AutoUpdate.dll到底是个啥文件,为啥瑞星说是怀疑却不杀
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AutoUpdate.dll到底是个啥文件,为啥瑞星说是怀疑却不杀相关的知识,希望对你有一定的参考价值。
这是在我传奇游戏目录下面发现的 。应该怎么处理 。 我能直接删除它吗? 谢谢了
AutoUpdate.dll一般是自动升级的数据库文件,可能与你的游戏的升级有关。瑞星是在全盘杀毒后提示的还是在电脑中央突然弹出一个提示框,还是在“电脑安检”里提示发现可疑文件?
一般如果瑞星提示是可疑文件的话,不一定是带有病毒,所以瑞星没有清除或删除它。
不过也有可能是它本身带有病毒,建议上传到http://www.virscan.org/,如果报警的杀毒软件比较多,我建议你把它给删除了吧。
你也可以去下载360顽固木马专杀大全(http://www.360.cn/killer/360compkill.html)进行查杀。 参考技术A 楼主的描述应该是瑞星对该文件报“可疑文件”,处理方式为“不处理”
可疑文件不确定是病毒,所以瑞星软件选择的是不处理。且可疑文件会自动上传,如果确认是病毒,升级后就会对此文件查杀。如果楼主想手动上传,可以登陆http://mailcenter.rising.com.cn/FileCheck/网址上传该文件,上传后可以得到rs开头的查询编码,楼主可以通过此编码查询处理进度及结果 参考技术B 按照你介绍的情况,这个AUTOupdate.dll是一个游戏更新数据库文件
这个可以删除,只不过删除了以后,你以后升级游戏的话就要手动升级了
瑞星说是怀疑对象是因为它会随着游戏的启动自动运行 参考技术C 瑞星经常报错文件。诶 垃圾了
Netty系列进阶篇一:阻塞和多路复用到底是个啥?
文章目录
一、进阶篇:Netty封装了什么?
之前整理的整个Netty篇,快速的完成了从BIO到Netty的进化,但是始终会有一个感觉,就是这些网络IO的代码有点别扭,有很多代码之间的逻辑需要强行去记忆。这个番外篇我们就会深入底层去探究这些Java代码背后的秘密。当理解了这些底层的知识后,再回头来看这些IO代码,才能真正理解代码之间的逻辑关联。另外,关于Netty,虽然功能确实非常强大,但是官网上也直说了他只是一个框架。而对于框架,我们知道一般都是对一些现有技术的封装,而Netty也只是对NIO的封装,那Netty到底对NIO封装了一些什么东西呢?
之所以准备成一个进阶篇,也是有几个原因的。首先,这一篇预备的一些内容都是以之前正篇的内容为基础的,只有用熟练了,去了解底层才有意义。代码都没有写熟练,就看是探究底层只是自欺欺人。另外,这一篇准备的都是一些底层原理性的东西,固然能够加深对Netty的理解,但是跟实际开发工作可能关联不是很紧密。但是如果想要进阶,还是非常重要的。
进阶篇的具体内容预备是从NIO的三大核心组件入手,Selector、Buffer和Channel。这一节先来梳理Selector多路复用器。
二、刨根问底:到底什么是阻塞?什么是多路复用器?
关于多路复用器,在之前的几篇中做了简单的介绍。这一章的目的就是在这些简单介绍的基础上,彻彻底底弄明白这个多路复用器的机制。先来回顾一下NIO的整体流程:
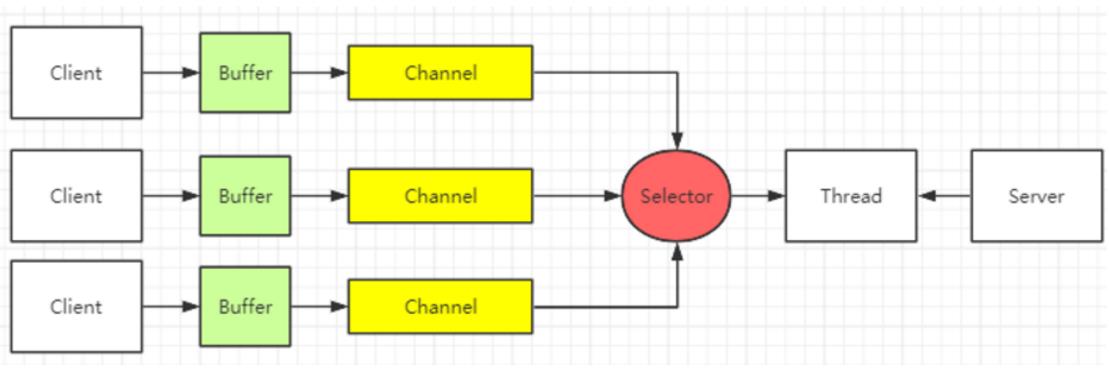
之前提到,NIO相比于BIO,使用多路复用器,可以只用一个线程就管理所有的客户端连接,而BIO需要对每一个连接创建一个线程。那是不是只要实现了一个线程管理多个连接,就是多路复用了?例如在BIO中每个客户端过来会产生一个新的socket对象,那我将这个socket对象放到一个集合中保存起来,然后启动一个线程,不断的扫描这个集合,那也实现了一个线程管理多个连接,这就是一个多路复用吗?就像这样
List<Socket> allSocket = new ArrayList<>();
while(true) {
Socket socket = serverSocket.accept();
new Thread(()->{doWork(socket)}).start(); // 创建一个新的线程
}
void doWork(Socket socket) {
//在新线程中处理连接相关业务
final InputStream inputStream = socket.getInputStream();
.....
