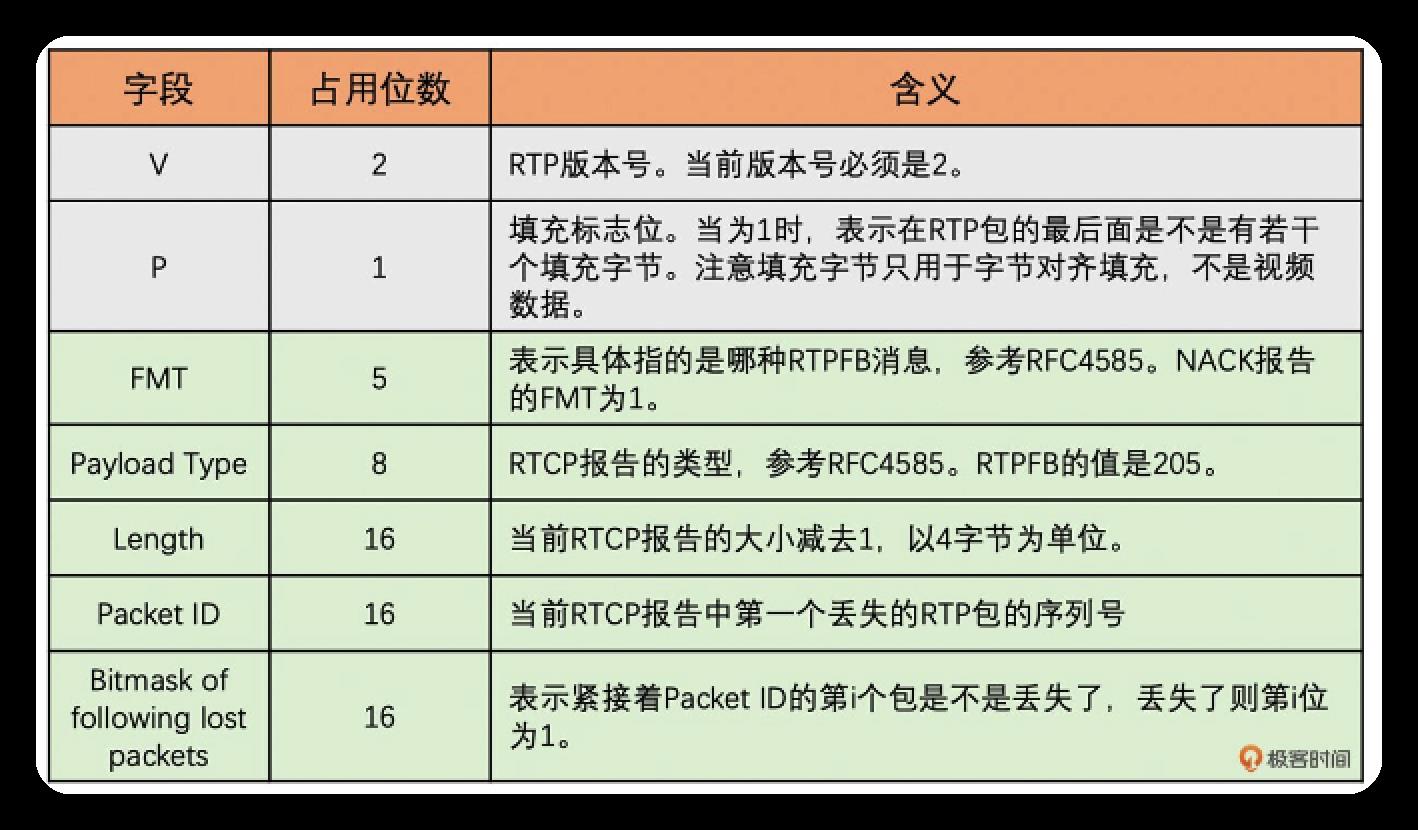
RTCP有多种报文协议:发送端报告SR,接收端报告RR,RTP反馈报告RTPFB. 每种报告的有效载荷不同, 我们通过这些报告在接收端和发送端传递当前统计的RTP包的传输情况. RTCP本身不具备丢包重传和带宽预测功能, 这些功能需我们自己实现.
下图是RTPFB报告中的NACK报告(丢包提示报告).

RTP传输视频数据, 像快递盒, 先装好视频, 在填好视频基本信息和收件人地址,最后讲视频送到收件人手里.
RTCP像统计快递运送情况的记录表, 其中的NACK报告就是快递丢件记录表, 发件人收到NACK后, 可重传一个同样的快递给收件人.
H264的RTP打包
RTP头部: 如上文所述; RTP内容: 放H264码流.
有3种方式: 单NALU封包(一个NALU打一个RTP包),组合封包(多个NALU打一个RTP包),分片封包(一个NALU分开放在连续多个RTP包).
单NALU封包

此方式适合单个RTP包小于1500Byte(MTU大小), 一般若P帧和B帧编码后较小, 适合此方式.
