秒级的 npm 安装速度是怎么做到的?
Posted SHERlocked93
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了秒级的 npm 安装速度是怎么做到的?相关的知识,希望对你有一定的参考价值。
cnpm rapid 将正式开源了。接下来我将深入介绍 cnpm rapid 模式的实现原理,以及如何通过集成 cnpm rapid 模式带来的 npmfs 来加速 npm 依赖安装。
目录
本次分享分为三部分,分别是 “cnpm rapid 模式剖析”、“企业如何集成 rapid 模式加速 CI/CD”、“如何参与 cnpm rapid 开源贡献”。

cnpm rapid 模式剖析
首先,先来看下 cnpm rapid 模式对比其他 npm 安装器的性能。

我们使用以下基准测试环境来进行测试。

测试的结果如下,对比性能最慢的 npm,我们的安装速度提升了 10 倍,即使对比最快的 pnpm 和 常规模式的 cnpm,我们也能有 3 倍的安装速度提升。

理解我们如何做性能优化,可以从问题入手。我们来看下 npm 有哪些性能瓶颈。
我们知道一次依赖安装主要分为下面几个步骤:
依赖树生成;
依赖包下载;
依赖包解压缩到 node_modules 目录;
其他脚本执行,文件权限变更等操作。

我们分别来看下前面最核心的三个流程,有哪些性能瓶颈。还是以基准测试举例,安装一个内网 @alipay/smallfish 包:
在生成依赖树的过程中,我们需要 2211 次 registry 请求,获取所有依赖的版本信息;
紧接着,我们根据生成的依赖树去下载 2211 个依赖安装包;
下载完依赖包之后,我们需要将依赖包解压到项目 node_modules 目录。

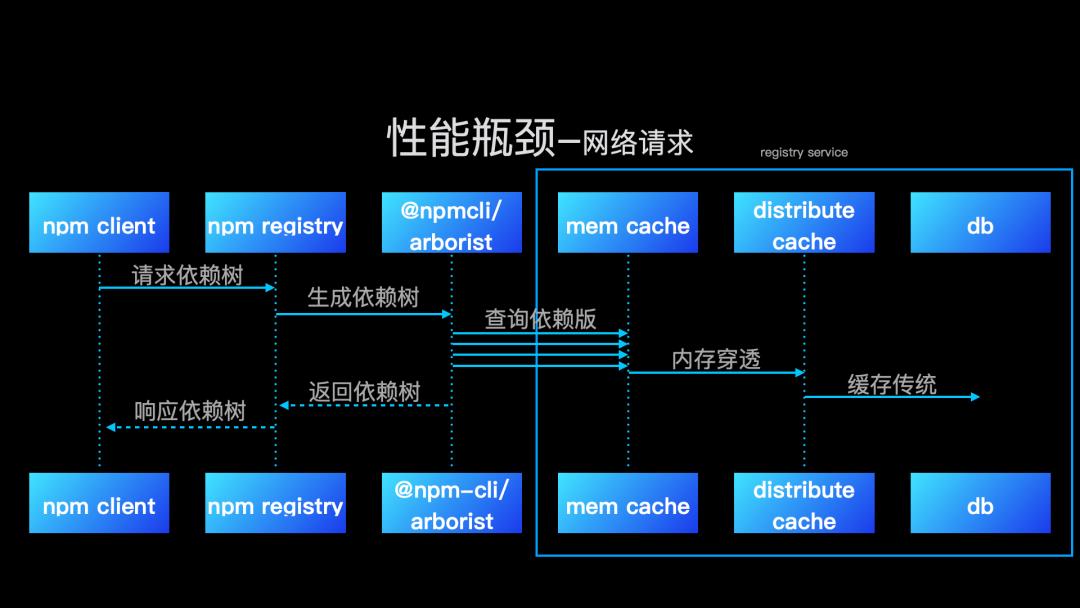
首先看,我们如何优化网络请求。npm 生成依赖树是通过递归请求 registry 信息。