}
不用说你也会觉得不太对劲,好像没有这样的叫法。这就引出了第一个问题,什么是多路复用?多路复用(multiplexing)是一个操作系统内核中的概念,并不是一种实现效果。对应linux操作系统,可以简单的认为,只有使用到了select、poll和epoll三个系统调用(system call)的程序才能称为多路复用器。
这里涉及到了一些操作系统的知识,这里简单介绍一下。
1、操作系统基础
关于操作系统的知识体系,太庞大了。我们这里只是对相关的部分内容做尽量简单易懂的梳理。对于Linux操作系统,整体的系统架构图如下:

1-1 用户态与内核态
现代操作系统,为了保护系统的安全,都会划分出内核空间和用户空间,或者我们经常说的内核态和用户态。Linux给所有的系统操作划分不同的"权限",简单来说,就是划分为内核态和用户态两个等级。运行在用户态的进程大都是一些应用程序,能够访问的系统资源受到极大的限制。而运行在内核态的进程权限就非常大,可以"为所欲为"。这么做的目的是为了保护操作系统的底层资源。例如文件都要存在硬盘,但是如果用户编写的应用程序可以随意的操作硬盘的启动扇区,那分分钟就可以把系统搞崩溃。其实在早期确实有这样的病毒程序,可以轻易把操作系统弄崩溃。现在划分为内核态和用户态之后,用户态的应用程序就不能直接操作底层的硬件接口了,如果需要操作硬盘,比如存文件,那就必须经过内核态来协调。这样就可以对所有底层硬件的操作方式进行规范。
有了用户态和内核态的划分后,应用程序就经常需要在用户态和内核态之间进行切换。例如程序要保存一个文件到硬盘,在程序执行的用户态,是不能直接操作磁盘的。只有切换到内核态才能真正去操作磁盘。这里就涉及到另外一个问题,用户态如何切换到内核态?
1-2 系统调用
用户态的应用程序有三种方式可以切换到内核态:
1、通过系统调用。系统调用是操作系统内核中的一些标准操作,也就是运行在内核态的最小功能单元。用户程序不能直接调用这些系统调用,但是可以通过一些操作系统提供的标准库函数去调用这些系统调用。
2、一些异常事件。当CPU在运行用户态程序时,突然发生某些不可预估的异常事件,就会触发一个从当前用户态进程向内核态执行的异常事件。比如缺页异常。
3、外围设备中断。当外围设备,比如键盘、鼠标、网卡等。完成了用户的请求后,会向CPU发出中断信号,这个中断信号会在CPU内部注册,并对应一个处理程序。此时,CPU就会暂停执行下一行的指令,转而去执行中断信号对应的处理程序。如果先前执行的指令是在用户态,而接下来的指令是在内核态,就自然完成了用户态到内核态的切换。
这其中,关于中断(Interrupt),是操作系统中非常重要的一个概念。CPU正是通过这些中断信号,来触发从一个线程到另一个线程的切换。我们在多线程部分常说的CPU时间片,实际就是由中断信号触发CPU进行线程切换而产生的效果。而系统调用从本质上说也是一种中断,相对于外围设备的硬中断,也可以称为软中断。这是操作系统为用户特别开放的一种中断。
由中断往下可以引出 全局描述表GDT , 中断描述表IDT,以及CPU实模式和保护模式等非常多的知识点。这里就略过了。
在Linux服务器上,可以通过man 指令来查看系统调用的相关资料。例如man syscalls可以查看所有的系统调用
man 2 select,就可以用来查看select这个系统调用的描述文件。
在这个指令中,2 就表示是查系统调用。另外
1:表示标准命令;
3:表示库函数,例如 man 3 printf;
4:表示设备说明;
5:表示文件格式;
6:为游戏预留;
7:表示杂项 例如 man 7 epoll;
8:表示管理员命令;
9:其他,用来存放内核例行程序的文档。
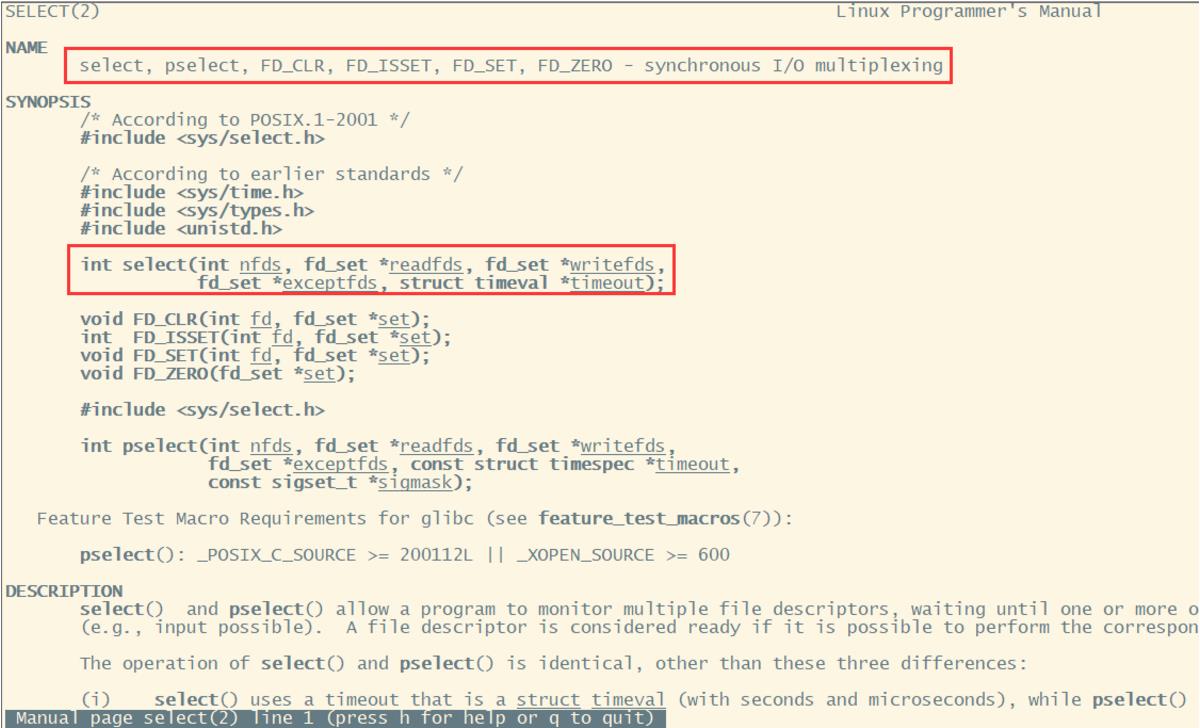
从这个描述文件中可以看到,关于select有一系列的系统调用。其中,select()和pselect()这两个系统调用允许程序监控多个file descriptors。直到一个或多个file descriptors调整为"ready"状态,可以开始进行一些IO操作。
1-3 File Descriptor 文件描述符
这里又涉及到一个操作系统的重要概念 file Descriptor ,文件描述符,简称FD。这个FD形式上是一个非负整数,实际上,指向内核为每个进程所维护的该进程打开文件的记录表。在Linux中,常说一切皆文件,其实就是指的这个FD。例如在网络编程中,都会创建Socket。而在内核中,创建一个Socket后,就会以一个FD来描述这个Socket。后续对这个Socket的操作都会围绕这个FD展开。
