pytorch 中的存储方式
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pytorch 中的存储方式相关的知识,希望对你有一定的参考价值。
1 逻辑存储与内存存储
对于一个Tensor来说,我们可以认为它有两种存储方式
- 逻辑存储

- 内存存储

1.1 高维张量
- 在torch/numpy中, 即使是高维张量在内存中也是存储在一块连续的内存区域中
- 会记录一些元信息来描述数组的"形态", 例如起始地址, 步长 (stride), 大小 (size)等.
- 对高维张量进行索引时我们采用
起始地址 + 地址偏移量的计算方式, 而地址偏移量就需要用到stride和size的信息
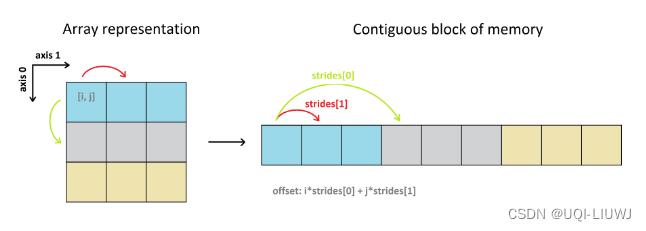
当我们在使用view去修改tensor的时候, 其实我们并没有修改tensor在内存中的存储, 而只是通过修改stride和size来描述张量形状的变化:
1.2 按行展开和按列展开
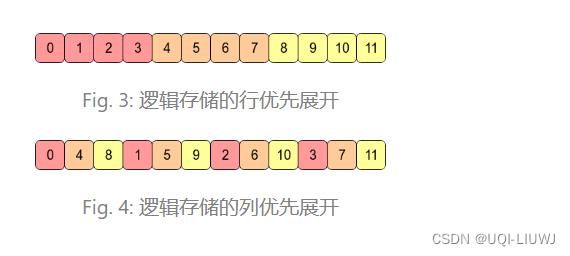
- 如果张量x的行优先展开形式和其内存存储一致, 则我们称之为C-contiguous.
- Numpy, Pytorch中的
contiguous指的就是C-contiguous
- Numpy, Pytorch中的
- 如果张量x的列优先展开形式和其内存存储一致, 则我们称之为Fortran-contiguous.
- Matlab, Fortran中的
contiguous指的是Fortran-contiguous.
- Matlab, Fortran中的
2 View,reshape,permute
2.1 view
view要求输入和输出的tensor都是contiguous的, 否则会throw exception- 换言之, 你不管对一个tensor使用了多少次
view, 你都只是在改变stride和size, 并没有修改这个tensor的内存存储
2.2 reshape
- 对于contiguous的输入,
reshape等于view - 对于incontiguous的输入,
reshape等于tensor.contigous().view- 其中
contiguous()会开辟一块新的内存空间, 将incontiguous的张量按照行优先展开的方式存储进去. - 所以
reshape是有可能修改内存存储的结构的
- 其中
2.3 permute
- 虽然
permute和view一样, 都是修改stride和size, 但是permute并不保证返回的tensor是contiguous的. - 换言之
permute().contiguous()就有可能修改内存存储方式了. 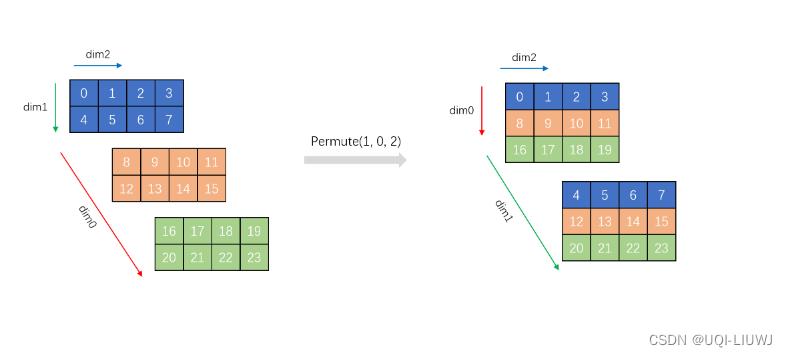
参考文献:Pytorch中的View, Reshape, Permute | Lemon's Blog (coderlemon17.github.io)
以上是关于pytorch 中的存储方式的主要内容,如果未能解决你的问题,请参考以下文章