我们内部提供了服务端生成依赖树服务,服务里面通过内存缓存,分布式缓存,将内部常用的依赖元信息进行缓存,省去了传统客户端生成依赖树时,都需要去 DB 查询的性能损失。这样对比客户端依赖树生成,服务端依赖树生成只需要一次 http 请求,服务端通过两级缓存大幅度提高了依赖树生成的速度。
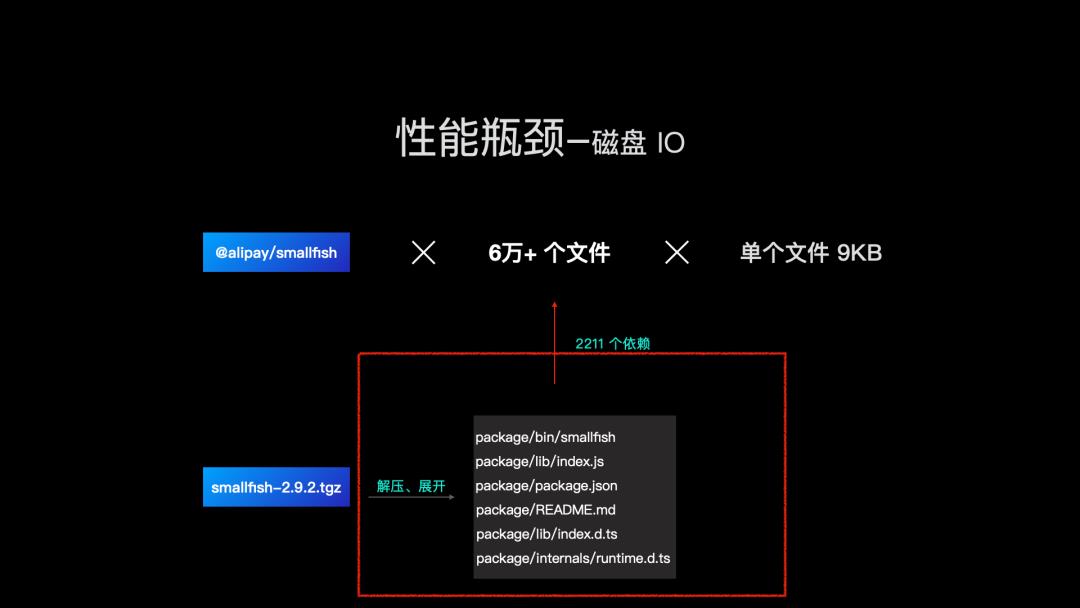
再来看,我们如何优化磁盘 IO。一个 npm 包从下载到写入磁盘是以下流程。以@alipay/smallfish 为例,会解压缩 smallfish.tgz 包,展开 6 个文本文件,将文件写入 node_modules。这个过程还包含目录的创建。

那么,我们来看写入流程。当我们将依赖包从 OSS 下载并写到磁盘时,会使用 Node.js 的 API fs.writeFile,而 fs.writeFile 是 write syscall 的 Node.js 封装。我们每次调用 fs.writeFile 对应底层一次或多次的 write syscall,这个次数取决于文件大小和单次 write syscall 写入数据量。如果单次 write syscall 写入量没有写满,就会浪费一次系统调用,尤其在小文件写入时。

于是同样写入 100MB 的一个大文件,和写入 102400 个 1KB 的小文件,后者性能会变得非常差。

我们知道 npm 包分发是通过 tar.gz 文件格式将多个文件归档成一个文件进行的,而经过统计,npm 包大小中位数在 16KB。解压缩后会膨胀出数量众多的小文件。于是大量写入小文件,IO 性能就会急剧下降。