组合封包
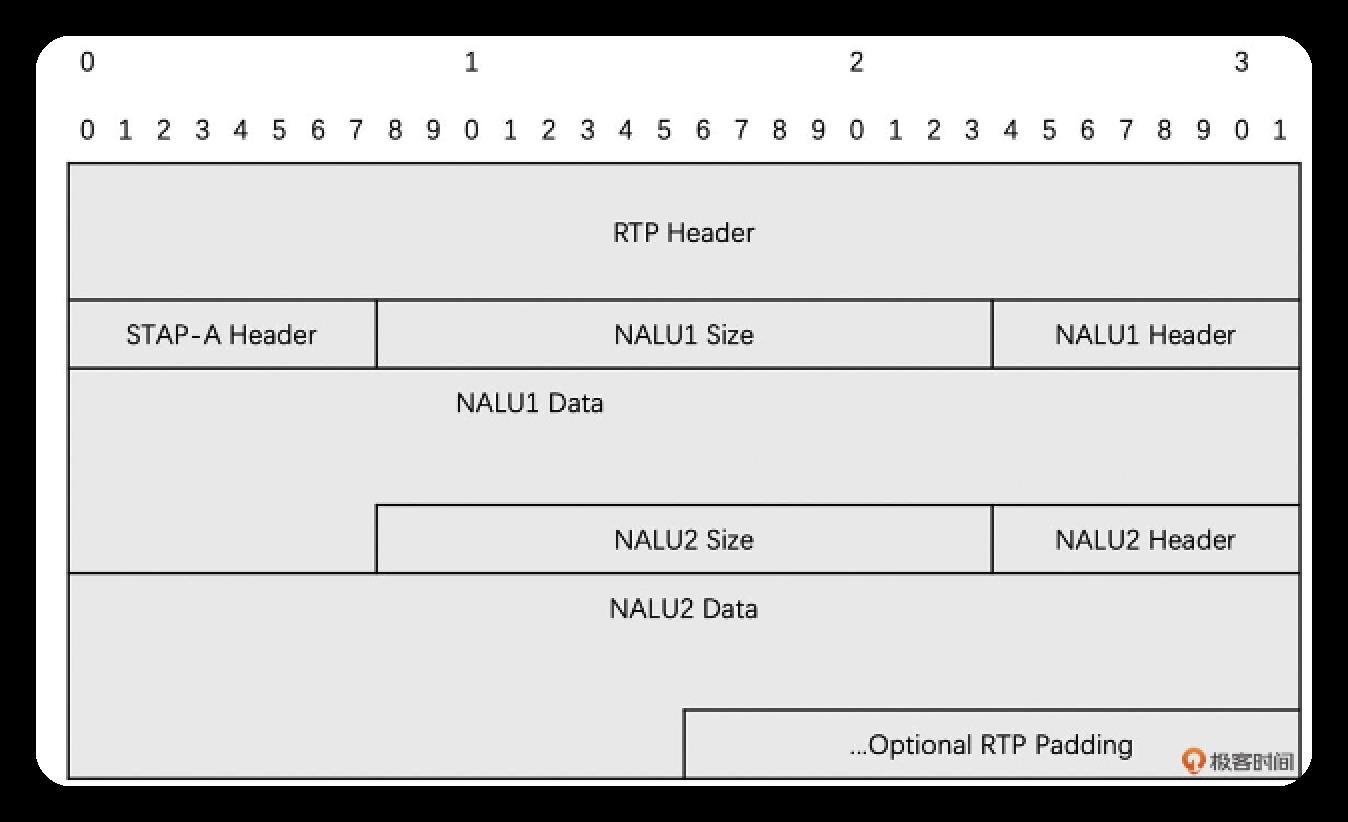
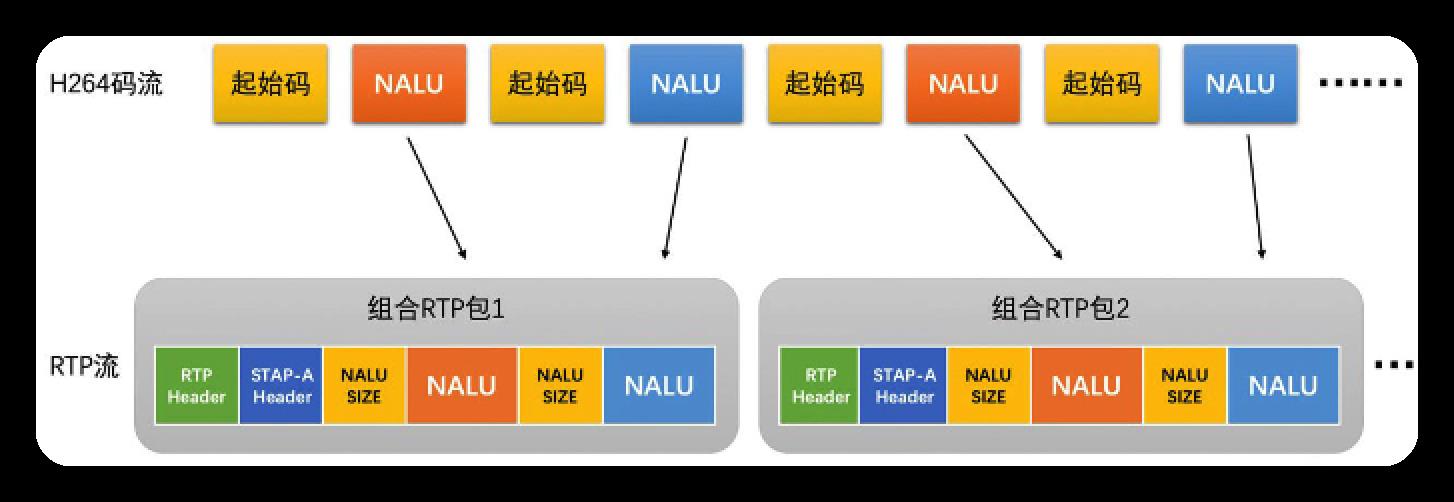
此方式适合单个NALU较小的情况,如多个NALU打包小于1500Byte时,但此情况少见.
