自然语言处理(NLP)基于PaddleHub的文本审核
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自然语言处理(NLP)基于PaddleHub的文本审核相关的知识,希望对你有一定的参考价值。
【自然语言处理(NLP)】基于PaddleHub的文本审核
(文章目录)
前言
(一)、任务描述
在2017年之前,工业界和学术界对NLP文本处理依赖于序列模型Recurrent Neural Network (RNN).
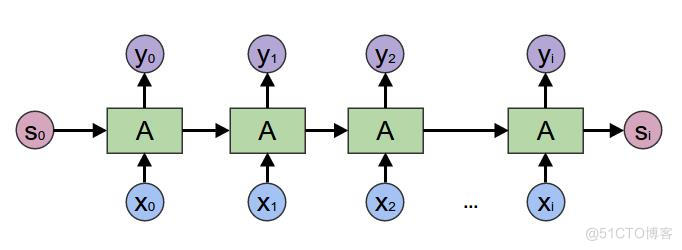
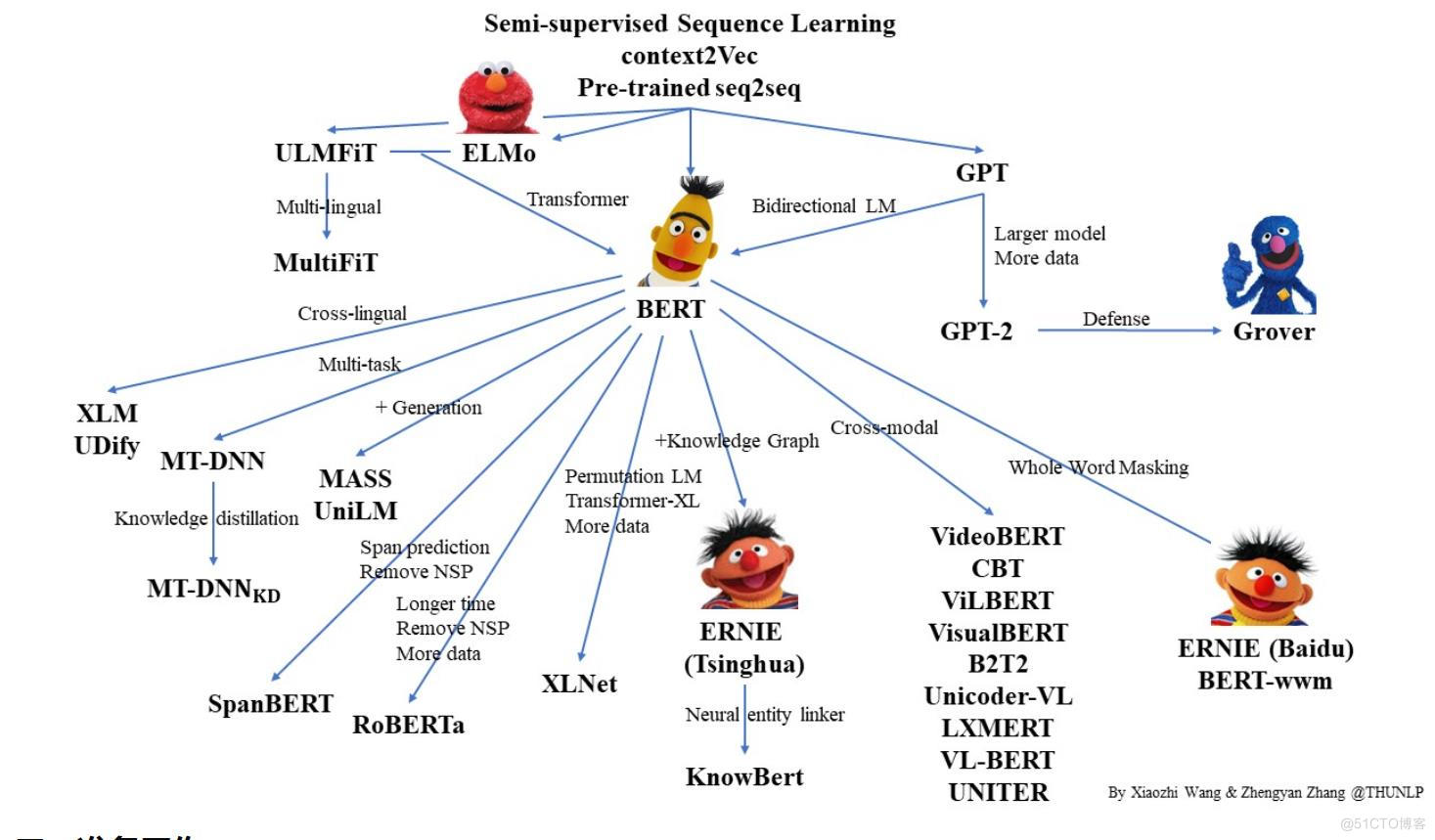
近年来随着深度学习的发展,模型参数数量飞速增长,为了训练这些参数,需要更大的数据集来避免过拟合。然而,对于大部分NLP任务来说,构建大规模的标注数据集成本过高,非常困难,特别是对于句法和语义相关的任务。相比之下,大规模的未标注语料库的构建则相对容易。最近的研究表明,基于大规模未标注语料库的预训练模型(Pretrained Models, PTM) 能够习得通用的语言表示,将预训练模型Fine-tune到下游任务,能够获得出色的表现。另外,预训练模型能够避免从零开始训练模型。
(二)、环境配置
本示例基于飞桨开源框架2.0版本。
一、数据准备
(一)、导入相关包
!pip install -U paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple
import paddlehub as hub
import paddle
(二)、代码步骤
使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
- 选择模型
- 加载自定义数据集
- 选择优化策略和运行配置
- 执行fine-tune并评估模型
二、Fine-tune
(一)、选择模型
model = hub.Module(name="ernie", task=seq-cls, num_classes=3) # 在多分类任务中,num_classes需要显式地指定类别数,此处根据数据集设置为3
hub.Module的参数用法如下:
name:模型名称,可以选择ernie,ernie_tiny,bert-base-cased,bert-base-chinese,roberta-wwm-ext,roberta-wwm-ext-large等。task:fine-tune任务。此处为seq-cls,表示文本分类任务。num_classes:表示当前文本分类任务的类别数,根据具体使用的数据集确定,默认为2。
NOTE: 文本多分类的任务中,num_classes需要用户指定,具体的类别数根据选用的数据集确定,本教程中为3。
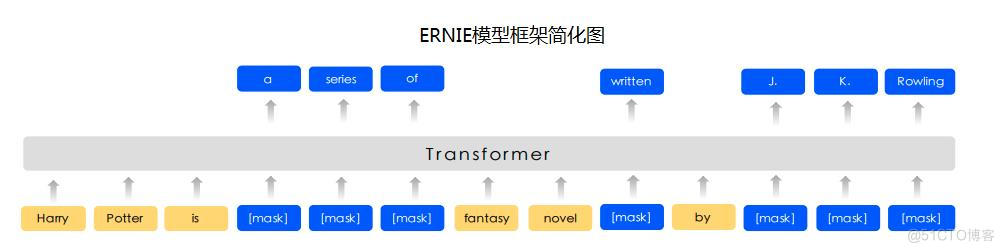
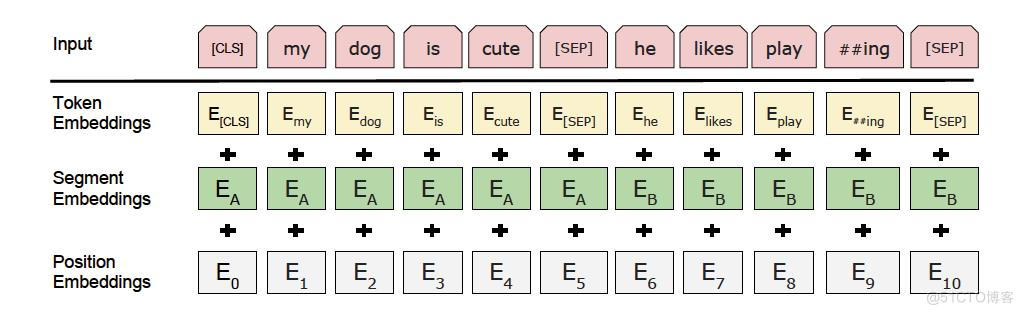
PaddleHub还提供BERT等模型可供选择, 当前支持文本分类任务的模型对应的加载示例如下:
| 模型名 | PaddleHub Module |
|---|---|
| ERNIE, Chinese | hub.Module(name=ernie) |
