Android 音频系统:从 AudioTrack 到 AudioFlinger
Posted zyuanyun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Android 音频系统:从 AudioTrack 到 AudioFlinger相关的知识,希望对你有一定的参考价值。
1. android 音频框架概述
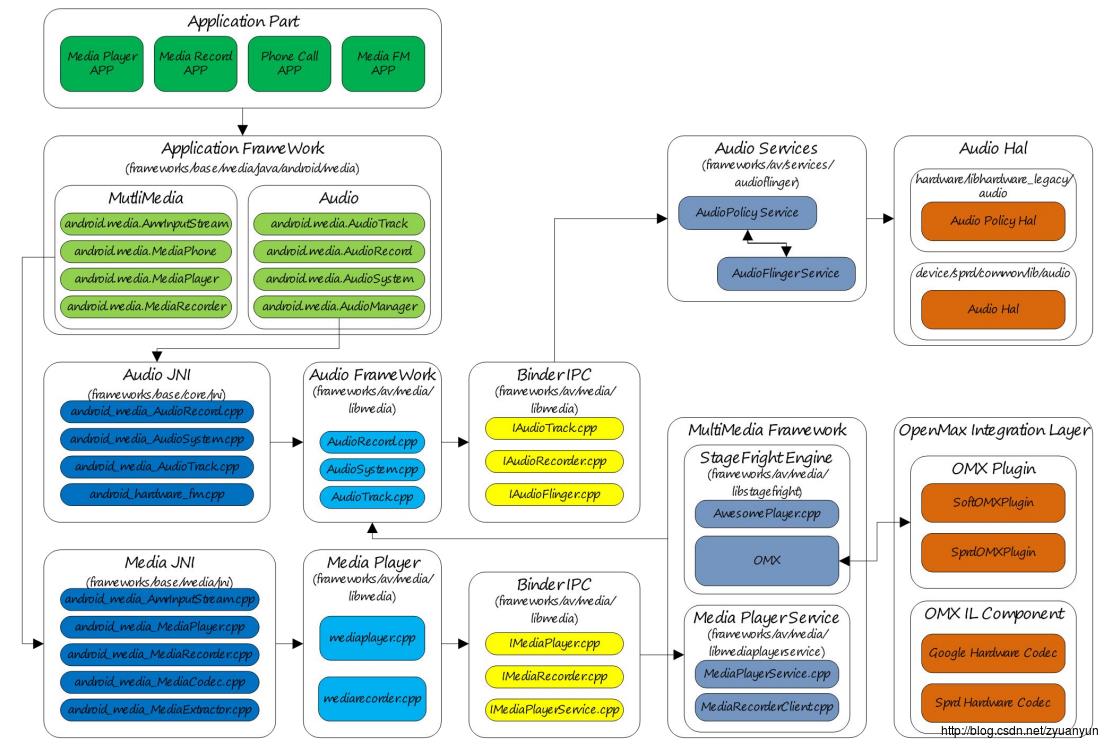
Audio 是整个 Android 平台非常重要的一个组成部分,负责音频数据的采集和输出、音频流的控制、音频设备的管理、音量调节等,主要包括如下部分:
- Audio Application Framework:音频应用框架
- AudioTrack:负责回放数据的输出,属 Android 应用框架 API 类
- AudioRecord:负责录音数据的采集,属 Android 应用框架 API 类
- Audiosystem: 负责音频事务的综合管理,属 Android 应用框架 API 类
- Audio Native Framework:音频本地框架
- AudioTrack:负责回放数据的输出,属 Android 本地框架 API 类
- AudioRecord:负责录音数据的采集,属 Android 本地框架 API 类
- AudioSystem: 负责音频事务的综合管理,属 Android 本地框架 API 类
- Audio Services:音频服务
- AudioPolicyService:音频策略的制定者,负责音频设备切换的策略抉择、音量调节策略等
- AudioFlinger:音频策略的执行者,负责输入输出流设备的管理及音频流数据的处理传输
- Audio HAL:音频硬件抽象层,负责与音频硬件设备的交互,由 AudioFlinger 直接调用
与 Audio 强相关的有 MultiMedia,MultiMedia 负责音视频的编解码,MultiMedia 将解码后的数据通过 AudioTrack 输出,而 AudioRecord 采集的录音数据交由 MultiMedia 进行编码。
本文分析基于 Android 7.0 - Nougat。
//
// 声明:本文由 http://blog.csdn.net/zyuanyun 原创,转载请注明出处,谢谢!
