LSTM Fully Convolutional Networks for Time Series Classification 学习记录
Posted 彭祥.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LSTM Fully Convolutional Networks for Time Series Classification 学习记录相关的知识,希望对你有一定的参考价值。
LSTM Fully Convolutional Networks for Time Series Classification
用于时间序列分类的LSTM+FCN网络(Long short-term Memory+Fully Convolutional Networks)
INTRODUCTION
A plethora of research have been done using feature-based approaches
or methods to extract a set of features that represent time series
patterns.Bag-of-Words (BoW) , Bag-of-features (TSBF) , Bag-of-SFA-Symbols (BOSS) , BOSSVS ,Word ExtrAction for time Series cLassification (WEASEL), have obtained promising results in the field. Bag-of-words
quantizes the extracted features and feeds the BoW into a classifier. TSBF extracts multiple subsequences of random local information, which a supervised learner condenses into a cookbook used to predict time series labels. BOSS introduces a combination of a distance based classifier and histograms.The histograms represent substructures of a time series that
are created using a symbolic Fourier approximation. BOSSVS extends this method by proposing a vector space model to reduce time complexity while maintaining performance.WEASEL converts time series into feature vectors using a sliding window. Machine learning algorithms utilize these feature vectors to detect and classify the time series. All these classifiers require heavy feature extraction and feature engineering.
许多研究使用基于特征的方式去提取一组代表时间序列参数的特征。
Bag-of-words量化提取的特征,并将 BoW 馈送到分类器中。
TSBF 提取随机的多个子序列本地信息,受监督的学习者将其浓缩为
用于预测时间序列标签的说明书。
BOSS引入了基于距离的分类器和直方图的组合。
直方图表示时间序列的子结构,这些子结构使用标准傅里叶近似创建。
BOSSVS通过提出一种向量空间模型来扩展这种方法,以降低时间复杂性,同时保持性能。
WEASEL使用滑动窗口将时间序列转换为特征向量。机器学习算法利用这些特征向量来检测和分类时间序列。所有这些分类器都需要大量的特征提取和特征工程。
Ensemble algorithms also yield state-of-the-art performance with time
series classification problems. Three of the most successful ensemble
algorithms that integrate various features of a time series are
Elastic Ensemble (PROP) , a model that integrates 11 time series
classifiers using a weighted ensemble method, Shapelet ensemble (SE)
[8], a model that applies a heterogeneous ensemble onto transformed
shapelets, and a flat collective of transform based ensembles (COTE)
[8], a model that fuses 35 various classifiers into a single
classifier.
集成算法也可提供最先进的性能去处理时间序列分类问题。
其中三个最成功的集成算法使用了大量的时间序列特征。
PROP,一个使用加权集成算法的融合了11个时间序列分类器的模型。
SE,一个使用各种各样的集成去转换形状的模型。
This paper proposes two deep learning models for end to-end time
series classification. The proposed models do not require heavy
preprocessing on the data or feature engineering. Both the models are
tested on all 85 UCR time series benchmarks and outperform most of the
state-of-the-art models. The remainder of the paper is organized as
follows.Section II reviews the background work. Section III presents
the architecture of the proposed models. Section IV analyzes and
discusses the experiments performed. Finally, conclusions are drawn in
Section V.