| ERNIE tiny, Chinese | hub.Module(name=ernie_tiny) |
| ERNIE 2.0 Base, English | hub.Module(name=ernie_v2_eng_base) |
| ERNIE 2.0 Large, English | hub.Module(name=ernie_v2_eng_large) |
| BERT-Base, English Cased | hub.Module(name=bert-base-cased) |
| BERT-Base, English Uncased | hub.Module(name=bert-base-uncased) |
| BERT-Large, English Cased | hub.Module(name=bert-large-cased) |
| BERT-Large, English Uncased | hub.Module(name=bert-large-uncased) |
| BERT-Base, Multilingual Cased | hub.Module(nane=bert-base-multilingual-cased) |
| BERT-Base, Multilingual Uncased | hub.Module(nane=bert-base-multilingual-uncased) |
| BERT-Base, Chinese | hub.Module(name=bert-base-chinese) |
| BERT-wwm, Chinese | hub.Module(name=chinese-bert-wwm) |
| BERT-wwm-ext, Chinese | hub.Module(name=chinese-bert-wwm-ext) |
| RoBERTa-wwm-ext, Chinese | hub.Module(name=roberta-wwm-ext) |
| RoBERTa-wwm-ext-large, Chinese | hub.Module(name=roberta-wwm-ext-large) |
| RBT3, Chinese | hub.Module(name=rbt3) |
| RBTL3, Chinese | hub.Module(name=rbtl3) |
| ELECTRA-Small, English | hub.Module(name=electra-small) |
| ELECTRA-Base, English | hub.Module(name=electra-base) |
| ELECTRA-Large, English | hub.Module(name=electra-large) |
| ELECTRA-Base, Chinese | hub.Module(name=chinese-electra-base) |
| ELECTRA-Small, Chinese | hub.Module(name=chinese-electra-small) |
通过以上的一行代码,model初始化为一个适用于文本分类任务的模型,为ERNIE的预训练模型后拼接上一个全连接网络(Full Connected)。
