python爬虫爬取国家科技报告服务系统数据,共计30余万条
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫爬取国家科技报告服务系统数据,共计30余万条相关的知识,希望对你有一定的参考价值。
python爬虫爬取国家科技报告服务系统数据,共计30余万条
按学科分类【中图分类】
共计三十余万条科技报告数据
爬取的网址:https://www.nstrs.cn/kjbg/navigation

!!!
如果要完整地跑起来代码,需要先看一下我的这篇博客,完成IP代理池的相关配置:
https://www.cnblogs.com/rainbow-1/p/16725503.html
!!!
分析网站数据来源可以发现,是使用的post方式的请求,且参数列表如下:

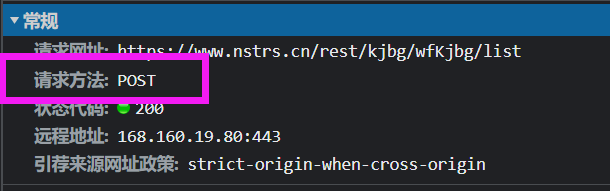
那么我们需要做的就是模拟这个请求,同时需要带上我们自定义的参数,这里面需要的其实一个就是页码pageNo,另一个是分类,如下图:

parms =
"pageNo": i,
"competentOrg": "",
"jihuaId": "",
"fieldCode": "",
"classification": name, # 修改
"kjbgRegion": "",
"kjbgType": "",
"grade": ""
下面是代码:
爬虫方法report_crawler
也就是你需要直接运行的方法。
我这部分是从"社会科学总论"这个分类开始爬的,前面那些如果需要爬,就直接改pageList页码列表、nameList名称列表、tableList数据库表列表就可以【切记是一 一对应的!】
import json
import random
from time import sleep
import requests
from fake_useragent import UserAgent
from report_data.into_mysql import insert_mysql
from report_data.ip_redis import my_redis
"""
post方法参数
params:字典或字节序列,作为参数增加到链接中
data:字典,字节序列或文件对象,作为请求的内容
json:JSON格式的数据,作为Request的内容
headers:字典,HTTP定制头(模拟浏览器进行访问)
cookies:字典或CpplieJar,Request中的cookie
auth:元祖,支持HTTP认证功能
files:字典类型,传输文件
timeout:设定超时时间,秒为单位
proxies:字典类型,设定访问代理服务器,可以增加登陆认证
allow_redirects:True//False,默认为True,重定向开关
stream:True/False,默认为True,获取内容立即下载开关
verify:True/False,默认为True,认证SSL证书开关
cert:本地SSL证书路径
"""
# 页码pageList
# 分类名称参数列表 nameList
#
def get_report(page,name,tableName):
# ------------------------------ 修改页码
for i in range(1,page):
print("---------------------------------")
ua = UserAgent()
print("【随机 UserAgent:】" + ua.random) # 随机产生headers
temp_headers = ua.random
# --------------------------------------
test_redis = my_redis()
temp_proxy = test_redis.get_ip()
print("【随机 IP:】" + temp_proxy)
url="https://www.nstrs.cn/rest/kjbg/wfKjbg/list"
# url2 = "https://www.nstrs.cn/rest/kjbg/wfKjbg/list?pageNo=2&competentOrg=&jihuaId=&fieldCode=&classification=医药、卫生&kjbgRegion=&kjbgType=&grade="
parms =
"pageNo": i,
"competentOrg": "",
"jihuaId": "",
"fieldCode": "",
"classification": name, # 修改
"kjbgRegion": "",
"kjbgType": "",