既然写入一个大文件的速度比写入同等大小的多个小文件的速度快,结合 npm 包是通过 tar.gz 文件格式进行分发。那么,我们是不是可以直接把 npm 包的 tar.gz 文件写入磁盘这样我们的写入性能是不是就快很多。那么问题就变成,不解压展开文件。
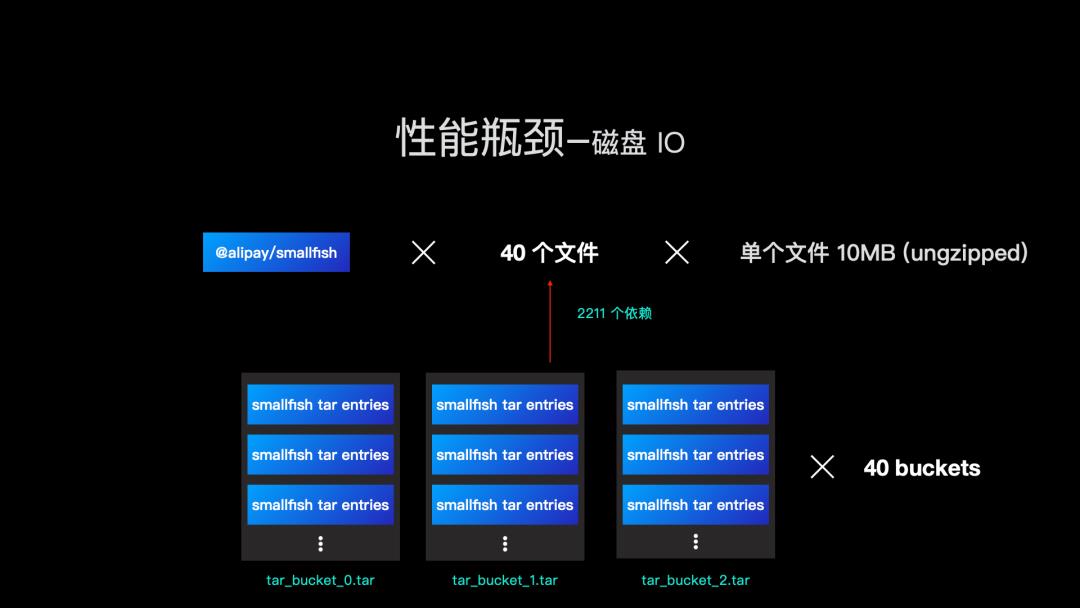
还是以 @alipay/smallfish 为例,我们的优化磁盘 IO 的手段就变成直接将 2211 个 tar.gz 包写入磁盘。当然实际操作中,我们会将 tar.gz 包解压缩成 tar 进行存储,因为我们需要读取 tar.gz 里面的 entry 进而获取真正的 npm 包产物。

进一步,我们知道 tar 是可以无限在文件末尾增加新的 entry。

既然我们已经有 2211 个 tar 包,那是不是可以在写入磁盘的时候,把 2211 个 tar 包拼接成 1 个 tar 包,这样就只需要处理 1 个 tar 包的写入,IO 性能进一步大幅提升。理论如此,但是实际上,我们的写入流是伴随着下载流同步进行的,前面提到单个 npm tgz 的中位数是 16KB,写成一个 tar 包当然会大幅提高 IO 性能,但是我们的网络带宽就没办法占满,经过测试,我们选择了 40 个线程做并发的下载和写入,这样我们就需要 40 个 tar 包来存储所有的依赖。
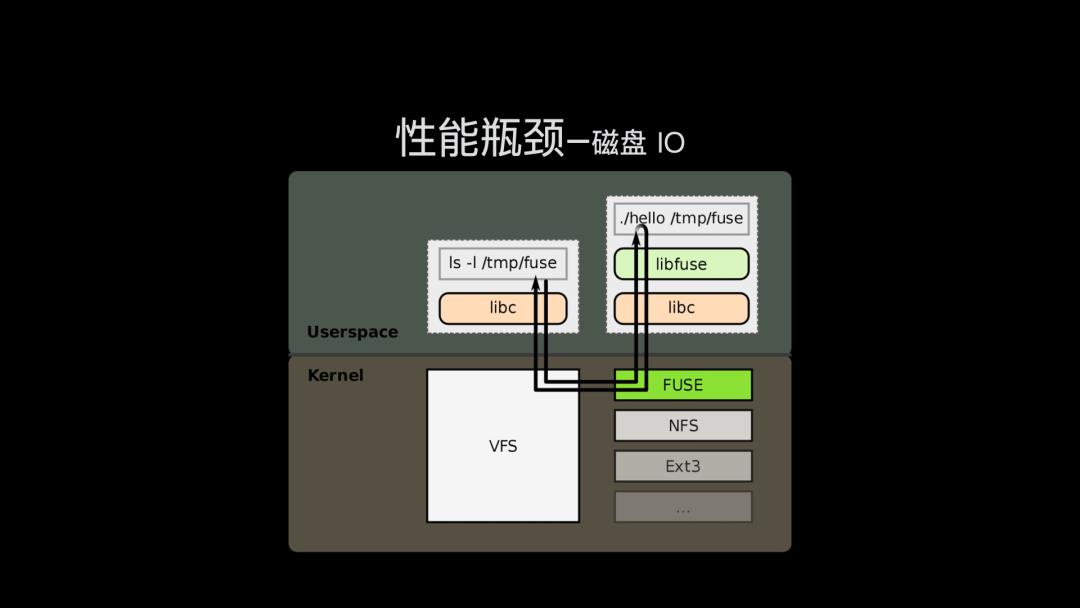
现在问题来到我们有 40 个 tar 包,里面包含所有 smallfish 项目的依赖文件。但是 tar 不展开,我们是没办法构建标准的 node_modules 文件目录的,项目也就跑不起来。