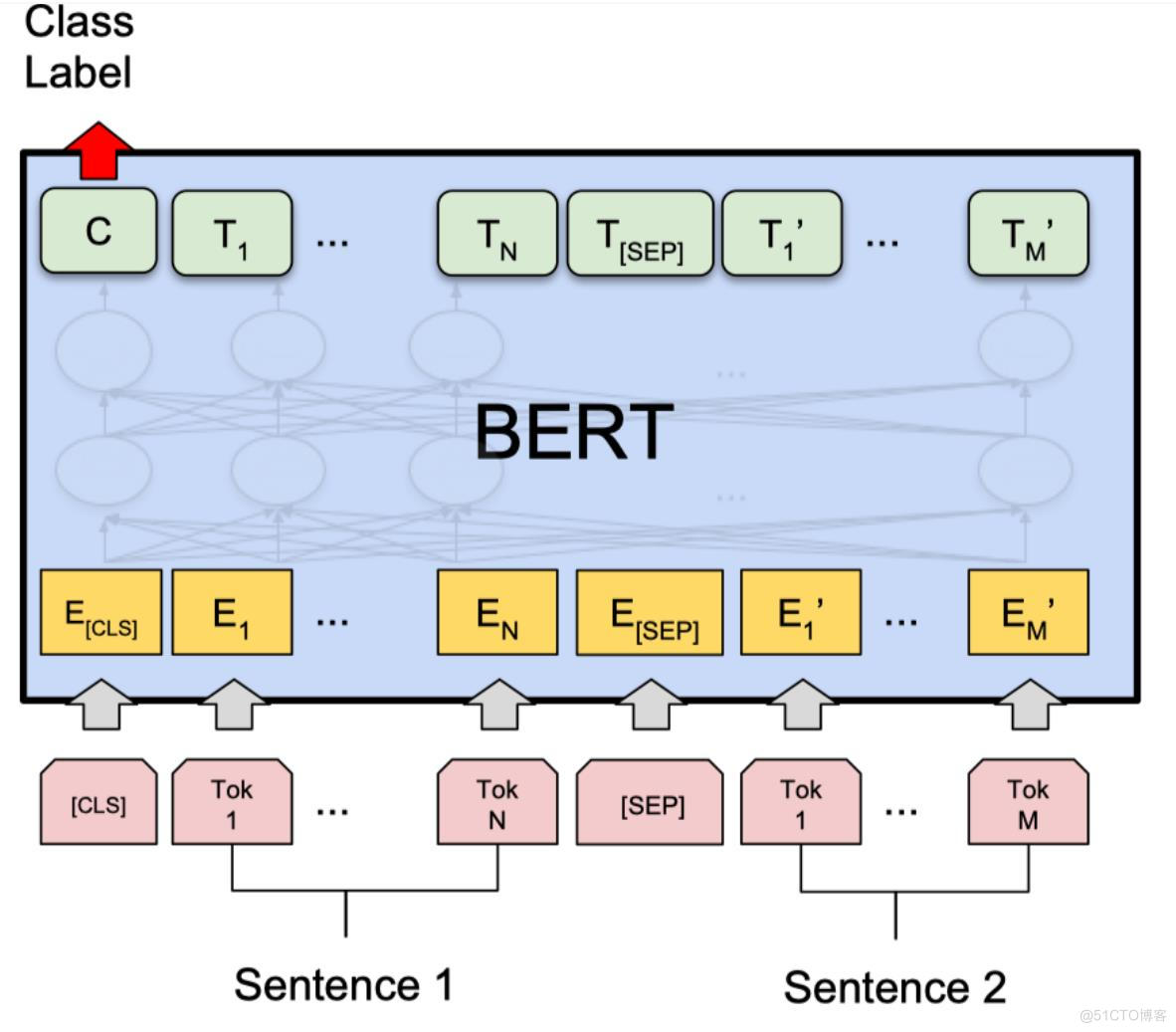 以上图片来自于:https://arxiv.org/pdf/1810.04805.pdf
以上图片来自于:https://arxiv.org/pdf/1810.04805.pdf
(二)、加载自定义数据集
低俗文本较为敏感,这里用疫情期间网民情绪文本积极、中性、消极表示。
# 解压数据集
!cd data/data22724 && unzip -o test_dataset.zip
!cd data/data22724 && unzip -o "train_ dataset.zip"
# 转换编码
def re_encode(path):
with open(path, r, encoding=GB2312, errors=ignore) as file:
lines = file.readlines()
with open(path, w, encoding=utf-8) as file:
file.write(.join(lines))
re_encode(data/data22724/nCov_10k_test.csv)
re_encode(data/data22724/nCoV_100k_train.labled.csv)
# 读取数据
import pandas as pd
train_labled = pd.read_csv(data/data22724/nCoV_100k_train.labled.csv, engine =python)
test = pd.read_csv(data/data22724/nCov_10k_test.csv, engine =python)
# 清除异常标签数据
train_labled = train_labled[train_labled[情感倾向].isin([-1,0,1])]
# 划分验证集,保存格式 text[\\t]label
from sklearn.model_selection import train_test_split
train_labled = train_labled[[微博中文内容, 情感倾向]]
train, valid = train_test_split(train_labled, test_size=0.2, random_state=2020)
train.to_csv(/home/aistudio/data/data22724/train.txt, index=False, header=False, sep=\\t)
valid.to_csv(/home/aistudio/data/data22724/valid.txt, index=False, header=False, sep=\\t)
输出结果如下图1所示:

import os, io, csv
from paddlehub.datasets.base_nlp_dataset import InputExample, TextClassificationDataset
# 数据集存放位置
DATA_DIR="/home/aistudio/data/data22724"
输出结果如下图2所示:

class News(TextClassificationDataset):
def __init__(self, tokenizer, mode=train, max_seq_len=128):
