Elasticsearch - Elasticsearch 优化(十五)
Posted MinggeQingchun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch - Elasticsearch 优化(十五)相关的知识,希望对你有一定的参考价值。
一、硬件选择
Elasticsearch 的基础是 Lucene,所有的索引和文档数据是存储在本地的磁盘中
具体的路径可在 ES 的配置文件../config/elasticsearch.yml 中配置,如下:
#-----------------------------------
Paths
------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
#
# Path to log files:
#
#path.logs: /path/to/logs
#磁盘在现代服务器上通常都是瓶颈。Elasticsearch 重度使用磁盘,你的磁盘能处理的吞吐量越大,你的节点就越稳定。这里有一些优化磁盘 I/O 的技巧:
1、使用 SSD;固态硬盘比机械磁盘快
2、使用 RAID 0。条带化 RAID 会提高磁盘 I/O,代价显然就是当一块硬盘故障时整个就故障了。不要使用镜像或者奇偶校验 RAID 因为副本已经提供了这个功能
3、另外,使用多块硬盘,并允许 Elasticsearch 通过多个 path.data 目录配置把数据条带化分配到它们上面
4、不要使用远程挂载的存储,比如 NFS 或者 SMB/CIFS。这个引入的延迟对性能来说完全是背道而驰的
二、分片策略
1、合理设置分片数
分片和副本的设计为 ES 提供了支持分布式和故障转移的特性,但并不意味着分片和副本是可以无限分配的。而且索引的分片完成分配后由于索引的路由机制,我们是不能重新修改分片数的。
我们并不知道这个索引将来会变得多大,并且过后也不能更改索引的大小,所以为了保险起见,还是给它设为 1000 个分片。但是需要知道的是,一个分片并不是没有代价的。需要了解:
1、一个分片的底层即为一个 Lucene 索引,会消耗一定文件句柄、内存、以及 CPU 运转
2、每一个搜索请求都需要命中索引中的每一个分片,如果每一个分片都处于不同的节点还好, 但如果多个分片都需要在同一个节点上竞争使用相同的资源就有些糟糕了
3、用于计算相关度的词项统计信息是基于分片的。如果有许多分片,每一个都只有很少的数据会导致很低的相关度。
一个业务索引具体需要分配多少分片可能需要架构师和技术人员对业务的增长有个预先的判断,横向扩展应当分阶段进行。为下一阶段准备好足够的资源。 只有当你进入到下一个阶段,你才有时间思考需要作出哪些改变来达到这个阶段。一般来说,我们遵循一些原则:
1、控制每个分片占用的硬盘容量不超过 ES 的最大 JVM 的堆空间设置(一般设置不超过 32G,参考下文 的 JVM 设置原则),因此,如果索引的总容量在 500G 左右,那分片大小在 16 个左右即可;当然,最好同时考虑原则 2
2、考虑一下 node 数量,一般一个节点有时候就是一台物理机,如果分片数过多,大大超过了节点数,很可能会导致一个节点上存在多个分片,一旦该节点故障,即使保持了 1 个以上的副本,同样有可能会导致数据丢失,集群无法恢复。所以, 一般都设置分片数不超过节点数的 3 倍。
3、主分片,副本和节点最大数之间数量,我们分配的时候可以参考以下关系:
节点数 <= 主分片数*(副本数+1)
2、推迟分片分配
对于节点瞬时中断的问题,默认情况,集群会等待一分钟来查看节点是否会重新加入,如果这个节点在此期间重新加入,重新加入的节点会保持其现有的分片数据,不会触发新的分片分配。这样就可以减少 ES 在自动再平衡可用分片时所带来的极大开销。
通过修改参数 delayed_timeout ,可以延长再均衡的时间,可以全局设置也可以在索引级别进行修改:
PUT /_all/_settings
"settings":
"index.unassigned.node_left.delayed_timeout": "5m"
三、路由选择
当我们查询文档的时候,Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?它其实是通过下面这个公式来计算出来:
shard = hash(routing) % number_of_primary_shards
routing 默认值是文档的 id,也可以采用自定义值,比如用户 id。
1、不带 routing 查询
在查询的时候因为不知道要查询的数据具体在哪个分片上,所以整个过程分为 2 个步骤
(1)分发:请求到达协调节点后,协调节点将查询请求分发到每个分片上
(2)聚合: 协调节点搜集到每个分片上查询结果,在将查询的结果进行排序,之后给用户返回结果
2、带 routing 查询
查询的时候,可以直接根据 routing 信息定位到某个分配查询,不需要查询所有的分配,经过协调节点排序
向上面自定义的用户查询,如果 routing 设置为 userid 的话,就可以直接查询出数据来,效率提升很多
四、写入速度优化
ES 的默认配置,是综合了数据可靠性、写入速度、搜索实时性等因素。实际使用时,我们需要根据公司要求,进行偏向性的优化
针对于搜索性能要求不高,但是对写入要求较高的场景,我们需要尽可能的选择恰当写优化策略。综合来说,可以考虑以下几个方面来提升写索引的性能:
(1)加大 Translog Flush ,目的是降低 Iops、Writeblock
(2)增加 Index Refresh 间隔,目的是减少 Segment Merge 的次数
(3)调整 Bulk 线程池和队列
(4)优化节点间的任务分布
(5)优化 Lucene 层的索引建立,目的是降低 CPU 及 IO
1、批量数据提交
ES 提供了 Bulk API 支持批量操作,当我们有大量的写任务时,可以使用 Bulk 来进行批量写入
通用的策略如下:Bulk 默认设置批量提交的数据量不能超过 100M。数据条数一般是 根据文档的大小和服务器性能而定的,但是单次批处理的数据大小应从 5MB~15MB 逐渐增加,当性能没有提升时,把这个数据量作为最大值
2、优化存储设备
ES 是一种密集使用磁盘的应用,在段合并的时候会频繁操作磁盘,所以对磁盘要求较 高,当磁盘速度提升之后,集群的整体性能会大幅度提高
3、合理使用合并
Lucene 以段的形式存储数据。当有新的数据写入索引时,Lucene 就会自动创建一个新的段
随着数据量的变化,段的数量会越来越多,消耗的多文件句柄数及 CPU 就越多,查询效率就会下降
由于 Lucene 段合并的计算量庞大,会消耗大量的 I/O,所以 ES 默认采用较保守的策略,让后台定期进行段合并
4、减少 Refresh 的次数
Lucene 在新增数据时,采用了延迟写入的策略,默认情况下索引的 refresh_interval 为1 秒
Lucene 将待写入的数据先写到内存中,超过 1 秒(默认)时就会触发一次 Refresh,然后 Refresh 会把内存中的的数据刷新到操作系统的文件缓存系统中。
如果我们对搜索的实效性要求不高,可以将 Refresh 周期延长,例如 30 秒。这样还可以有效地减少段刷新次数,但这同时意味着需要消耗更多的 Heap 内存
5、加大 Flush 设置
Flush 的主要目的是把文件缓存系统中的段持久化到硬盘,当 Translog 的数据量达到512MB 或者 30 分钟时,会触发一次 Flush
index.translog.flush_threshold_size 参数的默认值是 512MB,我们进行修改
增加参数值意味着文件缓存系统中可能需要存储更多的数据,所以我们需要为操作系统的文件缓存系统留下足够的空间
6、减少副本的数量
ES 为了保证集群的可用性,提供了 Replicas(副本)支持,然而每个副本也会执行分析、索引及可能的合并过程,所以 Replicas 的数量会严重影响写索引的效率
当写索引时,需要把写入的数据都同步到副本节点,副本节点越多,写索引的效率就越慢
如 果 我 们 需 要 大 批 量 进 行 写 入 操 作 , 可 以 先 禁 止 Replica 复 制 , 设 置 index.number_of_replicas: 0 关闭副本。在写入完成后,Replica 修改回正常的状态
五、内存设置
ES 默认安装后设置的内存是 1GB,对于任何一个现实业务来说,这个设置都太小了
如果是通过解压安装的 ES,则在 ES 安装文件中包含一个 jvm.option 文件,添加如下命令来设置 ES 的堆大小,Xms 表示堆的初始大小,Xmx 表示可分配的最大内存,都是 1GB。
