吃透Redis系列:RDB和AOF持久化详细介绍
Posted 吃透Java
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吃透Redis系列:RDB和AOF持久化详细介绍相关的知识,希望对你有一定的参考价值。
Redis系列文章:
吃透Redis系列(三):Redis管道,发布/订阅,事物,过期时间 详细介绍
吃透Redis系列(九):Redis代理twemproxy和predixy详细介绍
吃透Redis系列(十一):Jedis和Lettuce客户端详细介绍
文章目录
由于 Redis 是一个内存数据库,所谓内存数据库,就是将数据库中的内容保存在内存中,这与传统的mysql,Oracle等关系型数据库直接将内容保存到硬盘中相比,内存数据库的读写效率比传统数据库要快的多(内存的读写效率远远大于硬盘的读写效率)。但是保存在内存中也随之带来了一个缺点,一旦断电或者宕机,那么内存数据库中的数据将会全部丢失。
为了解决这个缺点,Redis提供了将内存数据持久化到硬盘,以及用持久化文件来恢复数据库数据的功能。Redis 支持两种形式的持久化,一种是RDB快照(snapshotting),另外一种是AOF(append-only-file)。
介绍持久化之前,我们先要了解一下Linux中fork()和copy on write
前置知识:Linux中fork()系统调用和内核的copy on write机制
我们可以输入man fork来查看linux中提供的fork()函数:
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
在Linux中,可以通过fork()系统调用来创建一个子进程,子进程的所有数据(变量、环境变量、程序计数器等)数值都和父进程一致。其中父子进程之间的数据有如下特点:
- 父进程的数据,子进程可以看到
- 父进程修改数据,子进程看不到,子进程修改数据,父进程也看不到
对于如上结论,我们可以做如下解释:
1,假设当前有一个redis进程,在此进程内有一个变量a,放在进程内的虚拟内存编号为3的位置,指向物理内存地址为8的位置,值为x,即a=x;

2,当前redis进程通过fork()系统调用创建出一个子进程,当前子进程和父进程肯定都是指向物理内存地址8的位置:
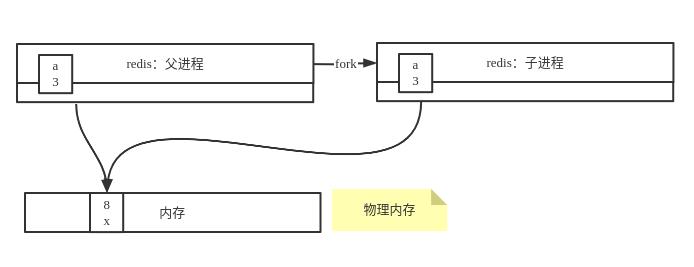
3,当子进程中修改a的值改为y时,系统则为y申请了一块新的内存空间,子进程a的值则指向新的物理内存地址为9的y值,但是父进程依然是指向物理内存地址为8的x的值:
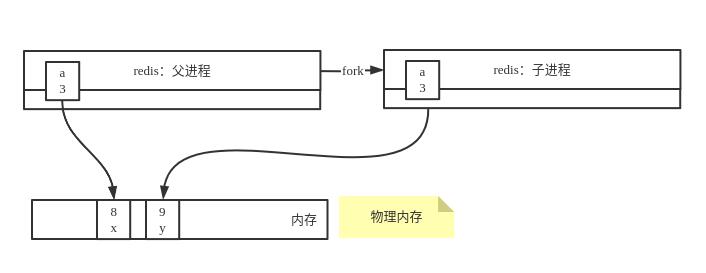
内核的copy on write机制:
也就是写时复制技术:内核只为新生成的子进程创建虚拟空间结构,它们来复制于父进程的虚拟空间结构,但是不为这些段分配物理内存,它们共享父进程的物理空间,当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间。
RDB方式
RDB是Redis用来进行持久化的一种方式,是把当前内存中的数据集快照写入磁盘,也就是 Snapshot 快照(数据库中所有键值对数据)。恢复时是将快照文件直接读到内存里。
其实现原理是:当前Redis进程fork()创建出一个子进程,通过子进程把内存中的数据写入磁盘进行持久化,通过上面的前置知识,我们已经了解当父进程fork出子进程时,父子进程之间的数据是相互隔离的,父进程依然可以对外提供服务,当父进程有数据修改时,父进程会重新开辟一块内存来存储,不过此时子进程是不知道父进程的修改的,子进程依然是备份的父进程修改之前的数据!
