Elasticsearch:Flattened 数据类型映射
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:Flattened 数据类型映射相关的知识,希望对你有一定的参考价值。
在本文中,我们将了解为了更好地处理包含大量或未知数量字段的文档而引入的 Elasticsearch 扁平化数据类型(flattened datatype)。 默认情况下,Elasticsearch 会在提取文档时自动映射文档中包含的字段。 虽然这是开始使用 Elasticsearch 的最简单方法,但随着时间的推移,它往往会导致字段爆炸,并且 Elasticsearch 的性能将受到 “内存不足(out of memory)” 错误和索引和查询数据时性能不佳的影响。
这种被称为 “mapping explosions” 的情况实际上很常见。 这就是 Flattened 数据类型旨在解决的问题。 让我们学习如何使用它来提高 Elasticsearch 在实际场景中的性能。
为什么选择 Elasticsearch 扁平化数据类型?
在处理包含大量不可预测字段的文档时,使用扁平化映射类型可以通过将整个 JSON 对象(及其嵌套字段)索引为单个关键字字段来帮助减少字段总数。但是,这有一个警告:对于扁平化类型,我们的查询选项将受到更多限制,因此我们需要在创建映射之前了解数据的性质。为了更好地理解为什么我们可能需要扁平化类型,让我们首先回顾一些处理具有大量字段的文档的其他方法。
Nested DataType
Nested DataType,也即嵌套数据类型定义在数组字段中,包含大量对象。 数组中的每个对象都将被视为一个单独的文档。尽管这种方法可以处理许多字段,但它也存在一些缺陷,例如:
- Kibana 尚不支持嵌套字段和查询,因此它牺牲了数据的可见性
- 每个嵌套查询都是一个内部连接操作,因此它们可能会影响性能
- 如果我们在一个文档中有一个包含 4 个对象的数组,Elasticsearch 在内部将其视为 4 个不同的文档。 因此文档数量会增加,在某些情况下可能会导致计算不准确
禁用字段
我们可以禁用具有太多内部字段的字段。 通过应用此设置,Elasticsearch 将不会解析该字段及其内容。 这种方法的好处是可以控制整个字段,但是;
- 它使该字段成为仅查看(view only)字段 — 即它可以在文档中查看,但不能进行查询(query)操作。
- 它只能应用于顶级字段,因此需要牺牲其所有内部字段的查询能力。
Elasticsearch 扁平化数据类型没有嵌套数据类型引起的问题,并且与禁用字段相比还提供了不错的查询功能。
扁平类型是如何工作
flattened 类型提供了一种替代方法,其中整个对象被映射为单个字段。 给定一个对象,展平的映射将解析出它的叶子值(leaf values)并将它们作为关键字索引到一个字段中。