分片封包

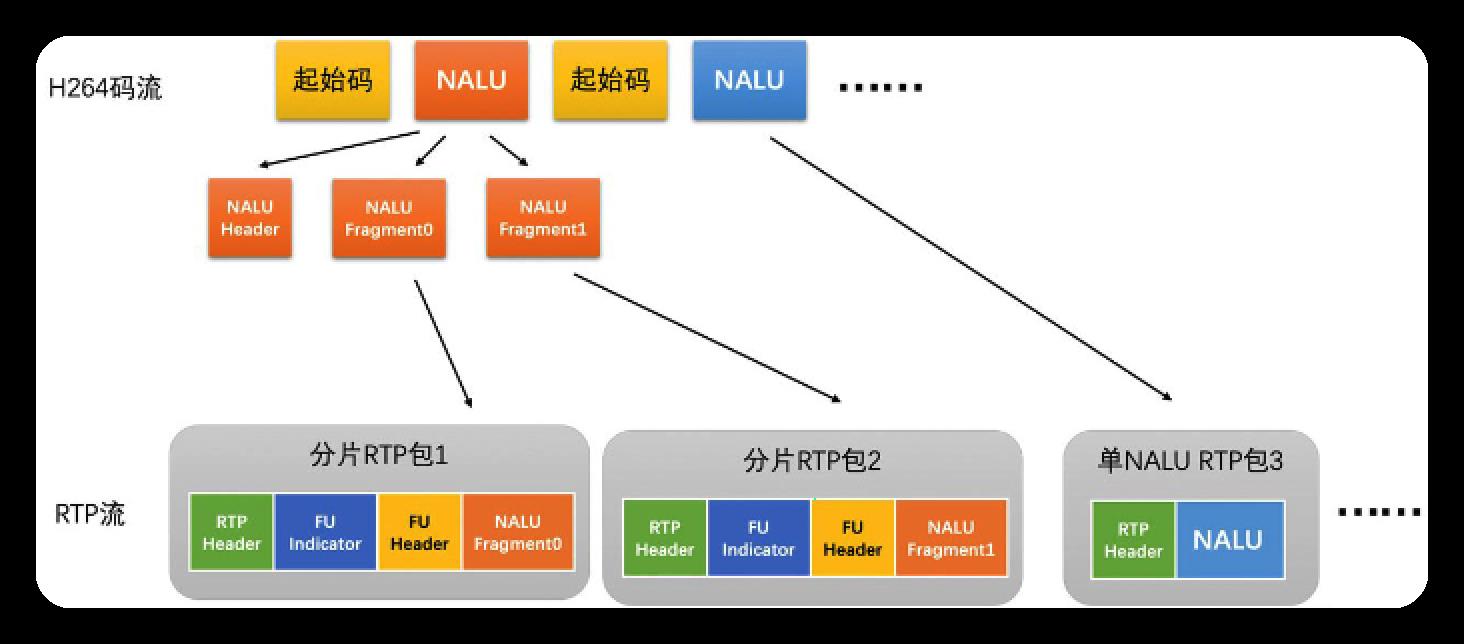
常用, 但缺点是若丢了一个片则整包数据都废弃了
一般在一个H264码流中会混合多种RTP打包方式
- 小的P帧,B帧,SPS,PPS用单个NALU封包
- 打的I帧,P帧,B帧用分片封包
带宽预测
RTP和RTCP一般都用UDP做传输层协议,故需自己实现拥塞控制算法.
预测出带宽后, 即可控制发送端的数据量, 防止因不够, 而导致的延时/丢包.