本质上,无论 tar 还是 node_modules 都是通过文件系统来管理的,上层 Node.js 读写文件,也是通过调用标准的文件系统 API 来实现的,例如前面提到的 write syscall,那么我们是否可以构建一个不一样的文件系统,底层读 tar,上层构造出 node_modules。事实上这是另外一个非常通用的文件系统技术,FUSE,也即用户态文件系统。区别于普通的文件系统,FUSE 需要上层的 hello 程序来托管 /tmp/fuse 挂载点,通过 libfuse 库跟 libc 来交互,libc 再调用内核 FUSE 实现,来进行文件的读写。
我们需要一个能通过 FUSE 构造用户态文件系统的项目即上图中的 hello 程序,这里我们采用了蚂蚁集团和阿里云共同开源的项目 Nydus,这个项目主要是给云原生时代,镜像加速做文件系统使用,但对我们来说,只要能构造文件系统就足够。

于是,我们的项目架构就变成底层是 tar buckets 来托管原始的 npm 包文件,通过 nydus 构造出文件系统来保证 node_modules 是原生的文件系统,具备完整的文件系统操作。

但是这里还有一个问题,我们现在只通过 nydus 给用户提供了一个 node_modules 文件目录。那用户如果需要 debug,修改 node_modules 中的文件,或者依赖安装时,会进行 preinstall/install/postinstall 等操作,显然作为全局的 tar buckets,我们既不能随意改动里面的文件数据,否则另外一个项目就可能拿到的不是预期内的文件,同时 tar 的成本会很高,改一个 entry,就意味着 nydus 构造出来的文件系统需要重新构建,因为读取数据的元信息变了。这就意味着 nydus 构造的文件系统一定是只读的。那么我们怎么实现写呢?

这就要引入另外一个技术,overlay。这个技术是可以将两个文件系统合并成一个文件系统。如下图,overlay 分为三层目录:lower、upper 和 merged。三者的合并逻辑是,在 upper dir 进行的,针对 lower dir 同名文件的操作,都会被覆盖掉,最终体现在 merged dir。举个例子:
File1 在 lower 和 upper dir 都存在,那么最终 merged dir 里面的 File1 会是 upper dir 的文件;
File2 在 upper dir 被删除,即使 lower dir 仍存在着个文件,最终 merged dir File2 也会被删除;
如果 upper dir 没有 File3 或者 lower dir 没有 File4,那么 merged dir 会直接使用这个文件。

从上面这个例子可以得到一个启发:既然 nydus 构造的文件系统是只读的,那么我们只要再构造一个可写的文件系统,然后通过 overlay 合并,我们就能得到一个可读可写的 node_modules 目录。这里为了简单我们可以直接使用 tmpfs 构造一个 upper dir,nydus 基于 tar buckets 构造的目录为 lower dir。这样我们就完美的构造出了一个可读可写的 node_modules 目录。

回过头,我们来看下社区现有安装器存在的一些体验问题。
npm 慢;
cnpm 解决了速度问题,但是增加的软链部分破坏了社区生态;
yarn 在上层代理了模块查找,更是大幅度的破坏了社区生态,需要对社区内的项目,尤其是构建框架进行定制才行;
pnpm 则是目前来讲,更加成功的项目,但是通过硬链全局缓存,导致模块修改影响全局项目,体验并不好。

而 cnpm rapid,通过潜到更底层的文件系统,在下载速度更快的同时,将上层的不兼容文件一一规避,带来默认良好的社区兼容性。

集成 rapid 模式加速 CI/CD
那么如何通过集成 cnpm rapid 模式来加速我们的 CI/CD 服务呢,下面第二部分,我将给大家分享下,怎么在 CI/CD 流中集成 cnpm rapid 模式。

