Hadoop与Spark的关系,Spark集群必须依赖Hadoop吗?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop与Spark的关系,Spark集群必须依赖Hadoop吗?相关的知识,希望对你有一定的参考价值。
Spark集群也是构建在分布式系统上的,要用到HDFS上是吗?所以必须先搭建Hadoop吗?如果不是的话Spark应该怎么搭建,不用详细讲,就大概说说。最近搭建了Spark集群是在Hadoop集群上的,所以想了解一下他俩的区别
必须在hadoop集群上,它的数据来源是HDFS,本质上是yarn上的一个计算框架,像MR一样。
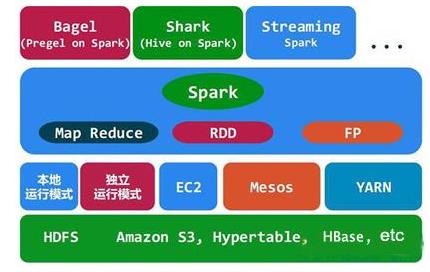
Hadoop是基础,其中的HDFS提供文件存储,Yarn进行资源管理。可以运行MapReduce、Spark、Tez等计算框架。
与Hadoop相比,Spark真正的优势在于速度,Spark的大部分操作都是在内存中,而Hadoop的MapReduce系统会在每次操作之后将所有数据写回到物理存储介质上,这是为了确保在出现问题时能够完全恢复,但Spark的弹性分布式数据存储也能实现这一点。
扩展资料:
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
参考资料来源:百度百科-SPARK
参考技术A Spark已经取代Hadoop成为最活跃的开源大数据项目,但是,在选择大数据框架时,企业不能因此就厚此薄彼近日,著名大数据专家Bernard Marr在一篇文章中分析了Spark和 Hadoop 的异同
Hadoop和Spark均是大数据框架,都提供了一些执行常见大数据任务的工具,但确切地说,它们所执行的任务并不相同,彼此也并不排斥
虽然在特定的情况下,Spark据称要比Hadoop快100倍,但它本身没有一个分布式存储系统
而分布式存储是如今许多大数据项目的基础,它可以将 PB 级的数据集存储在几乎无限数量的普通计算机的硬盘上,并提供了良好的可扩展性,只需要随着数据集的增大增加硬盘
因此,Spark需要一个第三方的分布式存储,也正是因为这个原因,许多大数据项目都将Spark安装在Hadoop之上,这样,Spark的高级分析应用程序就可以使用存储在HDFS中的数据了
与Hadoop相比,Spark真正的优势在于速度,Spark的大部分操作都是在内存中,而Hadoop的MapReduce系统会在每次操作之后将所有数据写回到物理存储介质上,这是为了确保在出现问题时能够完全恢复,但Spark的弹性分布式数据存储也能实现这一点
另外,在高级数据处理(如实时流处理、机器学习)方面,Spark的功能要胜过Hadoop
在Bernard看来,这一点连同其速度优势是Spark越来越受欢迎的真正原因
实时处理意味着可以在数据捕获的瞬间将其提交给分析型应用程序,并立即获得反馈
在各种各样的大数据应用程序中,这种处理的用途越来越多,比如,零售商使用的推荐引擎、制造业中的工业机械性能监控