//
2. AudioTrack API 概述
播放声音可以使用 MediaPlayer 和 AudioTrack,两者都提供 Java API 给应用开发者使用。两者的差别在于:MediaPlayer 可以播放多种格式的音源,如 mp3、flac、wma、ogg、wav 等,而 AudioTrack 只能播放解码后的 PCM 数据流。从上面 Android 音频系统架构图来看:MediaPlayer 在 Native 层会创建对应的音频解码器和一个 AudioTrack,解码后的数据交由 AudioTrack 输出。所以 MediaPlayer 的应用场景更广,一般情况下使用它也更方便;只有一些对声音时延要求非常苛刻的应用场景才需要用到 AudioTrack。
2.1. AudioTrack Java API
AudioTrack Java API 两种数据传输模式:
| Transfer Mode | Description |
|---|---|
| MODE_STATIC | 应用进程将回放数据一次性付给 AudioTrack,适用于数据量小、时延要求高的场景 |
| MODE_STREAM | 用进程需要持续调用 write() 写数据到 FIFO,写数据时有可能遭遇阻塞(等待 AudioFlinger::PlaybackThread 消费之前的数据),基本适用所有的音频场景 |
AudioTrack Java API 音频流类型:
| Stream Type | Description |
|---|---|
| STREAM_VOICE_CALL | 电话语音 |
| STREAM_SYSTEM | 系统声音 |
| STREAM_RING | 铃声声音,如来电铃声、闹钟铃声等 |
| STREAM_MUSIC | 音乐声音 |
| STREAM_ALARM | 警告音 |
| STREAM_NOTIFICATION | 通知音 |
| STREAM_DTMF | DTMF 音(拨号盘按键音) |
Android 为什么要定义这么多的流类型?这与 Android 的音频管理策略有关,例如:
- 音频流的音量管理,调节一个类型的音频流音量,不会影响到其他类型的音频流
- 根据流类型选择合适的输出设备;比如插着有线耳机期间,音乐声(STREAM_MUSIC)只会输出到有线耳机,而铃声(STREAM_RING)会同时输出到有线耳机和外放
这些属于 AudioPolicyService 的内容,本文不展开分析了。应用开发者应该根据应用场景选择相应的流类型,以便系统为这道流选择合适的输出设备。
一个 AudioTrack Java API 的测试例子(MODE_STREAM 模式):
//Test case 1: setStereoVolume() with max volume returns SUCCESS
@LargeTest
public void testSetStereoVolumeMax() throws Exception {
// constants for test
final String TEST_NAME = "testSetStereoVolumeMax";
final int TEST_SR = 22050;
final int TEST_CONF = AudioFormat.CHANNEL_OUT_STEREO;
final int TEST_FORMAT = AudioFormat.ENCODING_PCM_16BIT;
final int TEST_MODE = AudioTrack.MODE_STREAM;
final int TEST_STREAM_TYPE = AudioManager.STREAM_MUSIC;
//-------- initialization --------------
// 稍后详细分析 getMinBufferSize
int minBuffSize = AudioTrack.getMinBufferSize(TEST_SR, TEST_CONF, TEST_FORMAT);
// 创建一个 AudioTrack 实例
AudioTrack track = new AudioTrack(TEST_STREAM_TYPE, TEST_SR, TEST_CONF, TEST_FORMAT,
minBuffSize, TEST_MODE);
byte data[] = new byte[minBuffSize/2];
//-------- test --------------
// 调用 write() 写入回放数据
track.write(data, 0, data.length);
track.write(data, 0, data.length);
// 调用 play() 开始播放
track.play();
float maxVol = AudioTrack.getMaxVolume();
assertTrue(TEST_NAME, track.setStereoVolume(maxVol, maxVol) == AudioTrack.SUCCESS);
//-------- tear down --------------
// 播放完成后,调用 release() 释放 AudioTrack 实例
track.release();
}详细说明下 getMinBufferSize() 接口,字面意思是返回最小数据缓冲区的大小,它是声音能正常播放的最低保障,从函数参数来看,返回值取决于采样率、采样深度、声道数这三个属性。MODE_STREAM 模式下,应用程序重点参考其返回值然后确定分配多大的数据缓冲区。如果数据缓冲区分配得过小,那么播放声音会频繁遭遇 underrun,underrun 是指生产者(AudioTrack)提供数据的速度跟不上消费者(AudioFlinger::PlaybackThread)消耗数据的速度,反映到现实的后果就是声音断续卡顿,严重影响听觉体验。
// AudioTrack.java
/**
* Returns the estimated minimum buffer size required for an AudioTrack
* object to be created in the {@link #MODE_STREAM} mode.
* The size is an estimate because it does not consider either the route or the sink,
* since neither is known yet. Note that this size doesn't
* guarantee a smooth playback under load, and higher values should be chosen according to
* the expected frequency at which the buffer will be refilled with additional data to play.
* For example, if you intend to dynamically set the source sample rate of an AudioTrack
* to a higher value than the initial source sample rate, be sure to configure the buffer size
* based on the highest planned sample rate.
* @param sampleRateInHz the source sample rate expressed in Hz.
* {@link AudioFormat#SAMPLE_RATE_UNSPECIFIED} is not permitted.
* @param channelConfig describes the configuration of the audio channels.
* See {@link AudioFormat#CHANNEL_OUT_MONO} and
* {@link AudioFormat#CHANNEL_OUT_STEREO}
* @param audioFormat the format in which the audio data is represented.
* See {@link AudioFormat#ENCODING_PCM_16BIT} and
* {@link AudioFormat#ENCODING_PCM_8BIT},
* and {@link AudioFormat#ENCODING_PCM_FLOAT}.
* @return {@link #ERROR_BAD_VALUE} if an invalid parameter was passed,
* or {@link #ERROR} if unable to query for output properties,
* or the minimum buffer size expressed in bytes.
*/
static public int getMinBufferSize(int sampleRateInHz, int channelConfig, int audioFormat) {
int channelCount = 0;
switch(channelConfig) {
case AudioFormat.CHANNEL_OUT_MONO:
case AudioFormat.CHANNEL_CONFIGURATION_MONO:
channelCount = 1; // 单声道
break;
case AudioFormat.CHANNEL_OUT_STEREO:
case AudioFormat.CHANNEL_CONFIGURATION_STEREO:
channelCount = 2; // 双声道
break;
default:
if (!isMultichannelConfigSupported(channelConfig)) {
loge("getMinBufferSize(): Invalid channel configuration.");
return ERROR_BAD_VALUE;
} else {
channelCount = AudioFormat.channelCountFromOutChannelMask(channelConfig);
}
}
if (!AudioFormat.isPublicEncoding(audioFormat)) {
loge("getMinBufferSize(): Invalid audio format.");
return ERROR_BAD_VALUE;
}
// sample rate, note these values are subject to change
// Note: AudioFormat.SAMPLE_RATE_UNSPECIFIED is not allowed
if ( (sampleRateInHz < AudioFormat.SAMPLE_RATE_HZ_MIN) ||
(sampleRateInHz > AudioFormat.SAMPLE_RATE_HZ_MAX) ) {
loge("getMinBufferSize(): " + sampleRateInHz + " Hz is not a supported sample rate.");
return ERROR_BAD_VALUE; // 采样率支持:4KHz~192KHz
}
// 调用 JNI 方法,下面分析该函数
int size = native_get_min_buff_size(sampleRateInHz, channelCount, audioFormat);
if (size <= 0) {
loge("getMinBufferSize(): error querying hardware");
return ERROR;
}
else {
return size;
}
}
// android_media_AudioTrack.cpp
// ----------------------------------------------------------------------------
// returns the minimum required size for the successful creation of a streaming AudioTrack
// returns -1 if there was an error querying the hardware.
