IO模型之完全懵逼到似懂非懂
Posted ShuSheng007
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了IO模型之完全懵逼到似懂非懂相关的知识,希望对你有一定的参考价值。
[版权申明] 非商业目的注明出处可自由转载
出自:shusheng007
文章目录
概述
I/O是Input/Output的缩写,意为输入输出,是计算机系统中非常非常非常重要的内容,毕竟没有输入输出你要它干毛?同时也很复杂啊,今天咱也就是从宏观上概述一下,当扫盲了。
要理解IO首先需要理解下面这些概念
假设我们有一个服务端程序,有一堆客户端程序,一堆客户端程序要与服务端程序交换数据,我们就以查询为例
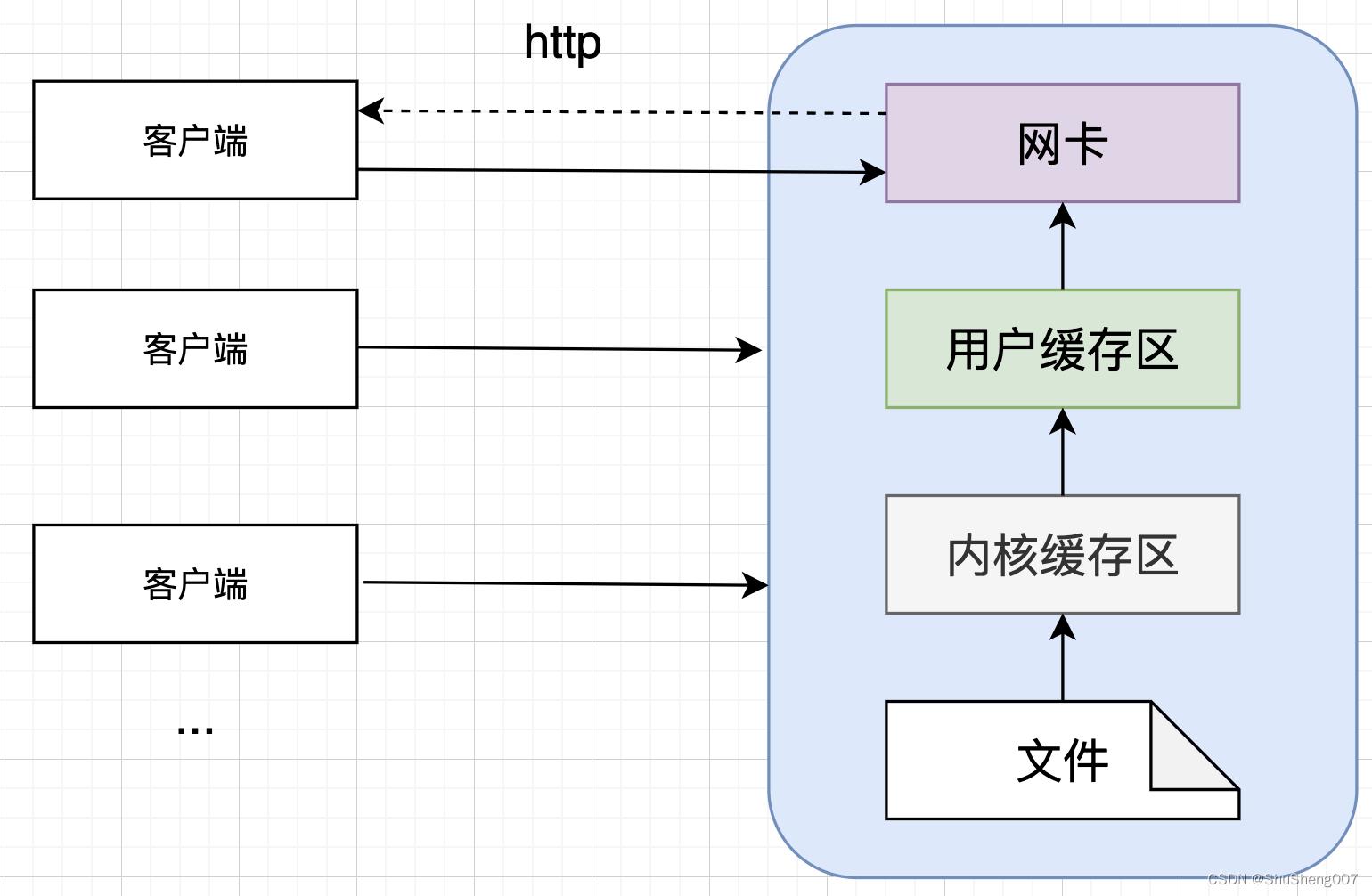
假设客户端就是要读取服务器上的某个文件的内容,那么你了解这个数据的流转情况吗?