我们也有一个办法可以实际看到这些FD。 例如,我们在Linux上编辑一个简单的java程序, BlockDemo.java
import java.util.Scanner;
public class BlockDemo {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
final String s = scanner.nextLine();
System.out.println(s);
}
}
将这个BlockDemo.java上传到安装了JDK8的一台Linux机器上,javac BlockDemo.java 编译, 然后java BlockDemo执行。这个小程序执行后,会在控制台阻塞住,等待从控制台输入。这时不要输入内容,打开另外一个连接窗口,执行jps查看这个Java程序的进程号。例如我这里查到的进程号是4870。 然后使用指令 lsof -p 4870 查看该进程的描述
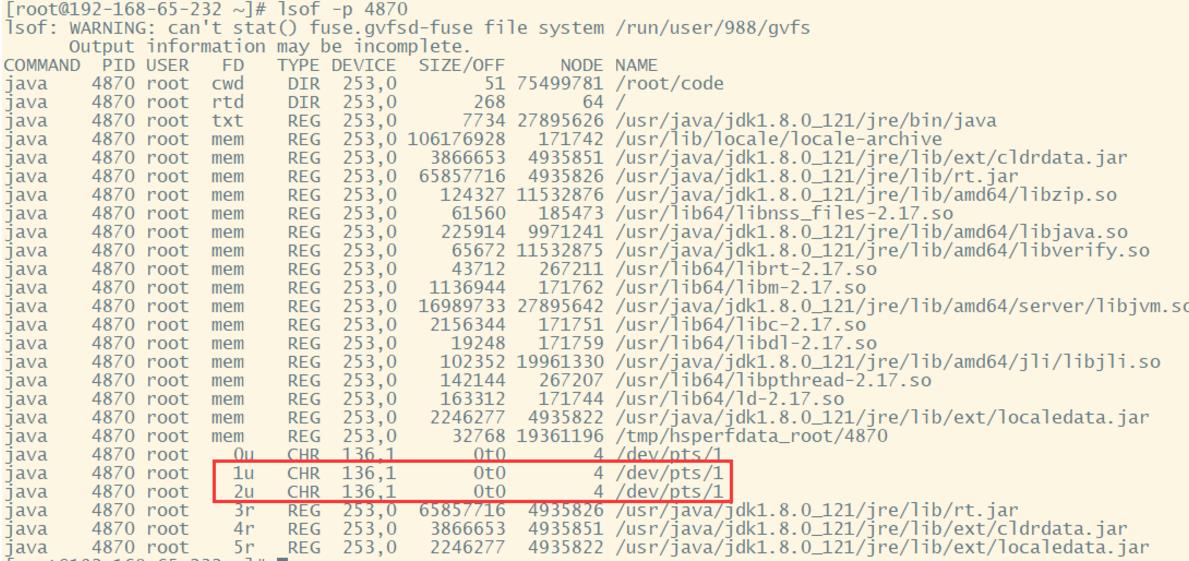
这里就列出了该进程相关的FD。这其中cwd,表示程序的工作目录。 rtd,表示用户的根目录。 txt,表示运行程序的指令,例如对于shell脚本通常是/sbin/bash。mem,表示memory-mapped file,内存映射文件(没错,就是零拷贝的mmap机制。如果在程序中添加一个mmap的文件映射,这里就会列出一条类型为mem的FD。)下面的0u,1u,2u就是Java的标准FDF。其中0U,表示标准输出,1u表示标准输入, 2u表示标准错误。我们通常写的脚本 java xxx 1>xxx & 2> xxx,这里面的1和2就对应这里列出的FD。
1-4 简单跟踪程序的系统调用过程
1-4-1 跟中BIO服务端启动过程
在Linux中,提供了一个strace指令可以帮我们查看应用的系统调用情况。例如,对于Netty基础篇中的com.roy.bio.BioServer服务类。
package com.roy.bio;
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
import java.nio.ByteBuffer;
/**
* @author :楼兰
* @date :Created in 2021/6/2
* @description:
**/
public class BioServer {
public static void main(String[] args) throws IOException {
ServerSocket serverSocket = new ServerSocket(8080);
System.out.println("服务启动完成");
while (true) {
//BIO每次会在这个地方阻塞住,只到有请求进来。
final Socket socket = serverSocket.accept();
System.out.println("有请求进来了。");
//通过inputStream解析客户端传过来的消息
final InputStream inputStream = socket.getInputStream();
byte[] buffer = new byte[1024];
int len;
//连接建立后,如果当前线程暂时没有数据可读,则线程就阻塞在 Read 操作上,造成线程资源浪费
// while (true) {
len = inputStream.read(buffer);
// if (len == -1) {
// break;
// }
System.out.println("收到消息:" + new String(buffer, 0, len));
// buffer = new byte[1024];
// }
//通过outputStream给客户端返回响应
final OutputStream outputStream = socket.getOutputStream();
outputStream.write(("你的消息 :" + new String(buffer) + " 收到了。").getBytes());
outputStream.flush();