本文提出了两个用于端到端时间序列分类模型。提出的模型不需要不需要对数据或特征工程进行繁重的预处理。两种模型都使用 85 个 UCR 时间序列基准测试,性能优于大多数 UCR 时间序列基准测试最先进的模型。论文的剩余部分将在第二章介绍背景工作,第三章介绍模型结构,第四章分析与讨论进行的实验,最后,将在第五章进行总结。
NETWORK ARCHITECTURE(网络结构)

def generate_lstmfcn(MAX_SEQUENCE_LENGTH, NB_CLASS, NUM_CELLS=8):
ip = Input(shape=(1, MAX_SEQUENCE_LENGTH))
x = LSTM(NUM_CELLS)(ip)
#以一定概率丢弃一训练的参数,防止其过拟合
x = Dropout(0.8)(x)#缀学层
#Permute可以同时多次交换tensor的维度
y = Permute((2, 1))(ip)
y = Conv1D(128, 8, padding='same', kernel_initializer='he_uniform')(y)#一维卷积层
#批归一化 让我们的均值方差变化没有那么猛烈
y = BatchNormalization()(y)
y = Activation('relu')(y)#激活函数
y = Conv1D(256, 5, padding='same', kernel_initializer='he_uniform')(y)
y = BatchNormalization()(y)
y = Activation('relu')(y)
y = Conv1D(128, 3, padding='same', kernel_initializer='he_uniform')(y)
y = BatchNormalization()(y)
y = Activation('relu')(y)
y = GlobalAveragePooling1D()(y)#池化
x = concatenate([x, y])#全局池层和LSTM块的输出被串联并传递到softmax分类层
out = Dense(NB_CLASS, activation='softmax')(x)
model = Model(ip, out)
model.summary()
# add load model code here to fine-tune
return model

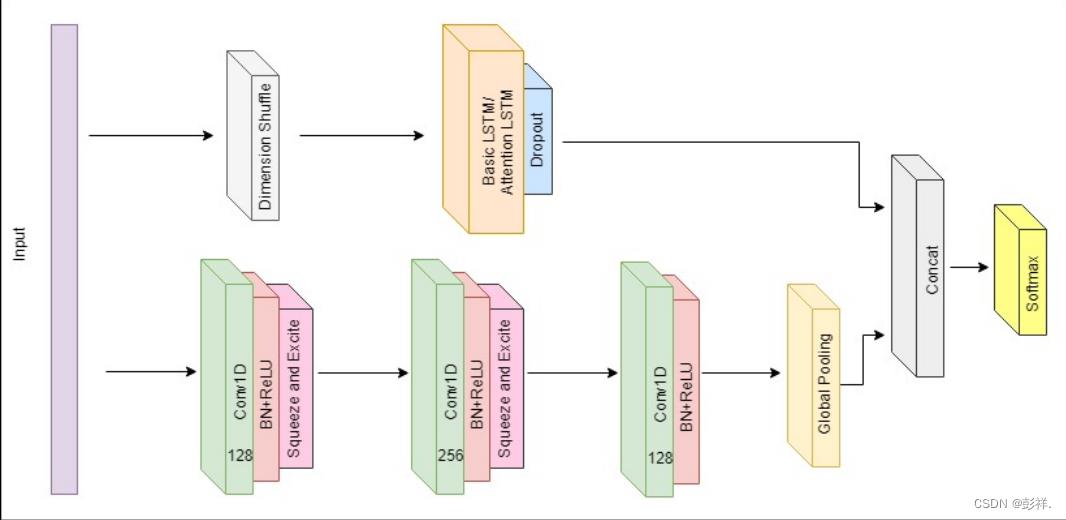
由时间卷积组成的全卷积网络通常用作特征提取器。全局平均池化用于在分类之前减少模型中的参数数量。在所提出的模型中,全卷积块由LSTM块加dropou组成。
The fully convolutional block consists of three stacked temporal convolutional blocks with filter sizes of 128, 256, and 128 respectively. Each convolutional block is identical to the convolution block in the CNN architecture proposed by Wang et al… Each block consists of a temporal convolutional layer, which is accompanied by batch normalization (momentum of 0.99, epsilon of 0.001) and followed by a ReLU activation function. Finally, global average pooling is applied after the final convolution block.
全卷积块由三个堆叠的时间卷积块组成,它们的滤波器大小分别为128、256和128。每个卷积块与Wang等人提出的CNN架构中的卷积块相同。每个块由一个时间卷积层组成,使用批量归一化(动量为0.99,ε为0.001),然后是ReLU激活函数。最后,在最后的卷积块之后应用全局平均池化。
Simultaneously, the time series input is conveyed into a dimension shuffle layer (explained more in Section III-B). The transformed time series from the dimension shuffle is then passed into the LSTM block. The LSTM block, comprising of either a general LSTM layer or an Attention LSTM layer, is followed by a dropout. The output of the global poolinglayerandtheLSTMblockisconcatenatedandpassed onto a softmax classification layer.