确保 Xmx 和 Xms 的大小是相同的,其目的是为了能够在 Java 垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小而浪费资源,可以减轻伸缩堆大小带来的压力
ES 堆内存的分配需要满足以下两个原则:
1、不要超过物理内存的 50%:Lucene 的设计目的是把底层 OS 里的数据缓存到内存中
Lucene 的段是分别存储到单个文件中的,这些文件都是不会变化的,所以很利于缓存,同时操作系统也会把这些段文件缓存起来,以便更快的访问
如果我们设置的堆内存过大,Lucene 可用的内存将会减少,就会严重影响降低 Lucene 的全文本查询性能
2、堆内存的大小最好不要超过 32GB:在 Java 中,所有对象都分配在堆上,然后有一个 Klass Pointer 指针指向它的类元数据
这个指针在 64 位的操作系统上为 64 位,64 位的操作系统可以使用更多的内存(2^64)。在 32 位的系统上为 32 位,32 位的操作系统的最大寻址空间为 4GB(2^32)
但是 64 位的指针意味着更大的浪费,因为你的指针本身大了。浪费内存不算,更糟糕的是,更大的指针在主内存和缓存器(例如 LLC, L1 等)之间移动数据的时候,会占用更多的带宽
最终我们都会采用 31 G 设置
-Xms 31g
-Xmx 31g
假设你有个机器有 128 GB 的内存,你可以创建两个节点,每个节点内存分配不超过 32 GB。 也就是说不超过 64 GB 内存给 ES 的堆内存,剩下的超过 64 GB 的内存给 Lucene
六、重要配置
| 参数名 | 参数值 | 说明 |
| cluster.name | elasticsearch | 配置 ES 的集群名称,默认值是 ES ,建议改成与所 存数据相关的名称, ES 会自动发现在同一网段下的 集群名称相同的节点 |
| node.name | node-1 | 集群中的节点名,在同一个集群中不能重复。节点 的名称一旦设置,就不能再改变了。当然,也可以 设 置 成 服 务 器 的 主 机 名 称 , 例 如 node.name:$HOSTNAME |
| node.master | true | 指定该节点是否有资格被选举成为 Master 节点,默 认是 True ,如果被设置为 True ,则只是有资格成为 Master 节点,具体能否成为 Master 节点,需要通 过选举产生 |
| node.data | true | 指定该节点是否存储索引数据,默认为 True 。数据 的增、删、改、查都是在 Data 节点完成的 |
| index.number_of_shards | 1 | 设置都索引分片个数,默认是 1 片。也可以在创建 索引时设置该值,具体设置为多大都值要根据数据 量的大小来定。如果数据量不大,则设置成 1 时效 率最高 |
| index.number_of_replicas | 1 | 设置默认的索引副本个数,默认为 1 个。副本数越 多,集群的可用性越好,但是写索引时需要同步的 数据越多 |
| transport.tcp.compress | true | 设置在节点间传输数据时是否压缩,默认为 False , 不压缩 |
| discovery.zen.minimum_master_nodes | 1 | 设置在选举 Master 节点时需要参与的最少的候选 主节点数,默认为 1 。如果使用默认值,则当网络 不稳定时有可能会出现脑裂。 合理的数值为 (master_eligible_nodes/2)+1 ,其中 master_eligible_nodes 表示集群中的候选主节点数 |
| discovery.zen.ping.timeout | 3s | 设置在集群中自动发现其他节点时 Ping 连接的超 时时间,默认为 3 秒。 在较差的网络环境下需要设置得大一点,防止因误 判该节点的存活状态而导致分片的转移 |
七、 性能优化-缓存
Elasticsearch会使用各种缓存,主要是如下三种缓存
(1)页缓存
(2)分片级请求缓存
(3)查询缓存
1、页缓存
