Dubbo 3 StateRouter:下一代微服务高效流量路由
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Dubbo 3 StateRouter:下一代微服务高效流量路由相关的知识,希望对你有一定的参考价值。
目前的微服务架构中,通常包含服务消费者、服务提供者、注册中心、服务治理四元素,其中服务消费者会向注册中心获取服务提供者的地址列表,并根据路由策略选出需要调用的目标服务提供者地址列表,最后根据负载算法直接调用提供者。当大规模生产环境下,服务消费者从注册中心获取到的服务提供者地址列表过大时,采用传统的路由方式在每次服务调用时都进行大量地址路由选址逻辑,导致服务调用性能低下,资源消耗过多。
云原生场景下,几千、上万乃至十万节点的集群已经不再罕见,如何高效实现这种大规模环境下的选址问题已经成为了必须解决的问题。
流量路由场景
流量路由,顾名思义就是将具有某些属性特征的流量,路由到指定的目标。流量路由是流量治理中重要的一环,多个路由如同流水线一样,形成一条路由链,从所有的地址表中筛选出最终目的地址集合,再通过负载均衡策略选择访问的地址。开发者可以基于流量路由标准来实现各种场景,如灰度发布、金丝雀发布、容灾路由、标签路由等。
路由选址的范式如下:target = rn(…r3(r2(r1(src))))

下面将借着介绍 OpenSergo 对于流量路由所定义的 v1alpha1 标准,来告诉大家实现流量路由所需的技术。
OpenSergo 流量路由 v1alpha1 标准
流量路由规则(v1alpha1) 主要分为三部分:
- Workload 标签规则 (WorkloadLabelRule):将某一组 workload 打上对应的标签,这一块可以理解为是为 APISIX 的各个上游打上对应的标签
- 流量标签规则 (TrafficLabelRule):将具有某些属性特征的流量,打上对应的标签
- 按照 Workload 标签和流量标签来做匹配路由,将带有指定标签的流量路由到匹配的 workload 中
我们可以赋予标签不同的语义,从而实现各个场景下的路由能力。

给 Workload 打标签:
我们对新版本进行灰度时,通常会有单独的环境,单独的部署集。我们将单独的部署集打上 gray 标签(标签值可自定义),标签会参与到具体的流量路由中。
我们可以通过直接在 Kubernetes workload 上打 label 的方式进行标签绑定,如在 Deployment 上打上 http://traffic.opensergo.io/label: gray标签代表灰度。对于一些复杂的 workload 打标场景(如数据库实例、缓存实例标签),我们可以利用 WorkloadLabelRule CRD 进行打标。示例:
apiVersion: traffic.opensergo.io/v1alpha1
kind: WorkloadLabelRule
metadata:
name: gray-sts-label-rule
spec:
workloadLabels: ['gray']
selector:
database: 'foo_db'给流量打标:
假设现在需要将内部测试用户灰度到新版主页,测试用户 uid=12345,UID 位于 X-User-Id header 中,那么只需要配置如下 CRD 即可:
apiVersion: traffic.opensergo.io/v1alpha1
kind: TrafficLabelRule
metadata:
name: my-traffic-label-rule
labels:
app: my-app
spec:
selector:
app: my-app
trafficLabel: gray
match:
- condition: "==" # 匹配表达式
type: header # 匹配属性类型
key: 'X-User-Id' # 参数名
value: 12345 # 参数值
- condition: "=="
value: "/index"
type: path通过上述配置,我们可以将 path 为 /index,且 uid header 为 12345 的 HTTP 流量,打上 gray 标,代表这个流量为灰度流量。
讲完场景,下面我们来谈纯技术,我们看看传统的流量路由选址方式是什么样的逻辑。
传统流量路由选址方式
一句话描述就是:每次调用时候根据请求中的条件计算结果地址列表,并遍历当前的地址列表,进行地址过滤。
每个 Router 在每次调用都需要动态计算当前请求需要调用的地址列表的子集,再传递给下一个 Router,伪代码如下:
List<Invoker<T>> route(List<Invoker<T>> invokers, URL url, Invocation invocation)
Tag = invocation.getTag;
List<Invoker<T>> targetInvokers = new List<>();
for (Invoker invoker: invokers)
if (invoker.match(Tag))
targetInvokers.add(invoker);
return targetInvokers;
我们分析一下该算法的时间复杂度,发现是O(n)的时间复杂度,每次每个 Router 的 route 调用逻辑都会遍历 invokers 列表,那么当 invokers 数量过大,每次 match 计算的逻辑过大,那么就会造成大量的计算成本,导致路由效率低下。
那么,针对低下效率的计算逻辑,我们是否有什么优化的空间?让我们先来分析与抽象 RPC 的流量路由选址过程。
路由逻辑分析与思考
RPC 的路由选址可以抽象总结为四个过程:
- 流量根据流量特性与路由规则选择对应的 Tag
- 根据 Tag 选择对应的服务端地址列表
- 将上一个 Router 的路由结果地址列表(传入的参数)与符合当前Router的路由结果的地址列表进行集合与操作
- 将(3.)的结果传给下一个 Router
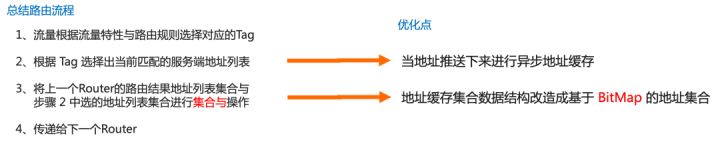
其中过程一由于流量一直在变,这个过程的计算必不可少,但是过程二,在绝大多数路由场景下其只会在地址推送于路由规则变化时才有重新计算的必要,如果在每次调用过程中进行大量地址计算,会导致调用性能损耗过大。是否可以把过程二的逻辑进行异步计算并将计算的地址结果进行缓存缓存?避免大量的重复计算。
同时考虑到过程三中的操作属于集合与逻辑,是否有更高效的数据结构?联想到 BitMap,是否可以将地址列表通过 BitMap 形式存储从而使集合与的时间复杂度降低一个数量级。
既然想到了可以优化的 idea,那么让我们来一起设计新的方案并且来实现它!