为了了解大量字段如何影响 Elasticsearch,让我们简要回顾一下 Elasticsearch 中映射(即模式 schema)的方式以及将大量字段插入其中时会发生什么。
Elasticsearch 中的 mapping
与传统数据库相比,Elasticsearch 的主要优势之一是它能够适应我们提供给它的不同类型的数据,而无需在模式中预定义数据类型。相反,当数据被摄取时,Elasticsearch 会自动为我们生成模式。这种由 Elasticsearch 自动检测新增字段的数据类型称为动态映射。
但是,在许多情况下,需要手动分配不同的数据类型以更好地优化 Elasticsearch 以满足我们的特定需求。将数据类型手动分配给某些字段称为显式映射(explicit mapping)。
显式映射适用于较小的数据集,因为如果映射频繁更改并且我们要显式定义它们,我们最终可能会多次重新索引数据。这是因为,一旦在索引中使用特定数据类型对字段进行索引,更改该字段数据类型的唯一方法是使用包含该字段的新数据类型的更新映射重新索引数据。
为了大大减少重新索引的迭代,我们可以采用使用动态模板的动态映射(dynamic mapping)方法,其中我们设置规则以自动动态映射新字段。这些映射规则可以基于检测到的数据类型、字段名称的模式或字段路径。
让我们首先仔细看看 Elasticsearch 中的映射过程,以更好地了解 Elasticsearch 扁平化数据类型旨在解决的挑战。
首先,让我们导航到 Kibana 开发工具。登录 Kibana 后,在侧边栏中将我们带到 “Dev Tools”:

这将启动 Kibana 中的 Dev Tools:
通过在 Kibana 开发工具中输入如上命令创建索引 demo-default。让我们通过键入以下命令来检索我们刚刚创建的索引的映射:
GET demo-default/_mapping
如响应中所示,没有与 demo-flattened 索引相关的映射信息,因为我们还没有提供映射,并且索引没有摄取任何文档。
现在让我们将示例日志索引到 demo-default 索引:
PUT demo-default/_doc/1
"message": "[5592:1:0309/123054.737712:ERROR:child_process_sandbox_support_impl_linux.cc(79)] FontService unique font name matching request did not receive a response.",
"fileset":
"name": "syslog"
,
"process":
"name": "org.gnome.Shell.desktop",
"pid": 3383
,