为了数据的安全、可靠,常规操作中,数据都是保存在磁盘文件中的。所以对数据的访问,绝大数情况下其实就是对文件的访问,为了提升对文件的读写的访问效率,Linux 内核会以页大小(4KB)为单位,将文件划分为多个数据块。当用户对文件中的某个数据块进行读写操作时,内核首先会申请一个内存页(称为 PageCache 页缓存)与文件中的数据块进行绑定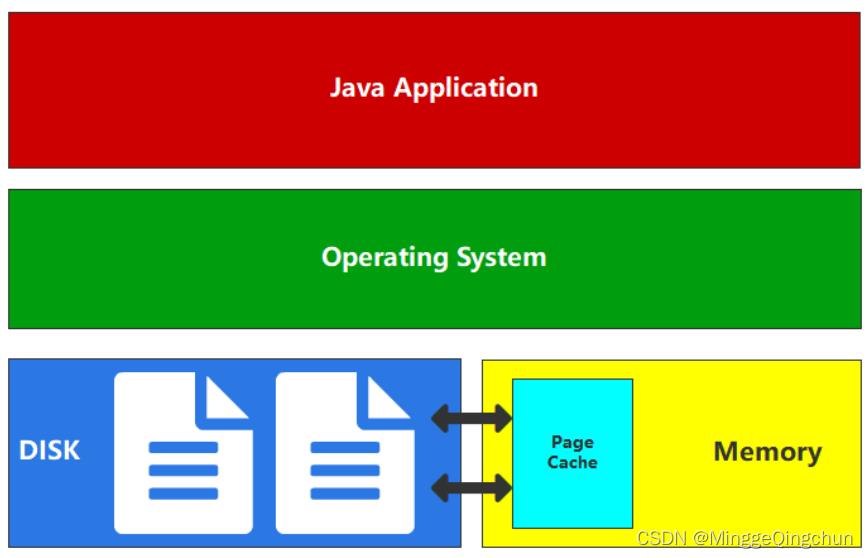
页缓存的基本理念是从磁盘读取数据后将数据放入可用内存中,以便下次读取时从内存返回数据,而且获取数据不需要进行磁盘查找。这些对应用程序来说是完全透明的,应用程序发出相同的系统调用,但操作系统可以使用页缓存而不是从磁盘读取
Java 程序是跨平台的,所以没有和硬件(磁盘,内存)直接交互的能力,如果想要和磁盘文件交互,那么必须要通过 OS 操作系统来完成文件的读写,我们一般就称之为用户态转换为内核态。而操作系统对文件进行读写时,实际上就是对文件的页缓存进行读写。所以对文件进行读写操作时,会分以下两种情况进行处理:
(1)当从文件中读取数据时,如果要读取的数据所在的页缓存已经存在,那么就直接把页缓存的数据拷贝给用户即可。否则,内核首先会申请一个空闲的内存页(页缓存),然后从文件中读取数据到页缓存,并且把页缓存的数据拷贝给用户
(2)当向文件中写入数据时,如果要写入的数据所在的页缓存已经存在,那么直接把新数据写入到页缓存即可。否则,内核首先会申请一个空闲的内存页(页缓存),并且把新数据写入到页缓存中。对于被修改的页缓存,内核会定时把这些页缓存刷新到文件中
与访问磁盘上的数据相比,通过页缓存可以更快地访问数据。这就是为什么建议的 Elasticsearch 内存通常不超过总可用内存的一半,这样另一半就可用于页缓存了。这也意味着不会浪费任何内存
如果数据本身发生更改,页缓存会将数据标记为脏数据,并将这些数据从页缓存中释放。 由于 Elasticsearch 和 Lucene 使用的段只写入一次,因此这种机制非常适合数据的存储方式
段在初始写入之后是只读的,因此数据的更改可能是合并或添加新数据。在这种情况下,需要进行新的磁盘访问。另一种可能是内存被填满了。在这种情况下,缓存数据过期的操作为 LRU
2、分片级请求缓存
对一个或多个索引发送搜索请求时,搜索请求首先会发送到 ES 集群中的某个节点,称之为协调节点;协调节点会把该搜索请求分发给其他节点并在相应分片上执行搜索操作,我们把分片上的执行结果称为“本地结果集”,之后,分片再将执行结果返回给协调节点;协调节点获得所有分片的本地结果集之后,合并成最终的结果并返回给客户端。Elasticsearch 会在每个分片上缓存了本地结果集,这使得频繁使用的搜索请求几乎立即返回结果。这里的缓存,称之为 Request Cache, 全称是 Shard Request Cache,即分片级请求缓存。
ES 能够保证在使用与不使用 Request Cache 情况下的搜索结果一致,那 ES 是如何保证的呢?这就要通过 Request Cache 的失效机制来了解啦。Request Cache 缓存失效是自动的,当索引 refresh 时就会失效,也就是说在默认情况下, Request Cache 是每 1 秒钟失效一次,但需要注意的是,只有在分片的数据实际上发生了变化时,刷新分片缓存才会失效。
也就是说当一个文档被索引 到 该文档变成 Searchable 的这段时间内,不管是否有请求命中缓存该文档都不会被返回
所以我们可以通过 index.refresh_interval 参数来设置 refresh 的刷新时间间隔,刷新间隔越长,缓存的数据越多,当缓存不够的时候,将使用 LRU 最近最少使用策略删除数据。
当然,我们也可以手动设置参数 indices.request.cache.expire 指定失效时间(单位为分钟),但是基本上我们没必要去这样做,因为缓存在每次索引 refresh 时都会自动失效
(1)Request Cache 的使用
默认情况下,Request Cache 是关闭的,我们可以在创建新的索引时启用
curl -XPUT 服务器 IP:端口/索引名 -d
'
"settings":
"index.requests.cache.enable": true
'curl -XPUT 服务器 IP:端口/索引名/_settings -d
'
"index.requests.cache.enable": true