回过头,我们看 cnpm rapid 模式的安装流程就核心的三部分:
服务端生成依赖树;
客户端基于依赖树去高速下载包,并合并成 tar 写到磁盘;
然后基于 nydus 和 overlay 我们构造了一个可读可写的文件系统。
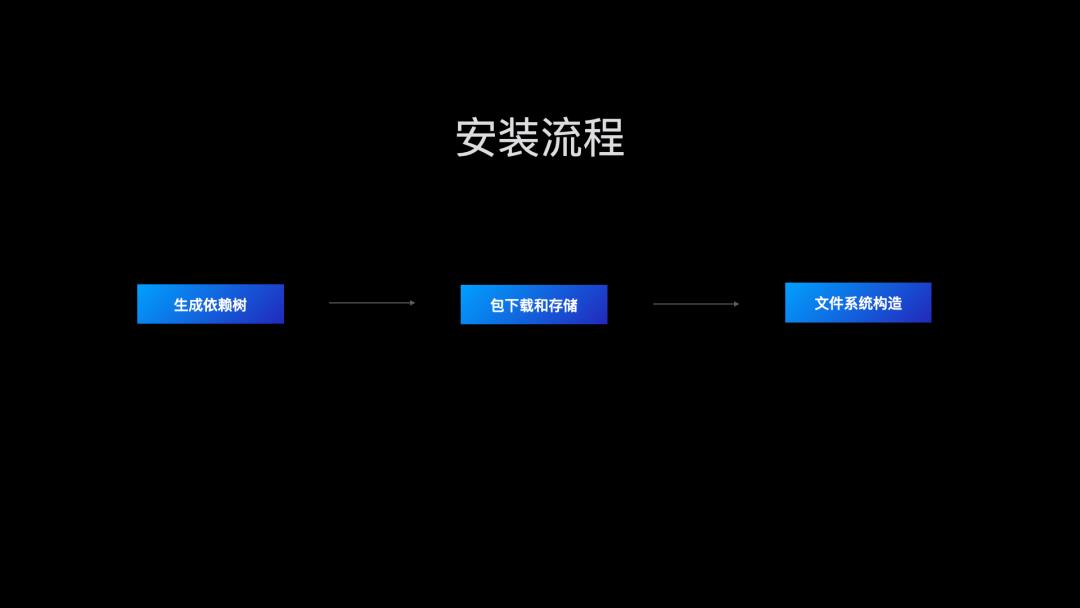
那么我们的改造流程也涉及这几部分,依赖树生成,高性能的下载器,镜像改造。
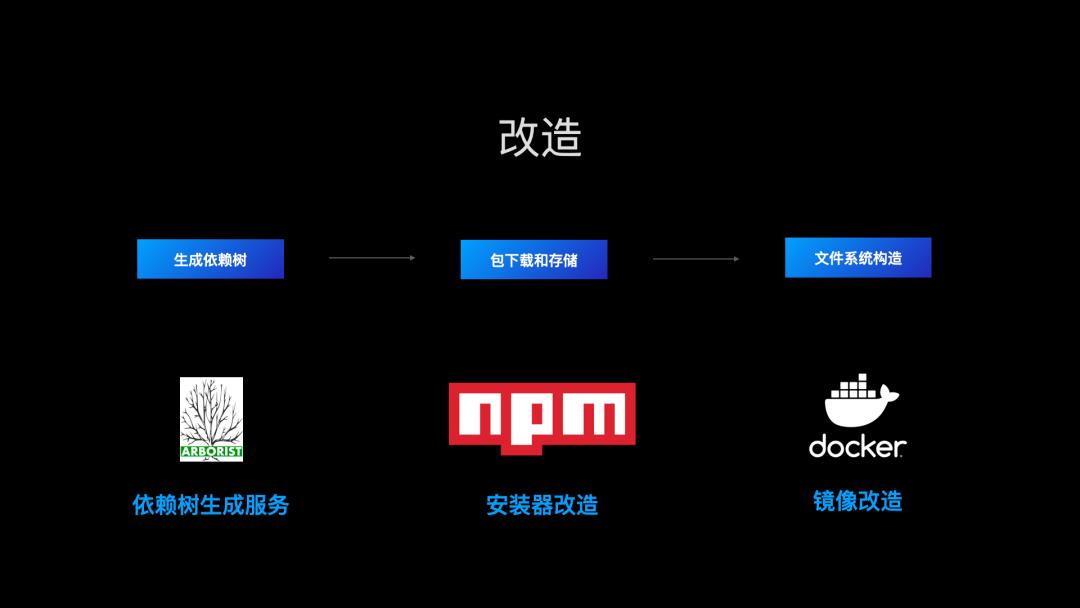
首先看依赖树生成服务,我们知道 npm 是通过 @npmcli/arborist 来生成依赖树的,那么为了得到同样的依赖树,我们也可以使用这个包来进行依赖树生成。区别是,我们将依赖树生成服务放到服务端,通过内存缓存和分布式缓存来提高依赖元数据的缓存命中率,进而提高依赖树的生成速度。