if mode == train:
data_file = train.txt
elif mode == test:
data_file = valid.txt
else:
data_file = valid.txt
super(News, self).__init__(
base_path=DATA_DIR,
data_file=data_file,
tokenizer=tokenizer,
max_seq_len=max_seq_len,
mode=mode,
is_file_with_header=True,
label_list=["-1", "0", "1"])
# 解析文本文件里的样本
def _read_file(self, input_file, is_file_with_header: bool = False):
if not os.path.exists(input_file):
raise RuntimeError("The file is not found.".format(input_file))
else:
with io.open(input_file, "r", encoding="UTF-8") as f:
reader = csv.reader(f, delimiter="\\t", quotechar=None)
examples = []
seq_id = 0
header = next(reader) if is_file_with_header else None
for line in reader:
example = InputExample(guid=seq_id, text_a=line[0], label=line[1])
seq_id += 1
examples.append(example)
return examples
train_dataset = News(model.get_tokenizer(), mode=train, max_seq_len=128)
dev_dataset = News(model.get_tokenizer(), mode=dev, max_seq_len=128)
test_dataset = News(model.get_tokenizer(), mode=test, max_seq_len=128)
for e in train_dataset.examples[:3]:
print(e)
输出结果如下图3所示:

NOTE: 最大序列长度max_seq_len是可以调整的参数,建议值128,根据任务文本长度不同可以调整该值,但最大不超过512。
(三)、选择优化策略和运行配置
optimizer = paddle.optimizer.Adam(learning_rate=5e-5, parameters=model.parameters()) # 优化器的选择和参数配置
trainer = hub.Trainer(model, optimizer, checkpoint_dir=./ckpt, use_gpu=True) # fine-tune任务的执行者
优化策略
Paddle2.0-rc提供了多种优化器选择,如SGD, Adam, Adamax等,详细参见策略。
在本教程中选择了Adam优化器,其的参数用法:
learning_rate: 全局学习率。默认为1e-3;parameters: 待优化模型参数。
运行配置
Trainer 主要控制Fine-tune任务的训练,是任务的发起者,包含以下可控制的参数:
model: 被优化模型;optimizer: 优化器选择;use_gpu: 是否使用gpu训练;use_vdl: 是否使用vdl可视化训练过程;checkpoint_dir: 保存模型参数的地址;compare_metrics: 保存最优模型的衡量指标;
(四)、执行fine-tune并评估模型
trainer.train(train_dataset, epochs=3, batch_size=32, eval_dataset=dev_dataset, save_interval=1) # 配置训练参数,启动训练,并指定验证集
部分输出结果如下图4所示:
trainer.train 主要控制具体的训练过程,包含以下可控制的参数:
train_dataset: 训练时所用的数据集;epochs: 训练轮数;batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;num_workers: works的数量,默认为0;eval_dataset: 验证集;log_interval: 打印日志的间隔, 单位为执行批训练的次数。save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
result = trainer.eval(test_dataset, batch_size=32) # 在测试集上评估当前训练模型
输出结果如下图5所示:

三、模型预测
当Finetune完成后,我们加载训练后保存的最佳模型来进行预测,完整预测代码如下:
# Data to be prdicted
data = [[""],[""],[""]]]
label_list=["-1", "0", "1"])
label_map =
idx: label_text for idx, label_text in enumerate(label_list)
model = hub.Module(
name=ernie,
task=seq-cls,
load_checkpoint=./ckpt/best_model/model.pdparams,
label_map=label_map)
results = model.predict(data, max_seq_len=128, batch_size=1, use_gpu=True)
for idx, text in enumerate(data):
print(Data: \\t Lable: .format(text[0], results[idx]))
总结
本系列文章内容为根据清华社出版的《自然语言处理实践》所作的相关笔记和感悟,其中代码均为基于百度飞桨开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【**学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。**】

以上是关于自然语言处理(NLP)基于PaddleHub的文本审核的主要内容,如果未能解决你的问题,请参考以下文章