RDB促发方式
RDB 有两种触发方式,分别是自动触发和手动触发。
自动触发
在 redis.conf 配置文件中的 SNAPSHOTTING 下,我们可以对其配置:
################################ SNAPSHOTTING ################################
#
# Save the DB on disk:
#
# save <seconds> <changes>
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
#
# Note: you can disable saving completely by commenting out all "save" lines.
#
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
#
# save ""
save 900 1
save 300 10
save 60 10000
# By default Redis will stop accepting writes if RDB snapshots are enabled
# (at least one save point) and the latest background save failed.
# This will make the user aware (in a hard way) that data is not persisting
# on disk properly, otherwise chances are that no one will notice and some
# disaster will happen.
#
# If the background saving process will start working again Redis will
# automatically allow writes again.
#
# However if you have setup your proper monitoring of the Redis server
# and persistence, you may want to disable this feature so that Redis will
# continue to work as usual even if there are problems with disk,
# permissions, and so forth.
stop-writes-on-bgsave-error yes
# Compress string objects using LZF when dump .rdb databases?
# For default that's set to 'yes' as it's almost always a win.
# If you want to save some CPU in the saving child set it to 'no' but
# the dataset will likely be bigger if you have compressible values or keys.
rdbcompression yes
# Since version 5 of RDB a CRC64 checksum is placed at the end of the file.
# This makes the format more resistant to corruption but there is a performance
# hit to pay (around 10%) when saving and loading RDB files, so you can disable it
# for maximum performances.
#
# RDB files created with checksum disabled have a checksum of zero that will
# tell the loading code to skip the check.
rdbchecksum yes
# The filename where to dump the DB
dbfilename dump.rdb
# Remove RDB files used by replication in instances without persistence
# enabled. By default this option is disabled, however there are environments
# where for regulations or other security concerns, RDB files persisted on
# disk by masters in order to feed replicas, or stored on disk by replicas
# in order to load them for the initial synchronization, should be deleted
# ASAP. Note that this option ONLY WORKS in instances that have both AOF
# and RDB persistence disabled, otherwise is completely ignored.
#
# An alternative (and sometimes better) way to obtain the same effect is
# to use diskless replication on both master and replicas instances. However
# in the case of replicas, diskless is not always an option.
rdb-del-sync-files no
# The working directory.
#
# The DB will be written inside this directory, with the filename specified
# above using the 'dbfilename' configuration directive.
#
# The Append Only File will also be created inside this directory.
#
# Note that you must specify a directory here, not a file name.
dir /var/lib/redis/6379
