手撕Resnet卷积神经网络-pytorch-详细注释版(可以直接替换自己数据集)-直接放置自己的数据集就能直接跑。跑的代码有问题的可以在评论区指出,看到了会回复。训练代码和预测代码均有。
Posted 小馨馨的小翟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手撕Resnet卷积神经网络-pytorch-详细注释版(可以直接替换自己数据集)-直接放置自己的数据集就能直接跑。跑的代码有问题的可以在评论区指出,看到了会回复。训练代码和预测代码均有。相关的知识,希望对你有一定的参考价值。
Alexnet网络详解代码:手撕Alexnet卷积神经网络-pytorch-详细注释版(可以直接替换自己数据集)-直接放置自己的数据集就能直接跑。跑的代码有问题的可以在评论区指出,看到了会回复。训练代码和预测代码均有。_小馨馨的小翟的博客-CSDN博客_alexnet神经网络代码
Resnet网络详解代码: 手撕Resnet卷积神经网络-pytorch-详细注释版(可以直接替换自己数据集)-直接放置自己的数据集就能直接跑。跑的代码有问题的可以在评论区指出,看到了会回复。训练代码和预测代码均有。_小馨馨的小翟的博客-CSDN博客
Googlenet网络详解代码:手撕Googlenet卷积神经网络-pytorch-详细注释版(可以直接替换自己数据集)-直接放置自己的数据集就能直接跑。跑的代码有问题的可以在评论区指出,看到了会回复。训练代码和预测代码均有。_小馨馨的小翟的博客-CSDN博客_cnn测试集准确率低
集成学习模型融合网络详解代码:
集成学习-模型融合(Lenet,Alexnet,Vgg)三个模型进行融合-附源代码-宇宙的尽头一定是融合模型而不是单个模型。_小馨馨的小翟的博客-CSDN博客_torch模型融合
深度学习常用数据增强,数据扩充代码数据缩放代码:
Resnet(Deep residual network, ResNet),深度残差神经网络,卷积神经网络历史在具有划时代意义的神经网络。与Alexnet和VGG不同的是,网络结构上就有很大的改变,在大家为了提升卷积神经网络的性能在不断提升网络深度的时候,大家发现随着网络深度的提升,网络的效果变得越来越差,甚至出现了网络的退化问题,80层的网络比30层的效果还差,深度网络存在的梯度消失和爆炸问题越来越严重,这使得训练一个优异的深度学习模型变得更加艰难,在这种情况下,网络结构图

何恺明提出了残差神经网络,提出残差学习来解决这个问题,他设计了如下图所示的神经网络结构,并在VGG19的基础上进行了修改。简单来说就是类似与加网络之前的结果,拉出来拉到后面进行拼接,组成新的输出。
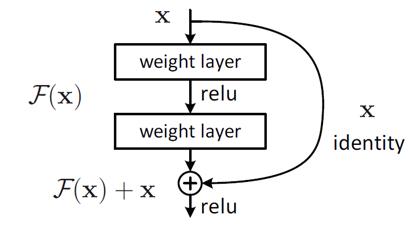
事实上在一些目标检测算法例如yolo系列的算法当中也用到了Resnet的结构,而且在很多多尺度特征融合的算法里 也是采用类似的方法,多层不同的输出组合在一起,因此学好Resnet网络对于以后学习目标检测算法具有深刻的意义。
导入库:
import torch
import torchvision
import torchvision.models
import os
from matplotlib import pyplot as plt
from tqdm import tqdm
from torch import nn
from torch.utils.data import DataLoader
from torchvision.transforms import transforms图像预处理:
将图像放缩成120*120进行处理,如果需要放缩成其他比例的,直接修改代码中的120成其他数即可。
data_transform =
"train": transforms.Compose([transforms.RandomResizedCrop(120),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((120, 120)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])导入数据:
将数据像挤牙膏似的一点一点的抽出去,设置相应的batc_size
自己的数据放在跟代码相同的文件夹下新建一个data文件夹,data文件夹里的新建一个train文件夹用于放置训练集的图片。同理新建一个val文件夹用于放置测试集的图片。
train_data = torchvision.datasets.ImageFolder(root = "./data/train" , transform = data_transform["train"])
traindata = DataLoader(dataset=train_data, batch_size=128, shuffle=True, num_workers=0) # 将训练数据以每次32张图片的形式抽出进行训练
test_data = torchvision.datasets.ImageFolder(root = "./data/val" , transform = data_transform["val"])
train_size = len(train_data) # 训练集的长度
test_size = len(test_data) # 测试集的长度
print(train_size) #输出训练集长度看一下,相当于看看有几张图片
print(test_size) #输出测试集长度看一下,相当于看看有几张图片
testdata = DataLoader(dataset=test_data, batch_size=128, shuffle=True, num_workers=0) # 将训练数据以每次32张图片的形式抽出进行测试
设置GPU 和 CPU的使用:
有GPU则调用GPU,没有的话就调用CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using device.".format(device))
构建Resnet网络:
因为Resnet网络太深,所以一般采用迁移学习的方法进行搭建
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=7,#种类修改的地方,你是几种,就把这个改成几,我是7中所以这里是7
include_top=True,
groups=1,
width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet34(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet50(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
def resnext50_32x4d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth
groups = 32
width_per_group = 4
return ResNet(Bottleneck, [3, 4, 6, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
def resnext101_32x8d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth
groups = 32
width_per_group = 8
return ResNet(Bottleneck, [3, 4, 23, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
net = resnet34()