System.out.println("返回消息响应。");
inputStream.close();
outputStream.close();
socket.close();
}
}
可以将他上传到Linux服务器当中,然后使用javac BioServer.java 指令进行编译。然后使用strace指令跟踪执行情况
strace -ff -o log java com.roy.bio.BioServer
这个指令会在命令行目录下生成一堆log.*格式的日志文件,其中后面的星号就是线程号。在Java8中,一般第二个生成的就是主线程的日志文件。(不同版本可能不一样,jdk1.4好像就是第一个)
我们可以查看下这个文件。less log.19078。这个文件中列出的就是程序进行过了的系统调用。里面的每一个系统调用也可以使用man 2 指令去查看。可以看到是非常多的。我们直接进入文件的最后,可以看到这样一段日志。
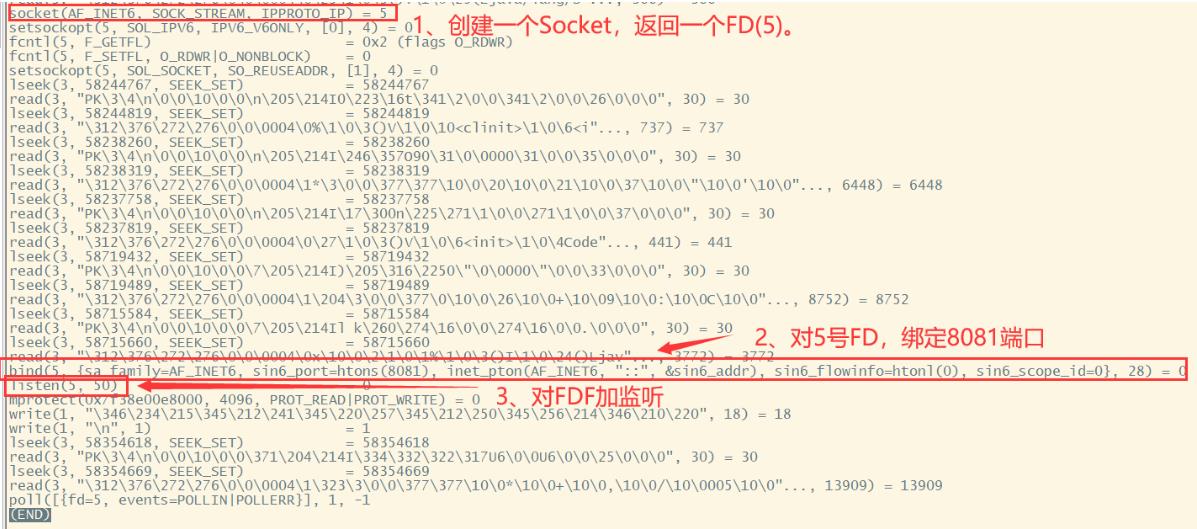
就像图中所示,第一个红框,socket方法就是创建一个serverSocket的过程,返回了一个编号为5的FD。
第二个红框,bind就是对5号FD绑定8081端口。
第三个红框,listen就是对5号FD开始监听。而在这个listen系统调用中,传入的第二个参数,就是在Netty中经常设置的ChannelOption.SO_BACKLOG属性,表示服务器可连接的队列个数。
在Linux内核中对TCP连接会维护两个队列,一个是sync queue,保存SYN已经到达,但是三次握手还没有完成的连接。另一个是accept queue,保存三次握手完成,内核正等待进程执行accept的调用的连接。而BackLog表示这两个队列的长度之和。如果两个队列的长度之和大于BackLog ,新的TCP连接就会被内核给拒绝掉。
其实这三个步骤就是网络IO服务端的通用过程,包括后面的NIO、Netty基本都是通过这样的三板斧展开监听的。
另外,从目前这个日志中也能看到,最后的一行poll指令没有执行完成,也就是进程阻塞在了这个地方。其实也就对应着我们代码中final Socket socket = serverSocket.accept(); 这一行。
之前分析过BIO的程序有两个阻塞点,一个是accept这一行,这是在等待客户端连接。 另一个阻塞点就是在len = inputStream.read(buffer); 这是在等待客户端传输数据。接下来,我们让程序进入下一个阻塞点,跟踪下系统调用情况。
1-4-2 跟踪一次BIO请求过程
接下来我们启动一个客户端去连接BioServer。可以打开一个新的命令行窗口,直接使用linux提供的nc指令来连接。
nc localhost 8081
执行这个指令后,客户端就连接上了BioServer。然后客户端会阻塞,等待出入。而在BioServer的命令窗口,可以看到已经接受到了客户端连接的事件。
[root@192-168-65-232 code]# strace -ff -o log java com.roy.bio.BioServer
服务启动完成
有请求进来了。
这时,再来刷新下log.19078文件,看下触发了哪些系统调用。
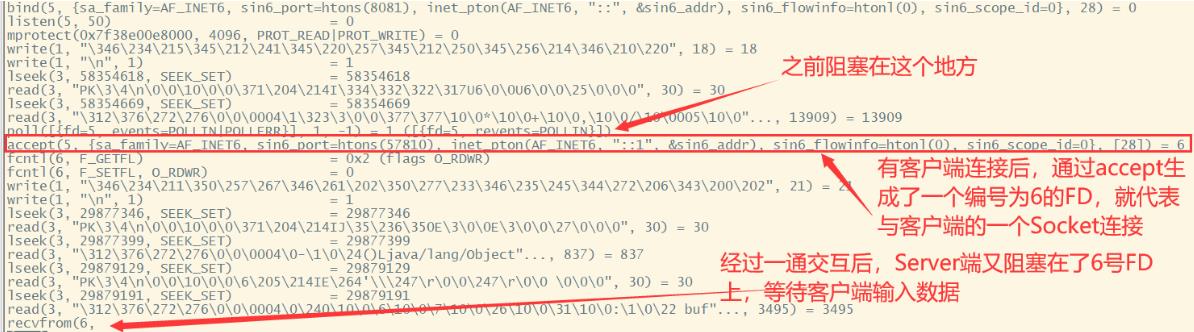
经过一通交互,BioServer又阻塞在了recvfrom这个系统调用上,等待客户端输入数据。
1-4-3 客户端输入数据,完成一次BIO请求。
接下来,在连接的客户端随便输入一个字符串 123。客户端会提示
你的消息:123 收到了
而服务端也会打印一次日志
收到消息: 123
返回消息响应
这样就完成了一次BIO的网络交互。同样再来跟踪下系统调用情况

可以看到,服务端接受到客户端的输入信息后,开辟了一个新的4号FD,通过4号FD完成与客户端的交互后,最终关闭了这个FD,表示断开了与客户端的这次连接。然后,服务端又重新阻塞在了poll这一行,等待下一次的客户端连接事件。
这样,我们就完成了一次简单的BIO连接交互过程的系统调用的日志跟踪。对于过程中几个关键的系统调用,如果不熟悉,可以实用man 2 指令查看下帮助文档。后面我们也会结合这些系统调用来分析Nio的其他执行过程,来真正理解多路复用。