网络设备分2种:
- 缓存大的设备: 若网络带宽不足, 则后面的数据需排队等前面的数据, 延时大
- 缓存小的设备: 若网络带宽不足, 则数据会丢掉, 即丢包
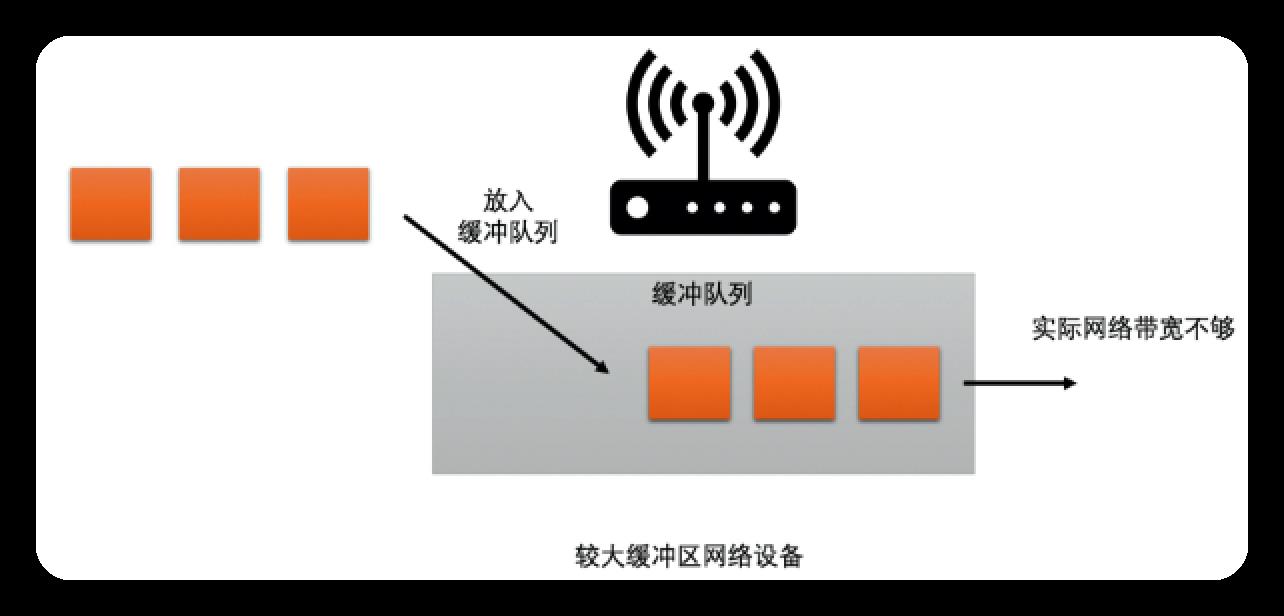
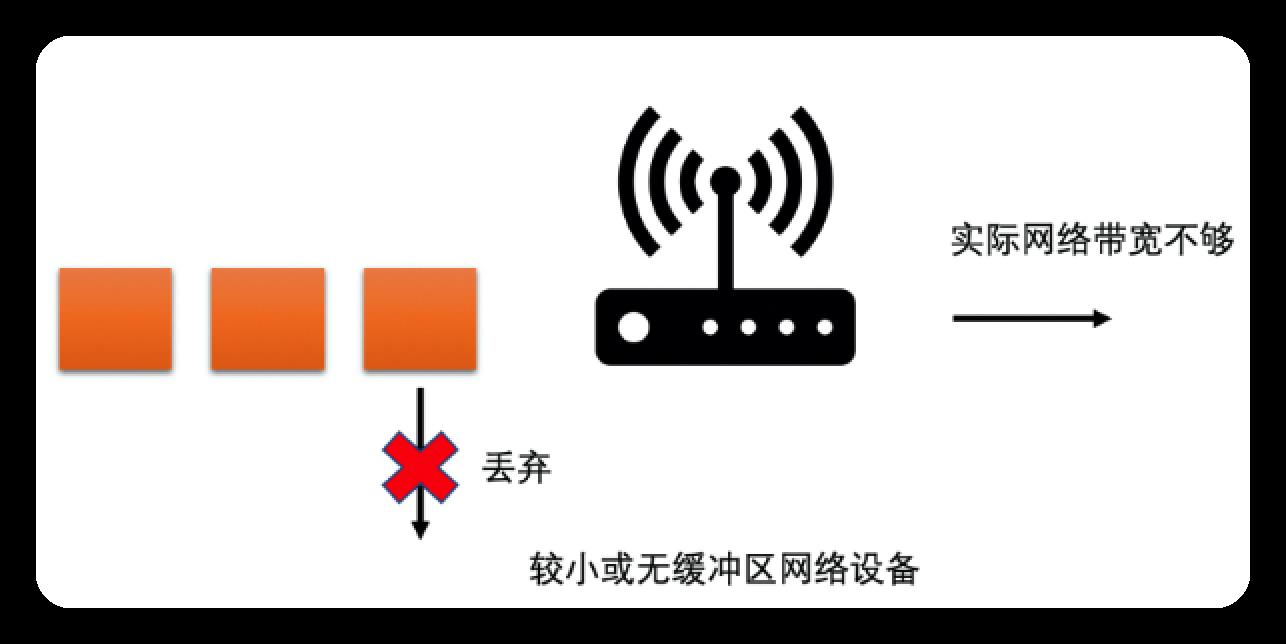
为了兼顾2种网络设备, 有2种带宽预测算法
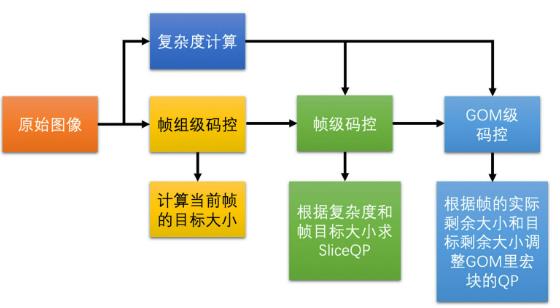
基于延时的带宽预测算法
计算一组RTP包的发送时长,接收时长,判断当前延时的变化趋势
若延时趋势逐渐变大, 则说明实际带宽<当前发送码率, 需降低预测的带宽值
若延时趋势没有变大, 则说明当前带宽良好, 则提高预测的带宽值, 知道延时明显变大后, 再降低预测的带宽值
通过如此事实调整预测值, 控制发送速率.
