FLINK 基于1.15.2的Java开发-搭建2主3从的生产集群环境
Posted TGITCIC
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FLINK 基于1.15.2的Java开发-搭建2主3从的生产集群环境相关的知识,希望对你有一定的参考价值。
要求
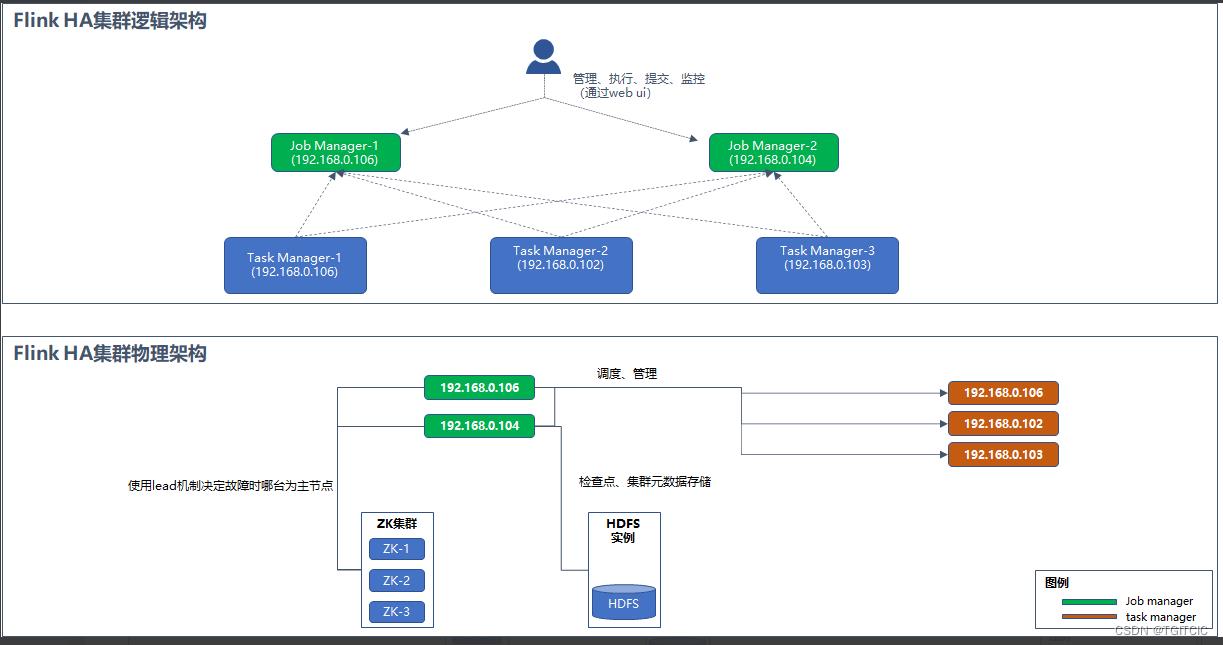
- 搭建flink生产集群,采用4台服务器;
- 2台Job Manager可开启WebUI;
- 3台Task Manager,分别连在2台Job Manager下;
规划硬件资源
| zk伪集群 | 全部位于192.168.0.106上 | 2181~2183 |
| hdfs单集群 | 位于192.168.0.106上 | hdfs端口:9000 |
| flink job manager-1 | 192.168.0.106上 | 同为task manager-1 |
| flink job manager-2 | 192.168.0.104上 | 作为192.168.0.106的backup |
| flink task manager-1 | 192.168.0.106 | 和job manager-1共用 |
| flink task manager-2 | 192.168.0.102 | - |
| flink task manager-3 | 192.168.0.103 | - |
规划软件资源
- jdk-11.0.16.1
- hadoop-2.6.0+版本以上
- flink-1.15.2
- zk-3.4.3及以上版本
安装步骤逻辑说明(伪指令)-严格区分大小写
- 把所有服务器安装OpenJDK-这就不展开了;
- 在所有的服务器上解压apche hadoop官方的tgz包,并且通过修改hadoop安装目录内的hdfs-site.xml和core-site.xml的内容后,启动hadoop使得你具有hdfs的服务能力;
- 在所有的服务器上解压zk官方的tgz包,ZK在本地安装伪集群教程见此处:kafka搭建单机开发教程
- 在所有的服务器上解压flink官方的tgz包;
- 在所有的服务器上必须配置:HADOOP_HOME并把它指向apache hadoop的tgz包解压出来的目录,hadoop_conf_dir并把它指向apache hadoop的tgz包解压出来的目录,JAVA_HOME;
- 在所有的服务器上必须配置环境变量PATH,PATH中必须包含:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin;
- 在192.168.0.106上配置flink安装目录/conf/flink-conf.yaml文件,注意在/conf/flink-conf.yaml文件的头部加入必要的jvm参数,基本格式为:env.java.opts: -Xms2048m -Xmx10240m。因为flink不设jvm启动时为1GB JVM可用内存;
- 在192.168.0.106上配置flink安装目录/conf/masters、slave文件;
- 去flink官网下载:flink-shaded-hadoop-2-uber-2.6.5-10.0.jar,如果你的hadoop为2.8或者3.0那么就要去flink官网下载flink-shaded-hadoop-2-uber-你的hadoop版本号前两个数字必须对应-10.0.jar文件。把这个文件拷贝到每个服务器的flink安装目录/lib下;
- 把修改完的/flink安装目录下的/conf/flink-conf.yaml、/conf/masters、/conf/slave文件使用scp命令拷贝到各个flink服务器的flink安装目录/conf下;
- 修改secondary job manager即192.168.0.104即flink job manager-2号节点处的flink-conf.yaml文件中的:jobmanager.rpc.address:,使得这个地址为secondary job manager的ip所在地址;
- 启动zk、启动hadoop、在job manager-1和job manager-2上使用flink安装目录/bin/./start-cluster.sh来启动,再依次在task manager-1和task manager-2上使用flink安装目录/bin/./taskmanager.sh start启动各个task manager;
- 使用http://192.168.0.106:8081可以访问我们的flink集群,然后把192.168.0.106上flink的进程用flink安装目录/bin/./stop-cluster.sh关了,再使用http://192.168.0.106:8081,你发觉竟然依旧可以访问,因为此时192.168.0.104这个secondary的job manager自动通过zk选举已经被升级成了flink的master了;
下面,就根据以上步骤开始细节展开。
安装hadoop-HDFS本地伪集群-单个hdfs服务
