集成学习之随机森林案例专题Python机器学习系列(十七)
Posted 侯小啾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了集成学习之随机森林案例专题Python机器学习系列(十七)相关的知识,希望对你有一定的参考价值。
集成学习之随机森林案例专题【Python机器学习系列(十七)】
文章目录

集成学习算法,并不是一种具体的算法。确切地讲,集成学习算法是一种思想。它的工作原理是建立多个机器学习模型,并各自独立地学习并做出预测。通过融合多个模型,最终将得到的这些预测结果组成预测组合。这样预测的结果优于单个模型的预测结果。
比较典型的集成学习框架有Bagging、Boosting、Stacking。
🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ
1. Bagging 与 随机森林简介
Bagging的思想是从原始样本中集合采样,得到大小相同的多个样本集合(有放回的抽样),然后在每个样本集合上分别训练一个模型,最终用投票法进行预测。
Bagging模型最经典的代表是 随机森林算法。
随机森林是一个包含多棵决策树的分类器,其做法是,在从原始数据集中有放回地进行n次抽样,在采得n个样本的基础上,再在每个样本中随机挑选出k个特征再组成新的数据集,之后再分别训练决策树。最后训练出多棵决策树进行集成。
随机森林算法具有的优势:
①便于处理高维度特征数据,且不需要做特征选择,训练完之后可以给出哪些特征比较重要。
②因为并行,速度较快,且便于做可视化展示进行分析。
随机森林,作为决策树模型与Bagging的结合,是当前一个比较公认非常好的模型。其他算法,如KNN算法也可以使用Bagging模型,但是效果复杂且不胜人意。
python在sklearn库中提供了两个随机森林接口,一个是RandomForestClassifier接口,用于解决分类问题。另一个是RandomForestRegressor接口,用于解决回归问题。
该接口的参数及默认值如下:
RandomForestClassifier:
n_estimators=100, 决策树数量
*,
criterion=“gini”, 特征选择指标 默认 基尼指数
max_depth=None, 决策树的最大深度
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=“sqrt”, 最大特征数
max_leaf_nodes=None,
min_impurity_decrease=0.0,
bootstrap=True,
oob_score=False,
n_jobs=None,
random_state=None, 随机种子
verbose=0,
warm_start=False,