"@timestamp": "2020-03-09T18:00:54.000+05:30",
"host":
"hostname": "bionic",
"name": "bionic"
索引文档后,我们可以使用以下命令检查映射的状态:
GET demo-default/_mapping
正如你在映射中看到的那样,Elasticsearch 自动为我们刚刚提取的文档中包含的每个字段生成映射。
更新集群 mappings
集群状态包含节点在集群中运行所需的所有信息。 这包括集群中包含的节点的详细信息、索引模板等元数据以及集群中每个索引的信息。如果 Elasticsearch 作为集群运行(即具有多个节点),则唯一的主节点将向集群中的每个其他节点发送集群状态信息,以便所有节点在任何时间点都具有相同的集群状态。
目前,要理解的重要一点是映射分配存储在这些集群状态中。可以使用以下请求查看集群状态信息:
GET /_cluster/state?filter_path=metadata.indices.demo-default集群状态 API 请求的响应将类似于以下示例:
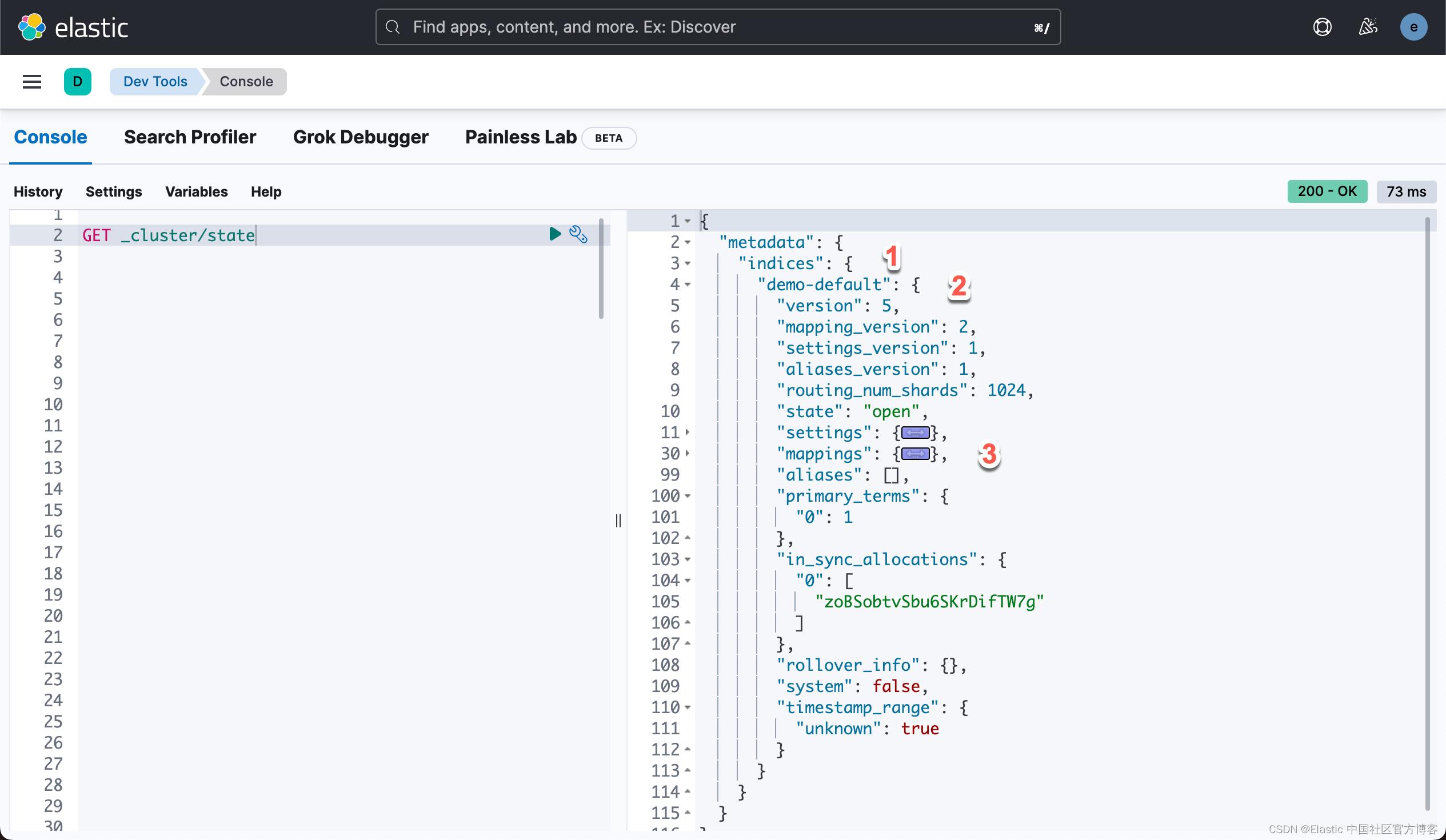
在这个集群状态示例中,你可以在 “metadata” 字段下看到 “indices” 对象 (#1)。 嵌套在此对象中,你将找到集群中索引的完整列表(#2)。 在这里,我们可以看到我们创建的名为 demo-default 的索引,它包含索引元数据,包括设置和映射(#3)。 展开映射对象后,我们现在可以看到 Elasticsearch 创建的索引映射。
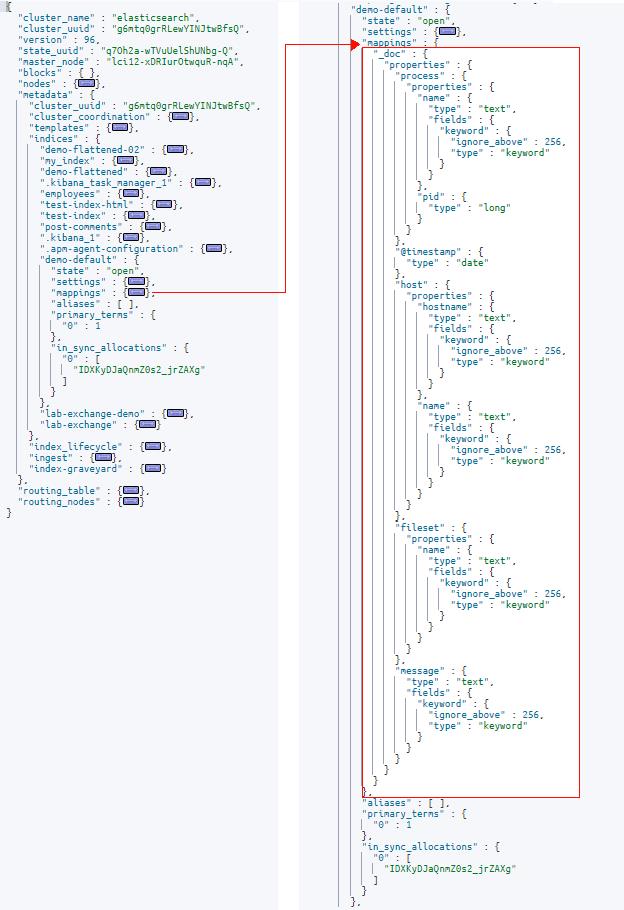
基本上发生的情况是,对于添加到索引的每个新字段,都会创建一个映射,然后该映射会在集群状态下更新。 此时,集群状态从主节点传输到集群中的每个其他节点。
映射爆炸
到目前为止,一切似乎都很顺利,但是如果我们需要摄取包含大量新字段的文档会发生什么? Elasticsearch 必须为每个新字段更新集群状态,并且该集群状态必须传递给所有节点。跨节点的集群状态传输是单线程操作 — 因此要更新的字段映射越多,完成更新所需的时间就越长。这种延迟通常以性能不佳的集群而结束,有时会导致整个集群停机。这被称为 “映射爆炸(mapping explosion)”。
这也是 Elasticsearch 从 5.x 及更高版本开始将索引中的字段数限制为 1,000 个的原因之一。如果我们的字段数超过 1,000,我们必须手动更改默认索引字段限制(使用 index.mapping.total_fields.limit 设置)或者我们需要重新考虑我们的架构。
这正是 Elasticsearch 扁平化数据类型旨在解决的问题。
Elasticsearch Flattened DataType
