自己动手写编译器:汤普森构造法
Posted tyler_download
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自己动手写编译器:汤普森构造法相关的知识,希望对你有一定的参考价值。
上节我们描述了正则表达式的规则,有过一些编程经验的同学或许都用过正则表达式功能,通常使用它来检验特定格式的字符串,例如检验输入的邮箱是否合法等。当然大多数时候我们只要“调用”即可,但对于要做编译器而言,我们必须自己实现正则表达式引擎的功能。
本节我们要实现的正则表达式引擎将用于判断输入的字符串是否满足我们自己设定的语法规则,首先我们给出一段语法表达式:
stmt -> if expr then stmt | if expr then stmt else stmt |
ϵ
\\epsilon
ϵ
expr -> term relop term | term
term -> id | number
上面这段语法其实描述了Pascal语言的if判断逻辑,上面语法中有几个关键token,分别为:
1,关键字: if, then , else
2, 操作符:relop, 它包含 >, <, <>(不等于), ==,
3, 变量名和数字,也就是id, 和 number
我们将读取一段文本,然后判断文本中的字符串是否属于上面三个类别,下面我们给出判断字符串是否满足条件的正则表达式:
digit -> [0-9]
digits ->
d
i
g
i
t
+
digit^+
digit+
number -> digits(.digits)?(‘E’[±]?digits)? (这里的E表示单个字符“E")
letter -> [A-Za-z]
id -> letter(letter | digit)*
if -> “if”
then -> “then”
