Person re-identification行人重识别
Posted 郑烯烃快去学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Person re-identification行人重识别相关的知识,希望对你有一定的参考价值。
在做跟随车的时候需要考虑到这么一个问题:需要精准的识别要跟随的人,并且这个人是一个背向你的状态。那么在这就提到一个概念:Person re-identification。简单来说,就是在多摄像头的复杂场景中,快速定位查找指定目标的所有结果。基本思想其实就是相似度匹配。这个网络模型在很多场景是可以见到的,比如说监控跟踪人物,各种人脸识别闸机等等,首先先介绍几个常用的模型,至于使用我会后面部署到NVidia的Xavier上以及地平线的旭日x3上的。
目录
0x02 《Relation-Aware Global Attention》
0x03 《Relation Network for Person Re-identification》
0x01 Person re-identification
(一)概述与挑战
行人重识别,简单来说就是要在不同时间、地点或者相机上匹配到一个特定的人,属于图像检索的内容。其难点和核心便在于如何从杂乱的背景、姿态的多样性以及存在遮挡等各种复杂多变的情况下,有效地从人像图像中鉴别并提取视觉特征(即区分出不同的人)。


那么这个行人重识别,所面临的挑战有什么:
-
低分辨率
-
遮挡
-
视角、姿态变化
-
光照变化
-
视觉模糊性

(二)评估标准
-
基本所有论文都会提到两个概念:rank1和map值。
-
返回结果中包含了一系列的图像,rank1指的是第一张结果正确。

- map值的计算:map要计算多次输入的综合ap结果,每张测试图片的计算其实可以简单概述为:一张正确图像本应该是第几个。
比如下面这个例子:
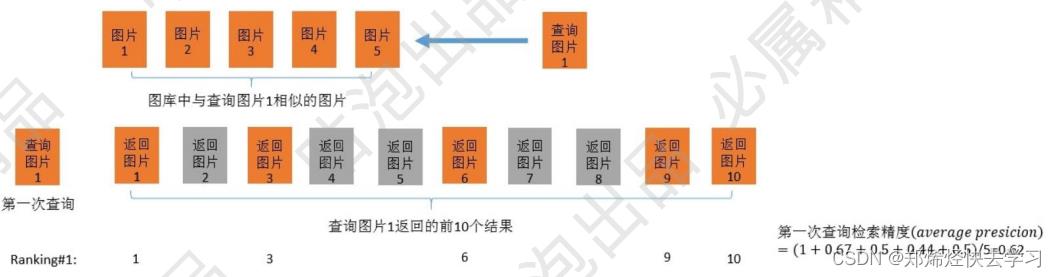
其中的ap计算为(1+2/3+3/6+4/9+5/10)。
之后进行第二次查询:

-
可以得到下一个ap为(1/2+2/5+3/7)。
那么我们就可以得到两个测试数据,ap分别为0.62,0.44,则map为(0.62+0.44)/2 = 0.53。
(三)损失函数的定义
通常是分类损失+Triplet loss(目标其实就是为了让特征提取的更好)
Triplet loss需要准备三份数据(可以从一个batch中选择),其中Anchor表示当前数据,Positive是跟A相同人的数据,Negative是不同人的数据。(三元组损失)
Triplet loss步骤如下:
-
分别对3份数据进行编码。
-
三份数据经过的网络是一样的。
-
计算之间的差异,通过差异值来更新权重值。

