Elasticsearch 8.X 集群无响应,怎么办?
Posted 铭毅天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 8.X 集群无响应,怎么办?相关的知识,希望对你有一定的参考价值。
在企业环境中,Elasticsearch 一般部署为多个节点的分布式集群,对 Elasticsearch 集群的读取或写入请求需要在多个节点之间进行协调。在单个服务器节点上没有数据的“全局视图”,这是认知前提。
当出现可靠性问题时,如果 Elasticsearch 集群设置有问题或整个集群不稳定,那么“紧急救火”可能会很紧张。
往小了说,可能影响客户体验,客户用着不爽;往大了说,处理不及时或处理不利,可能对企业带来负面影响。
因此,提前掌握快速恢复的步骤非常重要!在事故或停机期间花费大量时间在线研究解决方案,有过类似经历的读者会知道到底有多苦!
本系列文章可以作为工程师常备的 Elasticsearch 问题排查备忘单,遇到相关问题可以快速找到相应的推荐解决方案。
认知前置说明:
1)作为一种通用工具,Elasticsearch 拥有数千种不同的配置,使其能够适应各种不同的工作负载。
2)适用于一家公司的数据模型或配置也可能不适合另外一家的,不可能做到“普适”。
3)让 Elasticsearch 集群扩展以适配给定的功能和性能指标,并没有什么“灵丹妙药“,需要大量的性能测试和试错彩才能给出适合自己业务场景的结论。
本篇是系列文章第一篇,主要探讨:Elasticsearch 集群无响应,怎么办?
集群稳定性问题是最难调试的问题,尤其是在数据量或代码库没有任何变化的情况下。
1、 排查方案 1:检查集群状态的大小
1.1 集群状态的用途
集群状态——跟踪集群的全局状态,是控制流量和集群的核心。
集群状态包括集群中节点的元数据、分片的状态以及分片如何映射到节点、索引映射 Mapping 等等。
集群状态通常不会经常改变。但是,某些操作(例如将新字段添加到 Mapping)可能会触发更新。因为集群更新需要广播到集群中的所有节点,所以它应该很小(一般会<100MB)。
一个大的集群状态会很快使集群变得不稳定。发生不稳定的常见方式包含但不限于:映射爆炸(索引中的字段过多)或索引过多等。
1.2 集群状态(state)检查命令
使用以下命令查看集群状态。
GET /_cluster/state我这里 8.x 单节点的集群,会有:14万行+数据的输出,大小 5.57MB。
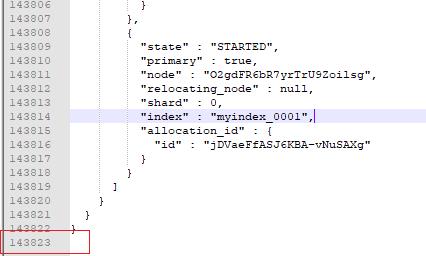
拿到上面的数据后,查看哪些索引在集群状态中具有最多的字段,这些索引可能是导致稳定性问题的“违规”索引。
如果集群状态很大并且还在增加,可以进一步了解查看单个索引或模糊匹配的多个索引模式,如下所示:
GET /_cluster/state/_all/my_index-*可以进一步核查“问题”索引的映射:
GET /my_index/_mapping1.3 集群状态异常问题的解决方案
看看数据是如何被索引的。发生映射爆炸的常见方式是使用高基数标识符作为 JSON 键。举例所示:
"1":
"status": "ACTIVE"
,
"2":
"status": "ACTIVE"
,
"3":
"status": "DISABLED"
上面的索引数据再更新会有“4”、“5”类似的新字段(“键”),集群状态就会更新。上面的 JSON 将很快导致 Elasticsearch 出现稳定性问题,因为每个键都被添加到全局状态中。推荐使用如下方式进行存储:
[
"id": "1",
"status": "ACTIVE"
,
"id": "2",
"status": "ACTIVE"
,
"id": "3",
"status": "DISABLED"
]
2、排查方案 2:检查 Elasticsearch 任务列表
当对 Elasticsearch 发出请求(索引操作、查询操作等)时,这些请求操作首先被插入到任务队列中,直到工作线程从队列中取出使用为止。
一旦线程池有一个空闲线程,它就会从任务队列中取出一个任务并处理。
这些操作一般是基于 9200 和 9300 端口的 Http 请求完成的,在给定时间,可能有成百上千个正在进行的操作,应该很快完成(如微秒或毫秒)。
2.1 获取任务列表(tasks)的方法
Elasticsearch 获取 tasks 的命令和 mysql 中的 “show processlist” 命令类似,用于
获取当前集群正在执行的任务列表。
MySQL “Show processlist” 命令使用方法如下:
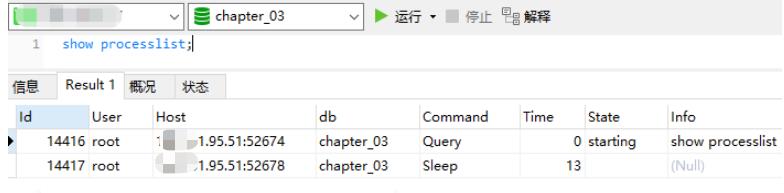
Elasticsearch 获取任务列表命令行如下:
GET /_cat/tasks?detailed&v
如上命令使用 ?detailed参数,可以获得有关目标索引和查询的详情信息。
如果不同任务都集中在一个节点,可能会出现节点过载问题。
进一步查看,如果不同任务都关联同一个索引,则可能该索引或该索引的数据有问题。
2.2 Elasticsearch 任务出现异常,如何破局?
第一:如果请求量高于正常水平,则考虑优化请求的方法(例如使用批量 bulk API 或更高效的查询/写入)。
第二:如果 task 任务变化看起来是随机的,可以将当前 task 结果列表备份,以便后续继续观察对比。
第三:如果您不知道请求来自何处,可以将 X-Opaque-Id 标头添加到您的 Elasticsearch 客户端,以识别哪些客户端正在触发查询。
命令行和执行结果如下所示:
curl -i -H "X-Opaque-Id: O2gdFR6bR7yrTrU9Zoilsg:23" --cacert ./config/certs/http_ca.crt -u elastic:changeme "https://172.21.0.14:9200/_tasks?group_by=parents"
3、排查方案 3:检查 Elasticsearch 待执行的任务(Pending tasks)
3.1 待执行的任务的含义
待处理任务——返回尚未执行的任何集群级别更改(例如创建索引、更新映射、分片分配或分片分配失败)的列表。
与第二部分讲解的任务队列不同,挂起的或待处理的更新任务需要多步握手才能将更新广播到集群中的所有节点,这可能需要一些时间。
一般情况下,Pending tasks 结果为空,只有类似快照还原等昂贵的操作可能会导致这种情况暂时飙升。
3.2 如何排查?
运行如下命令并确保没有或只有很少的任务在进行中。
GET /_cat/pending_tasks-
如果结果看起来是一个快速完成的持续集群更新流,请查看可能触发它们的原因。是映射爆炸还是创建了太多索引?
-
如果只是几个,但它们似乎卡住了,请查看主节点的日志和监控指标结果数据,看看是否有任何问题。例如,主节点是否遇到内存或网络问题,无法处理集群更新?
4、排查方案4:核查热点线程(Hot Threads)
4.1 热点线程用途
热点线程 API 是一个有价值的内置分析器,可以告诉技术人员(开发或运维等)Elasticseach 在哪里花费的时间最多。
热点线程可以为我们甄别问题提供帮助,例如 Elasticsearch 是否在索引刷新(数据写入阶段)上花费了太多时间或执行昂贵的查询(数据查询阶段)。
4.2 热点线程 API
GET /_nodes/hot_threads返回结果如下所示:
::: VM-0-14-centosO2gdFR6bR7yrTrU9ZoilsgGofHxDIUR-6EDMEENX2zSQ172.21.0.14172.21.0.14:9300cdfhilmrstwml.max_jvm_size=2147483648, ml.machine_memory=8200851456, xpack.installed=true
Hot threads at 2022-09-13T15:00:32.396Z, interval=500ms, busiestThreads=3, ignoreIdleThreads=true:具体细节推荐阅读:深入解读 Elasticsearch 热点线程 hot_threads。
本质:定位线程堆栈。
4.3 热点线程问题如何修复?
如果大量 CPU 时间花费在索引刷新( index refresh)上,则尝试将刷新间隔增加到默认的 1 秒以上。
实现方法推荐:
PUT test_index/_settings
"index":
"refresh_interval": "30s"
如果你看到大量缓存(cache),则可能是你的默认缓存设置不是最理想的并导致大量未命中。缓存的相关设置推荐阅读:Elasticsearch 缓存深入详解。
5、小结
你有没有遇到类似问题,如何排查的?
欢迎留言交流。
以上是关于Elasticsearch 8.X 集群无响应,怎么办?的主要内容,如果未能解决你的问题,请参考以下文章