有如下4个步骤:

- 计算一组RTP包的发送时长,接收时长,计算延时
- 根据当前延时, 和历史延时, 计算延时变化的趋势
- 根据延时变化趋势, 判断网络状况
- 根据网络状况, 调整
预测的带宽值
计算延时
按时间分组, 每5ms为一组
因为UDP可能乱序(如先发送的包,可能后到达), 为避免负责度, 故乱序的包不参与计算
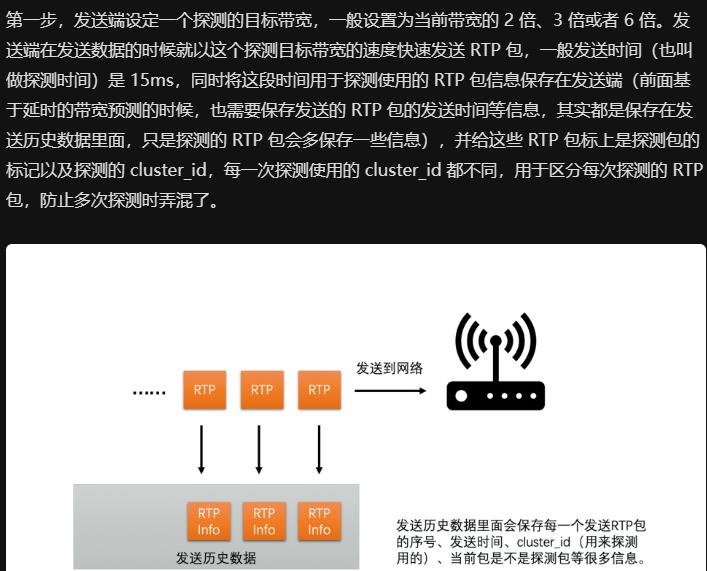
发送端每发送一个RTP包, 就记录一个包的序号和实际发送时间, 把这些信息记录到发送历史数据中
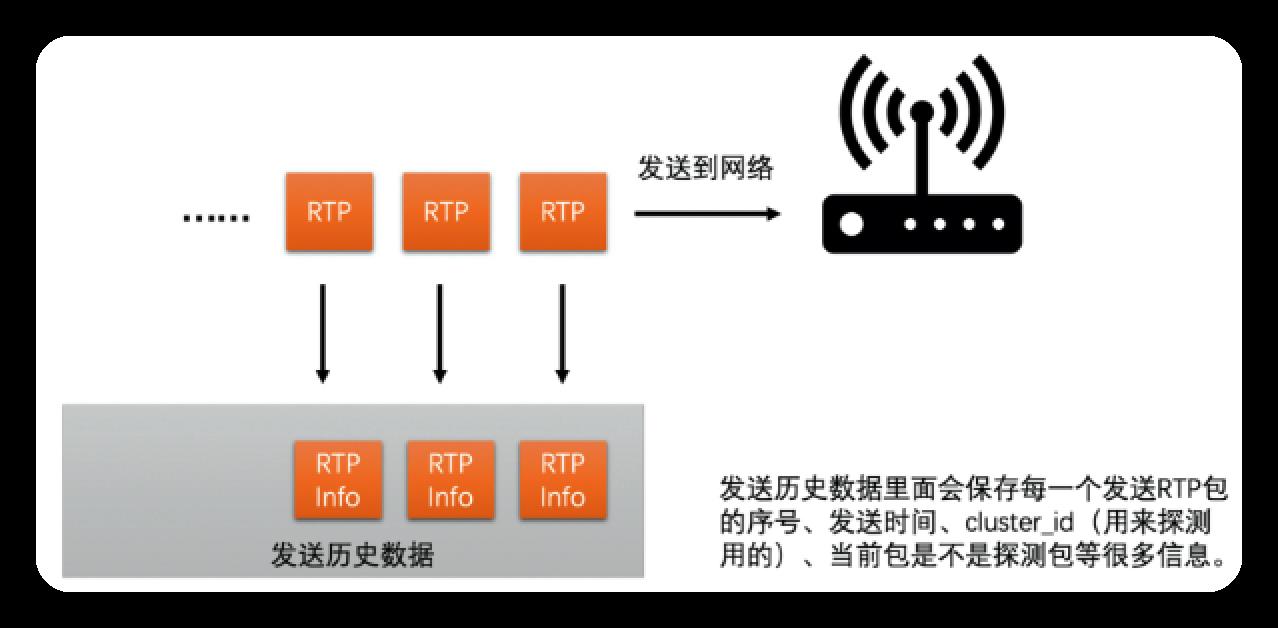

接收端每收到一个包, 也会记录包的序号和实际接收时间, 每隔一段时间就把这些统计信息(1. 每个包序号, 所对应的包, 是否被接收到了; 2. 当前包, 相比前一个包的接收间隔)发到发送端通过RTCP协议的Transport-CC报文