class_weight=None,
ccp_alpha=0.0,
max_samples=None 最大样本数
RandomForestRegressor:
n_estimators=100,
*,
criterion=“squared_error”,
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=1.0,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
bootstrap=True,
oob_score=False,
n_jobs=None,
random_state=None,
verbose=0,
warm_start=False,
ccp_alpha=0.0,
max_samples=None
2. 随机森林–分类任务
2.1 准备数据
为了更贴近拿到原始数据后的应用场景,首先我们需要准备一组较为复杂的数据,这里以葡萄酒数据为基准,对其稍作改动。
其中,特征"alcohol"表示酒精浓度,是(11,15)之间的浮点数,因为现有的特征的值都是浮点类型的数值,为了增加一个字符串类型的、表示类别的特征,这里将酒精度划分为4个层级,[11,12)之间的浮点数记作“低”,[12,13)之间的浮点数记作“中”,[13,14)之间的浮点数记作“高”,[14,15)之间的浮点数,记作“超高”。并将特证名“alcohol”改为"alcohol_level"。
除此之外,将标签列的数据0,1,2以映射的形式分别转化为“A类型”,“B类型”和“C类型”。
最后生成csv文件并保存,具体代码如下:
import pandas as pd
import numpy as np
from sklearn.datasets import load_wine
# 以葡萄酒数据集为基准
wine = load_wine()
# 取标签值数据,并重塑
target = wine.target.reshape((wine.target.shape[0], 1))
# 将特征数据与标签数据合并
data = np.hstack((wine.data, target))
feature_names = list(wine.feature_names) + ['target']
# 转换为DataFrame形式
df = pd.DataFrame(data, columns=feature_names)
# 对特征alcohol作以修改
df.alcohol = df.alcohol.astype(int)
df.alcohol = df.alcohol.astype(str)
df.alcohol = df.alcohol.map("11": "低", "12": "中", "13": "高", "14": "超高")
