Part 11:Pandas的索引index所具备的四大性能
Posted 编程贝多芬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Part 11:Pandas的索引index所具备的四大性能相关的知识,希望对你有一定的参考价值。
Pandas的索引index
Pandas的索引index的用途:
把数据存储于普通的column列也能用于数据查询,那使用index有什么好处?
index的用途总结:
1.更方便的数据查询;
2.使用index可以获得性能提升;
3.自动的数据对齐功能;
4.更多更强大的数据结构支持;
1.更方便的数据查询
import pandas as pd
df=pd.read_csv('./datas/ml-latest-small/ratings.csv')
df.head()
查询index的数量:df.count()
df.count()
drop==False,让索引列还保持在column:意思就是使id这一列继续存在于数据当中
#drop==False,让索引列还保持在column:意思就是使id这一列继续存在于数据当中
df.set_index('userId',inplace=True,drop=False)
df.head()
df.index 
第一种:使用index查询的方法---会使查询的代码比较简单
df.loc[500].head()
#第一种:使用index查询的方法---会使查询的代码比较简单
df.loc[500].head()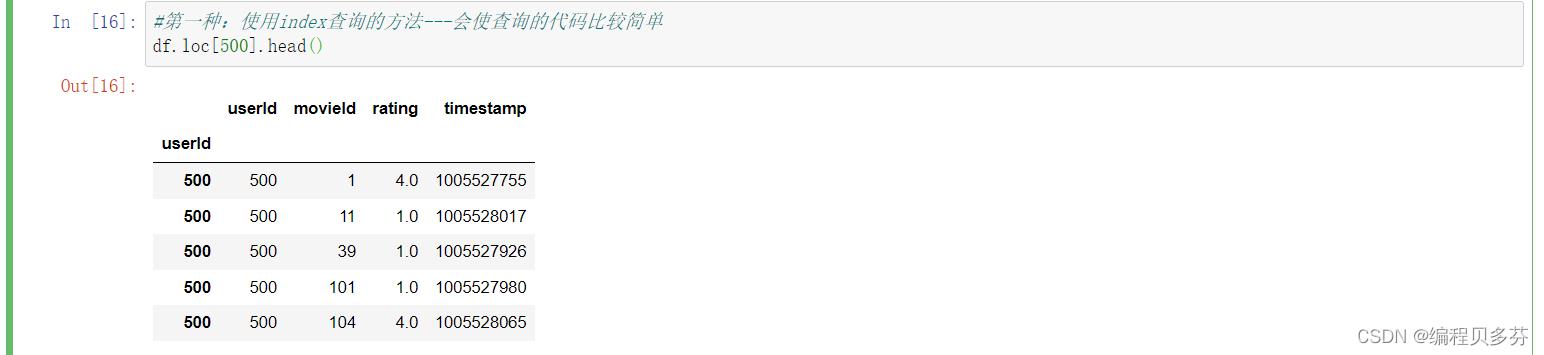
第二种:使用column的condition查询方法
condition=df['userId']
df.loc[condition==500].head()
#第二种:使用column的condition查询方法
condition=df['userId']
df.loc[condition==500].head()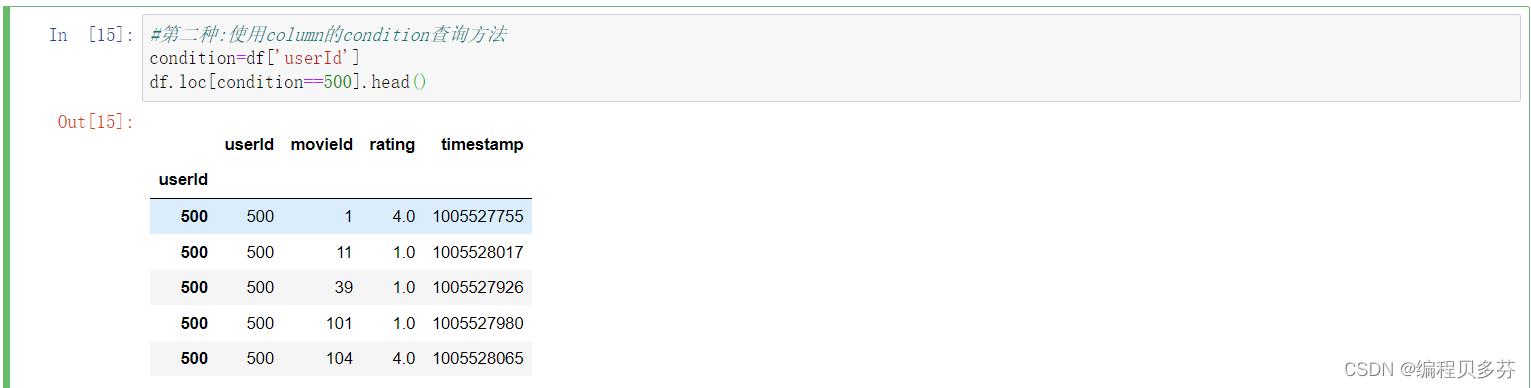
2.使用index会提升查询性能¶
如果index是唯一的,Pandas会使用哈希表优化,查询性能为O(1);
如果index不是唯一的,但是有序,Pandas会使用二分查找算法,查询性能为O(logN);
如果index是完全随机的,那么每次查询都要扫描全表,查询性能为O(N);
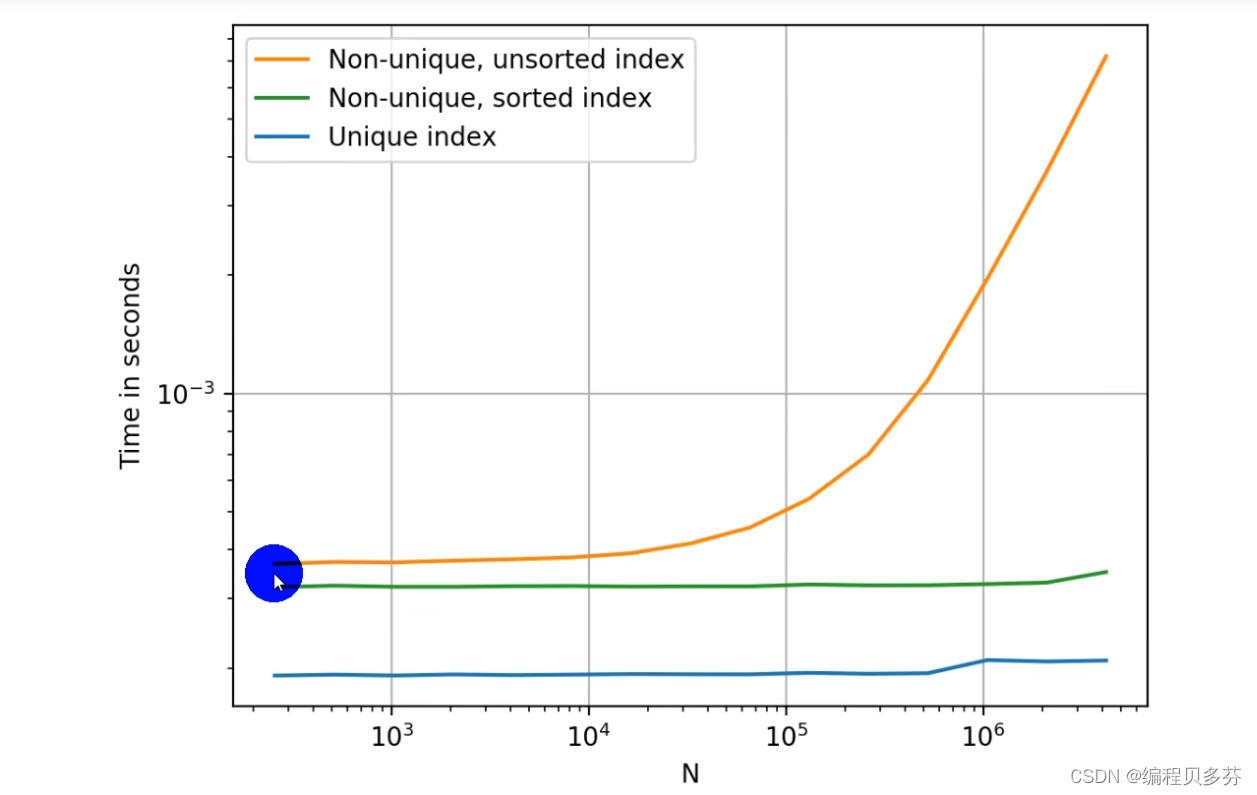
实验1:完全随机的顺序查询
将数据随机打散
!pip install sklearn
#将数据随机打散
from sklearn.utils import shuffle
df_shuffle=shuffle(df)
df_shuffle.head()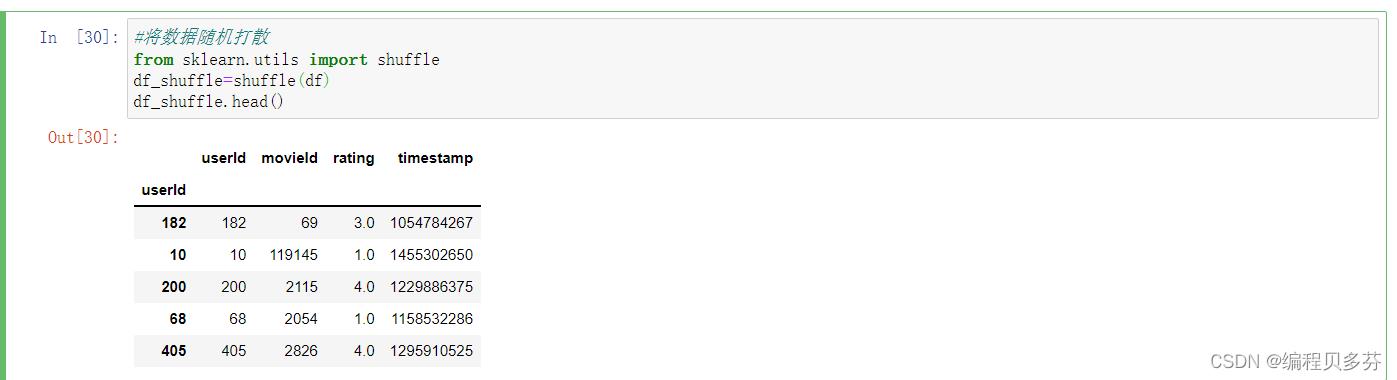
查询我们的索引是不是递增的
df_shuffle.index.is_monotonic_increasing
#查询我们的索引是不是递增的