使用 Elasticsearch 扁平化数据类型,具有大量嵌套字段的对象被视为单个关键字字段。 换句话说,我们将扁平化类型分配给我们知道包含大量嵌套字段的对象,以便将它们视为一个单独的字段而不是许多单独的字段。
扁平化实操
现在我们已经了解了为什么需要扁平化数据类型,让我们看看它的实际应用。我们将从摄取与之前相同的文档开始,但我们将创建一个新索引,以便我们可以将其与未偏平版本进行比较。创建索引后,我们将扁平化数据类型分配给文档中的一个字段。
好吧,让我们从创建新索引的命令开始:
PUT demo-flattened现在,在我们将任何文档提取到新索引之前,我们将明确地将 flattened 映射类型分配给名为 host 的字段,以便在提取文档时,Elasticsearch 将识别该字段并应用适当的 flattened 数据类型自动运用到该字段:
PUT demo-flattened/_mapping
"properties":
"host":
"type": "flattened"
让我们检查一下这个显式映射是否应用于这个请求中的 demo-flattened 索引:
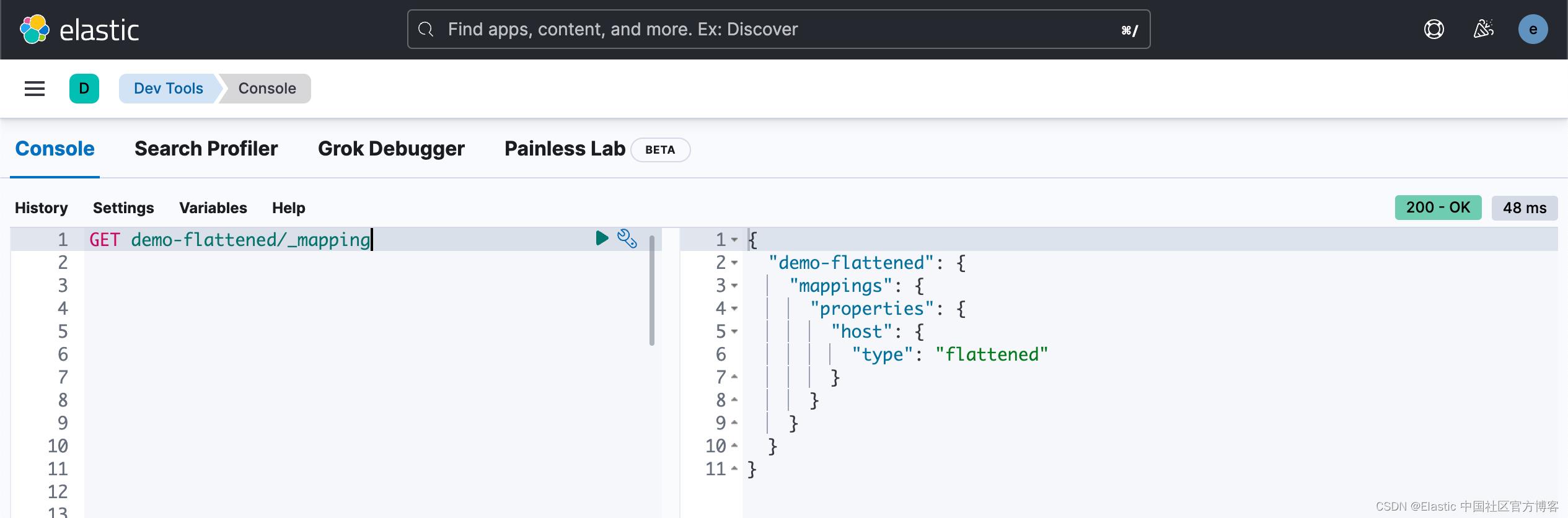
此响应证实我们确实已将 flattened 类型应用于映射。
现在让我们索引我们之前用这个请求索引的同一个文档:
PUT demo-flattened/_doc/1
"message": "[5592:1:0309/123054.737712:ERROR:child_process_sandbox_support_impl_linux.cc(79)] FontService unique font name matching request did not receive a response.",
"fileset":
"name": "syslog"
,
"process":
"name": "org.gnome.Shell.desktop",
"pid": 3383
,
"@timestamp": "2020-03-09T18:00:54.000+05:30",
"host":
"hostname": "bionic",
"name": "bionic"
对示例文档进行索引后,让我们在此请求中使用以下命令再次检查索引的映射:
GET demo-flattened/_mapping
我们可以在这里看到,Elasticsearch 自动将字段映射到数据类型,除了 host 字段,它仍然是 flattened 类型,正如我们之前配置的那样。现在,让我们比较未扁平(demo-default)和扁平(demo-flattened)索引的映射:

请注意我们的第一个非扁平索引如何为嵌套在 host 对象下的每个单独字段创建映射。 相比之下,我们最新的扁平化索引显示了将所有嵌套字段放入一个字段的单个映射,从而减少了索引中的字段数量。 这正是我们在这里所追求的。