首先操作系统被分为用户空间和内核空间,有些操作只能内核空间来做,例如我们这里要说的文件管理。你的应用程序是运行在用户空间的,你想要读取文件必须让操作系统帮你,你自己是没有权限的,这就是所谓的发起系统调用,而这个过程是很耗时的。
就像上面的图那样,当客户端向服务端发起查询请求时,服务端发起一次系统调用,让操作系统将硬盘中的文件读取到内核缓存区中,然后再拷贝到用户缓存区中,然后应用就拿到数据了。
那个IO模型描述的问题其实特别的窄:就是描述应用程序以何种方式向硬盘或者网卡读取数据(Input)及写入数据(output)的过程。你心中是不是充满了不解和疑惑?就这么屁大点事,为什么整的这么高深莫测。其实一开始很简单,后来实际应用中对效率的要求越来越高,所以就越整越复杂。
下面我就以我二把刀的IO知识,让大家从懵逼中解放出来…let’s go
IO演进
发展到现在I/O模型大概分为5类,你说为什么会有这么多模型呢?这是因为在不断的解决实际问题中演化出来的,也是一个长江后浪推前浪,前浪被拍死在沙滩上的过程…
下面这个图描述了应用读取文件的流程。应用从用户态调用操作系统的read方法发起系统调用,操作系统从硬盘中读取文件到内核缓存区中,然后将内核缓存区的数据再拷贝到用户缓存区中,应用程序就拿到数据了。
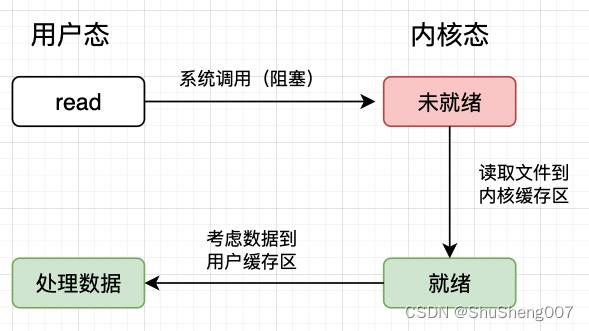
同步阻塞IO
这个是最初的解决方案。
服务端开一个线程,监听客户端的socket连接。然后客户端A与服务端连接上了,服务端就调用操作系统的read方法发起系统调用,让操作系统帮它去读取数据(从文件或者网络),此过程是一个阻塞的过程,只有客户端A顺利获得了数据返回了,其他客户端才能继续连接服务端。
这要是数据迟迟读取不到,监听客户端连接这条线程不就一直阻塞下去了吗?这还玩个蛋蛋,于是有了同步非阻塞IO
同步非阻塞IO
看到这个词不知道你们有没有疑问,我刚看到这个词的时候感到很疑惑。 同步怎还能非阻塞呢?同步是指谁是同步的?非阻塞是谁非阻塞了?日,完全不懂
其实这里说的同步以及是否阻塞都是针对发起系统调用那个read方法,此方法是操作系统提供的。 最开始的时候操作系统提供的这个read方法是同步阻塞的。也就是说,调用这个方法,只能等着它返回数据。
我们可以在应用层玩个小把戏,让服务端可以响应多个客户端的请求。 那就是用一个线程监听客户端的socket连接,每当建立一个连接后就启动一个新线程去调用read方法去读取数据,那样我们的服务端就可以同时处理多个客户端的请求了。但是这种方式可以支持的客户端并发量很低,因为你不可能同时开辟大量的线程,而且新建的每条线程读取数据的方式仍然是同步阻塞的。
那这个叫同步非阻塞IO吗?严格来说不算,因为那个操作系统的read方法仍然是同步阻塞的。那怎么办呢?那还能怎么办,只能联系下面这位大神了:

hi,哥们儿,现在的网民太残暴了,随便一个九流戏子嫖娼瞬间就能涌入1亿人围观,并发扛不住啊,你写那个linux内核的read方法能不能给改成非阻塞的啊…
于是,Linux操作系统的read函数就改成非阻塞的了。当应用调用read方法发起系统调用后,如果操作系统发现数据还没有读取到内核缓存区中,它立即就返回-1,否则返回对应的文件描述符。
那样我们新建的线程就可以不断的轮询read方法了,直到结果不为-1,期间这些线程都是非阻塞的,即所谓的同步非阻塞了。
多路复用IO
当我第一次看到这个名词时,整个人是懵逼的,多路复用?啥玩意?