"grade": ""
other_parms=
User-Agent: temp_headers,
https: http://+temp_proxy,
http: http://+temp_proxy
sleeptime = random.uniform(0, 0.7)
sleep(sleeptime)
# print(url)
response = requests.post(url, parms, other_parms)
response.encoding=utf8
print(response.text+\\n)
response_data = response.text # 返回数据
json_data = json.loads(response_data) # 封装字典
res_list_data = json_data[RESULT][list] # 一页 长度为10的list [ , , ... ] len=10
"""
重新构建一个 list [ ]
"""
for item in res_list_data:
insert_mysql(item,name,tableName)
return
if __name__ == __main__:
# 页码 pageList []
pageList = [788,779,656,584,573,510,440,361,
315,226,224,220,155,112,112,
87,53,50,39,33,18,12,5,4,2,2,2,2]
nameList = [
"社会科学总论",
"环境科学、安全科学",
"建筑科学",
"轻工业、手工业",
"数理科学与化学",
"能源与动力工程",
"电工技术",
"矿业工程",
"经济",
"文化、科学、教育、体育",
"水利工程",
"交通运输",
"自然科学总论",
"石油、天然气工业",
"冶金工业",
"武器工业",
"航空、航天",
"哲学、宗教",
"原子能技术",
"历史、地理",
"政治、法律",
"艺术",
"语言、文字",
"军事",
"综合性图书",
"文学",
"语言、文学",
"mks主义、ln主义、mzd思想、dxp理论"
]
tableList = ["tech_c","tech_x","tech_tu","tech_ts","tech_o","tech_tk","tech_tm",
"tech_td","tech_f","tech_g","tech_tv","tech_u",
"tech_n","tech_te","tech_tf","tech_tj","tech_v","tech_b","tech_tl",
"tech_k","tech_d","tech_j","tech_h","tech_e","tech_z","tech_i","tech_i","tech_a"]
for i in range(0,len(tableList)):
get_report(pageList[i],nameList[i],tableList[i])
目录方法category
返回一个中图分类号对应的名称
# 用以返回中图分类号
def get_code(key):
code_dict =
"医药、卫生":"R",
"一般工业技术":"TB",
"生物科学":"Q",
"数理科学和化学":"O",
"农业科学":"S",
"工业技术":"T",
"自动化技术、计算机技术":"TP",
"天文学、地球科学":"P",
"无线电电子学、电信技术":"TN",
"金属学与金属工艺":"TG",
"机械、仪表工业":"TH",
"化学工业":"TQ",
"社会科学总论":"C",
"环境科学、安全科学":"X",
"建筑科学":"TU",
"轻工业、手工业":"TS",
"数理科学与化学":"O",
"能源与动力工程":"TK",
"电工技术":"TM",
"矿业工程":"TD",
"经济":"F",
"文化、科学、教育、体育":"G",
"水利工程":"TV",
"交通运输":"U",
"自然科学总论":"N",
"石油、天然气工业":"TE",
"冶金工业":"TF",
"武器工业":"TJ",
"航空、航天":"V",
"哲学、宗教":"B",
"原子能技术":"TL",
"历史、地理":"K",
"政治、法律":"D",
"艺术":"J",
"语言、文字":"H",
"军事":"E",
"综合性图书":"Z",
"文学":"I",
"语言、文学":"I",
"mks主义、ln主义、mzd思想、dxp理论":"A",
res = code_dict.get(key)
return res
if __name__ == __main__:
data = get_code("工业技术")
print(data)