如果你没有离线数据,只是把hdfs当存储,那么你只要一台vm安装hdfs就够生产级别使用了,因此所有的服务器必须要有apache hadoop的安装目录而只需要在启动hdfs的那台机器上配置hdfs并启动hadoop的hdfs服务即可。
我们先把apache hadoop下载下来的tgz文件解压成这样:
hadoop安装目录/etc/hdfs-site.xml配置
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>我们这边申明了,这是一个单机用hdfs服务,这对于没有离线计算辅助flink来说已经足够了。
hadoop安装目录/etc/core-site.xml配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.0.106:9000</value>
</property>
</configuration>在此,我们申请了我们的hdfs服务使用的是192.168.0.106上的9000号端口向外暴露的。
一旦这样设了,我们在任何地方可以通过这样的hdfs url去访问hdfs服务:hdfs://192.168.0.106:9000/flink/sampledata/sinktoredis.txt
格式化name node
hdfs namenode -format配置/etc/profile
加入HADOOP_HOME、hadoop_conf_dir以及hadoop的bin和sbin目录进入环境PATH变量中去。
export HADOOP_HOME=/opt/hadoop-2.6.0
export hadoop_conf_dir=/opt/hadoop-2.6.0
export PATH=$PATH:$MAVEN_HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin注:所有flink相关的机器的/etc/profile都要有这些内容。
启动hadoop
start-dfs.sh注:所有flink相关的机器的/etc/profile都要有这些内容。
启动hadoop
start-dfs.sh关闭
stop-dfs.sh可以使用以下命令在hadoop里建立几个目录
hdfs dfs -mkdir -p /flink/ha/default
hdfs dfs -mkdir -p /flink/sampledata
hdfs dfs -mkdir /flink-checkpoint通过http://192.168.0.106:50070/可以访问hdfs界面
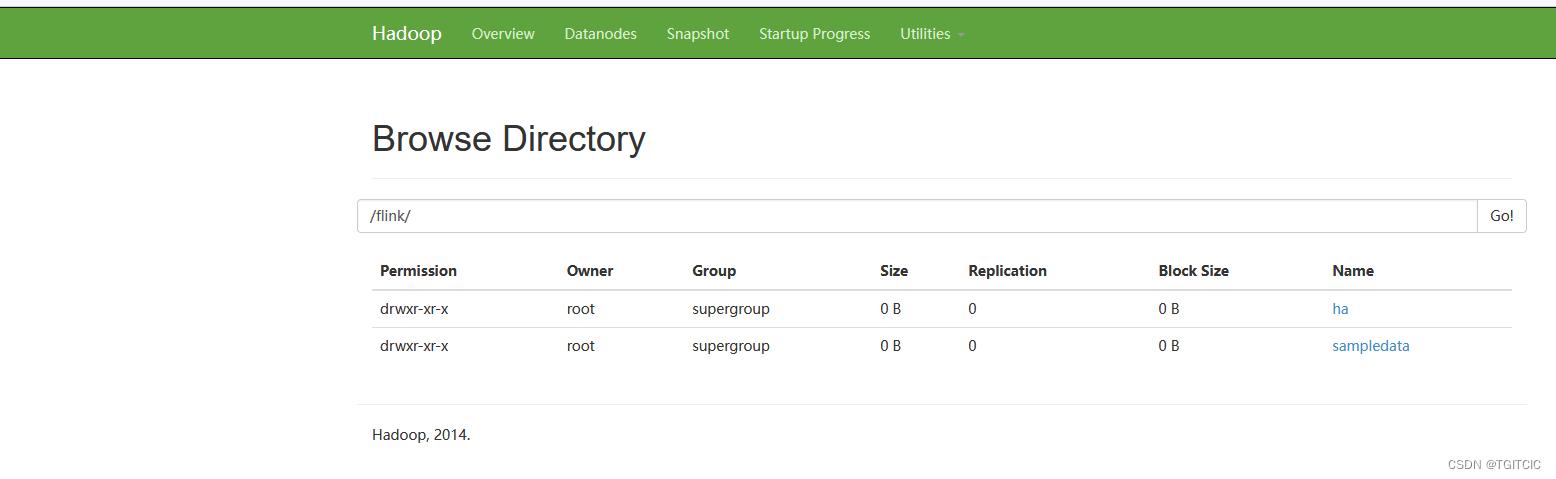
代表hadoop安装配置完成。
配置flink
flink hadoop集成
flink里集群里会把集群的元数据和断点/检查点checkpoint放到hdfs中去,因此flink需要一个“flink-shaded-hadoop的jar包”,可以去此处下载:
Apache Flink: Downloads

照着你的hadoop安装目录的版本号的前2位去下载这个jar。
我下载的就是“flink-shaded-hadoop-2-uber-2.6.5-10.0.jar”,把这个jar放到每一个服务器的flin安装目录的/lib目录下去吧。
配置flink的flink-conf.yaml文件
在192.168.0.106(job manager-1)节点上,我们打开flink安装目录/conf/flink-conf.yaml文件。把里面原来的内容全部删了,然后把下面这一段粘进去:
env.java.opts: -Xms2048m -Xmx10240m
jobmanager.rpc.address: 192.168.0.106
jobmanager.rpc.port: 6123
jobmanager.memory.process.size: 5000m
jobmanager.heap.size: 4000m
jobmanager.web.port: 8081
taskmanager.memory.process.size: 5000m
taskmanager.numberOfTaskSlots: 1
taskmanager.tmp.dirs: /tmp
taskmanager.memory.preallocate: false
taskmanager.heap.size: 4000m
parallelism.default: 1
jobmanager.execution.failover-strategy: region
#原来是rest.address: localhost
rest.address: 0.0.0.0
#原来是rest.bind-address:localhost
rest.bind-address: 0.0.0.0
web.submit.enable: true
#开启HA,使用文件系统作为快照存储
state.backend: filesystem
#启用检查点,可以将快照保存到HDFS