要理解多路复用首先要理解啥是单路,啥是复用,那单路不复用的时候是啥样的?
单路是啥,还记得上面讲同步非阻塞的时候我们开了多个线程去并发读取数据吗?一个读取行为就可以认为是一路,开了5个线程,发起5个读取数据的行为,那么就是发起了5路IO。那现在5路就需要5个线程,那10000用户并发,我们能开10000个线程吗?这显然是不靠谱的,于是我们就想,能不能使用一个线程同时处理多路IO,于是多路IO就复用了那个线程,于是就叫多路复用IO了。
我们又可以在应用层玩个小把戏,我们在接到客户端连接后不是去为每个连接开一个读取线程,而是将连接(文件描述符)放到一个数组中,然后开一个新线程不断的迭代这个数组,调用操作系统read方法发起系统调用,从而获取数据
伪代码如下
while(true)
array = [df1,df2,df3];
for(df:array)
if(read(df) != -1)
//获取到了数据
//这些处理过的连接可以从array中移除
那这个是多路复用吗?差不多了。但不是我们通常说的多路复用,真正的多路复用还是要靠操作系统的支持,你看不从根本上改变就没有根本的提升。
上面的方法有什么问题呢?问题还是出现在那个调用read方法的操作,我们迭代时每次调用read都是一次系统调用,这是特别耗时的。那怎么改进呢?既然是由于产生了多次系统调用,那么我们能不能减少呢?靠你我肯定是不行了,于是你又想到了那位总骂人的Linux大神:
hi,哥们儿,你能不能给提供一个方法,我们把一批文件描述符传给你,你在内核空间给遍历查询一下,然后告诉我们他们的状态啊啊?
于是就有了select
select 是操作系统提供的系统调用函数,通过它,我们可以把一个文件描述符的数组发给操作系统, 让操作系统在内核空间中遍历,确定哪个文件描述符可以读写, 然后告诉我们去处理。
应用程序调用select时传递一个文件描述符的数组,返回结果也是这个数组,只是其中的文件描述符被操作系统标记了,然后应用程序遍历这个数组,就知道哪些文件已经被读取到内核缓存区了,然后应用程序通过read方法去读取就好了。
至此感觉已经很完美了,但是其中还有几个点可以改进。
- select 调用需要传入 fd 数组,需要拷贝一份到内核,高并发场景下这样的拷贝消耗的资源是惊人的。(可优化为不复制)
- select 在内核层仍然是通过遍历的方式检查文件描述符的就绪状态,是个同步过程,只不过无系统调用切换上下文的开销。(内核层可优化为异步事件通知)
- select 仅仅返回可读文件描述符的个数,具体哪个可读还是要用户自己遍历。(可优化为只返回给用户就绪的文件描述符,无需用户做无效的遍历)
于是就有了 poll和epoll
poll 可以看成是select的增强版,解决了select只能处理1024个文件描述符的限制,其他都一样,没有解决上面说到的那3条。
select 使用固定长度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的个数是有限制的,在 Linux 系统中,由内核中的 FD_SETSIZE 限制, 默认最大值为 1024,只能监听 0~1023 的文件描述符。poll 不再用 BitsMap 来存储所关注的文件描述符,取而代之用动态数组,以链表形式来组织,突破了 select 的文件描述符个数限制,当然还会受到系统文件描述符限制。
epoll 是目前最新的解决方案,就是为了解决select/poll的存在的问题的。
使用epoll共三步:
- 第一步,创建一个 epoll 句柄
i nt epoll_create(int size);
- 第二步,向内核添加、修改或删除要监控的文件描述符。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
- 第三步,发起epoll_wait调用
int epoll_wait( int epfd, struct epoll_event *events, int max events, int timeout);
值得注意的是,我的理解是当epooll_wait获取到结果后,应用程序还是要调用read方法去读取数据的,epooll_wait只是告诉你这些文件准备好了,你去读吧
下面的图,引用至你管这破玩意叫 IO 多路复用?这篇好文

信号驱动IO
不懂
异步IO
总结
IO是比较基础的知识,平台搬砖的时候基本用不上,大部分时候已经被相关框架给深度屏蔽了…不过现在都是卷这些问题,应用层的显得太low了…无奈啊
参考文章:
你管这破玩意叫 IO 多路复用?,那个图解特别棒 。
IO 多路复用是什么意思?
以上是关于IO模型之完全懵逼到似懂非懂的主要内容,如果未能解决你的问题,请参考以下文章