在展平对象下添加新字段
我们已经了解了如何为具有大量嵌套字段的对象创建扁平映射。 但是,如果我们已经创建了映射后,额外的嵌套字段流入 Elasticsearch 会发生什么?
让我们看看当我们向已经映射到扁平类型的 host 对象添加更多嵌套字段时,Elasticsearch 会如何反应。
我们将使用 Elasticsearch 的 update API 将更新发布到 host 字段,并在 host 下添加两个名为 osVersion 和 osArchitecture 的新子字段:
POST demo-flattened/_update/1
"doc":
"host":
"osVersion": "Bionic Beaver",
"osArchitecture": "x86_64"
让我们检查一下我们更新的文档:

我们可以在这里看到这两个字段已成功添加到现有文档中。现在让我们看看 host 字段的映射会发生什么:
GET demo-flattened/_mappings
请注意,即使我们添加了两个新字段,Elasticsearch 也没有修改 host 字段的扁平映射类型。 这正是我们在索引可能生成大量字段的文档时希望发生的可预测行为。 由于附加字段被映射到单个扁平的 host 字段,因此无论添加多少嵌套字段,集群状态都保持不变。
通过这种方式,Elasticsearch 帮助我们避免了可怕的映射爆炸。 然而,与生活中的许多事情一样,扁平对象方法也有一个缺点,我们将在接下来介绍。
查询 Elasticsearch 扁平化数据类型对象
虽然可以查询在单个字段中 “扁平化” 的嵌套字段,但需要注意某些限制。 扁平对象中的所有字段值都存储为关键字 — 关键字字段不进行任何类型的文本分词(text tokenization)或分析,而是按原样存储。
由于没有 “已分析” 字段,我们失去的关键功能是使用不区分大小写的查询的能力,这样你就不必输入完全匹配的查询,并且分析的字段还使 Elasticsearch 能够将该字段纳入搜索分数。
让我们看一些示例查询,以更好地理解这些限制,以便我们可以为不同的用例选择正确的映射。
查询顶层扁平字段
host 字段下有一些嵌套字段。 让我们用文本查询来查询 host 字段,看看会发生什么:
GET demo-flattened/_search
"query":
"term":
"host": "Bionic Beaver"
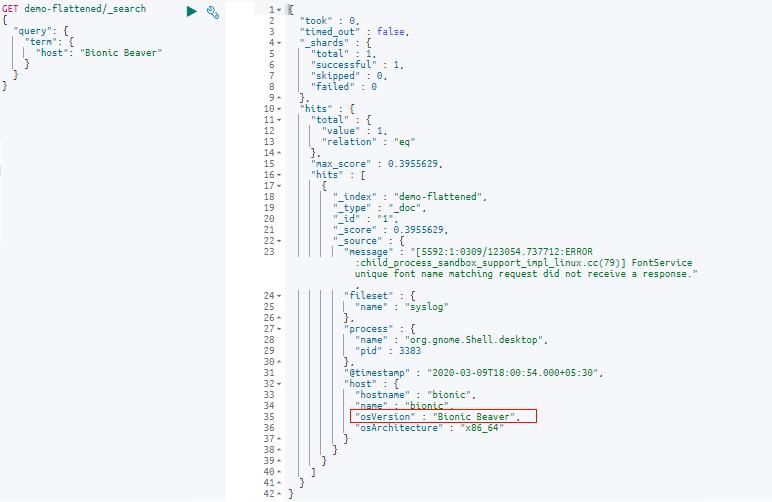
如我们所见,查询顶级 host 字段会查找嵌套在 host 对象下的所有值的匹配项。
有兴趣的小伙伴可以尝试如下的搜索:
GET demo-flattened/_search
"query":
"term":