若发送端收到此报文, 即可知此RTP包是否被接收到了; 若发送端未收到, 即说明丢包了(也可知未丢失的包,的接收时间)
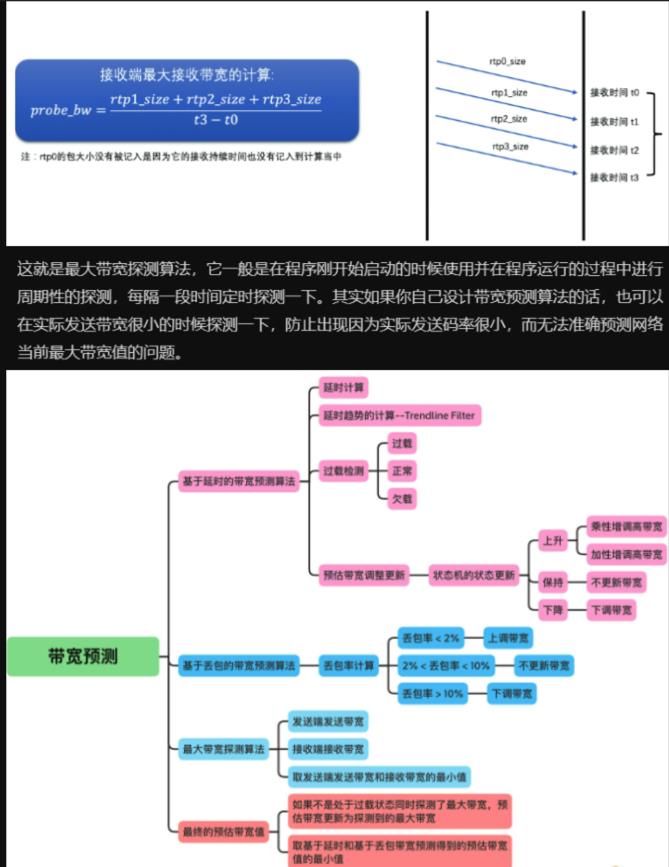
发送端根据发送历史数据中各包的发送时间和Transport-CC报文中计算的各包接收时间, 即可算出两组包之间的发送时长,和接收时长, 计算方法如下
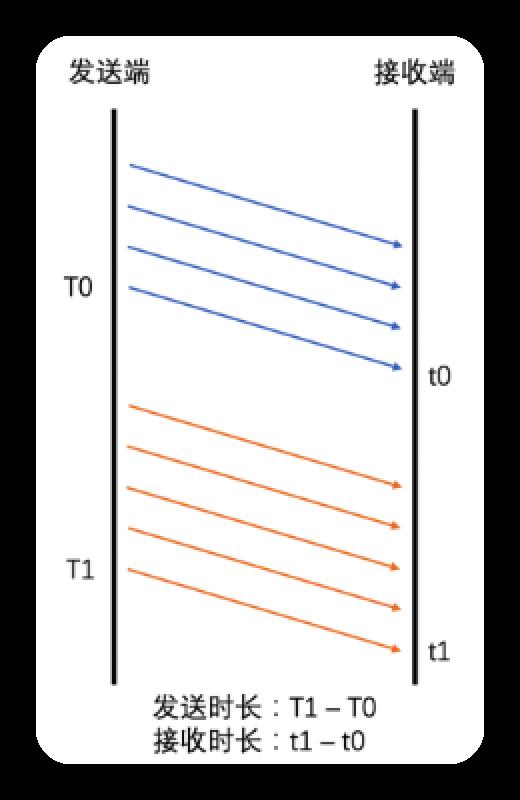
Transport-CC报文格式如下

将上文得到的接收时长-发送时长,即为延时
若延时>0,则说明网络慢,产生了缓存,继而产生了延时
若延时=0,说明网络刚好能承受数据量
若延时<0,一般出现在之前因网络带宽不足而已经缓存了一部分数据, 但目前网络明显在变好, 从而网络设备快速地将缓存中的数据发送出去, 此情况下机会出现接收时长很短, 导致接收时长小于发送时长, 即延时为负数.