user_agent方法
返回随机headers
from fake_useragent import UserAgent # 下载:pip install fake-useragent
import requests
ua = UserAgent() # 实例化,需要联网但是网站不太稳定-可能耗时会长一些
print(ua.random) # 随机产生
headers =
User-Agent: ua.random # 伪装
# 请求
if __name__ == __main__:
url = https://www.baidu.com/
response = requests.get(url, headers=headers ,proxies="http":"117.136.27.43")
print(response.status_code)
ip_redis方法
从redis数据库取出一个ip并返回(前3000个随机一个,降序排列)
import random
import redis
class my_redis:
def get_ip(self):
r = redis.Redis(host=127.0.0.1, port=6379, db=0,decode_responses=True)
my_redis_data = r.zrange("proxies:universal",1,3000,True)
return random.choice(my_redis_data)
# print(len(my_redis_data))
if __name__ == __main__:
test_redis=my_redis()
data=test_redis.get_ip()
print(data)
into_mysql方法
存入mysql数据库的方法
#连接数据库 获取游标
import pymysql
from report_data.category import get_code
def get_conn():
"""
:return: 连接,游标
"""
# 创建连接
conn = pymysql.connect(host="127.0.0.1",
user="root",
password="reliable",
db="tech",
charset="utf8mb4")
# 创建游标
cursor = conn.cursor() # 执行完毕返回的结果集默认以元组显示
if ((conn != None) & (cursor != None)):
print("数据库连接成功 ...")
else:
print("数据库连接失败!")
return conn, cursor
#关闭数据库连接和游标
def close_conn(conn, cursor):
if cursor:
cursor.close()
if conn:
conn.close()
return 1
# 数据表名
# 中图分类名
def insert_mysql(data,name,tableName):
print(data[title])
id=data[id]
title=data[title]
alternativeTitle=data[alternativeTitle]
creator=data[creator]
abstractEn=data[abstractEn]
keywordsEn=data[keywordsEn]
abstractCn=data[abstractCn]
keywordsCn=data[keywordsCn]
creatOrorganization=data[creatOrorganization]
prepareOrganization=data[prepareOrganization]
publicDate=data[publicDate]
createTime=data[createTime]
projectName=data[projectName]
competentOrg=data[competentOrg]
projectSubjectName=data[projectSubjectName]
projectSubjectId=data[projectSubjectId]
#------------------------------
classification=name # 修改
#------------------------------
classificationCode=get_code(classification) # 需要调用get_code(name)获取
responsiblePerson = data[responsiblePerson]
supportChannel = data[supportChannel]
undertakeOrg = data[undertakeOrg]
kjbgSource = data[kjbgSource]
proposalDate = data[proposalDate]
submittedDate = data[submittedDate]
kjbgRegion = data[kjbgRegion]
collectionDate = data[collectionDate]
collectionNumber = data[collectionNumber]
fieldCode = data[fieldCode]
fieldId = data[fieldId]
kjbgQWAddress = data[kjbgQWAddress]
isNewRecord = data[isNewRecord]
sourceUrl = "https://www.nstrs.cn/kjbg/detail?id="+id # 需要自己拼 https://www.nstrs.cn/kjbg/detail?id=
conn, cursor = get_conn()
# ------------------------------ 修改表名
sql = "insert into `"+tableName+"` (id,title,alternativeTitle,creator,abstractEn," \\
"keywordsEn,abstractCn,keywordsCn,creatOrorganization,prepareOrganization," \\
"publicDate,createTime,projectName,competentOrg,projectSubjectName," \\
"projectSubjectId,classification,classificationCode,responsiblePerson,supportChannel," \\
"undertakeOrg,kjbgSource,proposalDate,submittedDate,kjbgRegion," \\
"collectionDate,collectionNumber,fieldCode,fieldId,kjbgQWAddress," \\
"isNewRecord,sourceUrl) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s" \\
",%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
try:
try:
cursor.execute(sql, [id,title,alternativeTitle,creator,abstractEn,
keywordsEn,abstractCn,keywordsCn,creatOrorganization,prepareOrganization,
publicDate,createTime,projectName,competentOrg,projectSubjectName,
projectSubjectId,classification,classificationCode,responsiblePerson,supportChannel,
undertakeOrg,kjbgSource,proposalDate,submittedDate,kjbgRegion,
collectionDate,collectionNumber,fieldCode,fieldId,kjbgQWAddress,isNewRecord,sourceUrl])
except pymysql.err.IntegrityError:
print("主键冲突!")
conn.commit() # 提交事务 update delete insert操作
except pymysql.err.IntegrityError:
print("error!")
finally:
close_conn(conn, cursor)
return 1
if __name__ == __main__:
print()
最终爬取三十多万条科技报告,按中图分类建立了mysql数据表,分表存储不同分类的数据。
【其中的数理科学和化学,数理科学与化学这两个分类做了合并,合并为数理科学和化学类,属O】
【语言、文学和文学做了合并,同属 I 文学类】