# 修改列名 alcohol >> alcohol_level
df.rename(columns='alcohol': 'alcohol_level', inplace=True)
# 保存为csv文件 指定编码方式,并不要行索引列
# 修改标签 为汉字
df.category = df.category.astype(int).astype(str)
df.category = df.category.map("0": "A类型", "1": "B类型", "2": "C类型")
df.to_csv("adj_wine.csv", encoding='utf_8_sig', index=False)
得到数据部分展示如下: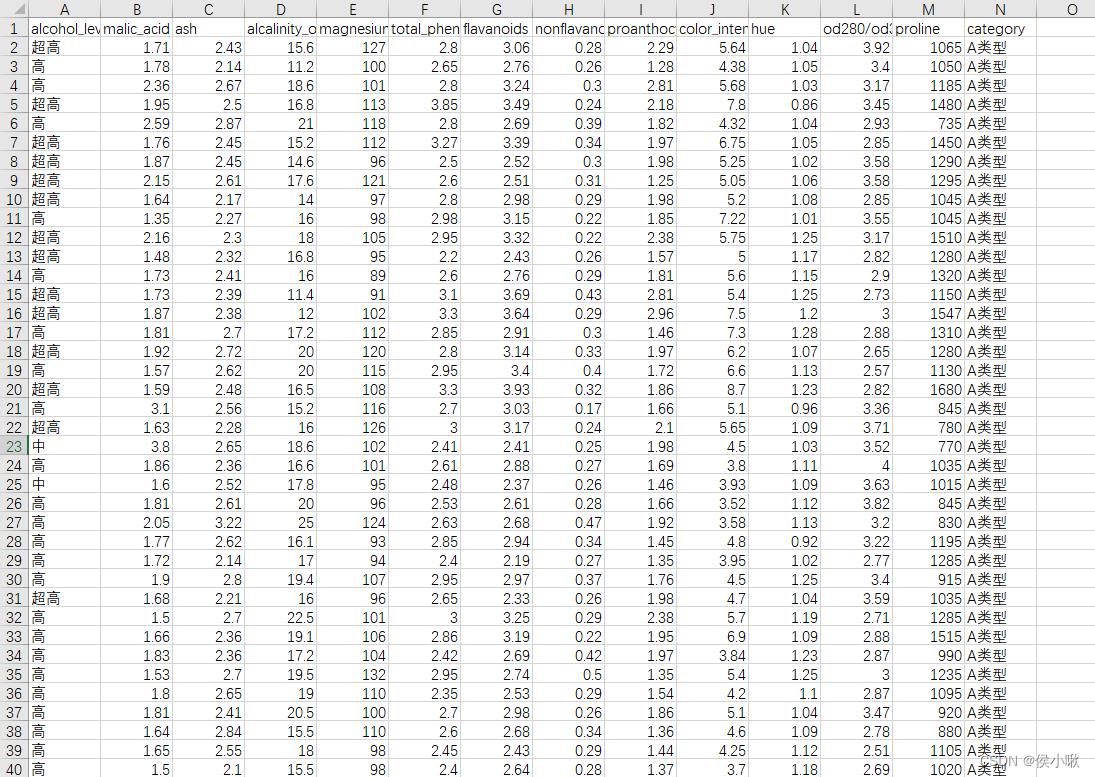
2.2 python实现随机森林–分类任务
使用上边准备的数据,编辑代码如下:
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.metrics import auc,roc_curve,roc_auc_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
df = pd.read_csv("adj_wine.csv")
df.head()
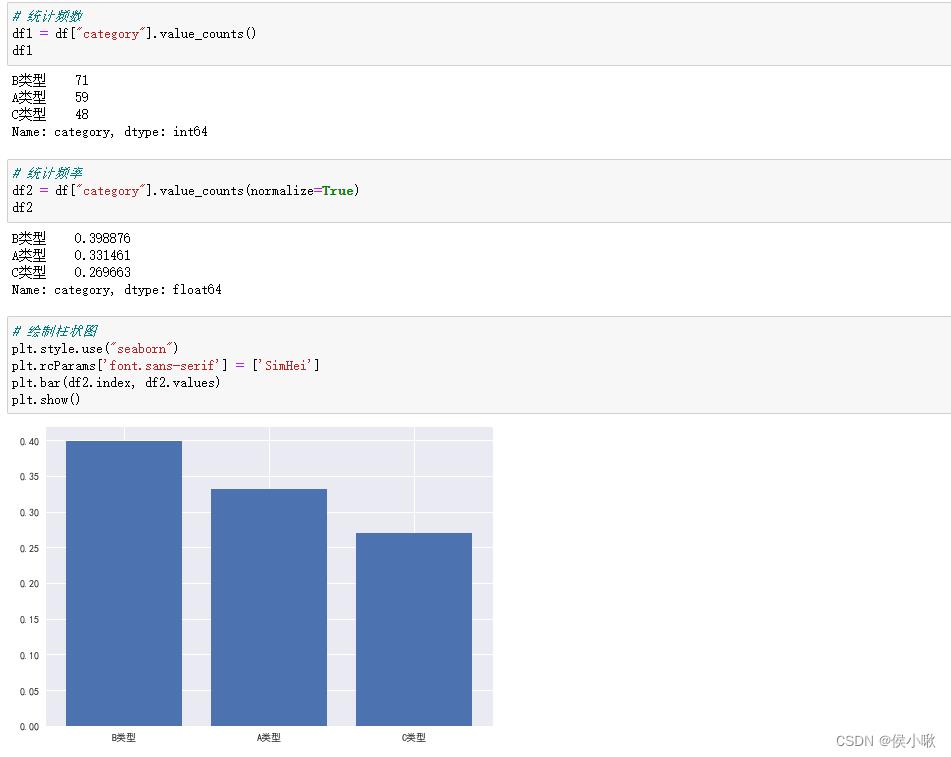
# 统计频数
df1 = df["category"].value_counts()
df1
# 统计频率
df2 = df["category"].value_counts(normalize=True)
df2
# 绘制柱状图
plt.style.use("seaborn")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.bar(df2.index, df2.values)
plt.show()
# 处理标签
dic = "A类型": 0, "B类型": 1, "C类型": 2
y = df["category"].map(dic)
X = df.drop("category", axis=1)
# 筛选是否存在没有变化的无用特征
for col_name in df.columns:
if len(df[col_name].value_counts()) == 1:
X = X.drop(col_name, axis=1)
# one-hot处理
X = pd.get_dummies(X)
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=10)
# 实例化随机森林 指定决策树数量为10 最大特征数为3
rf = RandomForestClassifier(