static jint android_media_AudioTrack_get_min_buff_size(JNIEnv *env, jobject thiz,
jint sampleRateInHertz, jint channelCount, jint audioFormat) {
size_t frameCount;
// 调用 AudioTrack::getMinFrameCount,这里不深究,到 native 层再分析
// 这个函数用于确定至少设置多少个 frame 才能保证声音正常播放,也就是最低帧数
const status_t status = AudioTrack::getMinFrameCount(&frameCount, AUDIO_STREAM_DEFAULT,
sampleRateInHertz);
if (status != NO_ERROR) {
ALOGE("AudioTrack::getMinFrameCount() for sample rate %d failed with status %d",
sampleRateInHertz, status);
return -1;
}
const audio_format_t format = audioFormatToNative(audioFormat);
if (audio_has_proportional_frames(format)) {
const size_t bytesPerSample = audio_bytes_per_sample(format);
return frameCount * channelCount * bytesPerSample; // PCM 数据最小缓冲区大小
} else {
return frameCount;
}
}
可见最小缓冲区的大小 = 最低帧数 * 声道数 * 采样深度,(采样深度以字节为单位),到这里大家应该有所明悟了吧,在视频中,如果帧数过低,那么画面会有卡顿感,对于音频,道理也是一样的。最低帧数如何求得,我们到 native 层再解释。
关于 MediaPlayer、AudioTrack,更多更详细的 API 接口说明请参考 Android Developer:
- MediaPlayer:https://developer.android.com/reference/android/media/MediaPlayer.html
- AudioTrack:https://developer.android.com/reference/android/media/AudioTrack.html
2.2. AudioTrack Native API
AudioTrack Native API 四种数据传输模式:
| Transfer Mode | Description |
|---|---|
| TRANSFER_CALLBACK | 在 AudioTrackThread 线程中通过 audioCallback 回调函数主动从应用进程那里索取数据,ToneGenerator 采用这种模式 |
| TRANSFER_OBTAIN | 应用进程需要调用 obtainBuffer()/releaseBuffer() 填充数据,目前我还没有见到实际的使用场景 |
| TRANSFER_SYNC | 应用进程需要持续调用 write() 写数据到 FIFO,写数据时有可能遭遇阻塞(等待 AudioFlinger::PlaybackThread 消费之前的数据),基本适用所有的音频场景;对应于 AudioTrack Java API 的 MODE_STREAM 模式 |
| TRANSFER_SHARED | 应用进程将回放数据一次性付给 AudioTrack,适用于数据量小、时延要求高的场景;对应于 AudioTrack Java API 的 MODE_STATIC 模式 |
AudioTrack Native API 音频流类型:
| Stream Type | Description |
|---|---|
| AUDIO_STREAM_VOICE_CALL | 电话语音 |
| AUDIO_STREAM_SYSTEM | 系统声音 |
| AUDIO_STREAM_RING | 铃声声音,如来电铃声、闹钟铃声等 |
| AUDIO_STREAM_MUSIC | 音乐声音 |
| AUDIO_STREAM_ALARM | 警告音 |
| AUDIO_STREAM_NOTIFICATION | 通知音 |
| AUDIO_STREAM_DTMF | DTMF 音(拨号盘按键音) |
AudioTrack Native API 输出标识:
| AUDIO_OUTPUT_FLAG | Description |
|---|---|
| AUDIO_OUTPUT_FLAG_DIRECT | 表示音频流直接输出到音频设备,不需要软件混音,一般用于 HDMI 设备声音输出 |
| AUDIO_OUTPUT_FLAG_PRIMARY | 表示音频流需要输出到主输出设备,一般用于铃声类声音 |
| AUDIO_OUTPUT_FLAG_FAST | 表示音频流需要快速输出到音频设备,一般用于按键音、游戏背景音等对时延要求高的场景 |
| AUDIO_OUTPUT_FLAG_DEEP_BUFFER | 表示音频流输出可以接受较大的时延,一般用于音乐、视频播放等对时延要求不高的场景 |
| AUDIO_OUTPUT_FLAG_COMPRESS_OFFLOAD | 表示音频流没有经过软件解码,需要输出到硬件解码器,由硬件解码器进行解码 |
我们根据不同的播放场景,使用不同的输出标识,如按键音、游戏背景音对输出时延要求很高,那么就需要置 AUDIO_OUTPUT_FLAG_FAST,具体可以参考 ToneGenerator、SoundPool 和 OpenSL ES。
一个 AudioTrack Natvie API 的测试例子(MODE_STATIC/TRANSFER_SHARED 模式),代码文件位置:frameworks/base/media/tests/audiotests/shared_mem_test.cpp:
int AudioTrackTest::Test01() {
sp<MemoryDealer> heap;
sp<IMemory> iMem;
uint8_t* p;
short smpBuf[BUF_SZ];
long rate = 44100;
unsigned long phi;
unsigned long dPhi;
long amplitude;
long freq = 1237;
float f0;
f0 = pow(2., 32.) * freq / (float)rate;
dPhi = (unsigned long)f0;
amplitude = 1000;
phi = 0;
Generate(smpBuf, BUF_SZ, amplitude, phi, dPhi); // fill buffer
for (int i = 0; i < 1024; i++) {
// 分配一块匿名共享内存
heap = new MemoryDealer(1024*1024, "AudioTrack Heap Base");
iMem = heap->allocate(BUF_SZ*sizeof(short));
// 把音频数据拷贝到这块匿名共享内存上
p = static_cast<uint8_t*>(iMem->pointer());
memcpy(p, smpBuf, BUF_SZ*sizeof(short));
// 构造一个 AudioTrack 实例,该 AudioTrack 的数据方式是 MODE_STATIC
// 音频数据已经一次性拷贝到共享内存上了,不用再调用 track->write() 填充数据了
sp<AudioTrack> track = new AudioTrack(AUDIO_STREAM_MUSIC,// stream type
rate,
AUDIO_FORMAT_PCM_16_BIT,// word length, PCM
AUDIO_CHANNEL_OUT_MONO,
iMem);
// 检查 AudioTrack 实例是否构造成功饿了
status_t status = track->initCheck();
if(status != NO_ERROR) {
track.clear();
ALOGD("Failed for initCheck()");
return -1;
}
// start play
ALOGD("start");
track->start(); // 开始播放
usleep(20000);
ALOGD("stop");
track->stop(); // 停止播放
iMem.clear();
heap.clear();
usleep(20000);
}
return 0;
}上个小节还存在一个问题:AudioTrack::getMinFrameCount() 如何计算最低帧数呢?