else -> “else”
relop -> ‘<’ | ‘>’ | “<=” | “>=” | “<>”
ws->
(
b
l
a
n
k
∣
t
a
b
∣
n
e
w
l
i
n
e
)
+
(blank | tab | newline)^+
(blank∣tab∣newline)+
从上面正则表达式可以看到,要满足number定义的规则,字符串需要由数字组成,它可以包含字符’.’ , 'E’等, 要满足id的规则,字符串必须要以字符开头,后面跟着0个或多个字符或数字,对于关键字if, then ,else 则是直接进行字符串完全匹配. ws表示空格,它是空格(blank),制表符(tab)和换行(newline)的组合。
接下来的问题是,我们如何实现匹配算法。这里我们需要引入一种数据结构叫”转换图“,每一种正则表达式都能转换成对应的”转换图",这个数据结构跟图论中的有向图很像,在概念上它由一系列的"点",和“有向边”组成,点对应状态,边对应状态之间的转换。总体来说”转换图“需要满足以下条件约束:
1, 在所有节点中,有部分节点称为”终结状态“,一旦进入这些节点就表明,当前读到的字符串满足了某些特定的规则。
2,在任何状态节点时,任何接收字符都只能对应一条转换边。
3,如果处于接收状态节点,并且带有一个*字符,意味着放弃当前读到的字符然后进入终结状态
4,它一定含有一个初始状态节点。
我们看一个具体例子,如何识别实现表达式relop对字符串的识别。首先我们构造转换图如下:
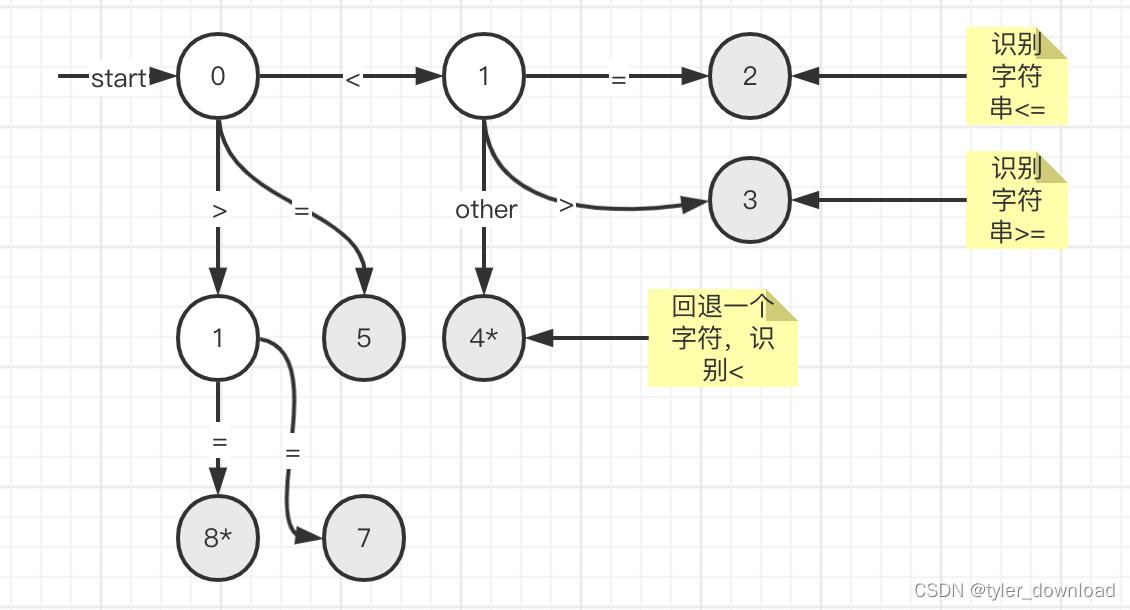