从这个过程中可以看到,这个简单的Bio网络程序,实际上也是用到了poll多路复用机制。不过由于阻塞,没有体现出多路复用的效果。实际上,对于我们在后面NIO中不断设置线程为非阻塞,也就对应一个系统调用 fcntl(fd, O_NONBLOCK ) 表示将目标fd设置为非阻塞。非阻塞后,程序就不会阻塞在recvfrom那一个系统调用上了,而会立即返回结果。
这个过程解释了为什么一直说NIO需要操作系统支持。同时也说明了一个道理,不管应用程序是用什么语言编写的,最终的执行结果都只能解释为一系列的系统调用。应用程序能做什么事情,最终都是离不开系统调用的支持。系统调用如果不支持,应用程序再牛也是巧妇难为无米之炊。
如果对操作系统的系统调用非常熟悉,其实从这个strace指令就可以跟踪出应用程序的执行步骤,并且发现应用程序的问题所在。例如,在分析文件IO时,上层语言会体现出非常多的使用方式,例如普通流、buffer缓冲流、还有零拷贝等等方式。而在分析文件IO时,都离不开一个问题,就是分析何种情况下会丢数据,例如机器重启后,日志文件会不会丢?丢的话会丢失多少?这些问题,从上层语言中是很难分析出结果的,都需要到系统层面来具体分析。另外,对于一些不太适合看源码的应用程序,比如redis、mysql、rabbitmq,通过系统调用也能分析出他们的一些关键机制。
关于线程阻塞,这又是操作系统中一个复杂的机制。
2、多路复用的流程
理解了系统调用之后,再来理解BIO、NIO、Netty这些古怪的代码,就容易找到一点感觉。以往对这些不同类型的IO,或许只能从编程模型上去强行理解,至于为什么要这么编程,很难找到主线。现在从系统调用层面来理解,这些IO当中前言不搭后语的代码就有了一根主线。
接下里还是继续回到我们的主题,多路复用器。
先来回顾下我们最初的Bio服务端代码:
public class BioServer {
public static void main(String[] args) throws IOException {
ServerSocket serverSocket = new ServerSocket(8080);
System.out.println("服务启动完成");
while (true) {
//阻塞点1
final Socket socket = serverSocket.accept();
System.out.println("有请求进来了。");
final InputStream inputStream = socket.getInputStream();
byte[] buffer = new byte[1024];
//阻塞点2
int len = inputStream.read(buffer);
final OutputStream outputStream = socket.getOutputStream();
outputStream.write(("你的消息 :" + new String(buffer) + " 收到了。").getBytes());
outputStream.flush();
System.out.println("返回消息响应。");
inputStream.close();
outputStream.close();
socket.close();
}
}
}
关于BIO,我们现在已经知道,他的执行效率是比较低的,很难支撑起高并发的场景。而他最大的问题,就在于两个同步阻塞点,一个是accept函数,一个是read函数。我们要考虑如何来优化BIO应用程序。就需要针对这两个阻塞点进行具体优化。
首先针对read函数阻塞,这个在很多场景下就不可接受了。因为如果有一个客户端连接上来,但是一直不发送消息,那这个服务端会一直阻塞在read函数这里。这样整个服务端就无法处理其他客户端的连接了。
要解决这个问题,最关键的就是对read函数进行改造,让他不再阻塞。很容易想到的一种办法,就是每次都创建一个线程去处理read函数,并处理业务。于是我们可以这样改:
while(true){
new Thread(()->{
byte[] buffer = new byte[1024];
int len = inputStream.read(buffer);
dosomething(buffer);
}).start();
}
这样,当给一个客户端建立好连接后,就可以立即等待新的客户端接入,而不用阻塞在原客户端的read请求上了。
不过,这种方式不叫非阻塞IO,只是通过多线程的手段使得主线程没有卡在read函数上。操作系统为我们提供的read这个系统调用仍然是阻塞的。而一个客户端就开一个线程,对服务器的资源消耗也是非常大的。所以这种小把戏,其实并不能真正提升BIO的性能。