首先要了解音频领域中,帧(frame)的概念:帧表示一个完整的声音单元,所谓的声音单元是指一个采样样本;如果是双声道,那么一个完整的声音单元就是 2 个样本,如果是 5.1 声道,那么一个完整的声音单元就是 6 个样本了。帧的大小(一个完整的声音单元的数据量)等于声道数乘以采样深度,即 frameSize = channelCount * bytesPerSample。帧的概念非常重要,无论是框架层还是内核层,都是以帧为单位去管理音频数据缓冲区的。
其次还得了解音频领域中,传输延迟(latency)的概念:传输延迟表示一个周期的音频数据的传输时间。可能有些读者一脸懵逼,一个周期的音频数据,这又是啥?我们再引入周期(period)的概念:Linux ALSA 把数据缓冲区划分为若干个块,dma 每传输完一个块上的数据即发出一个硬件中断,cpu 收到中断信号后,再配置 dma 去传输下一个块上的数据;一个块即是一个周期,周期大小(periodSize)即是一个数据块的帧数。再回到传输延迟(latency),传输延迟等于周期大小除以采样率,即 latency = periodSize / sampleRate。
最后了解下音频重采样:音频重采样是指这样的一个过程——把一个采样率的数据转换为另一个采样率的数据。Android 原生系统上,音频硬件设备一般都工作在一个固定的采样率上(如 48 KHz),因此所有音轨数据都需要重采样到这个固定的采样率上,然后再输出。为什么这么做?系统中可能存在多个音轨同时播放,而每个音轨的采样率可能是不一致的;比如在播放音乐的过程中,来了一个提示音,这时需要把音乐和提示音混音并输出到硬件设备,而音乐的采样率和提示音的采样率不一致,问题来了,如果硬件设备工作的采样率设置为音乐的采样率的话,那么提示音就会失真;因此最简单见效的解决方法是:硬件设备工作的采样率固定一个值,所有音轨在 AudioFlinger 都重采样到这个采样率上,混音后输出到硬件设备,保证所有音轨听起来都不失真。
sample、frame、period、latency 这些概念与 Linux ALSA 及硬件设备的关系非常密切,这里点到即止,如有兴趣深入了解的话,可参考:Linux ALSA 音频系统:逻辑设备篇
了解这些前置知识后,我们再分析 AudioTrack::getMinFrameCount() 这个函数:
status_t AudioTrack::getMinFrameCount(
size_t* frameCount,
audio_stream_type_t streamType,
uint32_t sampleRate)
{
if (frameCount == NULL) {
return BAD_VALUE;
}
// 通过 binder 调用到 AudioFlinger::sampleRate(),取得硬件设备的采样率
uint32_t afSampleRate;
status_t status;
status = AudioSystem::getOutputSamplingRate(&afSampleRate, streamType);
if (status != NO_ERROR) {
ALOGE("Unable to query output sample rate for stream type %d; status %d",
streamType, status);
return status;
}
// 通过 binder 调用到 AudioFlinger::frameCount(),取得硬件设备的周期大小
size_t afFrameCount;
status = AudioSystem::getOutputFrameCount(&afFrameCount, streamType);
if (status != NO_ERROR) {
ALOGE("Unable to query output frame count for stream type %d; status %d",
streamType, status);
return status;
}
// 通过 binder 调用到 AudioFlinger::latency(),取得硬件设备的传输延迟
uint32_t afLatency;
status = AudioSystem::getOutputLatency(&afLatency, streamType);
if (status != NO_ERROR) {
ALOGE("Unable to query output latency for stream type %d; status %d",
streamType, status);
return status;
}
// When called from createTrack, speed is 1.0f (normal speed).
// This is rechecked again on setting playback rate (TODO: on setting sample rate, too).
// 根据 afSampleRate、afFrameCount、afLatency 计算出一个最低帧数
*frameCount = calculateMinFrameCount(afLatency, afFrameCount, afSampleRate, sampleRate, 1.0f);
// The formula above should always produce a non-zero value under normal circumstances:
// AudioTrack.SAMPLE_RATE_HZ_MIN <= sampleRate <= AudioTrack.SAMPLE_RATE_HZ_MAX.
// Return error in the unlikely event that it does not, as that's part of the API contract.
if (*frameCount == 0) {
ALOGE("AudioTrack::getMinFrameCount failed for streamType %d, sampleRate %u",
streamType, sampleRate);
return BAD_VALUE;
}
ALOGV("getMinFrameCount=%zu: afFrameCount=%zu, afSampleRate=%u, afLatency=%u",
*frameCount, afFrameCount, afSampleRate, afLatency);
return NO_ERROR;
}
// 有兴趣的可以研究 calculateMinFrameCount() 的实现,需大致了解重采样算法原理
static size_t calculateMinFrameCount(
uint32_t afLatencyMs, uint32_t afFrameCount, uint32_t afSampleRate,
uint32_t sampleRate, float speed)
{
// Ensure that buffer depth covers at least audio hardware latency
uint32_t minBufCount = afLatencyMs / ((1000 * afFrameCount) / afSampleRate);
if (minBufCount < 2) {
minBufCount = 2;
}
ALOGV("calculateMinFrameCount afLatency %u afFrameCount %u afSampleRate %u "
"sampleRate %u speed %f minBufCount: %u",
afLatencyMs, afFrameCount, afSampleRate, sampleRate, speed, minBufCount);
return minBufCount * sourceFramesNeededWithTimestretch(
sampleRate, afFrameCount, afSampleRate, speed);
}
static inline size_t sourceFramesNeededWithTimestretch(
uint32_t srcSampleRate, size_t dstFramesRequired, uint32_t dstSampleRate,
float speed) {
// required is the number of input frames the resampler needs
size_t required = sourceFramesNeeded(srcSampleRate, dstFramesRequired, dstSampleRate);
// to deliver this, the time stretcher requires:
return required * (double)speed + 1 + 1; // accounting for rounding dependencies
}
// Returns the source frames needed to resample to destination frames. This is not a precise
// value and depends on the resampler (and possibly how it handles rounding internally).
