ELK日志系统设计方案-Log4j日志直推Kafka
Posted niaonao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ELK日志系统设计方案-Log4j日志直推Kafka相关的知识,希望对你有一定的参考价值。
ELK 日志系统的常见解决方案:
通常的产品或项目部署至服务器,服务一般会打印日志便于线上问题跟踪。
使用 Log4j 中的自定义 Appender,将服务运行打印的日志直接推送到 Kafka 中。经由 Logstash 消费 Kafka 生产的数据,进行加工过滤后输出到 ElasticSearch 进行日志数据的存储与全文检索。使用 Kibana 对日志数据进行可视化操作。
1. 单点日志系统设计
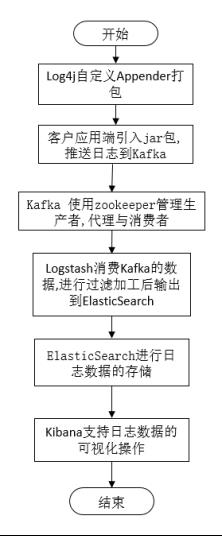
- 相对于 Filebeat 日志收集后输出到 Kafka 的方案,需要服务器存储日志文件。当随着业务复杂性上升,单日日志量也会较大,存储历史日志将占用服务器内存,且不便管理。
- 使用自定义 Appender 直接打印日志上报 Kafka,去掉了 Filebeat 日志收集,并解决了日志文件存储空间占用的问题。不过也存在因网络传输等原因造成日志丢失的风险。
2. 自定义Appender打包说明
- 应用场景
应用于 ELK 日志直推 Kafka 设计场景,自定义 Appender 项目开发打Jar包如下
log-system-util-1.0-SNAPSHOT-jar-with-dependencies.jar - 功能设计
项目打印日志,通过 log4j 将日志信息推送到 Kafka;
作为日志服务器监测对接应用存活状态,心跳监测或轮询监测; - 本地开发自定义 Appender 项目
实现 Appender 打印日志上报指定 Kafka 服务,项目本地打 jar 包,已供多应用对接此工具 - 安装 jar 包到 maven 仓库
mvn install:install-file
-Dfile=C:\\Users\\Zxy\\Desktop\\CODE\\log-system-util-1.0-SNAPSHOT-jar-with-dependencies.jar
-DgroupId=cn.nascent -DartifactId=log-system-util
-Dversion=1.0 -Dpackaging=jar
当出现BUILD SUCCESS 时就说明安装成功
命令说明
(1)-Dfile jar包所在路径,需要包含jar包名.例如:xx/xx/xx/**.jar
(2)-DgroupId 指定导入jar时的groupid,可以自定义,cn.nascent就是自定义的
(3)-DartifactId指定导入jar时的artifactId,可以自定义,log-system-util就是自定义的
(4)-Dversion 指定导入jar时的版本号,可以自定义。这里的1.0就是自定义的
(5)-Dpackaging 指定文件类型 ,由于这里是jar包的形式,所以这里得是jar
- 引入依赖
pers.niaonao 、 log-system-util 、 1.0.0 就是安装jar包时指定的参数
<dependency>
<groupId>pers.niaonao</groupId>
<artifactId>log-system-util</artifactId>
<version>1.0.0</version>
</dependency>
- 修改log4j.properties配置文件
#输出到kafka
log4j.logger.pers.niaonao=INFO,KAFKA
# appender KAFKA
log4j.appender.KAFKA=pers.niaonao.kafka.KafkaLog4jAppender
3. 使用示例
package pers.niaonao;
import org.apache.log4j.Logger;
public class MyAppender
private static Logger LOGGER = Logger.getLogger(MyAppender.class);
public static void main(String[] args) throws InterruptedException
int times = 16;
String mess = "Test My Appender";
String sendMess = null;
for (int i = 0; i < times; i++)
sendMess = mess + "=======>" + i;
MyAppender.LOGGER.info(sendMess);
Thread.sleep(300);
注意
(1) 不可以将 Kafka 定义到 rootLogger 中,这会造成程序的卡顿。因此需要另外定义一个 rootLogger。
(2) log4j.logger.后,=之前的的必须是你的包名。当你指定了这个包名之后,那么在这个包下的类产生的日志才会通过下面定义的appender 输送到 kafka 中。
(3) log4j.appender.KAFKA 这条配置,会在LogManager 类加载时,作为一个 appender 添加到以 log4j.logger 后面跟的包名为名的 logger 中去。之后这个包下的类获取 Logger 时会在类 Hierarchy.class 中的 updateParents 方法中将配置文件中的 appender 添加到在类中获取的 logger(Logger.getLogger(xx.class)) 中。
参考文章
ELK日志系统设计方案-Filebeat日志收集推送Kafka
ELK日志系统设计方案-Log4j日志直推Kafka
ELK日志系统设计方案-集群扩展
ELK日志系统部署实现
Powered By niaonao
以上是关于ELK日志系统设计方案-Log4j日志直推Kafka的主要内容,如果未能解决你的问题,请参考以下文章