强化学习 DQN 经验回放 是什么
Posted 软件工程小施同学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习 DQN 经验回放 是什么相关的知识,希望对你有一定的参考价值。
经验重放: 强化学习由于state之间的相关性存在稳定性的问题,因为智能体去探索环境时采集到的样本是一个时间序列,样本之间具有连续性,所以需要打破时间相关性,解决的办法是在训练的时候存储当前训练的状态到记忆体M,更新参数的时候随机从M中抽样mini-batch进行更新。
具体地,M中存储的数据类型为 <s,a,r,s′>,M有最大长度的限制,以保证更新采用的数据都是最近的数据。经验重放的最终目的是防止过拟合。

算法过程总结如下:
1.随机初始化一个状态 s,初始化记忆池(Replay DB),设置观察值。
2.循环遍历(是永久遍历还是只遍历一定次数这个自己设置):
(1) 根据策略选择一个行为(action)。
(2) 执行该行动(aaction),得到奖励(reward)、执行该行为后的状态 s`和游戏是否结束 done。
(3) 保存 s, a, r, s`, done 到记忆池里。
(4) 判断记忆池里的数据是否足够(即:记忆池里的数据数量是否超过设置的观察值),如果不够,则转到(5)步。
①在记忆池里随机抽取出一部分数据做为训练样本。
②将所有训练样本的 s`做为神经网络的输入值,进行批量处理,得到 s`状态下每个行为的 q 值的表。
③根据公式计算出 q 值表对应的 target_q 值表。
公式:Q(s, a) = r +Gamma * Max[Q(s`, all actions)]
④使用 q 与 target_q 训练神经网络。
(5) 判断游戏(目标系统是否运行结束)是否结束。
①游戏结束,给 s 随机设置一个状态,再执行(1), (2),(3),(4)。
②未结束,则当前状态 s 更新为 s`(意思就是当前的状态变成 s`,以当前的 s`去action,得到r,得到执行该行为后的状态 s`'和游戏是否结束 done)。

 https://zhuanlan.zhihu.com/p/339964218
https://zhuanlan.zhihu.com/p/339964218


从Replay Memory中抽取一定量的样本,对神经网络的参数进行更新

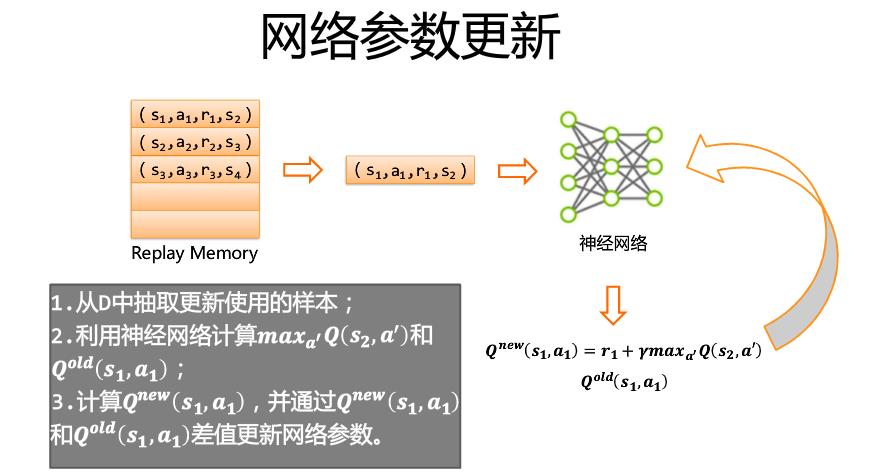
https://www.jianshu.com/p/42507aa63b05/ https://www.jianshu.com/p/42507aa63b05/
https://www.jianshu.com/p/42507aa63b05/
以上是关于强化学习 DQN 经验回放 是什么的主要内容,如果未能解决你的问题,请参考以下文章