再来看安装器改造,简单做可以直接集成 npminstall,这里包含完整的依赖安装流程。

如果你有内部定制的安装器,可以集成 npmfs。我们看 npminstall 是如何集成 npmfs 的。一个 rapid 模式的安装过程如下:
首先将 packge.json 发到服务端,生成依赖树;
然后调用经过写入优化的下载器,将依赖下载并写入磁盘;
然后调用 nydus 和 overlay 来构造 node_modules。
但是注意,我们在构造 node_modules时,还应该执行 npm 标准里面的 preinstall/install/postinstall 脚本。
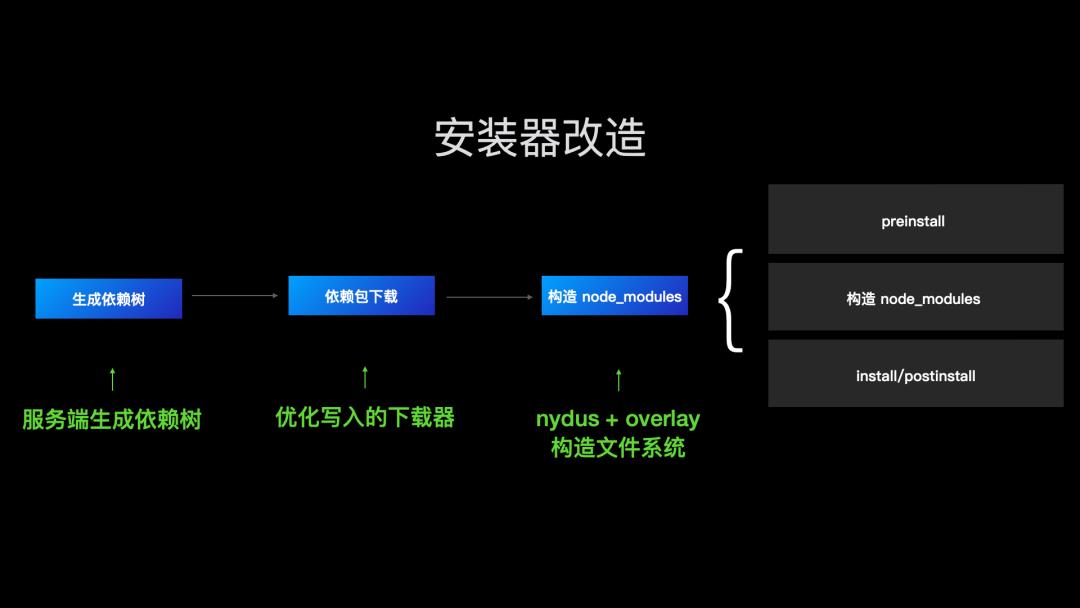
那么结合 node_modules 的构造过程,我们知道 lower dir 是只读,upper dir 是可写。按照 npm install 脚本的定义,overlay 构造 node_modules 之前,我们就应该执行 preinstall,node_modules 构造之后,我们按照顺序执行 install 和 postinstall 即可。但是 overlay 的 merged dir 实际上是一个挂载点,挂载的时候,会直接改变这个文件的类型,那么如果简单的将 preinstall 的结果写到 node_modules,在构造 node_modules 的时候,这些文件就会被删除掉。所以我们执行 preinstall 就需要在 upper dir 进行。
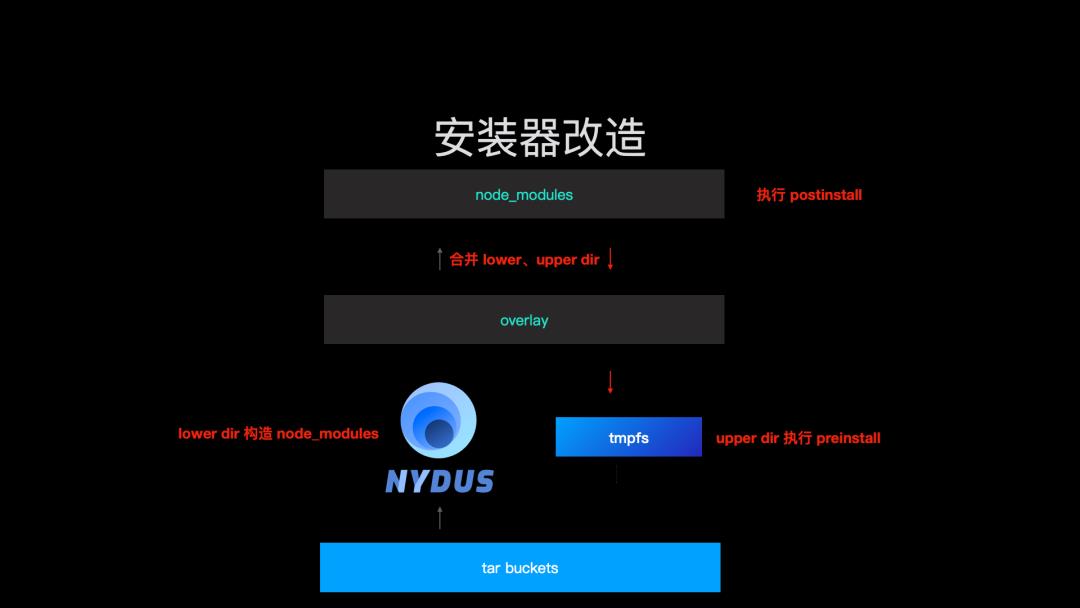
这样,我们得到的 node_modules 目录文件的逻辑就变成

