计算机到底能识别多少汉字?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机到底能识别多少汉字?相关的知识,希望对你有一定的参考价值。
参考技术A 分类: 电脑/网络 >> 电脑常识问题描述:
很多冷僻字都打不出来
请问,计算机到底能识别多少汉字?
解析:
80年代开始,个人计算机大量在中国使用,国家规定了G
B2312的标准,在CCDOS上开始使用.GB2312在字形上是采用的中国国家颁布的汉字字形,全部
是有拼音的,但是在编码上,为了保证计算机上的使用,采用的是ISO2022的编码法则.对于当
时,不同的国家,只有标准字符集和标准符号集在ISO2022中,不同国家的编码区域是完全一
样的,但是在各自的文字区域是复用的,即,如果安装了GB2312就无法兼容安装日本的标准编
码.在80年代末期和90年代初期,海峡两岸的交流越来越多,却出现了在计算机上文字互补兼
容的问题,在90年代初期,制定了一个GBK的规范,就是在大陆的6763字后面,增加BIG5里面的
15000汉字的部分.这个部分是字型与台湾的字型是一样的,但是编码仍然是ISO2022.同时8
0年代末期,国际上已经开始重视文化在计算机上的交流,提出了国际统一码的概念,就是在
一个编码体系里面容下全世界的文字.针对这个倡议,世界各国组织了 Unicode委员会,同时
也制定了一个新的编码标准,就是ISO10646编码.由于90年代初期,认识的局限性,中国没有
积极的参与这个活动,日本, 韩国在第一个标准里面占据了大量的码位,后来成立了Super
C.J.K小组进行协调,在这个标准里面,把大陆,台湾的字型都放在里面的话由中国人占据的
码位是20902个,含了所有的GB2312,GBK, BIG5的字型字.90年代末期,中国 *** 在此基础上
,对于部分字型进行了处理和规范,形成了GB13000.1的标准文件,字型略有不同,但是编码是
采用ISO10646的编码体系.目前在大陆的微软系统用字是ISO10646的20902个汉.Unicode
和ISO10646在初期的理论基础是不同的,Unicode认为字符编码应该是变长的,而ISO10646
认为字符编码是定长的,并且用2字节码就可以把世界上所有的文字解决完.UTF- 8,UTF-16
,UTF32就是在Unicode的理论上形成的计算机信息格式编码.在ISO10646的前面几个版本,是
可以用USC2,和UTF- 8进行处理的.但是,在90年代末期,中国向Unicode委员会又提交了6千
多个汉字,ISO10646的编码体系最大只能放65536个字符,无法满足东亚语言新提交的字符要
求,所以ISO10646从3.0开始进行扩充,在原有编码基础上,对于还未用满的区域进行了扩充
,拓展了一部分到4字节,这样 ISO10646的编码空间从65536到了150万字符的容量.所以在后
来的ISO10646标准都是采用了变长码的原则,完全与Unicode重合了.这样Unicode和ISO106
46变成了等同的关系,目前已经到4.0了,一共有71000汉字.在4.0中一共是3个部分,基本级
20902, 扩充A6千多个,扩充B4万5千多个.回过来,在中国进行WTO谈判时,某些 *** 官员自己
认为要反对文化入侵,对于外国进入中国的信息系统进行限制,在仓促之间推出了GB18030-
2000,这个标准在ISO10646的基本集的20902字是用ISO2022进行编码的,对于扩充A的字是采
用的四字节码.但是在计算机实现上,不能ISO2022和ISO10646混用,如何解决了?微软就在表
现层是GB18030-2000的,在底层是 ISO10646的,用UTF-8处理.所有的多国语言问题都是这样
处理啦.目前在Unix和Linux的处理是,把6千多个4字节变换成2字节,在表现层和底层都用I
SO2022的标准.新的Linux的内核和X-Windows都支持Unicode的,所以,我们计划在新的计划
中,变成和微软一样的处理方法,使得底层是统一编码的,表现层是可以多编码转换的关系.
因为扩充B的4万5千多字无法转换成2字节编码啦(65536限制),所以今年将发布的 GB18030
-2003的新的和扩充B等同的部分使得Linux和Unix将付出新的代价.建议FreeBSD处理时最好
采用和微软公司一样的方法.一次解决后,只需做翻译码表,而不需要动底层了.当时我是国
家图书馆的总工程师向信息产业部质疑为什么GB18030-2000是强制性的,如何解决多国语言
问题?如何参加国际交流?现在教育部语言文字委员会开始研究ISO10646/Unicode/GB13000
的问题,因为康熙字典有52000字,大约有4000多个在V4.0中,中华大字典
mysql一张表到底能存多少数据?