// Nevertheless, this should be an upper bound on the requirements of the resampler.
// If srcSampleRate and dstSampleRate are equal, then it returns destination frames, which
// may not be true if the resampler is asynchronous.
static inline size_t sourceFramesNeeded(
uint32_t srcSampleRate, size_t dstFramesRequired, uint32_t dstSampleRate) {
// +1 for rounding - always do this even if matched ratio (resampler may use phases not ratio)
// +1 for additional sample needed for interpolation
return srcSampleRate == dstSampleRate ? dstFramesRequired :
size_t((uint64_t)dstFramesRequired * srcSampleRate / dstSampleRate + 1 + 1);
}我们不深入分析 calculateMinFrameCount() 函数了,并不是说这个函数的流程有多复杂,而是它涉及到音频重采样的背景原理,说清楚 how 很容易,但说清楚 why 就很困难了。目前我们只需要知道:这个函数根据硬件设备的配置信息(采样率、周期大小、传输延迟)和音轨的采样率,计算出一个最低帧数(应用程序至少设置多少个帧才能保证声音正常播放)。
说点题外话,Anroid 2.2 时,AudioTrack::getMinFrameCount() 的处理很简单:
status_t AudioTrack::getMinFrameCount(
int* frameCount,
int streamType,
uint32_t sampleRate)
{
int afSampleRate;
if (AudioSystem::getOutputSamplingRate(&afSampleRate, streamType) != NO_ERROR) {
return NO_INIT;
}
int afFrameCount;
if (AudioSystem::getOutputFrameCount(&afFrameCount, streamType) != NO_ERROR) {
return NO_INIT;
}
uint32_t afLatency;
if (AudioSystem::getOutputLatency(&afLatency, streamType) != NO_ERROR) {
return NO_INIT;
}
// Ensure that buffer depth covers at least audio hardware latency
uint32_t minBufCount = afLatency / ((1000 * afFrameCount) / afSampleRate);
if (minBufCount < 2) minBufCount = 2;
*frameCount = (sampleRate == 0) ? afFrameCount * minBufCount :
afFrameCount * minBufCount * sampleRate / afSampleRate;
return NO_ERROR;
}从这段来看,最低帧数也是基于重采样来计算的,只不过这里的处理很粗糙:afFrameCount 是硬件设备处理单个数据块的帧数,afSampleRate 是硬件设备配置的采样率,sampleRate 是音轨的采样率,如果要把音轨数据重采样到 afSampleRate 上,那么反推算出应用程序最少传入的帧数为 afFrameCount * sampleRate / afSampleRate,而为了播放流畅,实际上还要大一点,所以再乘以一个系数(可参照 framebuffer 双缓冲,一个缓冲缓存当前的图像,一个缓冲准备下一幅的图像,这样图像切换更流畅),然后就得出一个可以保证播放流畅的最低帧数 minFrameCount = (afFrameCount * sampleRate / afSampleRate) * minBufCount。
为什么 Android 7.0 这方面的处理比 Android 2.2 复杂那么多呢?我想是两个原因:
- Android 7.0 充分考虑了边界处理
- Android 2.2 只支持采样率 4~48 KHz 的音轨,但 Android 7.0 支持采样率 4~192 KHz 的音轨,因此现在对重采样处理提出更严格的要求
3. AudioFlinger 概述
AudioPolicyService 与 AudioFlinger 是 Android 音频系统的两大基本服务。前者是音频系统策略的制定者,负责音频设备切换的策略抉择、音量调节策略等;后者是音频系统策略的执行者,负责音频流设备的管理及音频流数据的处理传输,所以 AudioFlinger 也被认为是 Android 音频系统的引擎。
3.1. AudioFlinger 代码文件结构
$ tree ./frameworks/av/services/audioflinger/
./frameworks/av/services/audioflinger/
├── Android.mk
├── AudioFlinger.cpp
├── AudioFlinger.h
├── AudioHwDevice.cpp
├── AudioHwDevice.h
├── AudioMixer.cpp
├── AudioMixer.h
├── AudioMixerOps.h
├── audio-resampler
│ ├── Android.mk
│ ├── AudioResamplerCoefficients.cpp
│ └── filter_coefficients.h
├── AudioResampler.cpp
├── AudioResamplerCubic.cpp
├── AudioResamplerCubic.h
├── AudioResamplerDyn.cpp
├── AudioResamplerDyn.h
├── AudioResamplerFirGen.h
├── AudioResamplerFirOps.h
├── AudioResamplerFirProcess.h
├── AudioResamplerFirProcessNeon.h
├── AudioResampler.h
├── AudioResamplerSinc.cpp
├── AudioResamplerSincDown.h
├── AudioResamplerSinc.h
├── AudioResamplerSincUp.h
├── AudioStreamOut.cpp
├── AudioStreamOut.h
├── AudioWatchdog.cpp
├── AudioWatchdog.h
├── BufferProviders.cpp
├── BufferProviders.h
├── Configuration.h
├── Effects.cpp
├── Effects.h
├── FastCapture.cpp
├── FastCaptureDumpState.cpp
