Sqoop import GC overhead limit exceeded 或者 Halting due to Out Of Memory Error解决思路
Posted 扫地增
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sqoop import GC overhead limit exceeded 或者 Halting due to Out Of Memory Error解决思路相关的知识,希望对你有一定的参考价值。
背景:
最近笔者在公司为公司搭建大数据集群已经小有成果,基本服务已经打通,也做了不少线上任务,但是在任务开发的过程中发现使用sqoop导数据经常会遇到资源不足导致报错,由于sqoop是java开发,虽然以前对这种问题屡见不鲜,但是在大数据集群中这些资源问题就显得特别多OOM,java head space栈溢出、甚至有时候还会出现GC overhead limit exceeded GC的问题。笔者特此总结希望对大家有所帮助。
报错:

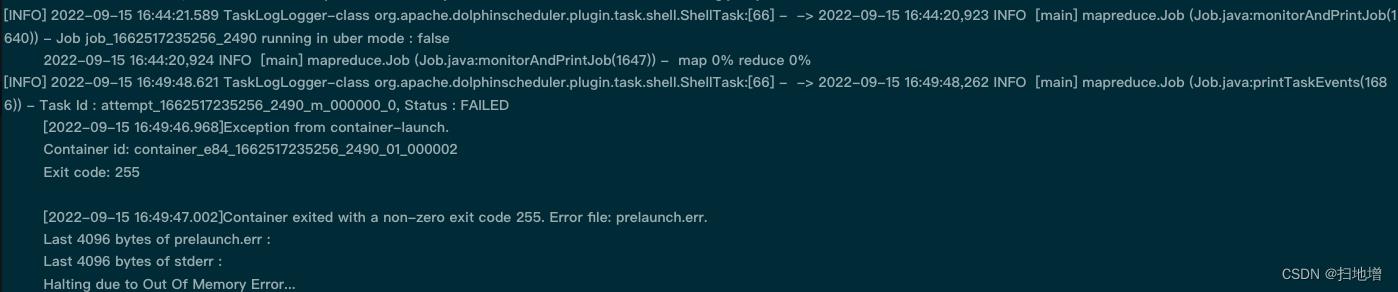
分析
遇到这些问题首先不要慌张,这可能并不是你自己的原因,可能就是资源配置不足引起,这个时候应该灵活应对,因为我们知道向公司伸手要钱实在太难。其实这个问题也要分为几个阶段去看:
出现 – java heap问题
我们应该考虑mysql是否使用了诸如mysql mycat代理,是否是将代理查挂了针对这种情况我们考虑减少每批次抓取数据的条尝试解决。
#配置每次抓取的条数,这个时候应该调小
#sqoop参数
--fetch-size 10000
# mysql JDBC中添加
--connect jdbc:mysql://localhost:3306/your_database&defaultFetchSize=10000&useCursorFetch=true
如果是代理挂了应该及时联系运维重启,然后在设置参数与运维一起进行商讨测试。
Out Of Memory 问题或者GC limit xxxxx问题
在使用sqoop导数据时我们应当知道sqoop只启动maptask,这里以mysql数据导入到hive数据为例,如果不注意设置MapReduce的资源,是会出现一个叫做GC limit xxxxx的错误的。使用一下脚本为例:
sqoop import \\
--connect jdbc:mysql://localhost:3306/your_database \\
--username root \\
--password 123456 \\
--target-dir /user/hive/warehouse/xxxx/xxx \\
--hive-import \\
--hive-database hive_database \\
--hive-table hive_tableName\\
--as-parquetfile \\
--null-string '\\\\N' \\
--null-non-string '\\0' \\
--fields-terminated-by '\\001' \\
--table mysql_tableName \\
--fetch-size 1000
运行这个命令的时候,程序在yarn中申请到了集群配置的内存资源,然后,任务失败了,报出一个GC limit的错误,当出现这样的错误的时候,很显然就是sqoop在进行数据传输的过程当中,因为内存不足,引发了错误。那么,如何让sqoop在创建一个mapreduce的任务时候,使用比较大的硬件资源呢。通过官网的文档得知,sqoop中有一个参数可以调整hadoop的参数,利用sqoop的-D <key=value>的参数可以让sqoop的job启动的时候申请更多的资源,这就提醒我们通用的sqoop脚本并不是在所有的场景下都适用。所以对不同任务因地制宜分配不同资源尤为重要。
因此可以尝试的解决思路有两个:
- 增加每个maptask资源
-D yarn.scheduler.minimum-allocation-mb=8096 \\
-D yarn.scheduler.maximum-allocation-mb=16192 \\
-D mapreduce.map.memory.mb=8096 \\
-D mapreduce.reduce.memory.mb=8096 \\
--connect jdbc:mysql://localhost:3306/your_database \\
--username root \\
--password 123456 \\
--target-dir /user/hive/warehouse/xxxx/xxx \\
--hive-import \\
--hive-database hive_database \\
--hive-table hive_tableName\\
--as-parquetfile \\
--null-string '\\\\N' \\
--null-non-string '\\0' \\
--fields-terminated-by '\\001' \\
--table mysql_tableName \\
--fetch-size 1000
使用上述的脚本之后,程序占用的内存明显提升,如果所需资源和当前资源差别不大这时候就可以解决掉问题。
简单介绍下这几个参数:
- yarn.scheduler.minimum-allocation-mb
每个container想RM申请内存的最小大小。兆字节。内存请求小于此值,实际申请到的是此值大小。默认值偏大 - yarn.scheduler.maximum-allocation-mb
每个container向RM申请内存的最大大小,兆字节。申请值大于此值,将最多得到此值内存。注意设置的值一定要小于集群自身配置的最大值,否则报错,这很容易理解我箱子就这么大,你给我箱子划分空间最大也就是箱子这么大 - mapreduce.map.memory.mb
一个 Map Task 可使用的内存上限(单位:MB),默认为 1024。如果 Map Task 实际使用的资源量超过该值,则会被强制杀死。 - mapreduce.reduce.memory.mb
一个 Reduce Task 可使用的资源上限(单位:MB),默认为 1024。如果 Reduce Task 实际使用的资源量超过该值,则会被强制杀死。 - 增加maptask数量
这种情况主要针对当前所配置的资源和所需资源差别比较大。可以考虑多channel方式,需要配置如下参数:
--split-by `field`
-m 10
如果以上方案一起使用都不起作用,建议更换导数据工具,不要死乞白赖的吊死在sqoop上,因为不至于为了导数据去增加集群资源配置。
以上是关于Sqoop import GC overhead limit exceeded 或者 Halting due to Out Of Memory Error解决思路的主要内容,如果未能解决你的问题,请参考以下文章