所以问题的核心还是在于操作系统内核提供的read这个系统调用上。如果操作系统内核不提供更进一步的优化,那上层的应用程序也只能束手无策。幸好,在上层应用的千呼万唤之下,操作系统提供了一种不阻塞的方式。
fcntl(5, F_SETFL, O_RDWR|O_NONBLOCK) = 0
通过这一部分,就希望彻底看懂一直讨论的阻塞到底是个什么东西。
3、调试NIO的系统调用
接下来,就拿之前篇章的示例代码,来逐步进行一下验证。
首先需要一种简单的方式来在Linux上执行之前的Netty示例代码。可以在项目的pom.xml文件中,引入一个maven插件,将整个项目代码以及相关依赖打成一个整的jar包,fat jar。
示例代码看之前的篇章
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
这样,使用maven进行clean package后,就可以将整个示例项目打成一个大的jar包。 NettyDemo-0.0.1.jar。上传到服务器后,就可以使用strace指令来分析Nio的系统调用了
strace -ff -o Log java -classpath NettyDemo-0.0.1.jar com.roy.nio.NioServer
注意下,如果Linux服务器上的jdk版本和你用来打包的windows机器的jdk版本不一致,有可能会无法运行。可以尝试下删除/META-INF下的 .RSA和 .SF后缀的签名文件。
这个NioServer的代码跟之前篇章介绍的是一样的。
public class NioServer {
public static void main(String[] args) throws IOException {
//1、绑定端口,开启服务
final ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
final Selector selector = Selector.open();
serverSocketChannel.bind(new InetSocketAddress(8080));
serverSocketChannel.configureBlocking(false);
//这里注意服务端的ServerSocketChannel也要注册到selector上。
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
System.out.println("服务器启动成功");
while (true){
//2、阻塞,等到客户端事件发生。这里设置了超时时间。
final int select = selector.select();
if(select < 1){
System.out.println("当前没有连接进来");
continue;
}
//每个注册上来的channel都会对应一个selectionKey。
final Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();
while (iterator.hasNext()){
final SelectionKey key = iterator.next();
//接收到的channel上发生的是一个accept事件
if(key.isAcceptable()){
//这里serverSocketChannel.accept()会接收客户端的socketChannel连接请求,并返回对接好的socketChannel
//但是要注意,如果此时没有对应的客户端channel,他就会返回一个null。
final SocketChannel newSocketChannel = serverSocketChannel.accept();
System.out.println("收到客户端的连接请求:"+newSocketChannel.getRemoteAddress());
newSocketChannel.configureBlocking(false);
//将与客户端对接好的socketChannel重新注册到selector上,这次是关注READ数据读取时间。
//注册读事件时,需要绑定一个buffer相当于是附件。所有的数据交互都会写入到这个ByteBuffer中。