├── FastCaptureDumpState.h
├── FastCapture.h
├── FastCaptureState.cpp
├── FastCaptureState.h
├── FastMixer.cpp
├── FastMixerDumpState.cpp
├── FastMixerDumpState.h
├── FastMixer.h
├── FastMixerState.cpp
├── FastMixerState.h
├── FastThread.cpp
├── FastThreadDumpState.cpp
├── FastThreadDumpState.h
├── FastThread.h
├── FastThreadState.cpp
├── FastThreadState.h
├── MODULE_LICENSE_APACHE2
├── NOTICE
├── PatchPanel.cpp
├── PatchPanel.h
├── PlaybackTracks.h
├── RecordTracks.h
├── ServiceUtilities.cpp
├── ServiceUtilities.h
├── SpdifStreamOut.cpp
├── SpdifStreamOut.h
├── StateQueue.cpp
├── StateQueue.h
├── StateQueueInstantiations.cpp
├── test-resample.cpp
├── tests
│ ├── Android.mk
│ ├── build_and_run_all_unit_tests.sh
│ ├── mixer_to_wav_tests.sh
│ ├── resampler_tests.cpp
│ ├── run_all_unit_tests.sh
│ ├── test-mixer.cpp
│ └── test_utils.h
├── Threads.cpp
├── Threads.h
├── TrackBase.h
└── Tracks.cpp
2 directories, 77 files记得刚接触 Android 时,版本是 Android 2.2-Froyo,AudioFlinger 只有 3 个源文件:AudioFlinger.cpp、AudioMixer.cpp、AudioResampler.cpp。
现在文件多了许多,代码量就不用说了。但是接口及其基本流程一直没有改变的,只是更加模块化了,Google 把多个子类抽取出来独立成文件,比如 Threads.cpp、Tracks.cpp、Effects.cpp,而 AudioFlinger.cpp 只包含对外提供的服务接口了。另外相比以前,增加更多的功能特性,如 teesink、Offload、FastMixer、FastCapture、FastThread、PatchPanel 等,这里不对这些功能特性扩展描述,有兴趣的可以自行分析。
- AudioResampler.cpp:重采样处理类,可进行采样率转换和声道转换;由录制线程 AudioFlinger::RecordThread 直接使用
- AudioMixer.cpp:混音处理类,包括重采样、音量调节、声道转换等,其中的重采样复用了 AudioResampler;由回放线程 AudioFlinger::MixerThread 直接使用
- Effects.cpp:音效处理类
- Tracks.cpp:音频流管理类,可控制音频流的状态,如 start、stop、pause
- Threads.cpp:回放线程和录制线程类;回放线程从 FIFO 读取回放数据并混音处理,然后写数据到输出流设备;录制线程从输入流设备读取录音数据并重采样处理,然后写数据到 FIFO
- AudioFlinger.cpp:AudioFlinger 对外提供的服务接口
本文内容主要涉及 AudioFlinger.cpp、Threads.cpp、Tracks.cpp 这三个文件。
3.2. AudioFlinger 服务启动
从 Android 7.0 开始,AudioFlinger 在系统启动时由 audioserver 加载(之前版本由 mediaserver 加载),详见 frameworks/av/media/audioserver/main_audioserver.cpp:
int main(int argc __unused, char **argv)
{
// ......
sp<ProcessState> proc(ProcessState::self());
sp<IServiceManager> sm = defaultServiceManager();
ALOGI("ServiceManager: %p", sm.get());
AudioFlinger::instantiate();
AudioPolicyService::instantiate();
RadioService::instantiate();
SoundTriggerHwService::instantiate();
ProcessState::self()->startThreadPool();
IPCThreadState::self()->joinThreadPool();
}可见 audioserver 把音频相关的服务都加载了,包括 AudioFlinger、AudioPolicyService、RadioService、SoundTriggerHwService。
main_audioserver.cpp 编译生成的可执行文件存放在 /system/bin/audioserver,系统启动时由 init 进程运行,详见 frameworks/av/media/audioserver/audioserver.rc:
service audioserver /system/bin/audioserver
class main
user audioserver
# media gid needed for /dev/fm (radio) and for /data/misc/media (tee)
group audio camera drmrpc inet media mediadrm net_bt net_bt_admin net_bw_acct
ioprio rt 4
writepid /dev/cpuset/foreground/tasks /dev/stune/foreground/tasksAudioFlinger 服务启动后,其他进程可以通过 ServiceManager 来获取其代理对象 IAudioFlinger,通过 IAudioFlinger 可以向 AudioFlinger 发出各种服务请求,从而完成自己的音频业务。
3.3. AudioFlinger 服务接口
AudioFlinger 对外提供的主要的服务接口如下:
| Interface | Description |
|---|---|
| sampleRate | 获取硬件设备的采样率 |
| format | 获取硬件设备的音频格式 |
| frameCount | 获取硬件设备的周期帧数 |
| latency | 获取硬件设备的传输延迟 |
| setMasterVolume | 调节主输出设备的音量 |
| setMasterMute | 静音主输出设备 |
| setStreamVolume | 调节指定类型的音频流的音量,这种调节不影响其他类型的音频流的音量 |
| setStreamMute | 静音指定类型的音频流 |
| setVoiceVolume | 调节通话音量 |