"host": "Bionic beaver"
在上面,我们把 Beaver 改为 beaver。由于 flattened 类型的字段没有被分词,也就是说它的大小写是不同的。上面的搜索结果是:
"took": 0,
"timed_out": false,
"_shards":
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
,
"hits":
"total":
"value": 0,
"relation": "eq"
,
"max_score": null,
"hits": []
显然它查询不到任何的结果。
查询扁平字段内的特定键值
例如,如果我们需要查询 host 对象中的 osVersion 等特定字段,我们可以使用以下查询来实现:
GET demo-flattened/_search
"query":
"term":
"host.osVersion": "Bionic Beaver"
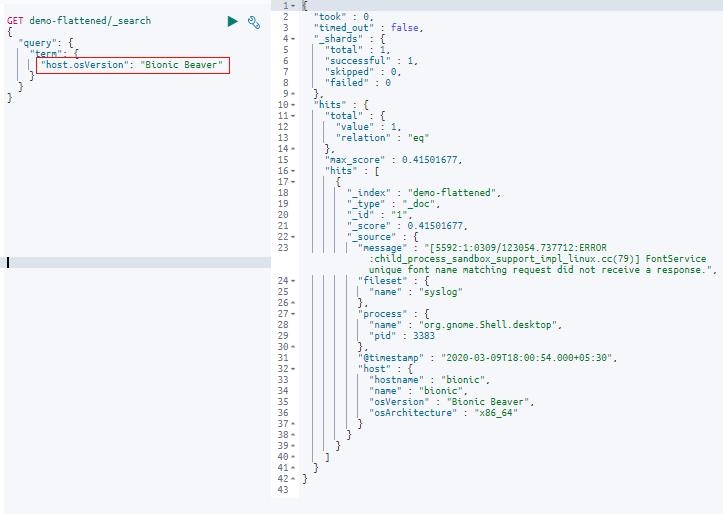
应用匹配查询
匹配查询(match query)返回与一个或多个字段上的文本或短语匹配的文档。
可以对展平的字段应用匹配查询,但由于展平的字段值仅存储为关键字,因此全文搜索功能存在一定的限制。 这可以通过在同一字段上执行三个单独的搜索来最好地证明。
Match Query 例子1
让我们在 host 字段中的 osVersion 字段中搜索文本 Bionic Beaver。 这里请注意搜索文本的大小写。
GET demo-flattened/_search
"query":
"match":
"host.osVersion": "Bionic Beaver"
传入搜索请求后,查询结果将如图所示:
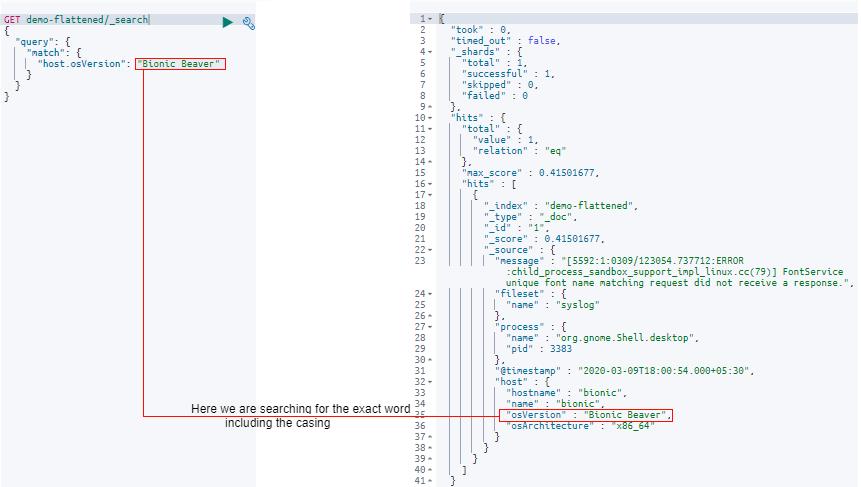
在这里,你可以看到结果包含字段 osVersion,其值为 Bionic Beaver,而且大小写也完全一致。
Match Query 例子2
在前面的示例中,我们看到匹配查询返回的关键字与 osVersion 字段的大小写完全相同。 在此示例中,让我们看看当搜索关键字与字段中的关键字不同时会发生什么:
GET demo-flattened/_search
"query":
"match":
"host.osVersion": "bionic beaver"
通过 match 查询后,我们没有得到任何结果。 这是因为存储在 osVersion 字段中的值正是 Bionic Beaver,并且由于使用了扁平化类型,Elasticsearch 没有对该字段进行分析,因此它只会返回与字母的确切大小写匹配的结果。
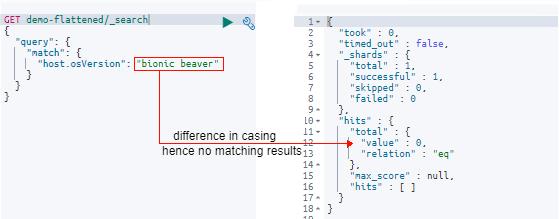
Match Query 例子3