df_shuffle.index.is_monotonic_increasing查询我们的索引是不是递减的
df_shuffle.index.is_monotonic_decreasing
#查询我们的索引是不是递减的
df_shuffle.index.is_monotonic_decreasing %timeit 函数是经过大量运算,统计计算出平均运行所用的时间
计时,查询id==500数据性能
%timeit df_shuffle.loc[500]
# %timeit 函数是经过大量运算,统计计算出平均运行所用的时间
# 计时,查询id==500数据性能
%timeit df_shuffle.loc[500]
实验2:将index排序后查询
调用sort函数默认为升序操作
#调用sort函数默认为升序操作
df_sorted=df_shuffle.sort_index()
df_sorted.head()
df_sorted.index.is_monotonic_increasing调用sort函数默认为降序操作 设置为ascending=False为降序操作
#调用sort函数默认为降序操作 设置为ascending=False为降序操作
df_sorted2=df_shuffle.sort_index(ascending=False)
df_sorted2.index.is_monotonic_decreasing判断索引是不是唯一的
df_sorted.index.is_unique
#判断索引是不是唯一的
df_sorted.index.is_unique如果index不是唯一的,但是有序,Pandas会使用二分查找算法,查询性能为O(logN);
%timeit df_sorted.loc[500]
#如果index不是唯一的,但是有序,Pandas会使用二分查找算法,查询性能为O(logN);
%timeit df_sorted.loc[500]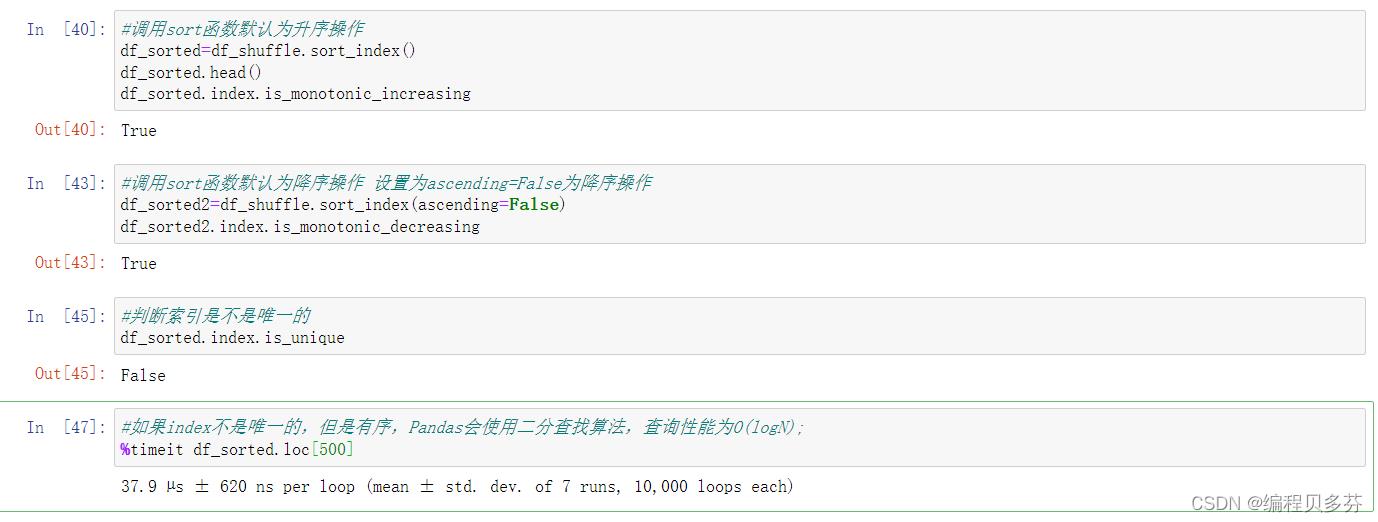
3、使用index能自动对齐数据
包括series和dataframe
index会自动对齐
#index会自动对齐
s1=pd.Series([1,2,3],index=list('abc'))
s1s2=pd.Series([2,3,4],index=list('bcd'))
s2当s1+s2中遇到另一方没有找到相同的索引时,会显示NaN,无法进行算术操作时
#当s1+s2中遇到另一方没有找到相同的索引时,会显示NaN,无法进行算术操作时
s1+s2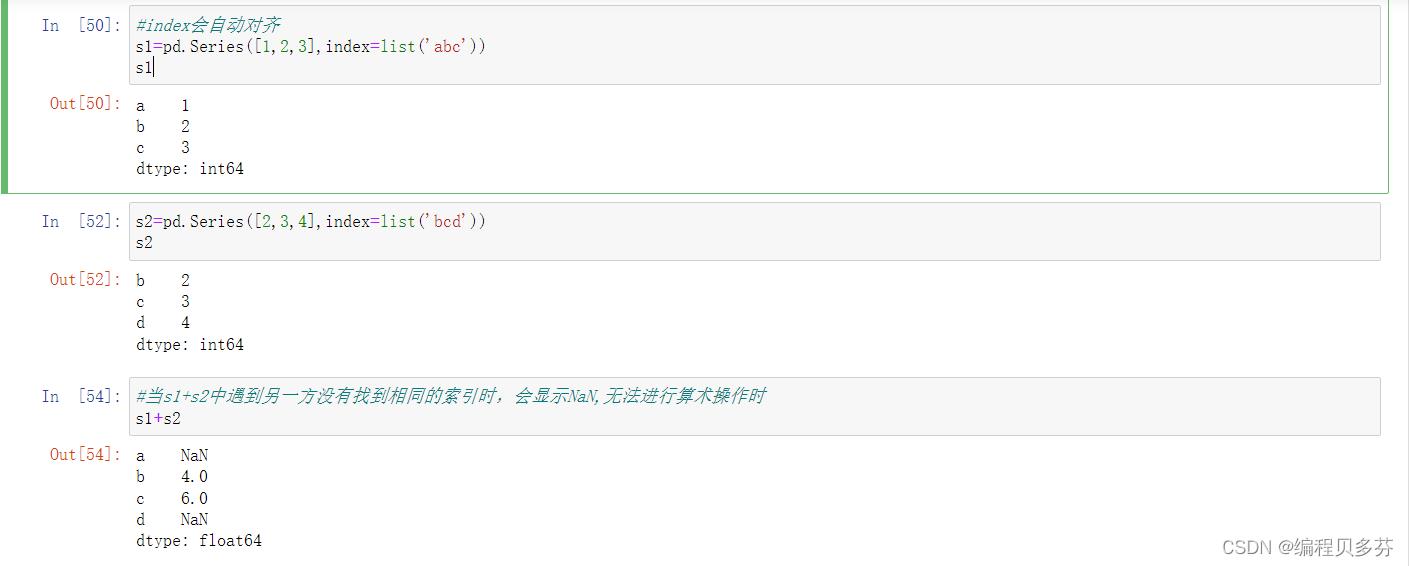
4.使用index更多更强大的数据结构支持
很多强大的索引数据结构
Categoricallndex,基于分类数据的Index,提升性能;
Multilndex,多维索引,用于groupby多维聚合后结果等;
Datetimelndex,时间类型索引,强大的日期和时间的方法支持;
以上是关于Part 11:Pandas的索引index所具备的四大性能的主要内容,如果未能解决你的问题,请参考以下文章