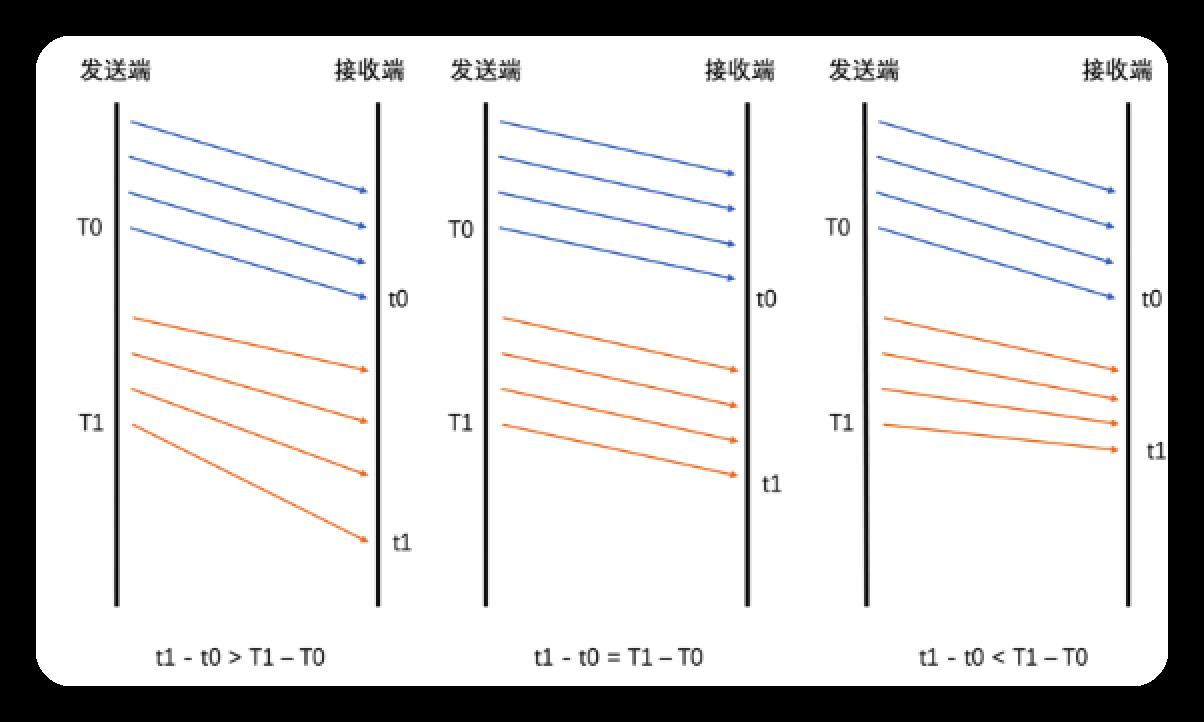
因为但一个包的延时可能有噪声干扰(如网络抖动), 故需要结合多个包的延时趋势, 判断.
延时变化趋势计算
利用TrendlineFilter滤波器, 其缓存了最近20个延时数据(到达发送端的时间,平滑后的累积延时:避免某延时的抖动)
然后应线性回归(如最小二乘法)求斜率
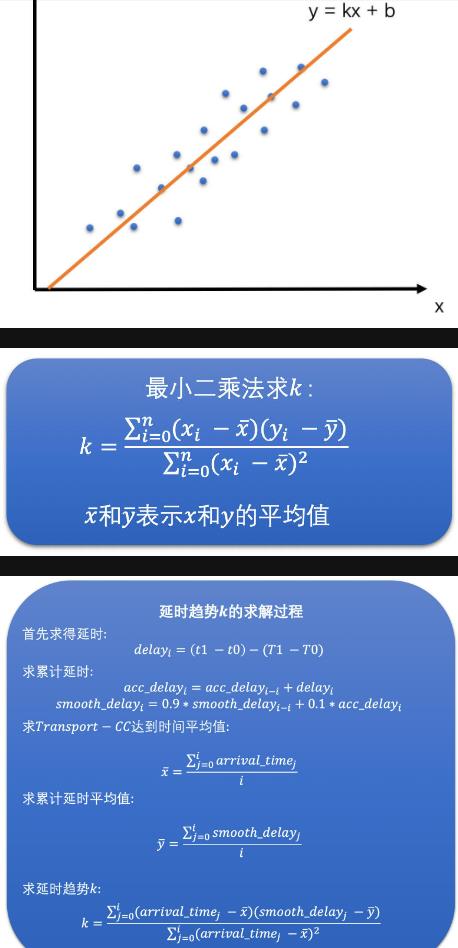
k>0时认为有延时,k=0时无延时,k<0无延时反而接收速度更快
网络状态判断
过载检测器: 比较延时趋势与延时阈值来判断网络是过载/欠载/正常状态; 并通过延时趋势更新延时阈值(为了防止阈值太大导致不够灵敏, 或阈值太小导致太敏感, 故动态调整)
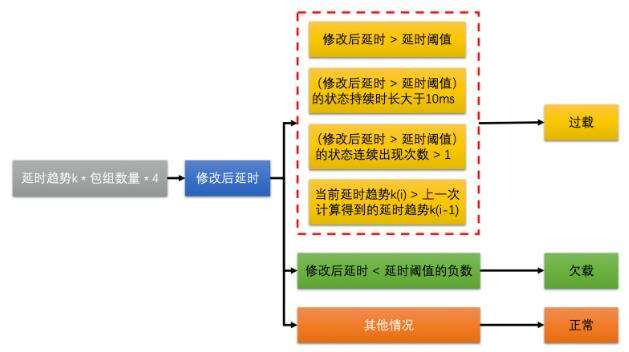


带宽动态调整
状态机: 上升/保持/下降状态.