n_estimators=10,
max_features=3,
random_state=222
)
# 训练模型
rf.fit(X_train, y_train)
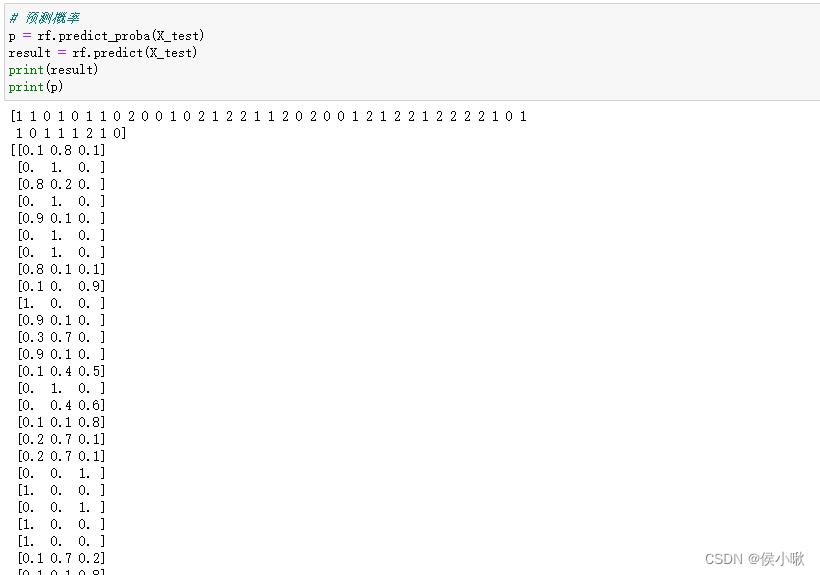
# 预测概率
p = rf.predict_proba(X_test)
# 预测结果
result = rf.predict(X_test)
print(result)
print(p)
2.3 绘制ROC曲线 与 计算AUC
绘制ROC曲线:
fpr0, tpr0, thresholds0 = roc_curve(y_test, p[:,0], pos_label = 0)
fpr1, tpr1, thresholds1 = roc_curve(y_test, p[:,1], pos_label = 1)
fpr2, tpr2, thresholds2 = roc_curve(y_test, p[:,2], pos_label = 2)
plt.plot(fpr0,tpr0)
plt.plot(fpr1,tpr1)
plt.plot(fpr2,tpr2)
plt.xlabel("fpr",fontsize=20)
plt.ylabel("tpr",fontsize=20)
plt.show()
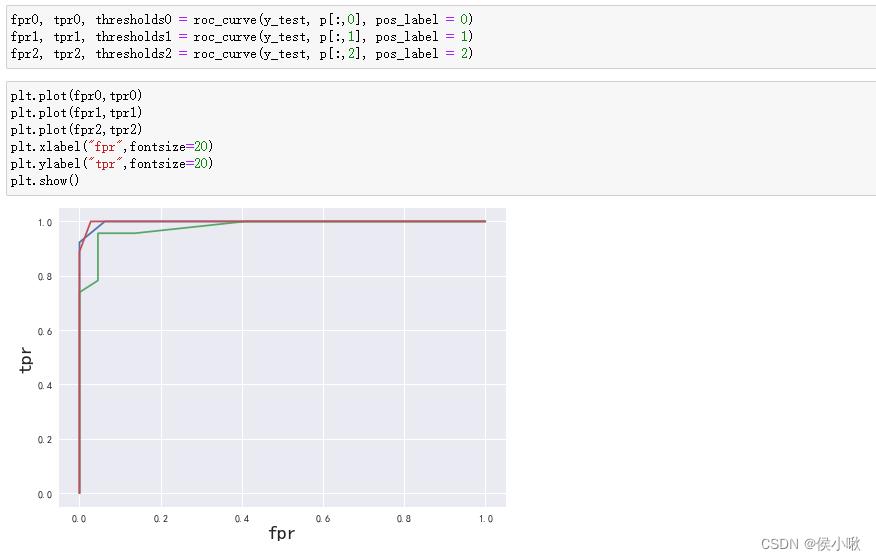
求AUC值:
auc0 = auc(fpr0, tpr0)
auc1 = auc(fpr1, tpr1)
auc2 = auc(fpr2, tpr2)
print(auc0,auc1,auc2)

求平均AUC值,以衡量模型总体性能:
roc_auc_score(y_test,p,multi_class='ovr')

2.4 绘制决策树
如果还想要实现某棵决策树的可视化,也是可以实现的。
from sklearn import tree
import graphviz
# 以第三棵决策树为例
tree_3 = rf.estimators_[3]
dot_data = tree.export_graphviz(tree_3,
filled = True,
rounded = True,
special_characters = True)
graph = graphviz.Source(dot_data)
graph.render('tree_3')
程序生成了一个pdf文件,打开可以看到,第三棵决策树如下图所示:
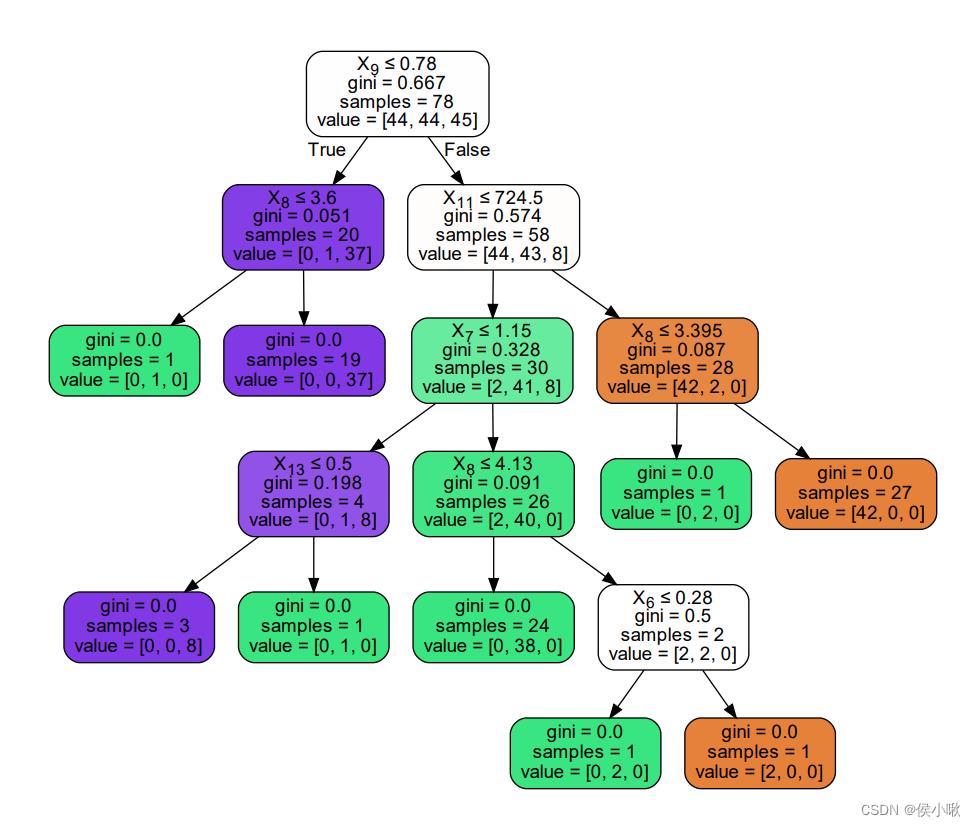
3. 随机森林–回归任务
做完分类任务,接下来我们来关注回归任务。(这里不再提供示例数据,仅展示数据详情)。