state.backend.fs.checkpointdir: hdfs://192.168.0.106:9000/flink-checkpoints
# 存储JobManager的元数据到HDFS
high-availability.storageDir: hdfs://192.168.0.106:9000/flink/ha/
#使用zookeeper搭建高可用
high-availability: zookeeper
# 配置ZK集群地址
high-availability.zookeeper.quorum: 192.168.0.106:2181,192.168.0.106:2182,192.168.0.106:2183
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /default
# 默认是 open,如果 zookeeper security 启用了更改成 creator
high-availability.zookeeper.client.acl: open
# 设置savepoints 的默认目标目录(可选)
# state.savepoints.dir: hdfs://namenode-host:port/flink-checkpoints
# 用于启用/禁用增量 checkpoints 的标志
# state.backend.incremental: false上述配置有几点很重要:
- 第一行的env.java.opts,就是设计了flink的java的jvm参数用的,如果不设,默你你只能使用1gb的jvm;
- 第二行的jobmanager.rpc.address对于每一个job manager,记得是job manager节点来说必须为自己的IP,对于task manager节点来说不重要。每个task manager是把自己当前的ip倒过来注册进job manager中去的,和xxl job的executor一样;
- taskmanager.numberOfTaskSlots: 1,这个就是1,因为我们不是逻辑是物理集群,每个vm上只有一个flink的实例;
- rest.address和rest.bind-address如果你不设,默认是只允许本机访问本机的web ui和本机自己所带的task manager实例,不能通过远程访问。因此我们在这边把它设成了0.0.0.0即同一网段均可访问;
- high-availability开头这几行定义的正是使用zk来决定谁是当前的flink master节点;
配置flink的masters文件
flink安装目录/conf/masters文件,打开,把里面内容变成如下:
192.168.0.106:8081
192.168.0.104:8081这就代表了我们有2个master。
配置flink的slave文件
192.168.0.106
192.168.0.102
192.168.0.103看,这边申明了3个task manager,其中192.168.0.106可以作为其本身的task manager。所以在运算时,flink的集群能力有3个实例;
全配完后记得把这上述这些文件分发到每一个服务器内
我们在192.168.0.106上配置完了flink,我们通过以下命令,把flink-conf.yaml、masters、slave分发到192.168.0.104、192.168.0.102、192.168.0.103机器上去
scp flink-conf.yaml root@192.168.0.104:/opt/flink-1.15.2/conf/
scp flink-conf.yaml root@192.168.0.102:/opt/flink-1.15.2/conf/
scp flink-conf.yaml root@192.168.0.103:/opt/flink-1.15.2/conf/
scp masters root@192.168.0.104:/opt/flink-1.15.2/conf/
scp masters root@192.168.0.102:/opt/flink-1.15.2/conf/
scp masters root@192.168.0.103:/opt/flink-1.15.2/conf/
scp slave root@192.168.0.104:/opt/flink-1.15.2/conf/
scp slave root@192.168.0.102:/opt/flink-1.15.2/conf/
scp slave root@192.168.0.103:/opt/flink-1.15.2/conf/
千万另忘了在secondary job manager即job manager-2节点上在例子中我们是:192.168.0.104的flink-conf.yaml里,把jobmanager.rpc.address后的地址改成192.168.0.104,而不要是scp过去的192.168.0.106。
保证每台服务器的/etc/profile内有这样的环境变量
export HADOOP_HOME=/opt/hadoop-2.6.0
export hadoop_conf_dir=/opt/hadoop-2.6.0