基于丢包的带宽预测算法
基于Transport-CC报文,计算丢包率,调整带宽
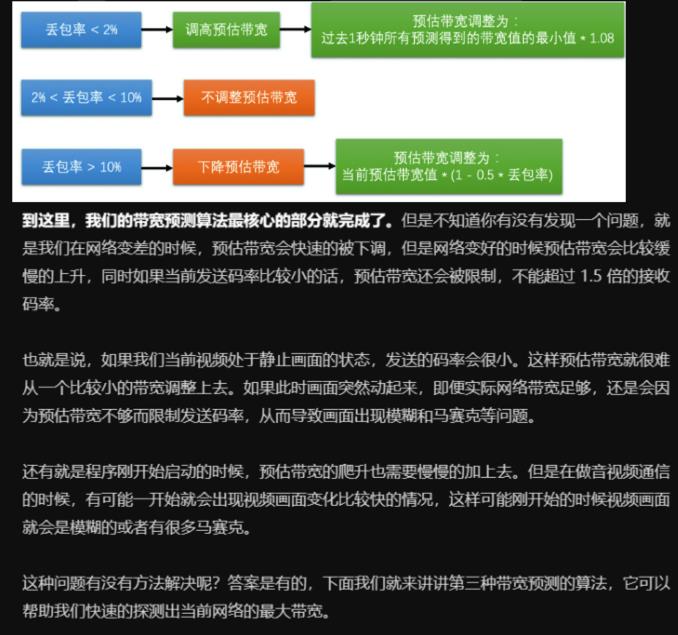
丢包率计算
丢包率=丢包的数量/总发送包的数量
若丢包率<2%,则网络状况很好,需调高带宽值,带宽值等于过去1秒内所有预测到的带宽最小值*1.08
若丢包率介于2%到10%之间,则网络正常,不调整
若丢包率>10%,则网络状况不好,需降低带宽值,等于当前预估带宽值*(1-0.5*丢包率)
最大带宽探测算法

码控算法
根据预测的带宽, 即可控制数据的发送码率.

码控原理: 控制编码器输出码流的大小,即为每帧图选合适的QP值, 当一帧图确定后, 其画面复杂度和QP值决定了其编码后的大小.
码控的类型
- VBR动态码率: 码率随原始视频画面复杂度变化而变化,画面复杂时码率高,画面简单是码率低, 目标是保证视频画面质量, 适合视频点播和短视频场景
- CQP恒定QP: 每个画面都用同一个QP值来编码, 实际工程不会使用
- 故当画面复杂时, 残差大, QP量化后残差还是大, 编码后的图像大
- 故当画面简单是, 残差小, 同样的QP量化后残差小, 甚至为0, 编码后图像小
- CRF恒定码率因子: 其QP会变化, 当画面运动大(人不关注细节)时提高QP, 当画面运动小(人关注细节)时降低QP. 总体比CQP更胜码率, 是x264默认的码控算法.
- CBR恒定码率: 将
码率和实际预测带宽匹配
CBR算法
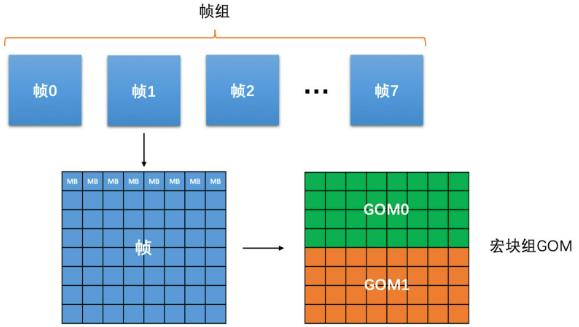
先确定帧组级(8帧为一组)的输出
以上是关于流媒体技术基础-流媒体编码与协议的主要内容,如果未能解决你的问题,请参考以下文章