第一步,导包,读取数据,并查看数据详情:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv("data.csv")
df.info()
df.head()
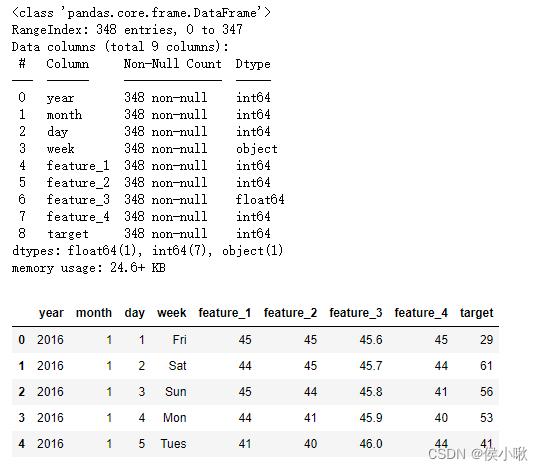
然后将数据转变为规范的时间序列数据
# 规范时间序列 将离散的日期组合
dates = pd.PeriodIndex(year=df["year"],month=df["month"],day=df["day"],freq="D")
# 该PeriodIndex类型无法直接作为绘图的x轴,需转为DatetimeIndex
dates = dates.to_timestamp()
dates

绘制出一些特征岁时间序列变动的可视化图像
plt.style.use("seaborn")
fg,ax = plt.subplots(2,2,figsize=(15,10))
ax[0,0].plot(dates,df["feature_1"])
ax[0,1].plot(dates,df["feature_2"])
ax[1,0].plot(dates,df["feature_3"])
ax[1,1].plot(dates,df["feature_4"])
plt.show()
效果如下:
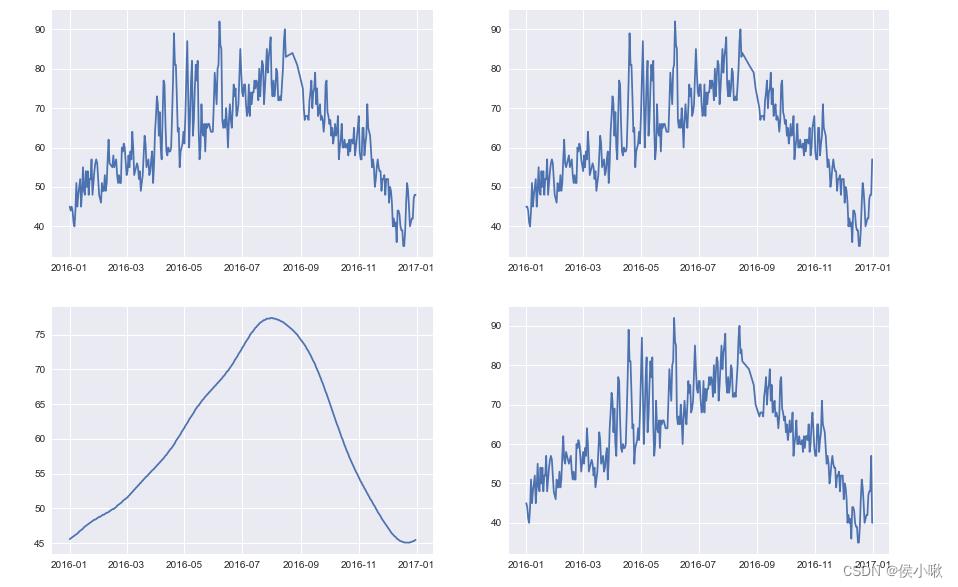
再将标签数据可视化:
plt.plot(dates,df["target"])
plt.show()

将值为文本的特征转为虚拟变量
# 转为one-hot编码
df_2 = pd.get_dummies(df)
df_2.head()
处理后的数据如下图所示:

然后,将标签和特征数据分离。
# 标签
labels = df_2["target"]
# 特征
df_features = df_2.drop("target",axis=1)
# 获取特征名称列表
feature_name_li = list(df_features.columns)
分割数据,并训练模型。最后输出预测结果。
# 数据分割
from sklearn.model_selection import train_test_split
train_feature,test_feature,train_y,test_y = train_test_split(df_features,labels,test_size=0.25,random_state=42)
from sklearn.ensemble import RandomForestRegressor
# 实例化随机森林
rf = RandomForestRegressor(
n_estimators=1000,
random_state=42
)
# 训练模型
rf.fit(train_feature,train_y)
