可视化分析(机器学习)
Posted 唯见江心秋月白、
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了可视化分析(机器学习)相关的知识,希望对你有一定的参考价值。
目录

一、实验内容
- 熟悉可视化分析的作用与方法;
- 掌握可视化分析的常用工具;
- 掌握可视化分析常用图表的Python实现。
二、实验过程
1、算法思想:
数据可视化是让用户直观了解数据潜藏的重要信息,有助于帮助用户理解分析数据。
那么数据可视化应该怎么做才能达到一个好的效果,制作数据可视化是一个设计的过程,我们可以通过尺寸可视化、颜色可视化、图形可视化、空间可视化以及概念可视化来让用户了解并分析数据。
2、算法原理
数据分析和数据可视化这两个术语密不可分。在实际处理数据时,数据分析先于可视化输出,而可视化分析又是呈现有效分析结果的一种好方法。
数据可视化:是关于数据视觉表现形式的科学技术研究。其中,这种数据的视觉表现形式被定义为“一种以某种概要形式抽提出来的信息,包括相应信息单位的各种属性和变量”。数据可视化主要是借助于图形化手段,清晰有效地传达与沟通信息。
数据可视化是指将大型数据集中的数据以图形图像形式表示,并利用数据分析和开发工具发现其中未知信息的处理过程。
3、算法分析
(1)需求分析
数据分析中的需求分析也是数据分析环节的第一步和最重要的步骤之一,决定了后续的分析的方向、方法。数据获取:数据是数据分析工作的基础,是指根据需求分析的结果提取,收集数据。
(2)数据预处理
数据预处理是指对数据进行数据合并,数据清洗,数据变换,数据标准化,数据变换后使得整体数据变为干净整齐,可以直接用于分析建模这一过程的总称。
(3)分析与建模
分析与建模是指通过对比分析、分组分析、交叉分析、回归分析等分析方法和聚类、分类、关联规则、智能推荐等模型与算法发现数据中的有价值信息,并得出结论的过程。
(4)模型评价与优化
模型评价是指对已经建立的一个或多个模型,根据其模型的类别,使用不同的指标评价其性能优劣的过程。
(5)部署
部署是指将通过了正式应用数据分析结果与结论应用至实际生产系统的过程。
三、源程序代码
源程序代码:
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
#——————————————————————————————————————————————————————————
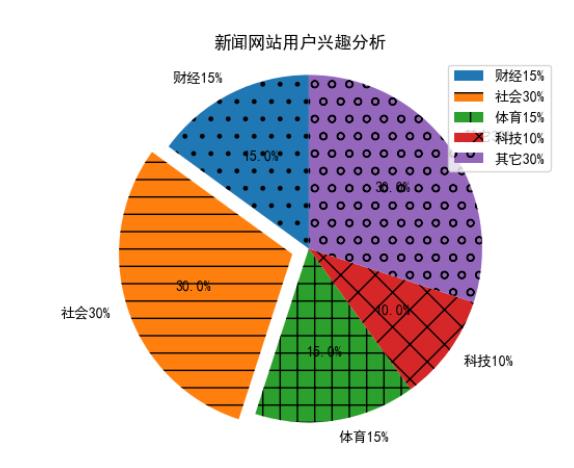
labels = '财经15%', '社会30%', '体育15%','科技10%', '其它30%'
sizes = [15, 30, 15, 10, 30]
explode = (0, 0.1, 0, 0,0)#突出第2项
fig1, ax1 = plt.subplots()
pie = ax1.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',shadow=False, startangle=90)
patches = pie[0]
patches[0].set_hatch('.')