| setMicMute | 静音麦克风输入 |
| setMode | 切换音频模式:音频模式有 4 种,分别是 Normal、Ringtone、Call、Communicatoin |
| setParameters | 设置音频参数:往下调用 HAL 层相应接口,常用于切换音频通道 |
| getParameters | 获取音频参数:往下调用 HAL 层相应接口 |
| openOutput | 打开输出流:打开输出流设备,并创建 PlaybackThread 对象 |
| closeOutput | 关闭输出流:移除并销毁 PlaybackThread 上面挂着的所有的 Track,退出 PlaybackThread,关闭输出流设备 |
| openInput | 打开输入流:打开输入流设备,并创建 RecordThread 对象 |
| closeInput | 关闭输入流:退出 RecordThread,关闭输入流设备 |
| createTrack | 新建输出流管理对象: 找到对应的 PlaybackThread,创建输出流管理对象 Track,然后创建并返回该 Track 的代理对象 TrackHandle |
| openRecord | 新建输入流管理对象:找到 RecordThread,创建输入流管理对象 RecordTrack,然后创建并返回该 RecordTrack 的代理对象 RecordHandle |
可以归纳出 AudioFlinger 响应的服务请求主要有:
- 获取硬件设备的配置信息
- 音量调节
- 静音操作
- 音频模式切换
- 音频参数设置
- 输入输出流设备管理
- 音频流管理
就本文范围而言,主要涉及 openOutput() 和 createTrack() 这两个接口,后面也会详细分析这两个接口的流程。
3.4. AudioFlinger 回放录制线程
AndioFlinger 作为 Android 的音频系统引擎,重任之一是负责输入输出流设备的管理及音频流数据的处理传输,这是由回放线程(PlaybackThread 及其派生的子类)和录制线程(RecordThread)进行的,我们简单看看回放线程和录制线程类关系:
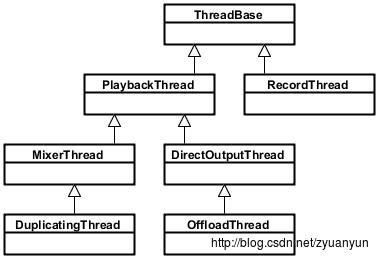
- ThreadBase:PlaybackThread 和 RecordThread 的基类
- RecordThread:录制线程类,由 ThreadBase 派生
- PlaybackThread:回放线程基类,同由 ThreadBase 派生
- MixerThread:混音回放线程类,由 PlaybackThread 派生,负责处理标识为 AUDIO_OUTPUT_FLAG_PRIMARY、AUDIO_OUTPUT_FLAG_FAST、AUDIO_OUTPUT_FLAG_DEEP_BUFFER 的音频流,MixerThread 可以把多个音轨的数据混音后再输出
- DirectOutputThread:直输回放线程类,由 PlaybackThread 派生,负责处理标识为 AUDIO_OUTPUT_FLAG_DIRECT 的音频流,这种音频流数据不需要软件混音,直接输出到音频设备即可
- DuplicatingThread:复制回放线程类,由 MixerThread 派生,负责复制音频流数据到其他输出设备,使用场景如主声卡设备、蓝牙耳机设备、USB 声卡设备同时输出
- OffloadThread:硬解回放线程类,由 DirectOutputThread 派生,负责处理标识为 AUDIO_OUTPUT_FLAG_COMPRESS_OFFLOAD 的音频流,这种音频流未经软件解码的(一般是 MP3、AAC 等格式的数据),需要输出到硬件解码器,由硬件解码器解码成 PCM 数据
PlaybackThread 中有个极为重要的函数 threadLoop(),当 PlaybackThread 被强引用时,threadLoop() 会真正运行起来进入循环主体,处理音频流数据相关事务,threadLoop() 大致流程如下(以 MixerThread 为例):
bool AudioFlinger::PlaybackThread::threadLoop()
{
// ......
while (!exitPending())
{
// ......
{ // scope for mLock
Mutex::Autolock _l(mLock);
processConfigEvents_l();
// ......
if ((!mActiveTracks.size() && systemTime() > mStandbyTimeNs) ||
isSuspended()) {
// put audio hardware into standby after short delay
if (shouldStandby_l()) {
threadLoop_standby();
mStandby = true;
}
// ......
}
// mMixerStatusIgnoringFastTracks is also updated internally
mMixerStatus = prepareTracks_l(&tracksToRemove);
// ......
} // mLock scope ends
// ......
if (mBytesRemaining == 0) {
mCurrentWriteLength = 0;
if (mMixerStatus == MIXER_TRACKS_READY) {
// threadLoop_mix() sets mCurrentWriteLength
threadLoop_mix();
}
// ......
}
// ......
if (!waitingAsyncCallback()) {
// mSleepTimeUs == 0 means we must write to audio hardware
if (mSleepTimeUs == 0) {
// ......
if (mBytesRemaining) {
// FIXME rewrite to reduce number of system calls
ret = threadLoop_write();
lastWriteFinished = systemTime();
delta = lastWriteFinished - mLastWriteTime;
if (ret < 0) {
mBytesRemaining = 0;
} else {
mBytesWritten += ret;
mBytesRemaining -= ret;
mFramesWritten += ret / mFrameSize;
}
}
// ......
}
// ......
}
// Finally let go of removed track(s), without the lock held
// since we can't guarantee the destructors won't acquire that
// same lock. This will also mutate and push a new fast mixer state.
threadLoop_removeTracks(tracksToRemove);
tracksToRemove.clear();
// ......
}
threadLoop_exit();
if (!mStandby) {
threadLoop_standby();
mStandby = true;
}
// ......