其目的也很简单,只需让A与P非常接近,A与N尽可能远离。公式:
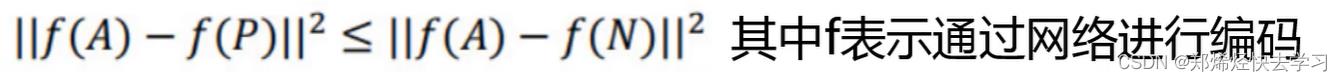
是否会存在问题呢?如果f把所有的输入都编码成0,依旧成立。所以这个目标需要重新修改一下:
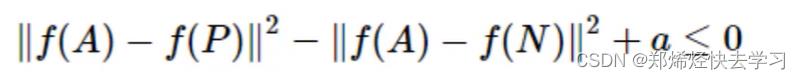
其中a通常叫做margin,也就是间隔,表示d(A,P)与d(A,N)至少得相差多少。所以我们就可以得到下面的这条公式:
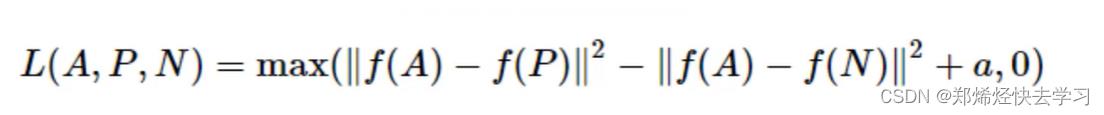
对于约束条件d(A,P)+a<=d(A,N),实际中用的最多的是hard negative方法,也就是在选择样本的时候,要让d(A,P)要约等于d(A,N),这样可以给网络带来一些挑战,才能刺激它来学习,不要让它原封不动。
0x02 《Relation-Aware Global Attention》
在看这篇论文之前,我们可以想到如何通过提取好的照片来进行特征提取,可以有多种方法,比如对这张图片进行分割,分割为4个部分,之后对每个部分进行比对,这也是一个不错的提议,那么就看看RAG是怎么提取特征的叭:
(一)模型架构

论文地址:
https://arxiv.org/pdf/1904.02998v1.pdf
注意力机制通过关注重要特征和抑制不重要的特征来提到表示能力。从17年开始,这个注意力机制一直受到关注,不仅在NLP领域上,在CV领域上也得到了很多的关注。在卷积神经网络中,注意力通常是通过局部卷积来学习的,它忽略了全局信息和隐藏关系。如何有效的利用远程上下文信息来全局的学习注意力还没有得到充分的研究。但是在本文中提到了一个有效的关系感知全局注意力的模块,以充分利用全局相关性来推断注意。具体来说,在计算某个特征位置的注意力时,为了掌握全局范围的信息,我们建议这些关系,即它与所有特征位置的成对相关性/亲和性,以及特征本身堆叠在一起,以便通过卷积运算来学习注意力。给定一个中间特征图,我们已经验证了在空间和通道上的有效性。
简单来说,本文主要提出了一个RGA(Relation-Aware Global Attention)模块,该模块可以提取空间上不同区域之间的关系向量,从而每个区域的特征能够抓住局部,同时把握全局:

那么a图我们可以理解为是一个空间维度,b图则是一个通道维度:
-
空间注意力:
对于一个输入为C×H×W的特征向量,在上图中,我们可以表示为C×3×3大小。分别输入到两个卷积层c1和c2。经过c卷积层后转化为向量[9,c],两者矩阵相乘,等到[9×9]的矩阵,代表每个向量之间的关系。再将得到的9×9矩阵经过reshape操作分别得到两个[9,3,3]和[9,3,3]矩阵。得到的两个relation feature矩阵可以图书的理解为,我和你之间的关系,以及你和我之间的关系。原始的输入值再经过一个卷积层取所有通道特征图的均值得到一个[1,3,3]的矩阵,因为只需要提取空间信息(所在位置),所以将通道数变为1。最后把这三个特征矩阵连接到一起[9+9+1,3,3]。因为卷积网络权值共享,将其压缩为[1,3,3],从而得到每一个位置的权重值,最后与输入x相乘。
-
通道注意力
和空间注意力相似,只不过通道做卷积和reshape操作,获得每个通道的权重值,即判断哪一个特征图重要。
那么我们再看看之前学习过的attention的各种模型:

a图也就是我们常用的卷积神经网络,对于每一个特征x学习一个attention值,因此只能学习到局部特征,而忽视了全局特征。
b图使用全连接网络(可以参照《Attention is all you Need》),学习到的attention值来自于所有特征向量的连接,虽然学习到了全局特征,但参数量过大,计算量太大。
c图通过考虑全局的相关信息学习attention的值,即对每一个特征向量,全局的关联信息用一个关系对ri = [ri,1, · · · , ri,5, r1,i, · · · , r5,i]表示,其中其中ri,1表示第i个特征节点和第一个特征节点的关系,以此类推。用一个符号ri&j = [ri,j , rj,i]表示,所有的ri&j组合可以得到x1一个关联特征,组合在一起得到下图中的特征向量r1,再和原始特征向量x1拼接,得到一个relation-aware feature y1, y1 = [x1, r1 ],作为提取attention的特征向量。因此可以看出,基于特征x1得到的attention值a1既包含了局部特征x1,又包含了全局所有特征之间的关系。
(二)项目环境与数据集架构分析
数据集的下载:CUHK Re-ID
在这我下载的是第三个数据集。之后根据GitHub下所说的:
创建一个名为 的文件
cuhk03/夹/YOUR_DATASET_PATH/。/YOUR_DATASET_PATH/cuhk03/从CUHK Re-ID下载数据集并提取cuhk03_release.zip. 然后你会有/YOUR_DATASET_PATH/cuhk03/cuhk03_release.从person-re-ranking下载训练/测试拆分协议。将两个 mat
cuhk03_new_protocol_config_detected.mat文件cuhk03_new_protocol_config_labeled.mat放在data/cuhk03. 在默认模式下,我们使用这个新的拆分协议 (767/700)。最后,数据结构看起来像cuhk03/ cuhk03_release/ cuhk03_new_protocol_config_detected.mat cuhk03_new_protocol_config_labeled.mat ...
对于香港科技大学的数据集,我们可以得到:数据集1_001_1_02.png,1为摄像头的id,001为人的id,1为这么一对摄像头中,是前面那个还是后面那个,最后一个数为第几个图。对于数据集的处理,在源码中有这么一段是用于处理.mat文件的,这个文件就是你下载下来的数据集中附带的,它可以对数据集进行区分:
def _process_images(img_refs, campid, pid, save_dir):
img_paths = [] # Note: some persons only have images for one view
for imgid, img_ref in enumerate(img_refs):
img = _deref(img_ref)
# skip empty cell
if img.size == 0 or img.ndim < 3: continue
# images are saved with the following format, index-1 (ensure uniqueness)
# campid: index of camera pair (1-5)
# pid: index of person in 'campid'-th camera pair
# viewid: index of view, 1, 2
# imgid: index of image, (1-10)
viewid = 1 if imgid < 5 else 2
img_name = ':01d_:03d_:01d_:02d.png'.format(campid+1, pid+1, viewid, imgid+1)
img_path = osp.join(save_dir, img_name)
imsave(img_path, img)
img_paths.append(img_path)
return img_paths最后他会生成两个文件夹:images_detected\\images_labeled,并且在main.imgreid.py中进行处理:
def get_data(name, split_id, data_dir, height, width, batch_size, num_instances,workers, combine_trainval, eval_rerank=False):
## Datasets
if name == 'cuhk03labeled':
dataset_name = 'cuhk03'
dataset = data_manager.init_imgreid_dataset(
root=data_dir, name=dataset_name, split_id=split_id,
cuhk03_labeled=True, cuhk03_classic_split=False,
)
dataset.images_dir = osp.join(data_dir, '/CUHK03_New/images_labeled/')
elif name == 'cuhk03detected':
dataset_name = 'cuhk03'
dataset = data_manager.init_imgreid_dataset(
root=data_dir, name=dataset_name, split_id=split_id,
cuhk03_labeled=False, cuhk03_classic_split=False,
)
dataset.images_dir = osp.join(data_dir, '/CUHK03_New/images_detected/')
## Num. of training IDs
num_classes = dataset.num_train_pids(三)参数配置与整体架构分析

以上就是在进行训练的过程。其中进行了很多次卷积处理,并且进行残差连接,不断地进行特征提取。那么接下来就是核心的步骤了,判断你和我之间的关系,我和你之间的关系:
Spatial Relation-Aware Attention 空间关系感知注意力—RGA-S