# 预测结果
prediction = rf.predict(test_feature)
prediction
输出预测结果如下:
模型评估,计算错误率
# 错误:测试集预测值 - 测试集真实值
errors = abs(prediction-test_y)
# 误差/真实值-->错误率
mape = (errors/test_y)*100
print(f"mape:np.mean(mape)")
输出结果:
mape:18.367474314916578
绘制决策树的过程略,如果需要绘制,仿照上边分类任务中的代码即可。
如果想要进一步深入学习随机森林,欢迎点击下方链接跳转:
随机森林进阶 以python_sklearn为工具
本次分享就到这里,小啾感谢您的关注与支持!
🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ
本次分享就到这里,小啾感谢您的关注与支持!
🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ
本专栏更多好文欢迎点击下方连接:
1.初识机器学习前导内容_你需要知道的基本概念罗列_以PY为工具 【Python机器学习系列(一)】
2.sklearn库数据标准预处理合集_【Python机器学习系列(二)】
3.K_近邻算法_分类Ionosphere电离层数据【python机器学习系列(三)】
4.python机器学习 一元线性回归 梯度下降法的实现 【Python机器学习系列(四)】
5.sklearn实现一元线性回归 【Python机器学习系列(五)】
6.多元线性回归_梯度下降法实现【Python机器学习系列(六)】
7.sklearn实现多元线性回归 【Python机器学习系列(七)】
8.sklearn实现多项式线性回归_一元/多元 【Python机器学习系列(八)】
9.逻辑回归原理梳理_以python为工具 【Python机器学习系列(九)】
10.sklearn实现逻辑回归_以python为工具【Python机器学习系列(十)】
11.决策树专题_以python为工具【Python机器学习系列(十一)】
12.文本特征提取专题_以python为工具【Python机器学习系列(十二)】
13.朴素贝叶斯分类器_以python为工具【Python机器学习系列(十三)】
14.SVM 支持向量机算法(Support Vector Machine )【Python机器学习系列(十四)】
15.PCA主成分分析算法专题【Python机器学习系列(十五)】
16.机器学习模型性能度量详解 【Python机器学习系列(十六)】
以上是关于集成学习之随机森林案例专题Python机器学习系列(十七)的主要内容,如果未能解决你的问题,请参考以下文章