return false;
}- threadLoop() 循环的条件是 exitPending() 返回 false,如果想要 PlaybackThread 结束循环,则可以调用 requestExit() 来请求退出;
- processConfigEvents_l() :处理配置事件;当有配置改变的事件发生时,需要调用 sendConfigEvent_l() 来通知 PlaybackThread,这样 PlaybackThread 才能及时处理配置事件;常见的配置事件是切换音频通路;
- 检查此时此刻是否符合 standby 条件,比如当前并没有 ACTIVE 状态的 Track(mActiveTracks.size() = 0),那么调用 threadLoop_standby() 关闭音频硬件设备以节省能耗;
- prepareTracks_l(): 准备音频流和混音器,该函数非常复杂,这里不详细分析了,仅列一下流程要点:
- 遍历 mActiveTracks,逐个处理 mActiveTracks 上的 Track,检查该 Track 是否为 ACTIVE 状态;
- 如果 Track 设置是 ACTIVE 状态,则再检查该 Track 的数据是否准备就绪了;
- 根据音频流的音量值、格式、声道数、音轨的采样率、硬件设备的采样率,配置好混音器参数;
- 如果 Track 的状态是 PAUSED 或 STOPPED,则把该 Track 添加到 tracksToRemove 向量中;
- threadLoop_mix():读取所有置了 ACTIVE 状态的音频流数据,混音器开始处理这些数据;
- threadLoop_write(): 把混音器处理后的数据写到输出流设备;
- threadLoop_removeTracks(): 把 tracksToRemove 上的所有 Track 从 mActiveTracks 中移除出来;这样下一次循环时就不会处理这些 Track 了。
这里说说 PlaybackThread 与输出流设备的关系:PlaybackThread 实例与输出流设备是一一对应的,比方说 OffloadThread 只会将音频数据输出到 compress_offload 设备中,MixerThread(with FastMixer) 只会将音频数据输出到 low_latency 设备中。
从 Audio HAL 中,我们通常看到如下 4 种输出流设备,分别对应着不同的播放场景:
- primary_out:主输出流设备,用于铃声类声音输出,对应着标识为 AUDIO_OUTPUT_FLAG_PRIMARY 的音频流和一个 MixerThread 回放线程实例
- low_latency:低延迟输出流设备,用于按键音、游戏背景音等对时延要求高的声音输出,对应着标识为 AUDIO_OUTPUT_FLAG_FAST 的音频流和一个 MixerThread 回放线程实例
- deep_buffer:音乐音轨输出流设备,用于音乐等对时延要求不高的声音输出,对应着标识为 AUDIO_OUTPUT_FLAG_DEEP_BUFFER 的音频流和一个 MixerThread 回放线程实例
- compress_offload:硬解输出流设备,用于需要硬件解码的数据输出,对应着标识为 AUDIO_OUTPUT_FLAG_COMPRESS_OFFLOAD 的音频流和一个 OffloadThread 回放线程实例
其中 primary_out 设备是必须声明支持的,而且系统启动时就已经打开 primary_out 设备并创建好对应的 MixerThread 实例。其他类型的输出流设备并非必须声明支持的,主要是看硬件上有无这个能力。
可能有人产生这样的疑问:既然 primary_out 设备一直保持打开,那么能耗岂不是很大?这里阐释一个概念:输出流设备属于逻辑设备,并不是硬件设备。所以即使输出流设备一直保持打开,只要硬件设备不工作,那么就不会影响能耗。那么硬件设备什么时候才会打开呢?答案是 PlaybackThread 将音频数据写入到输出流设备时。
下图简单描述 AudioTrack、PlaybackThread、输出流设备三者的对应关系:
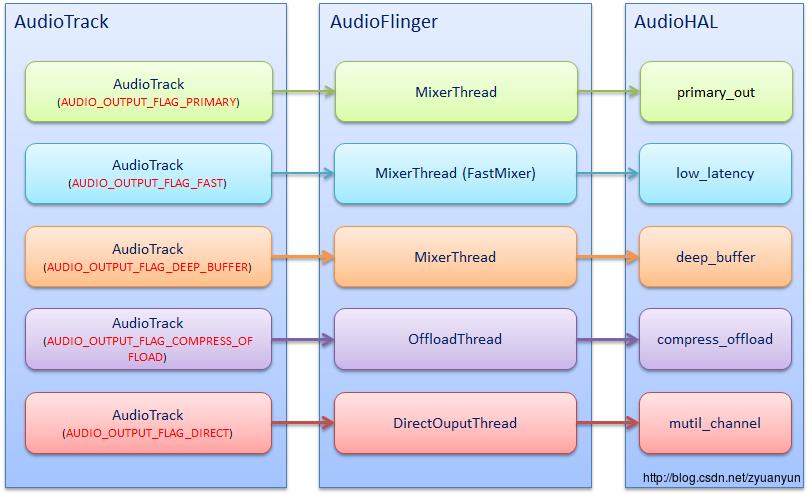
我们可以这么说:输出流设备决定了它对应的 PlaybackThread 是什么类型。怎么理解呢?意思是说:只有支持了该类型的输出流设备,那么该类型的 PlaybackThread 才有可能被创建。举个例子:只有硬件上具备硬件解码器,系统才建立 compress_offload 设备,然后播放 mp3 格式的音乐文件时,才会创建 OffloadThread 把数据输出到 compress_offload 设备上;反之,如果硬件上并不具备硬件解码器,系统则不应该建立 compress_offload 设备,那么播放 mp3 格式的音乐文件时,通过 MixerThread 把数据输出到其他输出流设备上。
那么有无可能出现这种情况:底层并不支持 compress_offload 设备,但偏偏有个标识为 AUDIO_OUTPUT_FLAG_COMPRESS_OFFLOAD 的音频流送到 AudioFlinger 了呢?这是不可能的。系统启动时,会检查并保存输入输出流设备的支持信息;播放器在播放 mp3 文件时,首先看 compress_offload 设备是否支持了,如果支持,那么不进行软件解码,直接把数据标识为 AUDIO_OUTPUT_FLAG_COMPRESS_OFFLOAD;如果不支持,那么先进行软件解码,然后把解码好的数据标识为 AUDIO_OUTPUT_FLAG_DEEP_BUFFER,前提是 deep_buffer 设备是支持了的;如果 deep_buffer 设备也不支持,那么把数据标识为 AUDIO_OUTPUT_FLAG_PRIMARY。
系统启动时,就已经打开 primary_out、low_latency、deep_buffer 这三种输出流设备,并创建对应的 MixerThread 了;而此时 DirectOutputThread 与 OffloadThread 不会被创建,直到标识为 AUDIO_OUTPUT_FLAG_DIRECT/AUDIO_OUTPUT_FLAG_COMPRESS_OFFLOAD 的音频流需要输出时,才开始创建 DirectOutputThread/OffloadThread 和打开 direct_out/compress_offload 设备。这一点请参考如下代码,注释非常清晰:
AudioPolicyManager::AudioPolicyManager(AudioPolicyClientInterface *clientInterface)
// ......
{
// ......
// mAvailableOutputDevices and mAvailableInputDevices now contain all attached devices
// open all output streams needed to access attached devices
// ......
for (size_t i = 0; i < mHwModules.size(); i++) {
// ......
// open all output streams needed to access attached devices
// except for direct output streams that are only opened when they are actually
// required by an app.
// This also validates mAvailableOutputDevices list
for (size_t j = 0; j < mHwModules[i]->mOutputProfiles.size(); j++)
{
// ......
if ((outProfile->getFlags() & AUDIO_OUTPUT_FLAG_DIREC以上是关于Android 音频系统:从 AudioTrack 到 AudioFlinger的主要内容,如果未能解决你的问题,请参考以下文章