可以注意到它构建了两个大小一样的辅助特征图,用于存储关系。之后进行resize,更改维度,调换顺序,以便于计算你我关系,使矩阵可以更好的计算。做完乘积的操作后,即可以得到我跟你的关系,以及你跟我的关系,将其拼接在一起,resize回去,resize为256个特征的向量图,最后我们将每个特征都求取平均,获得一个平均值,得到一个矩阵,然后拼起来,再浓缩起来,最后乘以x,变换为原来的大小。以上就是空间注意力机制的处理。
通过CNN层得到的特征图为的shape为HWC,设计的RGA-S空间关系感知注意力来学习大小为H*W的空间注意力图,取每个空间位置的C维特征向量作为特征节点。所有的空间形成位置形成一个有N=WxH个节点的图形,通过建立空间中节点之间的相似性矩阵,即NxN的矩阵,来表示节点之间的成对关系。 为了方便解释RGA-S如何具体实现,我们以经过第一个残差块res1_layer的RGA-S1为例来给予说明,其它的RGA-S实现于此一样,只不过是特征图的H和W不一样而已。经过数据增强输入图片的shape为3x256x128,首先经过Zeropadding,然后是步长stride=2的卷积块(Conv+BN+Relu),得到的shape为64x128x64,再经过stride=2的MaxPooling,得到的shape为64x64x32,经过残差网络的第一个残差块,其中的卷积步长stride=1,得到res1_layer的shape为256x64x32,作为RGA-S1的输入。
RGA-S1的输入input为256x64x32,两个去向,如上图所示,一个是向右做embedding操作,即嵌入全局信息。具体做法是经过一个1x1卷积进行降维,将通道数减少为 256/8 =32,得到g_xs,此时shape为32x64x32,由于我们需要实现的是空间注意力机制,因此沿着通道数方向,进行mean求平均操作,将64维通道数使用其均值进行替代,此时g_xs的shape维1x64x32。第二个去向向下的操作,首先经过一个1x1卷积进行降维,将通道数减少为 256/8 =32,此时shape为32x64x32,记为theta_xs;进行了两次这样的操作,另一个记为phi_xs,shape同样为32x64x32。然后我们将theta_xs和phi_xs进行reshape操作,reshape为32x(64x32)=32x2048,然后再将theta_xs经过一次维度的调换permute,故此时的shape为2048x32,而phi_xs的shape为32x2048,于是将theta_xs和phi_xs进行矩阵的乘法,得到Gs,shape为2048x2048,至此Gs表示的就是该特征图空间中2048个特征节点之间的成对关系。首先找到我和别人的成对关系,将Gs进行reshape操作得到Gs_out,shape为 2048,64,32。其次,找到别人和我之间的成对关系,于是将Gs进行维度调换permute操作,得到的shape为2048x2048,再进行reshape操作得到Gs_in,shape为2048,64,32,进行关系对的堆叠cat操作,得到Gs_joint,shape为2048+2048=4096,64,32,然后再将Gs_joint进行1x1操作将4096浓缩成2048/8=256, 使用256维来代表空间成对关系,此时Gs_joint的shape变为256,64,32。于是,将全局的信息与空间中特征点之间的关系进行堆叠操作,得到ys,shape为257,64,32,再将关系维度使用1x1卷积进行浓缩,先将维度压缩成257/8=32,再使用1x1卷积压缩为1,shape为1,64,32,即我们得到了1个特征图上空间中特征节点之间的关系,输入input的shape为256,64,32,我们直到空间中的特征节点在即使在不同的特征图中其位置是不变的,于是我们将上述得到的一个特征节点关系特征图进行repeat操作,得到256个关系特征图,shape变为1,64,32->256,64,32,然后求sigmoid,转化为0-1之间的概率值,最后于输入input进行相乘操作,得到最后的输出256,64,32,即输出带有空间注意力的特征节点值。 引用:行人重识别—Relation-Aware Global Attention模型介绍及代码实现_ManManMan池的博客-CSDN博客_行人重识别代码实现
主要代码:
def forward(self, x):
b, c, h, w = x.size()
if self.use_spatial:
# spatial attention
theta_xs = self.theta_spatial(x)
phi_xs = self.phi_spatial(x)
theta_xs = theta_xs.view(b, self.inter_channel, -1)
theta_xs = theta_xs.permute(0, 2, 1)
phi_xs = phi_xs.view(b, self.inter_channel, -1)
Gs = torch.matmul(theta_xs, phi_xs)
Gs_in = Gs.permute(0, 2, 1).view(b, h*w, h, w)
Gs_out = Gs.view(b, h*w, h, w)
Gs_joint = torch.cat((Gs_in, Gs_out), 1)
Gs_joint = self.gg_spatial(Gs_joint)
g_xs = self.gx_spatial(x)
g_xs = torch.mean(g_xs, dim=1, keepdim=True)
ys = torch.cat((g_xs, Gs_joint), 1)
W_ys = self.W_spatial(ys)