# load pretrain weights
# download url: https://download.pytorch.org/models/resnet34-333f7ec4.pth
model_weight_path = "./resnet34-pre.pth" #加载resnet的预训练模型
assert os.path.exists(model_weight_path), "file does not exist.".format(model_weight_path)
net.load_state_dict(torch.load(model_weight_path, map_location=device))
net.to(device)
print(net.to(device)) #输出模型结构
启动模型,测试模型输出:
test1 = torch.ones(64, 3, 120, 120) # 测试一下输出的形状大小 输入一个64,3,120,120的向量
test1 = net(test1.to(device)) #将向量打入神经网络进行测试
print(test1.shape) #查看输出的结果
设置训练需要的参数,epoch,学习率learning 优化器。损失函数。
epoch = 10 # 迭代次数即训练次数
learning = 0.001 # 学习率
optimizer = torch.optim.Adam(net.parameters(), lr=learning) # 使用Adam优化器-写论文的话可以具体查一下这个优化器的原理
loss = nn.CrossEntropyLoss() # 损失计算方式,交叉熵损失函数设置四个空数组,用来存放训练集的loss和accuracy 测试集的loss和 accuracy
train_loss_all = []
train_accur_all = []
test_loss_all = []
test_accur_all = []开始训练:
for i in range(epoch): #开始迭代
train_loss = 0 #训练集的损失初始设为0
train_num = 0.0 #
train_accuracy = 0.0 #训练集的准确率初始设为0
net.train() #将模型设置成 训练模式
train_bar = tqdm(traindata) #用于进度条显示,没啥实际用处
for step, data in enumerate(train_bar): #开始迭代跑, enumerate这个函数不懂可以查查,将训练集分为 data是序号,data是数据
img, target = data #将data 分位 img图片,target标签
optimizer.zero_grad() # 清空历史梯度
outputs = net(img.to(device)) # 将图片打入网络进行训练,outputs是输出的结果
loss1 = loss(outputs, target.to(device)) # 计算神经网络输出的结果outputs与图片真实标签target的差别-这就是我们通常情况下称为的损失
outputs = torch.argmax(outputs, 1) #会输出10个值,最大的值就是我们预测的结果 求最大值
loss1.backward() #神经网络反向传播
optimizer.step() #梯度优化 用上面的abam优化
train_loss += abs(loss1.item()) * img.size(0) #将所有损失的绝对值加起来
accuracy = torch.sum(outputs == target.to(device)) #outputs == target的 即使预测正确的,统计预测正确的个数,从而计算准确率
train_accuracy = train_accuracy + accuracy #求训练集的准确率
train_num += img.size(0) #
print("epoch: , train-Loss: , train-accuracy:".format(i + 1, train_loss / train_num, #输出训练情况
train_accuracy / train_num))
train_loss_all.append(train_loss / train_num) #将训练的损失放到一个列表里 方便后续画图
train_accur_all.append(train_accuracy.double().item() / train_num)#训练集的准确率开始测试:
test_loss = 0 #同上 测试损失
test_accuracy = 0.0 #测试准确率
test_num = 0
net.eval() #将模型调整为测试模型
with torch.no_grad(): #清空历史梯度,进行测试 与训练最大的区别是测试过程中取消了反向传播
test_bar = tqdm(testdata)
for data in test_bar:
img, target = data
outputs = net(img.to(device))
loss2 = loss(outputs, target.to(device))
outputs = torch.argmax(outputs, 1)
test_loss = test_loss + abs(loss2.item()) * img.size(0)
accuracy = torch.sum(outputs == target.to(device))
test_accuracy = test_accuracy + accuracy
test_num += img.size(0)
print("test-Loss: , test-accuracy:".format(test_loss / test_num, test_accuracy / test_num))
test_loss_all.append(test_loss / test_num)
test_accur_all.append(test_accuracy.double().item() / test_num)
绘制训练集loss和accuracy图 和测试集的loss和accuracy图:
#下面的是画图过程,将上述存放的列表 画出来即可
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(range(epoch), train_loss_all,
"ro-", label="Train loss")
plt.plot(range(epoch), test_loss_all,
"bs-", label="test loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1, 2, 2)
plt.plot(range(epoch), train_accur_all,
"ro-", label="Train accur")
plt.plot(range(epoch), test_accur_all,
"bs-", label="test accur")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
torch.save(net.state_dict(), "Resnet.pth")
print("模型已保存")
全部train训练代码:
import torch
import torchvision
import torchvision.models
import os
from matplotlib import pyplot as plt
from tqdm import tqdm
from torch import nn
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
data_transform =