附几张结果图:
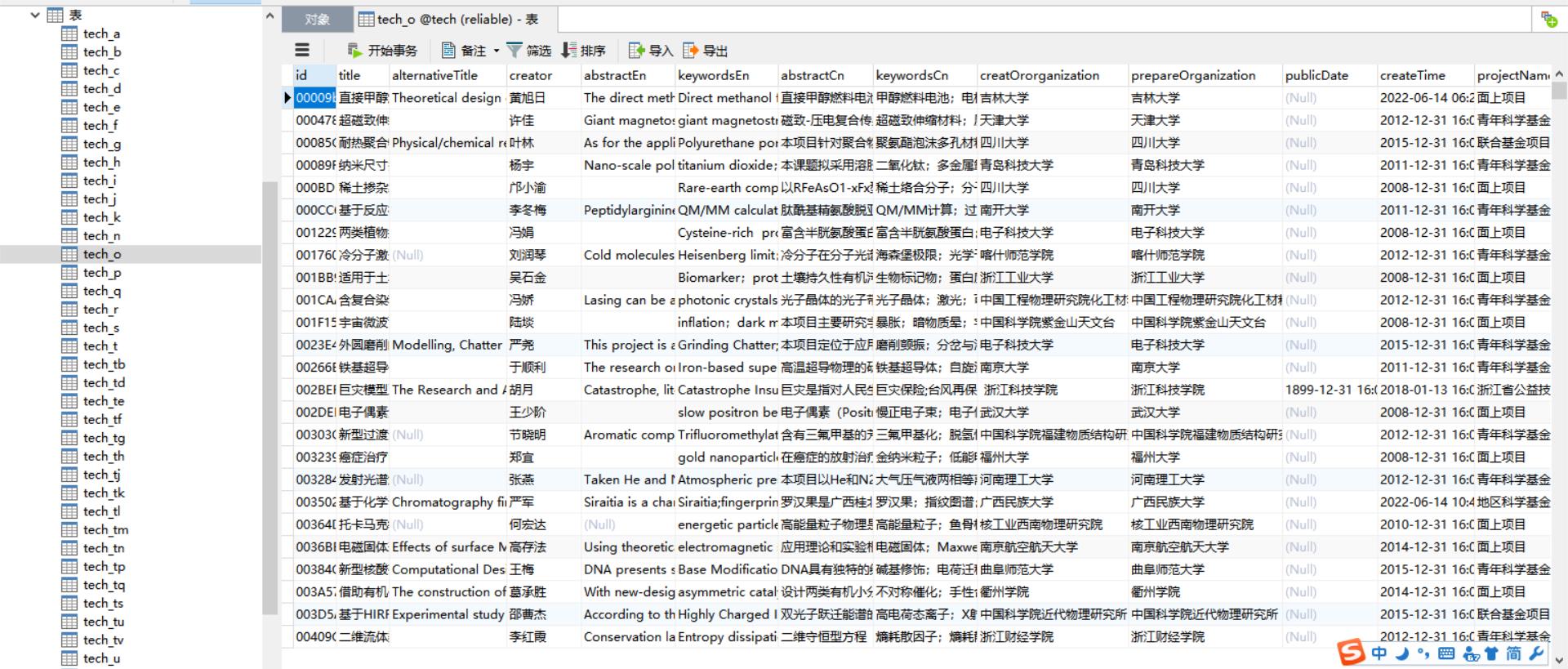
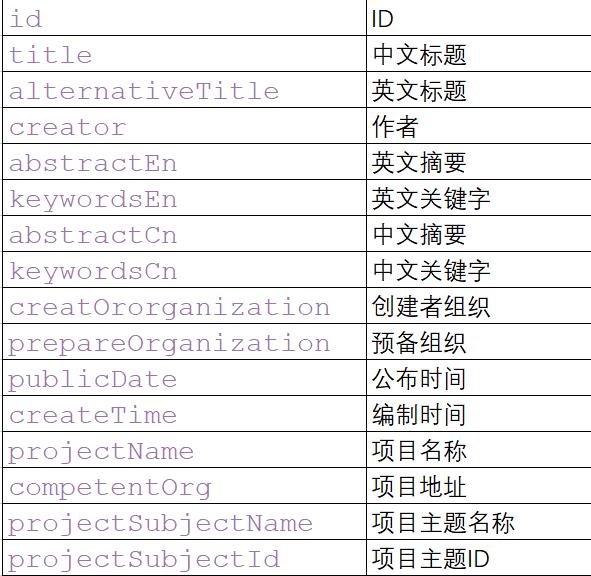
最后说一下数据表结构:
/*
Navicat MySQL Data Transfer
Source Server : reliable
Source Server Version : 80013
Source Host : localhost:3306
Source Database : tech
Target Server Type : MYSQL
Target Server Version : 80013
File Encoding : 65001
Date: 2022-09-24 13:54:05
*/
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for tech_o
-- ----------------------------
DROP TABLE IF EXISTS `tech_o`;
CREATE TABLE `tech_o` (
`id` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT ID,
`title` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci COMMENT 中文标题,
`alternativeTitle` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci COMMENT 英文标题,
`creator` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci COMMENT 作者,
`abstractEn` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci COMMENT 英文摘要,
`keywordsEn` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci COMMENT 英文关键字,
`abstractCn` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci COMMENT 中文摘要,
`keywordsCn` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci COMMENT 中文关键字,
`creatOrorganization` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci COMMENT 创建者组织,
`prepareOrganization` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 预备组织,
`publicDate` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 公布时间,
`createTime` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 编制时间,
`projectName` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 项目名称,
`competentOrg` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 项目地址,
`projectSubjectName` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 项目主题名称,
`projectSubjectId` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 项目主题ID,
`classification` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 中图分类名称,
`classificationCode` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 中图分类号,
`responsiblePerson` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 负责人,
`supportChannel` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 主办方,
`undertakeOrg` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 承办方,
`kjbgSource` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 科技报告来源单位,
`proposalDate` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 提议时间,
`submittedDate` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 提交时间,
`kjbgRegion` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 科技报告所属行政区划,
`collectionDate` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 收集时间,
`collectionNumber` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 收集编号,
`fieldCode` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 领域代码,
`fieldId` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 领域ID,
`kjbgQWAddress` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 报告链接,
`isNewRecord` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 是否新记录,
`sourceUrl` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 国家科技报告服务系统收录链接,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;

如果需要获取这部分数据,可关注我的微信公众号【小杨的挨踢IT生活】,回复 “科技报告” 获取下载链接。

以上是关于python爬虫爬取国家科技报告服务系统数据,共计30余万条的主要内容,如果未能解决你的问题,请参考以下文章