高效动态选址机制的设计与实现
假设目前有如下 6 条地址,我们需要实现按照 Tag 路由跟按照 AZ 路由的两个能力:
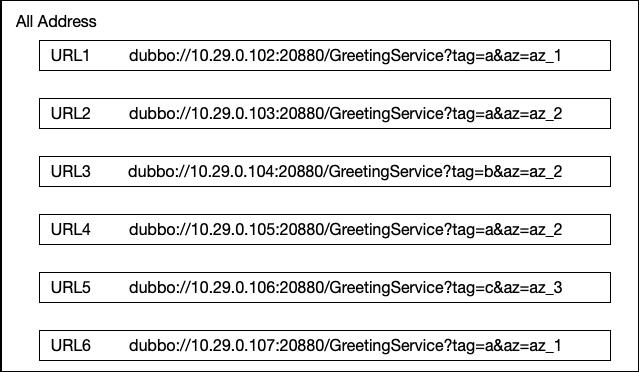
所以我们需要实现两个 Router,假设是 TagRouter 跟 AZRouter,TagRouter 有 3 种 tag 分别是 a、b、c;AZRouter 有三种 az 类型分别是 az_1、az_2、az_3 按照如上假设所示,其实是有 3 * 3 种组合,会存在 3 * 3 * 6 这么多的 URL 引用;假设当前的请求需要去 tag=a&az=az_2,那么按照 Dubbo 原先的方式我们需要在每个 Router 里面遍历一次上一个 Router 计算完成的地址列表,假设存在 M 个 Router、N 条 URL ,那么极端情况下每一次调用需要计算 M*N 次。
那么如果按照我们 StateRouter 路由方式会是怎么一个样子呢?
首先当地址通知下来后,或者路由规则变化时,每个 Router 会先将全量地址按照各自 Router 的路由规则将地址进行计算并将计算结果通过 BitMap 方式存下来;如下图所示:
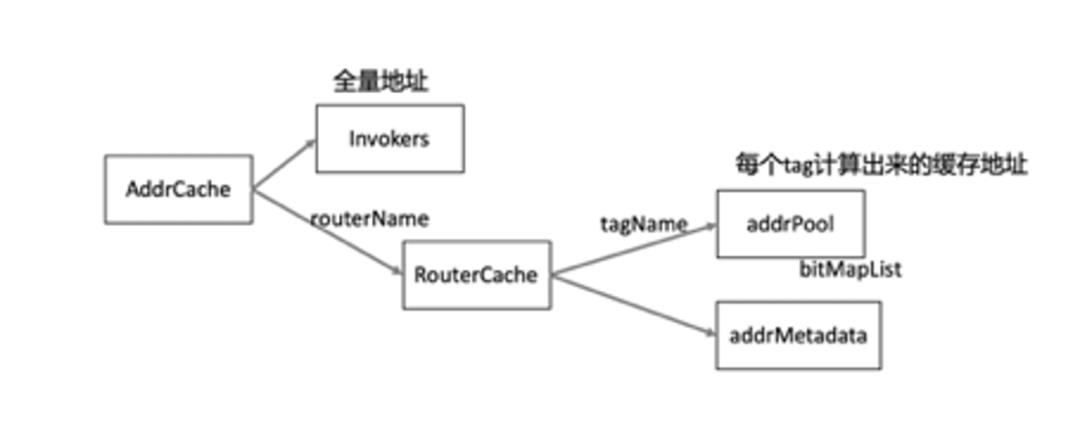
整体存储架构
我们还是以上述 6 个 URL 为例介绍:
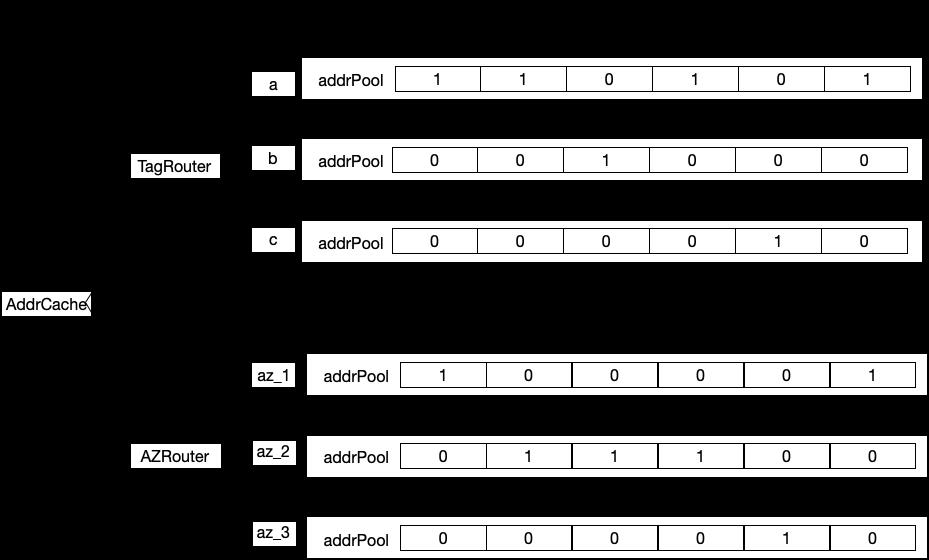
按照路由规则,通过 BitMap 方式进行地址缓存,接下来路由计算时,我们只需从 AddrCache 中取出对应的 addrPool 传递给下一个 Router 即可。
如果当前请求是需要满足 Tag=a & az=az_2,那么我们该如何路由呢?
- TagRouter 逻辑
- 按照流量计算出目标的 Tag,假设是 a
- 然后 AddrCache.get(TagRouter).get(a),取出对应的 targetAddrPool
- 将上一次传入的 addrPool 与 targetAddrPool 取出 resultAddrPool
- 将 resultAddrPool 传入 AZRouter
- AZRouter 逻辑
- 按照流量计算出目标的 Tag,假设是 az_2
- 然后 AddrCache.get(AZRouter).get(az_2),取出对应的 targetAddrPool
- 将上一次传入的 addrPool 与 targetAddrPool 取出 resultAddrPool
- 将 resultAddrPool 为最终路由结果,传递给 LoadBalance

关键源码的伪代码如下:
//List<Invoker<T>> -> Bitmap