1,save:
这里是用来配置触发 Redis的 RDB 持久化条件,也就是什么时候将内存中的数据保存到硬盘。比如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave(这个命令下面会介绍,手动触发RDB持久化的命令)
默认如下配置:
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存
save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存
save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存
当然如果你只是用Redis的缓存功能,不需要持久化,那么你可以注释掉所有的 save 行来停用保存功能。可以直接一个空字符串来实现停用:save “”
2,stop-writes-on-bgsave-error :
默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。这会让用户意识到数据没有正确持久化到磁盘上,否则没有人会注意到灾难(disaster)发生了。如果Redis重启了,那么又可以重新开始接收数据了
3,rdbcompression:
默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能,但是存储在磁盘上的快照会比较大。
4,rdbchecksum:
默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
5,dbfilename
设置快照的文件名,默认是 dump.rdb
6,dir
设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。默认是和当前配置文件保存在同一目录
也就是说通过在配置文件中配置的 save 方式,当实际操作满足该配置形式时就会进行 RDB 持久化,将当前的内存快照保存在 dir 配置的目录中,文件名由配置的 dbfilename 决定。
手动触发
手动触发Redis进行RDB持久化的命令有两种:
save
该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。
显然该命令对于内存比较大的实例会造成长时间阻塞,这是致命的缺陷,为了解决此问题,Redis提供了第二种方式。
bgsave
执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。具体操作是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。
基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令
恢复数据
将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可,redis就会自动加载文件数据至内存了。Redis 服务器在载入 RDB 文件期间,会一直处于阻塞状态,直到载入工作完成为止。
获取 redis 的安装目录可以使用 config get dir 命令

载入的标识是如下命令:

RDB优缺点
优点:
- RDB是一个非常紧凑(compact)的文件,它保存了redis 在某个时间点上的数据集。这种文件非常适合用于进行备份和灾难恢复。
- 生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
- RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
缺点:
- RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作,如果不采用压缩算法(内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑),频繁执行成本过高(影响性能)
- 不支持拉链,只有一个文件保存dump.rdb
- 在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改(数据有丢失)
RDB 自动保存的原理
Redis有个服务器状态结构:
struct redisService
//1、记录保存save条件的数组
struct saveparam *saveparams;
//2、修改计数器
long long dirty;
//3、上一次执行保存的时间
time_t lastsave;
首先看记录保存save条件的数组 saveparam,里面每个元素都是一个 saveparams 结构:
struct saveparam
//秒数
time_t seconds;
//修改数
int changes;
;
前面我们在 redis.conf 配置文件中进行了关于save 的配置:
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存
save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存
save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存
那么服务器状态中的saveparam 数组将会是如下的样子:

dirty 计数器和lastsave 属性:
dirty 计数器记录距离上一次成功执行 save 命令或者 bgsave 命令之后,Redis服务器进行了多少次修改(包括写入、删除、更新等操作)。
lastsave 属性是一个时间戳,记录上一次成功执行 save 命令或者 bgsave 命令的时间。
通过这两个命令,当服务器成功执行一次修改操作,那么dirty 计数器就会加 1,而lastsave 属性记录上一次执行save或bgsave的时间,Redis 服务器还有一个周期性操作函数 severCron ,默认每隔 100 毫秒就会执行一次,该函数会遍历并检查 saveparams 数组中的所有保存条件,只要有一个条件被满足,那么就会执行 bgsave 命令。
执行完成之后,dirty 计数器更新为 0 ,lastsave 也更新为执行命令的完成时间。
AOF方式
RDB是通过保存数据库中的键值对来记录数据库的状态。而另一种持久化方式 AOF 则是通过保存Redis服务器所执行的写命令来记录数据库状态。
比如对于如下命令:
127.0.0.1:6379> set k1 q
OK
127.0.0.1:6379> set k2 1
OK
127.0.0.1:6379> incr k2
(integer) 2
127.0.0.1:6379> get k2
"2"
127.0.0.1:6379>
RDB 持久化方式就是将 str1,str2,str3 这三个键值对保存到 RDB文件中,而 AOF 持久化则是将执行的 set,sadd,lpush 三个命令保存到 AOF 文件中,appendonly.aof文件:
*2
$6
SELECT
$1
0
*3
$3
set
$2
k1
$1
q
*3
$3
set
$2
k2
$1
1
*2
$4
incr
$2
k2
AOF配置
打开6379.config中append only model处:
- **appendonly:**默认值为no,也就是说redis 默认使用的是rdb方式持久化,如果想要开启 AOF 持久化方式,需要将 appendonly 修改为 yes。
- **appendfilename:aof:**文件名,默认是"appendonly.aof"
- **appendfsync:**aof持久化策略的配置,no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快,但是不太安全。always表示每次写入都执行fsync,以保证数据同步到磁盘,效率很低。everysec表示每秒执行一次fsync,可能会导致丢失这1s数据。通常选择 everysec ,兼顾安全性和效率。
- **no-appendfsync-on-rewrite:**在aof重写或者写入rdb文件的时候,会执行大量IO,此时对于everysec和always的aof模式来说,执行fsync会造成阻塞过长时间,no-appendfsync-on-rewrite字段设置为默认设置为no。如果对延迟要求很高的应用,这个字段可以设置为yes,否则还是设置为no,这样对持久化特性来说这是更安全的选择。 设置为yes表示rewrite期间对新写操作不fsync,暂时存在内存中,等rewrite完成后再写入,默认为no,建议yes。Linux的默认fsync策略是30秒。可能丢失30秒数据。默认值为no。
- **auto-aof-rewrite-percentage:**默认值为100。aof自动重写配置,当目前aof文件大小超过上一次重写的aof文件大小的百分之多少进行重写,即当aof文件增长到一定大小的时候,Redis能够调用bgrewriteaof对日志文件进行重写。当前AOF文件大小是上次日志重写得到AOF文件大小的二倍(设置为100)时,自动启动新的日志重写过程。
- **auto-aof-rewrite-min-size:**64mb。设置允许重写的最小aof文件大小,避免了达到约定百分比但尺寸仍然很小的情况还要重写。
- **aof-load-truncated:**aof文件可能在尾部是不完整的,当redis启动的时候,aof文件的数据被载入内存。重启可能发生在redis所在的主机操作系统宕机后,尤其在ext4文件系统没有加上data=ordered选项,出现这种现象 redis宕机或者异常终止不会造成尾部不完整现象,可以选择让redis退出,或者导入尽可能多的数据。如果选择的是yes,当截断的aof文件被导入的时候,会自动发布一个log给客户端然后load。如果是no,用户必须手动redis-check-aof修复AOF文件才可以。默认值为 yes。
- aof-use-rdb-preamble: 默认yes,在Redis4.0之后,新增了RDB-AOF混合持久化方式,这种方式结合了RDB和AOF的优点,既能快速加载又能避免丢失过多的数据。当开启混合持久化时,主进程先fork出子进程将现有内存副本全量以RDB方式写入aof文件中,然后将缓冲区中的增量命令以AOF方式写入aof文件中,写入完成后通知主进程更新相关信息,并将新的含有 RDB和AOF两种格式的aof文件替换旧的aof文件。
开启AOF
将 redis.conf 的 appendonly 配置改为 yes 即可。
AOF 保存文件的位置和 RDB 保存文件的位置一样,都是通过 redis.conf 配置文件的 dir 配置:

AOF重写
由于AOF持久化是Redis不断将写命令记录到 AOF 文件中,随着Redis不断的进行,AOF 的文件会越来越大,文件越大,占用服务器内存越大以及 AOF 恢复要求时间越长。为了解决这个问题,Redis新增了重写机制,当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集。可以使用命令 bgrewriteaof 来重新。
也就是说 AOF 文件重写并不是对原文件进行重新整理,而是直接读取服务器现有的键值对,然后用一条命令去代替之前记录这个键值对的多条命令,生成一个新的文件后去替换原来的 AOF 文件。
AOF 文件重写触发机制:通过 redis.conf 配置文件中的 auto-aof-rewrite-percentage:默认值为100,以及auto-aof-rewrite-min-size:64mb 配置,也就是说默认Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发。
这里再提一下,我们知道 Redis 是单线程工作,如果 重写 AOF 需要比较长的时间,那么在重写 AOF 期间,Redis将长时间无法处理其他的命令,这显然是不能忍受的。Redis为了克服这个问题,解决办法是将 AOF 重写程序放到子程序中进行,这样有两个好处:
- 子进程进行 AOF 重写期间,服务器进程(父进程)可以继续处理其他命令。
- 子进程带有父进程的数据副本,使用子进程而不是线程,可以在避免使用锁的情况下,保证数据的安全性。
使用子进程解决了上面的问题,但是新问题也产生了:因为子进程在进行 AOF 重写期间,服务器进程依然在处理其它命令,这新的命令有可能也对数据库进行了修改操作,使得当前数据库状态和重写后的 AOF 文件状态不一致。
为了解决这个数据状态不一致的问题,Redis 服务器设置了一个 AOF 重写缓冲区,这个缓冲区是在创建子进程后开始使用,当Redis服务器执行一个写命令之后,就会将这个写命令也发送到 AOF 重写缓冲区。当子进程完成 AOF 重写之后,就会给父进程发送一个信号,父进程接收此信号后,就会调用函数将 AOF 重写缓冲区的内容都写到新的 AOF 文件中。
这样将 AOF 重写对服务器造成的影响降到了最低。
以上是关于吃透Redis系列:RDB和AOF持久化详细介绍的主要内容,如果未能解决你的问题,请参考以下文章