同时,时间序列输入被传送到维度混洗层(dimension shuffle layer)(在第III-B节中有更多说明)。然后将来自维度混洗的变换后的时间序列传递到LSTM块中。由常规LSTM层或Attention LSTM层组成的LSTM块后面是一个辍学部分。全局池层和LSTM块的输出被串联并传递到softmax分类层。
NETWORK INPUT(网络输入)
解释维度混洗的作用,主要用于加快计算速度
The fully convolutional block and LSTM block perceive the same time series input in two different views. The fully convolutional block views the time series as a univariate time series with multiple time steps. If there is a time series of length N, the fully convolutional block will receive the data in N time steps.
全卷积块和LSTM块在两个不同的视图中感知相同的时间序列输入。全卷积块将时间序列视为具有多个时间步长的单变量时间序列。如果存在一个长度为N的时间序列,则全卷积块将以N个时间步长接收数据。
In contrast, the LSTM block in the proposed architecture receives the input time series as a multivariate time series with a single time step. This is accomplished by the dimension shuffle layer, which transposes the temporal dimension of the time series. A univariate time series of length N,after transformation, will be viewed as a multivariate time series (having N variables) with a single time step. Without the dimension shuffle, the performance of the LSTM block is significantly reduced due to the rapid overfitting of small short-sequence UCR datasets and a failure to learn long term dependencies in the larger long-sequence UCR datasets.
相反,所提出的体系结构中的LSTM块将输入时间序列作为具有单个时间步长的多元时间序列来接收。这是通过维度混洗层实现的,该层对时间序列的时间维度进行转置。长度为N的单变量时间序列,转换后,将被视为具有单个时间步长的多元时间序列(具有N个变量)。如果不进行尺寸调整,由于小的短序列UCR数据集的快速过拟合以及无法学习较大的长序列UCR数据集中的长期依存关系,LSTM块的性能将大大降低。
In addition, dimension shuffle improves the efficiency of this model by requiring an order of magnitude less time to train. When a dataset of N time steps and M variables use a LSTM without dimension shuffling, the LSTM will require N time steps to process a batch of M variables. In contrast, applying the dimension shuffle to the input will allow the LSTM model to process a batch of N variables in M time steps. This suggests that as long as the number of variables M is significantly smaller than the number of time steps N, dimension shuffle will greatly improve the speed of training. As each of the UCR datasets is univariate, the LSTM component of this model will require only 1 time step to process a batch of N variables.
另外,维度混洗通过减少所需的训练时间来提高此模型的效率。当N个时间步长和M个变量的数据集使用不带维数改组的LSTM时,LSTM将需要N个时间步长来处理一批M个变量。相比之下,将尺寸改组应用于输入将允许LSTM模型以M个时间步长处理一批N个变量。这表明,只要变量数M显着小于时间步长N,维数改组将极大地提高训练速度。由于每个UCR数据集都是单变量的,因此该模型的LSTM组件仅需要1个时间步即可处理一批N变量。
To illustrate this, a total of 18 hours is required on a single GTX 1080 Ti to train an LSTM-FCN for each of the 85 UCR datasets, and 19 hours for ALSTM-FCN.Without the dimension shuffle, it would take more than 100 hours to train the respective models on all 85 UCR datasets.
为了说明这一点,单个GTX 1080 Ti总共需要18个小时来训练85个UCR数据集中的LSTM-FCN,而ALSTM-FCN则需要19个小时。如果不进行维变换,则在所有85个UCR数据集上训练各自的模型将花费100多个小时。
以上是关于LSTM Fully Convolutional Networks for Time Series Classification 学习记录的主要内容,如果未能解决你的问题,请参考以下文章