"train": transforms.Compose([transforms.RandomResizedCrop(120),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((120, 120)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_data = torchvision.datasets.ImageFolder(root = "./data/train" , transform = data_transform["train"])
traindata = DataLoader(dataset=train_data, batch_size=128, shuffle=True, num_workers=0) # 将训练数据以每次32张图片的形式抽出进行训练
test_data = torchvision.datasets.ImageFolder(root = "./data/val" , transform = data_transform["val"])
train_size = len(train_data) # 训练集的长度
test_size = len(test_data) # 测试集的长度
print(train_size) #输出训练集长度看一下,相当于看看有几张图片
print(test_size) #输出测试集长度看一下,相当于看看有几张图片
testdata = DataLoader(dataset=test_data, batch_size=128, shuffle=True, num_workers=0) # 将训练数据以每次32张图片的形式抽出进行测试
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using device.".format(device))
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=7,
include_top=True,
groups=1,
width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet34(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet50(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
def resnext50_32x4d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth
groups = 32
width_per_group = 4
return ResNet(Bottleneck, [3, 4, 6, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
def resnext101_32x8d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth
groups = 32
width_per_group = 8
return ResNet(Bottleneck, [3, 4, 23, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
net = resnet34()
# load pretrain weights
# download url: https://download.pytorch.org/models/resnet34-333f7ec4.pth
model_weight_path = "./resnet34-pre.pth"
assert os.path.exists(model_weight_path), "file does not exist.".format(model_weight_path)
net.load_state_dict(torch.load(model_weight_path, map_location=device))
net.to(device)
print(net.to(device)) #输出模型结构
test1 = torch.ones(64, 3, 120, 120) # 测试一下输出的形状大小 输入一个64,3,120,120的向量
test1 = net(test1.to(device)) #将向量打入神经网络进行测试
print(test1.shape) #查看输出的结果
epoch = 10 # 迭代次数即训练次数
learning = 0.001 # 学习率
optimizer = torch.optim.Adam(net.parameters(), lr=learning) # 使用Adam优化器-写论文的话可以具体查一下这个优化器的原理
loss = nn.CrossEntropyLoss() # 损失计算方式,交叉熵损失函数
train_loss_all = [] # 存放训练集损失的数组
train_accur_all = [] # 存放训练集准确率的数组
test_loss_all = [] # 存放测试集损失的数组
test_accur_all = [] # 存放测试集准确率的数组
for i in range(epoch): #开始迭代
train_loss = 0 #训练集的损失初始设为0
train_num = 0.0 #
train_accuracy = 0.0 #训练集的准确率初始设为0
net.train() #将模型设置成 训练模式
train_bar = tqdm(traindata) #用于进度条显示,没啥实际用处
for step, data in enumerate(train_bar): #开始迭代跑, enumerate这个函数不懂可以查查,将训练集分为 data是序号,data是数据
img, target = data #将data 分位 img图片,target标签
optimizer.zero_grad() # 清空历史梯度
outputs = net(img.to(device)) # 将图片打入网络进行训练,outputs是输出的结果
loss1 = loss(outputs, target.to(device)) # 计算神经网络输出的结果outputs与图片真实标签target的差别-这就是我们通常情况下称为的损失
outputs = torch.argmax(outputs, 1) #会输出10个值,最大的值就是我们预测的结果 求最大值
loss1.backward() #神经网络反向传播
optimizer.step() #梯度优化 用上面的abam优化
train_loss += abs(loss1.item()) * img.size(0) #将所有损失的绝对值加起来
accuracy = torch.sum(outputs == target.to(device)) #outputs == target的 即使预测正确的,统计预测正确的个数,从而计算准确率
train_accuracy = train_accuracy + accuracy #求训练集的准确率
train_num += img.size(0) #
print("epoch: , train-Loss: , train-accuracy:".format(i + 1, train_loss / train_num, #输出训练情况
train_accuracy / train_num))
train_loss_all.append(train_loss / train_num) #将训练的损失放到一个列表里 方便后续画图
train_accur_all.append(train_accuracy.double().item() / train_num)#训练集的准确率
test_loss = 0 #同上 测试损失