Spark平台的速度和流数据处理能力也非常适合机器学习算法,这类算法可以自我学习和改进,直到找到问题的理想解决方案
这种技术是最先进制造系统(如预测零件何时损坏)和无人驾驶汽车的核心
Spark有自己的机器学习库MLib,而Hadoop系统则需要借助第三方机器学习库,如Apache Mahout
实际上,虽然Spark和Hadoop存在一些功能上的重叠,但它们都不是商业产品,并不存在真正的竞争关系,而通过为这类免费系统提供技术支持赢利的公司往往同时提供两种服务
例如,Cloudera 就既提供 Spark服务也提供 Hadoop服务,并会根据客户的需要提供最合适的建议
Bernard认为,虽然Spark发展迅速,但它尚处于起步阶段,安全和技术支持基础设施方还不发达,在他看来,Spark在开源社区活跃度的上升,表明企业用户正在寻找已存储数据的创新用法 参考技术B 必须在hadoop集群上,它的数据来源是HDFS,本质上是yarn上的一个计算框架,像MR一样。追问
我也是这么想的,Spark也需要map和reduce的过程。导师一直问我Spark和Hadoop是两个不同的东西,到底不同在哪儿,我说Spark是可以基于内存的,可以将Job的结果存在内存中迭代运行,除了这些Hadoop和Spark还有什么联系吗?谢谢您了
追答Hadoop是基础,其中的HDFS提供文件存储,Yarn进行资源管理。在这上面可以运行MapReduce、Spark、Tez等计算框架。
参考技术C 要清楚hdfs只是用来分布式存储数据的,spark总共有四种模式,local,standlone,yarn,mesos。只有yarn模式会用到hadoop的yarn集群spark集群安装并集成到hadoop集群
前言
最近在搞hadoop+spark+python,所以就搭建了一个本地的hadoop环境,基础环境搭建地址hadoop2.7.7 分布式集群安装与配置
本篇博客主要说明,如果搭建spark集群并集成到hadoop
安装流程
安装spark需要先安装scala 注意在安装过程中需要对应spark与scala版本, spark 也要跟hadoop对应版本,具体的可以在spark官网下载页面查看
下载sacla并安装
https://www.scala-lang.org/files/archive/scala-2.11.12.tgz tar zxf scala-2.11.12.tgz
移动并修改权限
chown hduser:hduser -R scala-2.11.11
mv /root/scala-2.11.11 /usr/local/scala
配置环境变量
vim .bashrc
#scala var
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
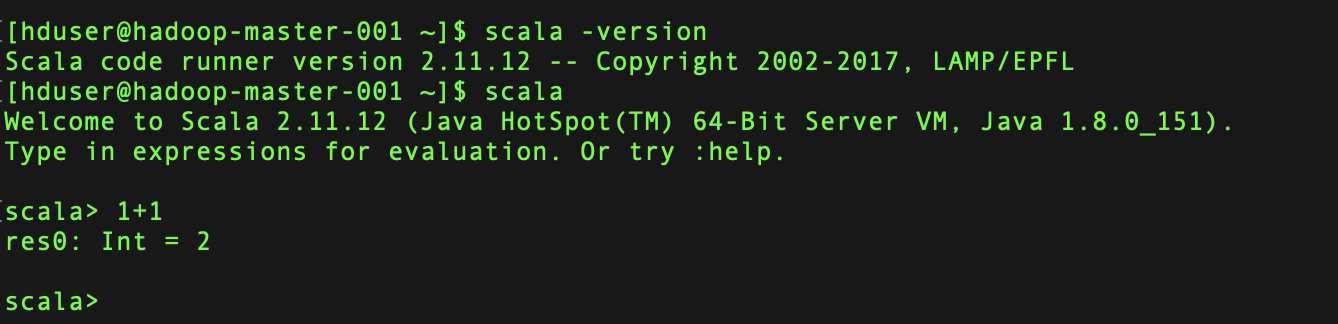
安装完成可以通过scala进如交互页面
注意事项
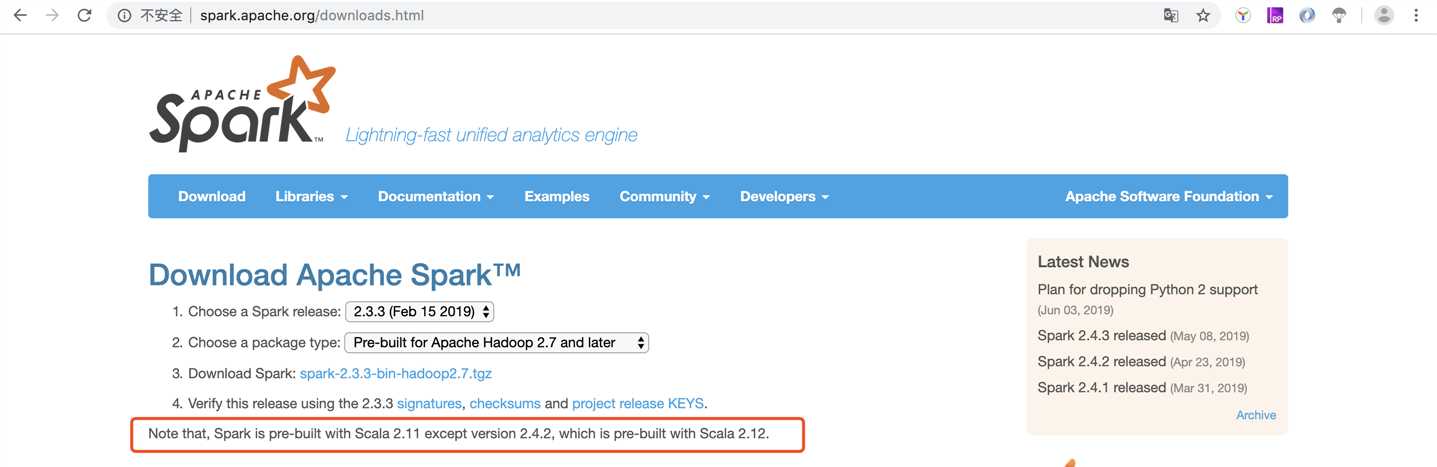