if not self.use_channel:
out = F.sigmoid(W_ys.expand_as(x)) * x
return out
else:
x = F.sigmoid(W_ys.expand_as(x)) * x
Channel Relation-Aware Attention 通道关系感知注意力—RGA-C
那么下面则对应的是channel的处理:
if self.use_channel:
# channel attention
xc = x.view(b, c, -1).permute(0, 2, 1).unsqueeze(-1)
theta_xc = self.theta_channel(xc).squeeze(-1).permute(0, 2, 1)
phi_xc = self.phi_channel(xc).squeeze(-1)
Gc = torch.matmul(theta_xc, phi_xc)
Gc_in = Gc.permute(0, 2, 1).unsqueeze(-1)
Gc_out = Gc.unsqueeze(-1)
Gc_joint = torch.cat((Gc_in, Gc_out), 1)
Gc_joint = self.gg_channel(Gc_joint)
g_xc = self.gx_channel(xc)
g_xc = torch.mean(g_xc, dim=1, keepdim=True)
yc = torch.cat((g_xc, Gc_joint), 1)
W_yc = self.W_channel(yc).transpose(1, 2)
out = F.sigmoid(W_yc) * x
return out做法跟之前一样,新建两个辅助的特征向量图,之后进行乘积,拼接,在通过卷积层浓缩 ,然后再进行拼接,得到总的特征图,在使用两个卷积,将其转为256个图中的权重分配,再乘上x即可。
给定一个中间特征图为的shape为HWC,设计的RGA-C空间关系感知注意力来学习一个通道数为C的通道注意力向量,将每个通道数上的d=HxW维特征向量作为特征节点,所有通道形成C个节点的图形,通过建立节点之间的相似性矩阵,即CxC的矩阵,来表示节点之间的成对关系。
RGA-C1的输入input为256x64x32,先对input进行reshape操作,shape为256x2048,再进行维度的调换permute操作,shape为2048x256,unsqueeze操作,得到xc,shape为2048,256,1。由于我们是在通道上实现关系感知全局注意力,因此需要将特征形式转化为与RGA-S1类似的输入形式。得到的新输入xc有两个去向,如上图所示,一个是向右做embedding操作,即嵌入全局信息。具体做法是经过一个1x1卷积进行降维,将通道数减少为 256/8 =32,得到g_xc,此时shape为32x256x1,由于我们需要实现的是空间注意力机制,因此沿着空间的方向,进行mean求平均操作,将32维空间特征使用其均值进行替代,此时g_xc的shape维1x256x1。第二个去向向下的操作,首先经过一个1x1卷积进行降维,将通道数减少为 256/8 =32,此时shape为32x256x1,记为theta_xc;进行了两次这样的操作,另一个记为phi_xc,shape同样为32x256x1。将theta_xc和phi_xc进行squeeze操作,去掉最后一个维度,因为我们计算关系矩阵时只需要二维的,此时theta_xc和phi_xc的shape都为32x256,再将theta_xc进行permute维度调换操作,shape为256x32,为了进行矩阵乘法操作,然后将theta_xc和phi_xc进行矩阵的乘法,得到Gc,shape为256x256,至此Gc表示的就是该特征图通道上256个特征节点之间的成对关系。首先找到我和别人的成对关系,将Gc进行unsqueeze操作得到Gc_out,shape为 256,256,1。其次,找到别人和我之间的成对关系,于是将Gs进行维度调换permute操作,得到的shape为256x256,再进行unsqueeze操作得到Gc_in,shape为256,256,1,进行关系对的堆叠cat操作,得到Gc_joint,shape为256+256=512,256,1,然后再将Gc_joint进行1x1操作将512浓缩成256/8=32, 使用32维来代表通道上特征节点间关系,此时Gc_joint的shape变为32,256,1 。最后,将全局的信息与空间中特征点之间的关系进行堆叠操作,得到yc,shape为33,256,1,再将关系维度使用1x1卷积进行浓缩,先将维度压缩成33/8=4,再使用1x1卷积压缩为1,shape为1,256,1,最后再进行维度的调换permute,shape变为 256,1,1,。即我们得到了在通道维度上256个特征节点之间的关系,然后求sigmoid,转化为0-1之间的概率值,最后与输入input256x64x32进行相乘操作,得到最后的输出256,64,32,即输出带有通道注意力的特征节点值。 引用:行人重识别—Relation-Aware Global Attention模型介绍及代码实现_ManManMan池的博客-CSDN博客_行人重识别代码实现
损失函数loss
当进行网络的训练时,网络的输出结果应该是两个,即输入图像的编码特征向量和类别的分类结果。编码的特征向量用于计算三元组损失Triplet loss,类别的结果用于计算类别损失。
-
分类损失:采用了平滑标签的交叉熵损失函数。具体实现的代码:
class CrossEntropyLabelSmoothLoss(nn.Module):