List<Invoker<T>> route(List<Invoker<T>> invokers, Map<Router, Map<Tag, List<Invoker<T>>> cache, URL url, Invocation invocation)
pool = cache.get(this);
Tag = invocation.getTag;
return pool.get(Tag) & invokers;
Dubbo3 使用案例
Dubbo3 在总体性能、集群吞吐量、稳定性等方面相比上一代微服务框架都有了显著的提升,尤其适用于大规模微服务集群实践的场景,StateRouter 即是其中非常重要的一环,该方案通过 Dubbo3 已经在包括阿里之内的众多企业实践验证。
另外提一下,感兴趣的开发者可搜索并加入贡献者群钉钉群 31982034,免费参与每周一次的 Dubbo 技术分享并有机会赢取定制礼品,如果您是 Dubbo3 企业用户欢迎加入钉钉交流群 34129986。
总结
目前 MSE 服务治理的 离群实例摘除、标签路由、金丝雀发布、全链路灰度等功能已经使用该路由方案,经过我们的压测与演练,在 CPU、RT 等方面均有不少提升,以 Demo 应用为例 (服务调用的跳数为 2,下游 30 节点,每个节点 1c2g) 其中调用 RT 提升约 6.7%。
更多服务治理能力与标准的探索
随着分布式服务架构的不断演进带来诸多复杂的稳定性与易用性问题,单一的监控已无法满足架构的演进。在现代微服务架构中,我们需要一些手段来对复杂的微服务架构进行“治理”。微服务治理就是通过全链路灰度、无损上下线、流控降级、异常流量调度、数据库治理等技术手段来减少甚至避免发布和管理大规模应用过程中遇到的稳定性问题,对微服务领域中的各个组件进行治理。服务提供者、消费者、注册中心、服务治理,构成现代微服务架构中重要的几环。
服务治理是微服务改造深入到一定阶段之后的必经之路,在这个过程中我们不断有新的问题出现。
- 除了全链路灰度,服务治理还有没其他能力?
- 服务治理能力有没一个标准的定义,服务治理能力包含哪些?
- 多语言场景下,有无全链路的最佳实践或者标准?
- 异构微服务如何可以统一治理?
当我们在探索服务治理的过程中,我们在对接其他微服务的时候,我们发现治理体系不同造成的困扰是巨大的,打通两套甚者是多套治理体系的成本也是巨大的。为此我们提出了 OpenSergo 项目。OpenSergo 要解决的是不同框架、不同语言在微服务治理上的概念碎片化、无法互通的问题。
作者:十眠
本文为阿里云原创内容,未经允许不得转载。
以上是关于Dubbo 3 StateRouter:下一代微服务高效流量路由的主要内容,如果未能解决你的问题,请参考以下文章
SpringCloud Alibaba微服务实战二十二 - 整合Dubbo