我们看上面的状态转换图,首先我们位于起始状态0,如果下面接收到字符’<‘就进入状态1,在状态1时,根据接收字符转入下一个状态,如果接收到字符’=‘,那么进入状态2,它是一个实心点,也就是终结态,它表示当前我们识别到了一个满足规则的字符串,也就是"<=",其他同理。这里需要注意状态4,如果在状态1时,读取的下一个字符不是’=‘和’>‘,那么转换图告诉我们放弃当前读到字符,然后进入状态4,此时我们读取到合法字符串那就是"<"。这里还有一个意味,如果我们处于状态0,当时读取字符不是’<', ‘=’, '>'那该怎么办,这种情况意味着上面转换图不适用。
下面我们看看识别变量名的转换图:
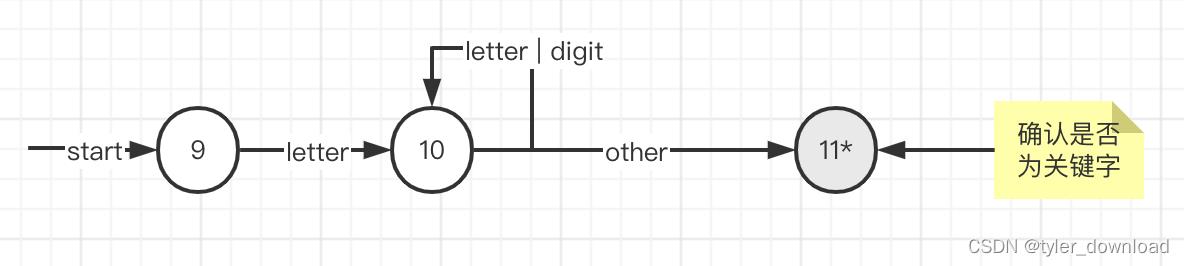
首先我们处于初始状态9,此时如果读入的字符是[A-Za-z],那么进入状态10,接下来如果读到的下个字符是英文字符或数字,那么就一直保持状态在状态10,如果读入的字符不属于英文字符后数字,那么放弃当前读入的字符同时进入状态11,因为它是终结状态,这意味着我们当前读取的字符串满足给定规则。这里需要注意的是,关键字字符串完全符合上面状态图描述的规则,为了将他们与变量名区分开来,我们首先将所有关键字字符串”写死“,在进入状态11后,我们把当前读取的字符串跟关键字列表一一比对,如果比对上那么把当前字符串识别为关键字,要不然就确认它是变量名。
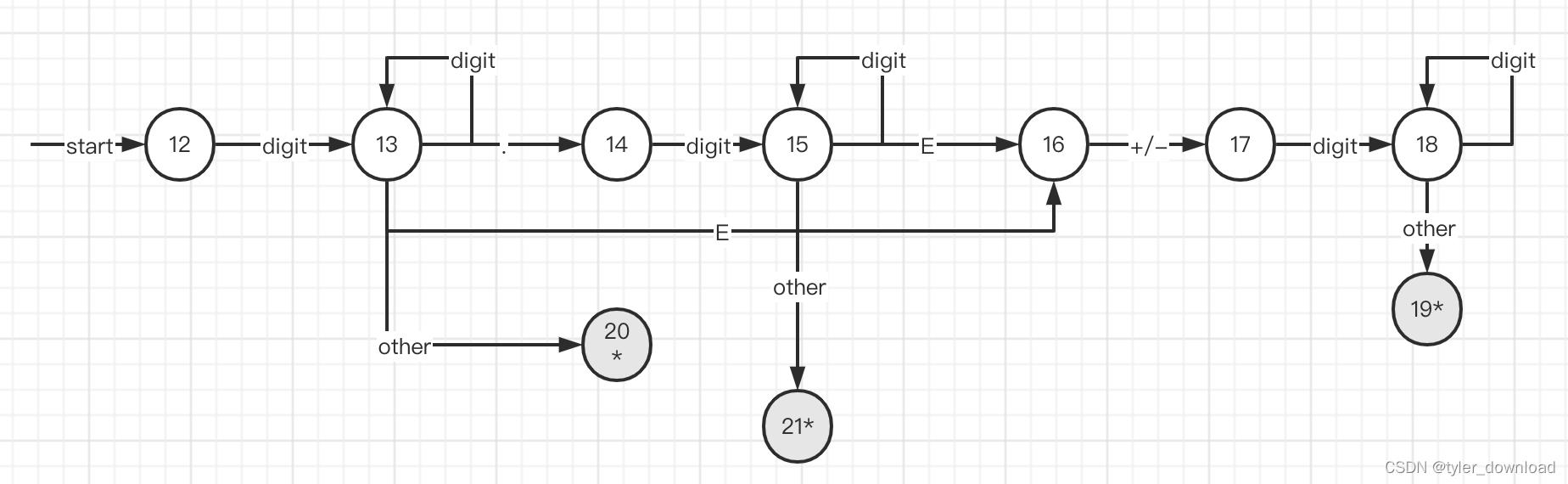
我们再看看识别数字的转换图:
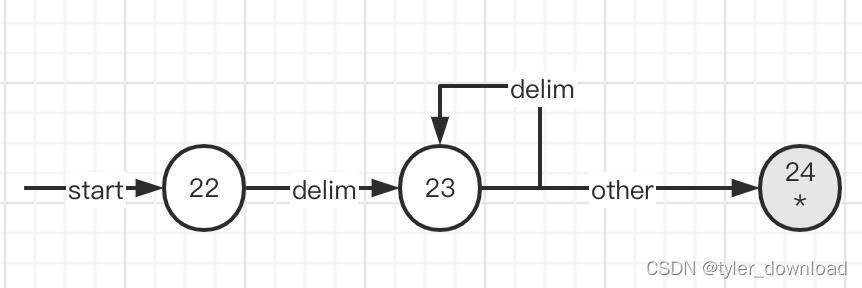
我们继续看识别空格,换行,制表等这些不被认为有效字符的识别:
这里我们看到的转换图有学名叫确定下状态机(DFA deterministic finite automa),在每个状态,它都能根据当前输入确定下一个状态,但很多情况下,我们很难直接从正则表达式去构造DFA,因此我们需要将其扩展一下变成NFA(no-deterministic finite automa)。相比于前者,NFA多了一种边叫
ϵ
\\epsilon