patches[1].set_hatch('-')
patches[2].set_hatch('+')
patches[3].set_hatch('x')
patches[4].set_hatch('o')
plt.legend(patches, labels)
ax1.axis('equal')
plt.title('新闻网站用户兴趣分析')
plt.show()
#——————————————————————————————————————————————————————————
#——————————————————————————————————————————————————————————
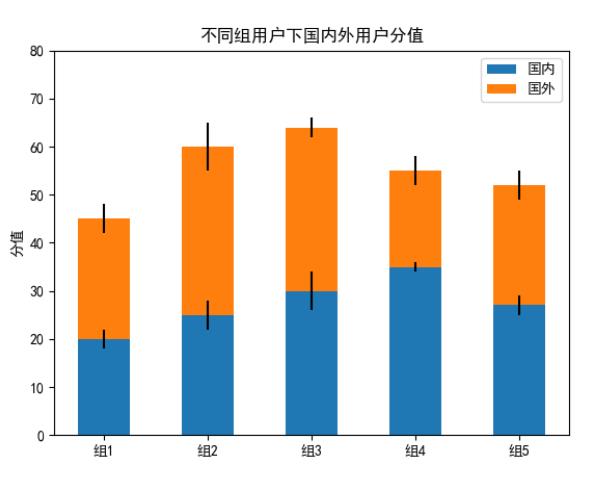
import numpy as np
N = 5
inMeans = (20, 25, 30, 35, 27)
outMeans = (25, 35, 34, 20, 25)
inStd = (2, 3, 4, 1, 2)
outStd = (3, 5, 2, 3, 3)
ind = np.arange(N) #Bar坐标位置
width = 0.5 #Bar的宽度
p1 = plt.bar(ind, inMeans, width, yerr=inStd)
p2 = plt.bar(ind, outMeans, width,bottom=inMeans, yerr=outStd)
plt.ylabel('分值')
plt.title('不同组用户下国内外用户分值')
plt.xticks(ind, ('组1', '组2', '组3', '组4', '组5'))
plt.yticks(np.arange(0, 81, 10))
plt.legend((p1[0], p2[0]), ('国内', '国外'))
plt.show()
#——————————————————————————————————————————————————————————
#——————————————————————————————————————————————————————————
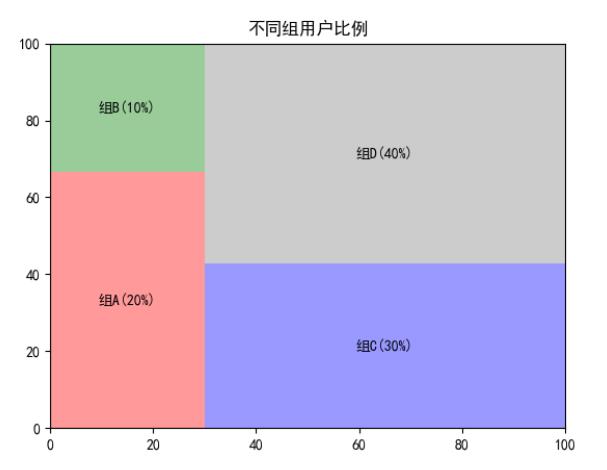
import matplotlib.pyplot as plt
import squarify
squarify.plot(sizes=[20,10,30,40], label=["组A(20%)", "组B(10%)", "组C(30%)", "组D(40%)"], color=["red","green","blue", "grey"], alpha=.4 )
#plt.axis('off')
plt.title('不同组用户比例')
plt.show()
#——————————————————————————————————————————————————————————
#——————————————————————————————————————————————————————————
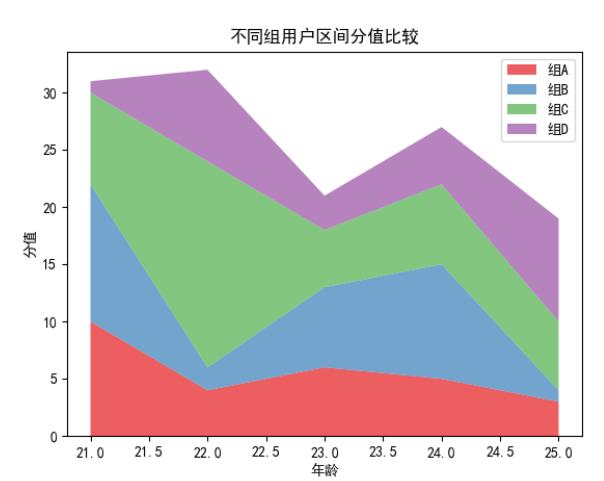
# library
import numpy as np
import seaborn as sns
x=range(21,26)
y=[ [10,4,6,5,3], [12,2,7,10,1], [8,18,5,7,6],[1,8,3,5,9] ]
labels = ['组A','组B','组C','组D']
pal = sns.color_palette("Set1")
plt.stackplot(x,y, labels=labels, colors=pal, alpha=0.7 )
plt.ylabel('分值')
plt.xlabel('年龄')
plt.title('不同组用户区间分值比较')
plt.legend(loc='upper right')
plt.show()
#——————————————————————————————————————————————————————————
四、运行结果及分析
五、实验总结
数据可视化就是通过对原始数据进行标准化、结构化的处理,把它们整理成数据表。将这些数值转换成视觉结构,通过视觉的方式把它表现出来。将视觉结构进行组合,把它转换成图形传递给用户,用户通过人机交互的方式进行反向转换,去更好地了解数据背后有什么问题和规律。
如果从技术上来说,大数据可视化的实施步骤主要有四项,第一就是需求分析,第二就是建设数据仓库或者数据集市模型,第三就是数据抽取、清洗、转换、加载,第四就是建立可视化分析场景。
以上是关于可视化分析(机器学习)的主要内容,如果未能解决你的问题,请参考以下文章