具体的代码实现如下

再看镜像改造,我们构造 node_modules 使用了 Linux 的 FUSE 和 overlay 技术,好在现在主流的 Linux 发行版都集成了两种技术。我们唯一要做的就是在 docker 容器中开启 fuse 设备。

这样我们就获得了如下的 CI/CD 流

如何参与 cnpm rapid 开源贡献
讲完 ci/cd 流程如何集成 cnpm rapid,我们其实有一点没有提到,就是个人开发者怎么使用 cnpm rapid。这里因为 macOS 跟 Linux 的差异,以及 ci/cd 和本地研发的习惯差异,个人开发者使用 cnpm rapid 模式还有一些体验问题。那么我们希望社区可以一块参与共建,让 cnpm rapid 成为性能最高,体验最好的 npm 依赖安装器。
那么,假如我们参与共建,肯定是需要了解下项目结构的。因为项目中用到了不少底层的技术,像 FUSE 和 overlay,我们的技术栈也分为 Node.js 和 rust。

项目地址如下,欢迎参与开源贡献 👏🏾 👏🏾 👏🏾
cnpm:
https://github.com/cnpm/cnpm
npminstall:
https://github.com/cnpm/npminstall
未来计划
对于 cnpm rapid 模式,我们的未来计划主要分为以下三块。

macOS 体验主要是在进程保活,上层文件系统的稳定以及保持常规的研发体验一致。

讲到这里,不知道大家有没有一个感受,那就是 npm 社区确实很繁荣,毕竟现在开源已经有四款 npm 依赖安装器。但同时这也意味着分裂,标准的不统一,我们有不同的依赖树锁文件,有不同的安装前置后置行为,甚至有不同的稳定性治理方案。

针对安装器不同,Node.js 官方推出了 corepack,里面包含了 npm、pnpm、yarn。

回过头,我们来看 JS 的标准组织,tc39 给我们带来了 ECMAScript 标准。这样浏览器厂商不至于各自为战,不会靠着市场份额,加塞私货,破坏 Web 生态的兼容性。

我们认为包管理到了需要类似 tc39 的组织和类似 ECMA-262 标准的时机了。

假如我们能把包管理这部分,通过类似 tc39 的组织一样进行标准化,我们会在标准,用户体验和社区生态上更进一步。
统一的标准
一致的用户体验
安全的社区生

cnpm:
https://github.com/cnpm/cnpm
npminstall:
https://github.com/cnpm/npminstall
最后
如果你觉得这篇内容对你挺有启发,我想邀请你帮我个小忙:
点个「喜欢」或「在看」,让更多的人也能看到这篇内容
我组建了个氛围非常好的前端群,里面有很多前端小伙伴,欢迎加我微信「sherlocked_93」拉你加群,一起交流和学习
关注公众号「前端下午茶」,持续为你推送精选好文,也可以加我为好友,随时聊骚。


点个喜欢支持我吧,在看就更好了
以上是关于秒级的 npm 安装速度是怎么做到的?的主要内容,如果未能解决你的问题,请参考以下文章