'开启缓存后,需要在搜索请求中加上 request_cache=true 参数,才能使查询请求被缓存, 比如:
curl -XGET '服务器 IP:端口/索引名/_search?request_cache=true&pretty' -H
'Content-Type: application/json' -d
'
"size": 0,
"aggs":
"popular_colors":
"terms":
"field": "colors"
'两个注意事项:
(1)参数 size:0 必须强制指定才能被缓存,否则请求是不会缓存的,即使手动的设置 request_cache=true
(2)在使用 script 脚本执行查询时,由于脚本的执行结果是不确定的(比如使用 random 函数或使用了当前时间作为参数),一定要指定 request_cache=false 禁用 Request Cache 缓存
(2)Request Cache 的设置
Request Cache 作用域为 Node,在 Node 中的 Shard 共享这个 Cache 空间。默认最大大小为 JVM 堆内存的 1%。可以使用以下命令在 config/elasticsearch.yml 文件中进行
更改:
indices.requests.cache.size: 1%
Request Cache 是以查询的整个 DSL 语句做为 key 的,所以如果要命中缓存,那么查询生成的 DSL 一定要一样,即使修改了一个字符或者条件顺序,都不能利用缓存,需要重新生成 Cache
3、查询缓存
这种缓存的工作方式也与其他缓存有着很大的不同。页缓存方式缓存的数据与实际从查询中读取的数据量无关。当使用类似查询时,分片级请求缓存会缓存数据。查询缓存更精细些,可以缓存在不同查询之间重复使用的数据
Elasticsearch 具有 IndicesQueryCache 类。这个类与 IndicesService 的生命周期绑定在一起,这意味着它不是按索引,而是按节点的特性 — 这样做是有道理的,因为缓存本身使用了 Java 堆
这个索引查询缓存占用以下两个配置选项
indices.queries.cache.count:缓存条目总数,默认为 10,000
indices.queries.cache.size:用于此缓存的 Java 堆的百分比,默认为 10%查询缓存已进入下一个粒度级别,可以跨查询重用!凭借其内置的启发式算法,它只缓存多次使用的筛选器,还根据筛选器决定是否值得缓存,或者现有的查询方法是否足够快,以避免浪费任何堆内存。这些位集的生命周期与段的生命周期绑定在一起,以防止返回过时的数据。一旦使用了新段,就需要创建新的位集。
加快检索速度其他方法
io_uring。这是一种在 Linux 下使用自 Linux 5.1 以来发布的完成队列进行异步 I/O 的新方法。请注意,io_uring 仍处于大力开发阶段。但是,Java 中有一些首次使用 io_uring的尝试,例如 netty。简单应用程序的性能测试结果十分惊人。我想我们还得等一段时间才能看到实际的性能数据,尽管我预计这些数据也会有重大变化。我们希望 JDK 将来也能提供对这一功能的支持。有一些计划支持 io_uring 作为 Project Loom 的一部分,这可能会将 io_uring 引入 JVM。更多的优化,比如能够通过 madvise() 提示 Linux 内核的访问模式,还尚未内置于 JVM 中。这个提示可防止预读问题,即内核尝试读取的数据会比预期下次读取的数据要多,这在需要随机访问时是无用的
(1)Lucene 开发人员一如既往地忙于从任何系统中获得最大的收益。目前已经有使用Foreign Memory API 重写 Lucene MMapDirectory 的初稿,这可能会成为 Java 16 中的一个预览功能。然而,这样做并不是出于性能原因,而是为了克服当前 MMap 实现的某些限制
(2)Lucene最近的另一个变化是通过在FileChannel 类中使用直接i/o (O_DIRECT)来摆脱原生扩展。这意味着写入数据将不会让页缓存出现“抖动”现象(Lucene 9 的功能)
以上是关于Elasticsearch - Elasticsearch 优化(十五)的主要内容,如果未能解决你的问题,请参考以下文章