newSocketChannel.register(selector,SelectionKey.OP_READ,ByteBuffer.allocate(512));
}
//数据读取事件
if(key.isReadable()){
//其他部分的代码基本都是模版,只有这一段是处理客户端请求的,需要定制一下。
handleKey(key);
}
// 把已经处理过的事件清除。防止重复处理。
// 不然的话,对于连接的请求,服务端还是会去accept产生一个socketChannel。但是此时没有客户端来对接,就会返回一个Null。
iterator.remove();
}
}
}
private static void handleKey(SelectionKey key) throws IOException {
//通过selectionKey反查对应的channel。拿到channel后就可以用来跟客户端交互。
final SocketChannel socketChannel = (SocketChannel)key.channel();
//客户端的所有消息内容都会通过这个附件传递。注意,这个附件默认是不会清空的。
ByteBuffer byteBuffer = (ByteBuffer)key.attachment();
byteBuffer.clear();
socketChannel.read(byteBuffer);
System.out.println("收到客户端的消息:"+new String(byteBuffer.array()));
String response = "服务端收到你的消息:"+new String(byteBuffer.array());
socketChannel.write(ByteBuffer.wrap(response.getBytes()));
}
}
执行后,就会启动一个Nio的服务端。同时,生成Log文件。 同样是查看Log开头的第二个文件。我这里文件是Log.15555
less Log.15555
可以看到几个关键的步骤。
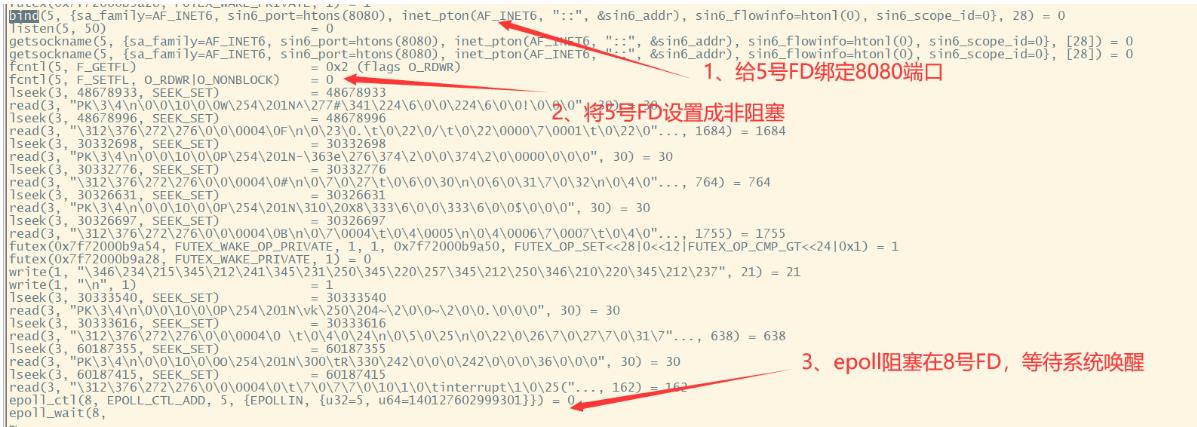
其中,正是因为标号为2的这一行系统调用,使得程序的主线程没有阻塞。而这一个系统调用,就对应了我们程序中那个莫名其妙的一行代码。
serverSocketChannel.configureBlocking(false);
最终,程序通过epoll的系统调用,阻塞在了8号FD上,等待客户端接入。
到这里,其实一方面,能看懂整个Nio怪异的上层代码是一个什么样的逻辑顺序。
接下来就准备用一个客户端连接进来,继续来跟踪这个epoll的多路复用机制。其实,继续仔细跟踪这个日志文件,搜索epoll的关键字,这时已经能够看到一些基础的步骤
epoll_create(256) = 8 创建一个epoll句柄。可以理解为在内核中创建了一个队列(实际上是一个红黑树),编号为8.
epoll_ctl(8, EPOLL_CTL_ADD, 5, {EPOLLIN, {u32=5, u64=140127602999301}}) = 0 向内核添加需要监控的文件描述符。可以理解为在8号队列中添加了一个5号FD。
epoll_wait(8, 程序阻塞在8号队列的epoll事件中。
经过这个操作之后,内核就对8号队列进行监控(这个队列也是一个FD)。当8号队列上监控的这些FD上有一个FD有事件时,就会通知epoll_wait。
我们来模拟这个过程。启动一个新的连接,使用nc指令连上Nio服务端。
nc localhost 8080
这样就会有一个客户端连上这个服务端。跟踪刚才的日志,会发现,之前阻塞的这个epoll_wait,已经往下执行了
epoll_wait(8, [{EPOLLIN, {u32=5, u64=140127602999301}}], 8192, -1) = 1
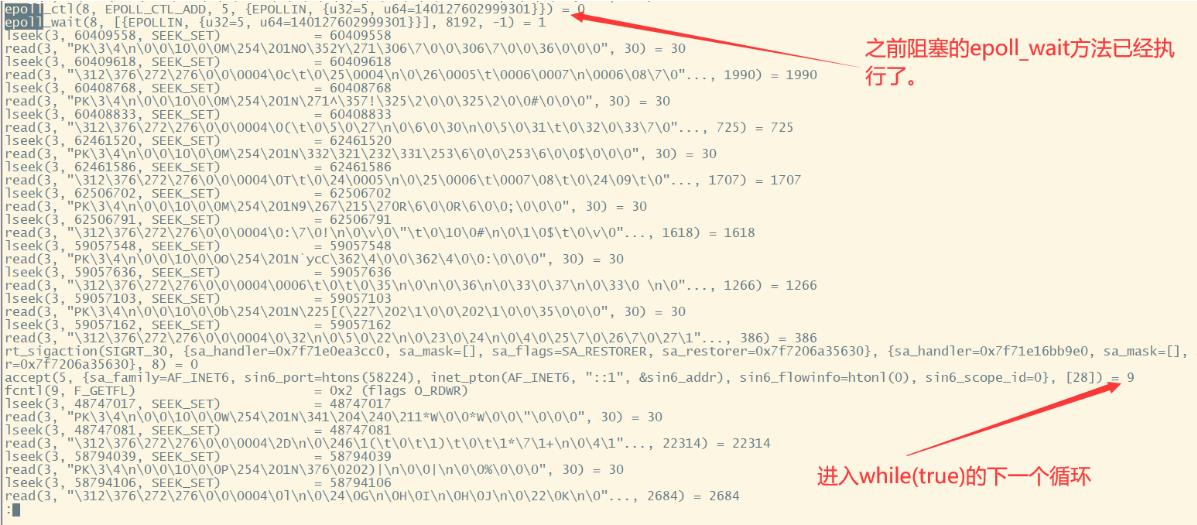
接下来,进入while(true)的下一个循环。会创建一个9号的FD。然后这个FD又会重新经过epoll_ctl添加到8号FD监控队列中,最终又阻塞到epoll_wait(8, 这样一个系统调用。
基于系统调用去分析一个程序的执行情况,是很麻烦的。但是对于IO场景就非常合适了。这样比较容易理解上层语言的底层运行机制。从关键的系统调用,再去反推上层代码的编写顺序,就更容易理解这些代码为什么是这样写的了。