"""Cross entropy loss with label smoothing regularizer.
Reference:
Szegedy et al. Rethinking the Inception Architecture for Computer Vision. CVPR 2016.
Equation: y = (1 - epsilon) * y + epsilon / K.
Args:
num_classes (int): number of classes.
epsilon (float): weight.
"""
def __init__(self, num_classes, epsilon=0.1, use_gpu=True):
super(CrossEntropyLabelSmoothLoss, self).__init__()
self.num_classes = num_classes
self.epsilon = epsilon
self.use_gpu = use_gpu
self.logsoftmax = nn.LogSoftmax(dim=1)
def forward(self, inputs, targets):
"""
Args:
inputs: prediction matrix (before softmax) with shape (batch_size, num_classes)
targets: ground truth labels with shape (num_classes)
"""
log_probs = self.logsoftmax(inputs)
# 进行one-hot编码 batch,num_classes
targets = torch.zeros(log_probs.size()).scatter_(1, targets.unsqueeze(1).cpu(), 1)
if self.use_gpu: targets = targets.cuda()
# 进行标签平滑
targets = (1 - self.epsilon) * targets + self.epsilon / self.num_classes
loss = (- targets * log_probs).mean(0).sum()
return loss```c
- 三元组损失
三元组损失需要准备3份数据,我们都是从一个batch中选取的,其中包含 了Anchor Positive Negative的信息,之后使用AP AN对map值进行计算。可以看看上面的有关计算:
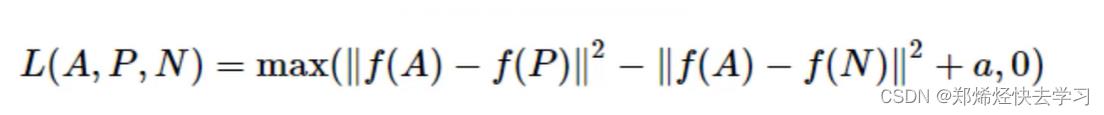
f表示的就是CNN进行特征提取,a通常叫做margin,也就是间隔,表示d(A,P)和d(A,N)至少得相差多少,但是我们直到A和P是相同的数据,它们的距离肯定很小,而A和N是不同的数据,距离自然很大。因此在实际中,我们在三元组损失中添加了hard negative mining的方法,具体做法就是,假设我们的一个batch中共8张图像,其中前四张是同一个人的一组图像,而后四张与前四张不是同一个人的一组图像,我们假设第一章图像就是当前的数据,对于hard negative,我们就是在第2-4张图像中,找到与当前数据距离最大的图像,即使||f(A)-f(P)||尽可能的很大,而在后四张图像中找到与当前数据距离最小的图像,即使||f(A)-f(N)||尽可能的很小。也就是在选择样本的时候让d(A,P)和d(A,N)尽可能相等,给网络一些挑战,才能刺激它来学习。
class TripletHardLoss(object):
def __init__(self, margin=None, metric="euclidean"):
self.margin = margin
self.metric = metric
if margin is not None:
self.ranking_loss = nn.MarginRankingLoss(margin=margin)
else:
self.ranking_loss = nn.SoftMarginLoss()
def __call__(self, global_feat, labels, normalize_feature=False):
# global_feat N,2048
if normalize_feature:
global_feat = normalize(global_feat, axis=-1)
if self.metric == "euclidean":
# 计算batch之间的相互距离
dist_mat = euclidean_dist(global_feat, global_feat)
elif self.metric == "cosine":
dist_mat = cosine_dist(global_feat, global_feat)
else:
raise NameError
dist_ap, dist_an = hard_example_mining(
dist_mat, labels)
y = dist_an.new().resize_as_(dist_an).fill_(1)
if self.margin is not None:
loss = self.ranking_loss(dist_an, dist_ap, y)
else:
loss = self.ranking_loss(dist_an - dist_ap, y)
prec = (dist_an.data > dist_ap.data).sum() * 1. / y.size(0)
return loss
其他的东西,就是类似于resnet50了。
训练传入参数:

0x03 《Relation Network for Person Re-identification》
论文地址:https://arxiv.org/pdf/1911.09318.pdf

(一)整体框架
局部特征与全局关系的计算方法
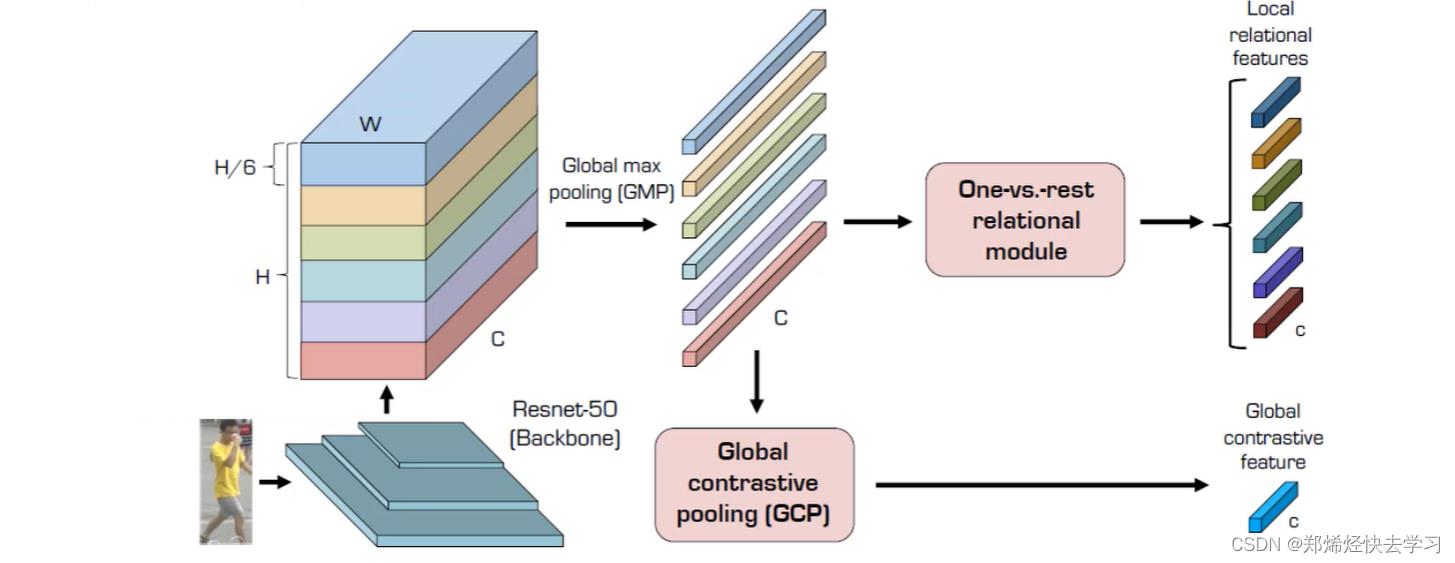
-
特征图局部特征提取,对图像进行切割。(假设六份)
-
maxpooling:六个局部特征代表,再求一个整体特征,之后就可以求得局部与整体的关系。(GCP)
-
再计算当前的这个特征与其他特征之间的关系,形成一个向量。
(二)特征分组方法
-
首先对整体进行特征提取,先将输入数据resize,然后输入到resnet中。基本所有的ReID模型都是先进行这一步,加载imagene预训练的resnet50模型。
-
将特征图分块,直接在h维度进行截取,并没有利用其他辅助信息,为了得到更综合的特征,源码分了三组实验。
(三)GCP模块特征融合方法
-
计算GCP特征,avgPool会引入局部与背景信息,其差异特征可以更好的描述局部搞关系,一定程度上去掉了一些噪音特征的干扰。(光照、遮挡等)