前言
程序员平时和mysql打交道一定不少,可以说每天都有接触到,但是mysql一张表到底能存多少数据呢?计算根据是什么呢?接下来咱们逐一探讨
知识准备
数据页
在操作系统中,我们知道为了跟磁盘交互,内存也是分页的,一页大小4KB。同样的在MySQL中为了提高吞吐率,数据也是分页的,不过MySQL的数据页大小是16KB。(确切的说是InnoDB数据页大小16KB)。详细学习可以参考官网 我们可以用如下命令查询到。
mysql> SHOW GLOBAL STATUS LIKE 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Innodb_page_size | 16384 |
+------------------+-------+
1 row in set (0.00 sec)
今天咱们数据页的具体结构指针等不深究,知道它默认是16kb就行了,也就是说一个节点的数据大小是16kb
索引结构(innodb)
mysql的索引结构咱们应该都知道,是如下的b+树结构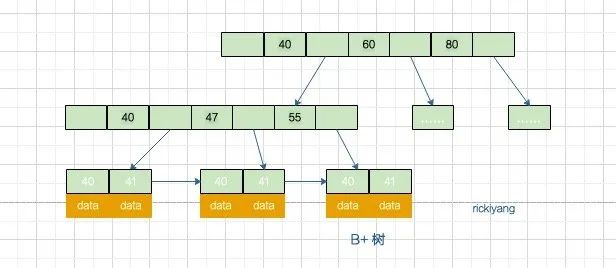 通常b+树非叶子节点不存储数据,只有叶子节点(最下面一层)才存储数据,那么咱们说回节点,一个节点指的是(对于上图而言)
通常b+树非叶子节点不存储数据,只有叶子节点(最下面一层)才存储数据,那么咱们说回节点,一个节点指的是(对于上图而言)
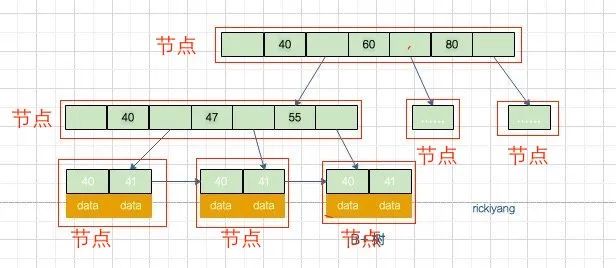
每个红框选中的部分称为一个节点,而不是说某个元素。了解了节点的概念和每个节点的大小为16kb之后,咱们计算mysql能存储多少数据就容易很多了
具体计算方法
根节点计算
首先咱们只看根节点
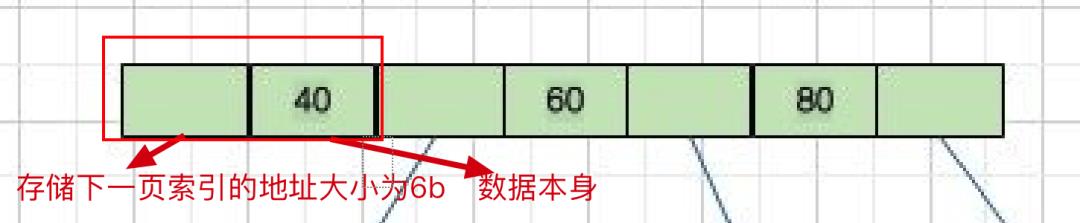 所以我们是可以计算出来一个数据为(8b+6b=14b)的空间(以bigint为例) 我们刚刚说到一个数据页的大小是16kb,也就是(16*1024)b,那么根节点是可以存储(16*1024/(8+6))个数据的,结果大概是1170个数据 如果跟节点的计算方法计算出来了,那么接下来的就容易了。
所以我们是可以计算出来一个数据为(8b+6b=14b)的空间(以bigint为例) 我们刚刚说到一个数据页的大小是16kb,也就是(16*1024)b,那么根节点是可以存储(16*1024/(8+6))个数据的,结果大概是1170个数据 如果跟节点的计算方法计算出来了,那么接下来的就容易了。
其余层节点计算
第二层其实比较容易,因为每个节点数据结构和跟节点一样,而且在跟节点每个元素都会延伸出来一个节点,所以第二层的数据量是1170*1170=1368900,问题在于第三层,因为innodb的叶子节点,是直接包含整条mysql数据的,如果字段非常多的话数据所占空间是不小的,我们这里以1kb计算,所以在第三层,每个节点为16kb,那么每个节点是可以放16个数据的,所以最终mysql可以存储的总数据为
1170 * 1170 * 16 = 21902400 (千万级条)
其实计算结果与我们平时的工作经验也是相符的,一般mysql一张表的数据超过了千万也是得进行分表操作了。
总结
最后用一张图片总结一下今天讨论的内容,希望您能喜欢
完
往期精选
扫描二维码
获取更多精彩
以上是关于计算机到底能识别多少汉字?的主要内容,如果未能解决你的问题,请参考以下文章