test_accuracy = 0.0 #测试准确率
test_num = 0
net.eval() #将模型调整为测试模型
with torch.no_grad(): #清空历史梯度,进行测试 与训练最大的区别是测试过程中取消了反向传播
test_bar = tqdm(testdata)
for data in test_bar:
img, target = data
outputs = net(img.to(device))
loss2 = loss(outputs, target.to(device))
outputs = torch.argmax(outputs, 1)
test_loss = test_loss + abs(loss2.item()) * img.size(0)
accuracy = torch.sum(outputs == target.to(device))
test_accuracy = test_accuracy + accuracy
test_num += img.size(0)
print("test-Loss: , test-accuracy:".format(test_loss / test_num, test_accuracy / test_num))
test_loss_all.append(test_loss / test_num)
test_accur_all.append(test_accuracy.double().item() / test_num)
#下面的是画图过程,将上述存放的列表 画出来即可
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(range(epoch), train_loss_all,
"ro-", label="Train loss")
plt.plot(range(epoch), test_loss_all,
"bs-", label="test loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1, 2, 2)
plt.plot(range(epoch), train_accur_all,
"ro-", label="Train accur")
plt.plot(range(epoch), test_accur_all,
"bs-", label="test accur")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
torch.save(net.state_dict(), "Resnet.pth")
print("模型已保存")
全部predict代码:
import torch
from PIL import Image
from torch import nn
from torchvision.transforms import transforms
image_path = "1.JPG" # 相对路径 导入图片
trans = transforms.Compose([transforms.Resize((120, 120)),
transforms.ToTensor()]) # 将图片缩放为跟训练集图片的大小一样 方便预测,且将图片转换为张量
image = Image.open(image_path) # 打开图片
print(image) # 输出图片 看看图片格式
image = image.convert("RGB") # 将图片转换为RGB格式
image = trans(image) # 上述的缩放和转张量操作在这里实现
print(image) # 查看转换后的样子
image = torch.unsqueeze(image, dim=0) # 将图片维度扩展一维
classes = ["1", "2", "3", "4", "5", "6", "7"] # 预测种类#自己是几种,这里就改成自己种类的字符数组
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
"""
注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。
但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2,
这么做的好处是能够在top1上提升大概0.5%的准确率。
可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch
"""
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=7,
include_top=True,
groups=1,
width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet34(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet50(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
def resnext50_32x4d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth
groups = 32
width_per_group = 4
return ResNet(Bottleneck, [3, 4, 6, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
def resnext101_32x8d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth
groups = 32
width_per_group = 8
return ResNet(Bottleneck, [3, 4, 23, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
# 以上是神经网络结构,因为读取了模型之后代码还得知道神经网络的结构才能进行预测
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 将代码放入GPU进行训练
print("using device.".format(device))
net = resnet34()
net.load_state_dict(torch.load("Resnet.pth", map_location=device))
net.to(device)
net.eval() # 关闭梯度,将模型调整为测试模式
with torch.no_grad(): # 梯度清零
outputs = net(image.to(device)) # 将图片打入神经网络进行测试
print(net) # 输出模型结构
print(outputs) # 输出预测的张量数组
ans = (outputs.argmax(1)).item() # 最大的值即为预测结果,找出最大值在数组中的序号,
# 对应找其在种类中的序号即可然后输出即为其种类
print(classes[ans])##输出的是那种即为预测结果代码下载链接:链接:https://pan.baidu.com/s/1el2kss9x1qiSLd4B4H3Iyw
提取码:m3zq
有用的话麻烦点一下关注,博主后续会开源更多代码,非常感谢支持!
以上是关于手撕Resnet卷积神经网络-pytorch-详细注释版(可以直接替换自己数据集)-直接放置自己的数据集就能直接跑。跑的代码有问题的可以在评论区指出,看到了会回复。训练代码和预测代码均有。的主要内容,如果未能解决你的问题,请参考以下文章
[Pytorch系列-46]:卷积神经网络 - 用GPU训练ResNet+CIFAR100数据集