为什么要使用avgPool求得平均特征?不妨想想maxPool所带来的利弊,maxPool会把这个特征进行放大,但是会忽略掉一些小特征。如果加了avgPool会带进去一些噪音,比如背景。所以我们综合一下,各取所长,使用(Avg-max)即可体验局部之间的关系。怎么理解呢,max可以理解为各个核心,之后使用分散的特征来区别之间的关系,即可很好的描述了局部关系。

GAP则相对于全局都有了,GMP相当于最核心那一块,GCP之后相对于各个关键点的信息了(contrastive)。
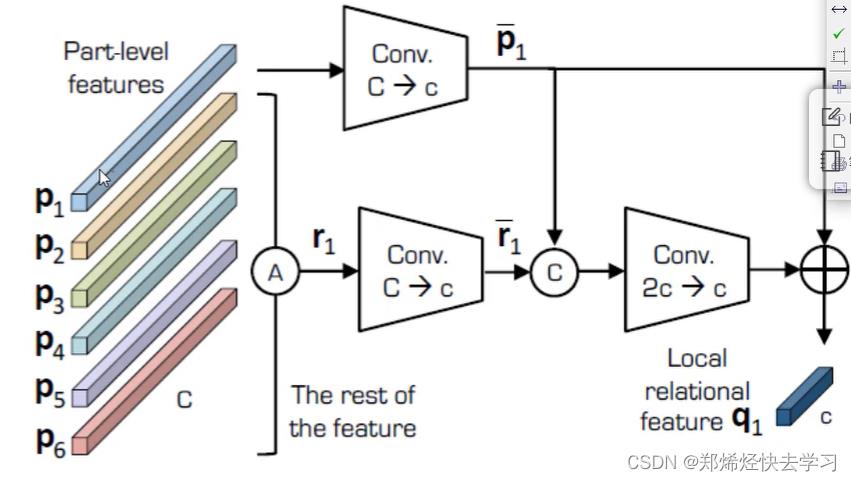
(四)one Vs reset方法
我们以p1为例子,我们将除了p外的其他特征做一次avgPool,在做一层conv,再把p1传进来做一次conv,之后将其特征融合,即可知道p1与其他人之间的关系。之后我们再加入p1,就可以得到q1。之后p2.....pn都是做一样的处理。
出发点在于别把局部信息孤立来算,有点类似于attention的方法。
(五)损失函数应用位置
损失有分类损失以及三元组损失,他们可以加在这些地方:

以上是关于Person re-identification行人重识别的主要内容,如果未能解决你的问题,请参考以下文章