三、章节总结
在这个章节中,我们深入到了操作系统内核中,探究了阻塞根源。我们在开发IO相关的程序时,会不断的分析阻塞的现象以及原因,也会想很多办法进行优化。但是,阻塞最底层的根源在于操作系统内核。而内核是任何应用程序最终执行的一道大闸。任何语言编写的应用程序最终都要翻译成系统调用,才能真正与硬件进行交互,最终落地。只要在操作系统内核中提供的一些关键的系统调用是阻塞的,那整个应用就只能是阻塞的。
BIO程序有两个绕不开的阻塞点,一个是在等待新的请求进来的时候。另一个是在等待连接进来的客户端发送消息的时候。这两个阻塞点,严重制约着网络IO程序的性能。而上层应用的程序员唯一能做的,就是针对第二个堵塞点,通过多线程的方式来防止主线程阻塞。给每个连接上来的客户端连接分配一个线程,通过不断扫描各个子线程,来感知客户端的业务请求。但是,不管程序员怎么想办法优化,整个应用程序也只能是阻塞的,也就是说,程序员是跳不出BIO的范畴的。而线程是有开销的,所以这种方式在并发度和性能消耗等方面的性能,是无法真正突破的。
当上层程序的这种无奈积累到了一定程度,操作系统就不得不出面来提供帮助。
一方面,针对第二个阻塞点,操作系统提供了真正非阻塞的IO系统调用。这样上层应用程序就可以在一个线程内持续的监听多个客户端的消息。这也就是非阻塞IO 。
另一方面,针对第一个阻塞点,操作系统提供了多路复用的机制。解决的思路跟上层应用的解决思路是一致的。也就是将连接上来的客户端都进行注册,然后不断循环扫描各个客户端连接,监听客户端的请求。但是,多路复用机制将原本上层应用的实现逻辑改为在操作系统内核中进行。这样极大的加快了多路复用的效率。
最初的多路复用机制是select函数。这个函数一次性传入所有需要监控的连接(在内核中是FD),并在内核中对这些FD进行持续的扫描。当发现其中有FD不老实时,就会通知应用程序有客户端事件发生了(不同的SelectionKey就代表不同的事件类型)。但是此时,内核无法判断是哪个FD上发生了事件,上层应用接到通知后,就只能自己再去遍历所有的FD,寻找有事件发生的连接,然后进行业务处理。 这也就对应了整个Nio的编程模型。这里也就解释了,为什么在Nio的应用程序中,要给serverSocketChannel调用一下register方法注册进去。在没有客户端接入时,服务端要将自己注册到内核中,这样内核的FD扫描才能有个起点。
但是select受限于操作系统,扫描的FD个数是受限的。于是又进化出了Poll函数,解决了slelect文件描述符受限的问题。但是,上层应用程序依然要自己去遍历所有客户端,寻找哪个客户端上有事件发生。高并发场景下,性能依然严重受限。
于是,在这个基础上又出现了epoll机制。epoll机制会直接返回有事件发生的FD。这样就省掉了上层应用频繁扫描所有客户端的消耗。进一步解决多路复用的高并发问题。这也就是NIO的编程模型。而Netty框架正是对于NIO编程模型的封装。这个封装,在java代码中的体现是非常弱的,因为你很难看到上层代码之间的封装关系,而所谓的封装,更多的是基于底层的系统调用进行封装,从而让上层代码编写比较简单。
但是epoll机制下,整个请求依然是同步的,也就是说,在内核扫描所有FD时,上层应用也只能傻傻等着。在AIO编程模型下,内核不光会扫描出有事件的FD,同时会进一步帮助应用完成业务逻辑。上层应用只需要在内核中注册一个监听程序,告诉操作系统内核要如何完成业务逻辑即可。 这就是异步非阻塞的编程模型。AIO的编程模型对系统内核的要求更高,目前还不是太稳定,所以用得还不是很多,也就没有诞生出很好的封装框架。
所以,IO模型的演进,都是由操作系统推进的。时代的需求倒逼操作系统将更多的功能添加到执行速度更高的操作系统内核中。而上层的高级语言,其实都是如牵线木偶一般,全由操作系统一步步推进。这也就是IO代码逻辑性始终难以理解的根源所在。但是,理清了操作系统底层的真个思路,这些IO代码就真正能够环环相扣,形成一条主线。
另外,在这一章节中,对于系统调用的跟踪分析方式,其实是适用于所有应用程序的,这才是应用程序背后的终极秘密。那在接下来的章节,也同样会通过系统调用,来针对Buffer和Channel来进行一些跟踪,来理解文件读写的秘密。并将谈到一个重要的问题,IO到底会不会丢数据?
以上是关于AutoUpdate.dll到底是个啥文件,为啥瑞星说是怀疑却不杀的主要内容,如果未能解决你的问题,请参考以下文章