转到我们的第三个示例,让我们看看在 osVersion 字段中仅查询 Beaver 部分短语的效果:
GET demo-flattened/_search
"query":
"match":
"host.osVersion": "Beaver"
在响应中,你可以看到没有匹配项。 这是因为我们的 Beaver 匹配查询与 Bionic Beaver 的确切值不匹配,因为缺少 Bionic 一词。
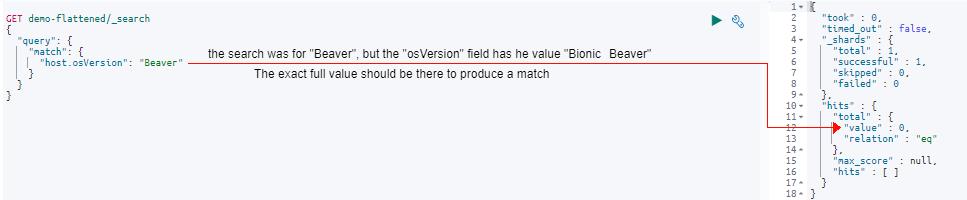
那是很多信息,所以现在让我们总结一下我们在 host.osVersion 字段上的示例 match 查询中学到的知识:
| Match Query Text | 结果 | 原因 |
|---|---|---|
| Bionic Beaver | osVersion 值为 Bionic Beaver 的文档返回 | 匹配查询文本与 host.os 版本值的精确匹配 |
| bionic beaver | 没有返回任何文件 | 匹配查询文本的大小写不同于 host.osVersion (Bionic Beaver) |
| Beaver | 没有返回任何文件 | 匹配查询仅包含一个 Beaver 标记。 但是 host.osVersion 值整体是 Bionic Beaver |
局限
每当面临扁平化对象的决定时,在使用 Elasticsearch 扁平化数据类型时,我们需要考虑以下几个关键限制:
1)目前支持的查询类型仅限于以下几种:
- term, terms, and terms_set
- prefix
- range
- match and multi_match
- query_string and simple_query_string
- exists
2)无法执行涉及数字计算的查询,例如查询数字范围等。
3)不支持结果突出显示(highligting)功能。
4)尽管支持诸如术语聚合之类的聚合,但不支持处理诸如 histogram 或 date_histogram 之类的数值数据的聚合。
总结
总之,我们了解到,如果我们将太多字段注入索引,Elasticsearch 的性能会迅速下降。 这是因为我们拥有的字段越多,所需的内存就越多,而 Elasticsearch 的性能最终会受到严重影响。 在处理有限资源或高负载时尤其如此。
Elasticsearch 扁平化数据类型用于有效减少索引中包含的字段数量,同时仍允许我们查询扁平化数据。
但是,这种方法有其局限性,因此应为不需要这些功能的情况保留选择使用 flattened 类型。
更多阅读:Elasticsearch:flattened 数据类型 (7.3 发行版新功能)
以上是关于Elasticsearch:Flattened 数据类型映射的主要内容,如果未能解决你的问题,请参考以下文章