ϵ,从一个状态节点可以发出多条这样的边,这种边表示不用输入任何字符就可以抵达给定状态,例如正则表达式any|d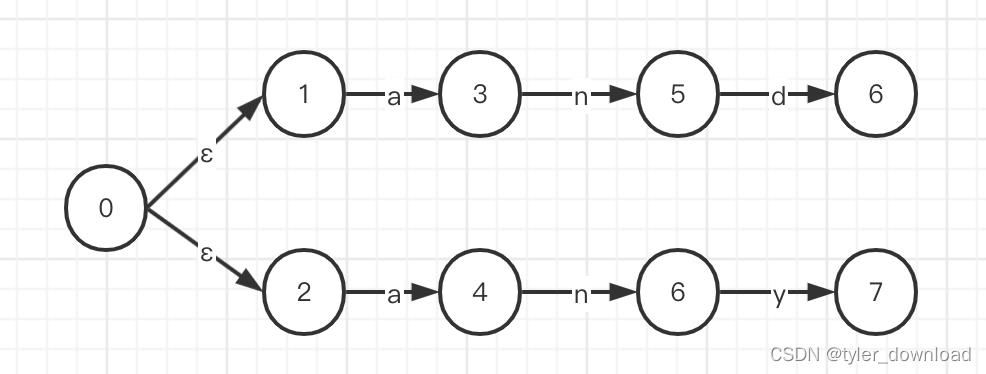
NFA比DFA更加灵活,但是也正是因为如此,它比较难以在计算机中进行应用,在后面内容中,我们将看到如何将正则表达式先用NFA表达,然后再将其转换为DFA。下面我们看看如何将正则表达式转换为NFA,这种算法也叫汤普森构造法。
首先最简单的正则表达式是匹配单个字符例如匹配字符’a’,它对应的NFA如下:
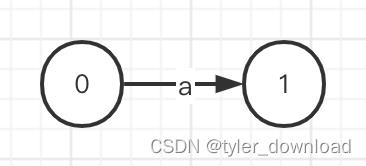
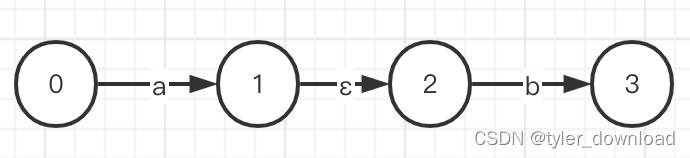
对应稍微复杂一点的表达式,例如识别字符"ab",那么我们可以分别构造识别a的状态机和识别b的状态机,然后使用一条
ϵ
\\epsilon
ϵ将两个状态机连起来:
对于表达式a|b,我们可以构造状态机如下:
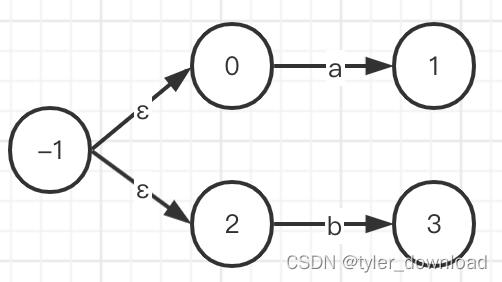
从这里我们可以看到,无论多么复杂的表达式,我们都可以通过这两种方法构造出其对应的NFA,对于表达式a*,它对应的NFA如下:
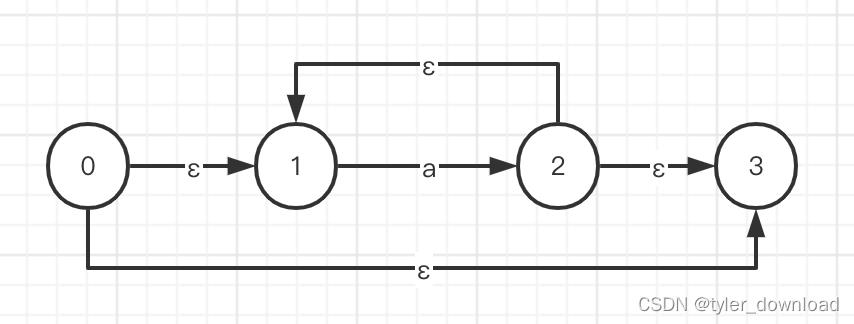
这里需要注意的是,a*表示0个或任意多个字符a的重复,如果是0个的话,那么我们直接从状态0通过ε边直达最终状态3,如果是有多个字符a,那么我们就在状态1和2之间来回。对于表达式:
a
+
a^+
a+,
我们只要去掉上边状态机底部的ε边即可。对于表达式a?,我们只要在上图NFA中去掉状态1和2之间那条ε边即可。
下一节我们看看如何在代码上实现汤普森构造法,进而实现一个正则表达式识别引擎。
以上是关于自己动手写编译器:汤普森构造法的主要内容,如果未能解决你的问题,请参考以下文章