export MAVEN_HOME=/opt/maven-3.8.5
export JAVA_HOME=/opt/jdk-11.0.16.1
export PATH=$PATH:$MAVEN_HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin启动flink集群
按照以下顺序:
- 先启动zk集群
- 再启动hadoop的hdfs集群:./start-dfs.sh或者是./stop-dfs.sh
- 在所有的job manager上即:192.168.0.106和192.168.0.104上使用./start-cluster.sh或者是/.stop-cluster.sh,一旦集群生效后你在启动cluster或者是停止cluster系统会提示你输入另一台secondary机器的linux有权限的用户名密码。你可以使用“linux远程登录免密“来规避,此设置很简单在此不作展开了,在confluence的hadoop集群安装时我已经详细有论述或者去看我的这篇博客,上述就是讲“如何启用linux远程登录免密“:Cloudera Manager集群(CDH6.2.0.1)完整搭建指南
- 在所有的task manager上即:192.168.0.102和192.168.0.103上使用./taskmanager.sh start或者是./taskmanager.sh stop
如何验证集群安装好了并且起作用
- 访问http://192.168.0.106:8081;
- 关闭192.168.0.106上的job manager进程,你可以使用jps查出job manager的进程id再kill -9,或者是使用./stop-cluster.sh;
- 再去访问http://192.168.0.106:8081,你会发觉竟然依旧可以访问。这是因为192.168.0.104已经被“顶”到了master的位置了;
附、读取HDFS文件然后sink到Redis的例子
其它内容和2.FLINK开发入门第二课中一样,只是这个SinkToRedis.java里改了一句话。
同时,我把文件的内容做成了一个文件使用hdfs dfs -put 本地文件 /flink/sampledata把它放到了hdfs上,然后在flink的读取时把本地读文件变成了读hdfs服务而己。
/* 系统项目名称 com.aldi.flink.demo SinkToRedis.java
*
* 2022年9月23日-上午11:43:33 2022XX公司-版权所有
*
*/
package com.aldi.flink.demo;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
/**
*
* SinkToRedis
*
*
* 2022年9月23日 上午11:43:33
*
* @version 1.0.0
*
*/
public class SinkToRedis
public static void main(String[] args) throws Exception
// 1、创建执行环境
// ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、读取数据
String path = "/opt/data/sinktoredis.txt";
DataStreamSource<String> txtSink = env.readTextFile("hdfs://192.168.0.106:9000/flink/sampledata/sinktoredis.txt");
// String outputPath = "/Users/chrishu123126.com/opt/datawarehouse/sample/wordcount/output";
DataStream<Tuple2<String, String>> data = txtSink.flatMap(new LineSplitter());
FlinkJedisPoolConfig conf =
new FlinkJedisPoolConfig.Builder().setHost("192.168.0.106").setPort(7002).setPassword("111111").build();
data.addSink(new RedisSink<>(conf, new SinkRedisMapper()));
env.execute();
pom.xml文件内需要增加以下dependency以便于flink可以使用hadoop插件。
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>$hadoop.version</version>
</dependency>此处的hadoop.version为:
<hadoop.version>2.6.5</hadoop.version>
以上是关于FLINK 基于1.15.2的Java开发-搭建2主3从的生产集群环境的主要内容,如果未能解决你的问题,请参考以下文章