注意:Spark与hadoop版本必须互相匹配,因为Spark会读取Hadoop HDFS 并且必须能在Hadoop YARN执行程序,所以必须要按照我们目前安装的Hadoop版本来选择
笔者这里用的是hadoop2.7.7 所以我选择的是Pre-built for Apache Hadoop 2.7 and later
下载并安装spark
http://mirror.bit.edu.cn/apache/spark/spark-2.3.3/spark-2.3.3-bin-hadoop2.7.tgz
tar zxf spark-2.3.3-bin-hadoop2.7.tgz
移动并修改权限
chown hduser:hduser spark-2.3.3-bin-hadoop2.7
mv spark-2.3.3-bin-hadoop2.7 /usr/local/spark
配置环境变量
vim .bashrc
#spark var
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
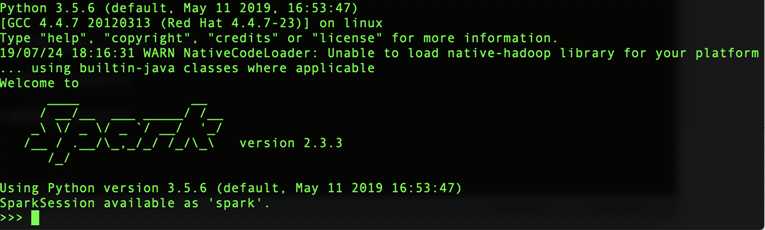
进入spark交互页面
默认是python2.7.x版本,对于当前来说版本比较老,可以修改pyspark来选择其他版本(前提是当前服务器已安装其他版本python)
修改master下的spark-env.sh #没有这个文件可以cp spark-env.sh.template spark-env.sh
在最后一行添加如下
export PYSPARK_PYTHON=/usr/bin/python3
修改master下的spark bin目录下pyspark
将文本中
PYSPARK_PYTHON=python
改为
PYSPARK_PYTHON=python3
#取消INFO信息打印
复制conf目录下的log4j模本文件到log4j.properties
将文本中
log4j.rootCategory=INFO, console
改为
log4j.rootCategory=WARN, console
测试与效果图
本地运行spark
pyspark --master local[4]
spark 读取本地文件,所有节点都必须存在该文件
textFile=sc.textFile("file:/usr/local/spark/README.md")
spark 读取hdfs文件
textFile2=sc.textFile("hdfs://hadoop-master-001:9000/wordcount/input/LICENSE.txt")

Hadoop YARN运行spark
HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop pyspark --master yarn --deploy-mode client
textFile = sc.textFile("hdfs://hadoop-master-001:9000/wordcount/input/LICENSE.txt")
textFile.count()

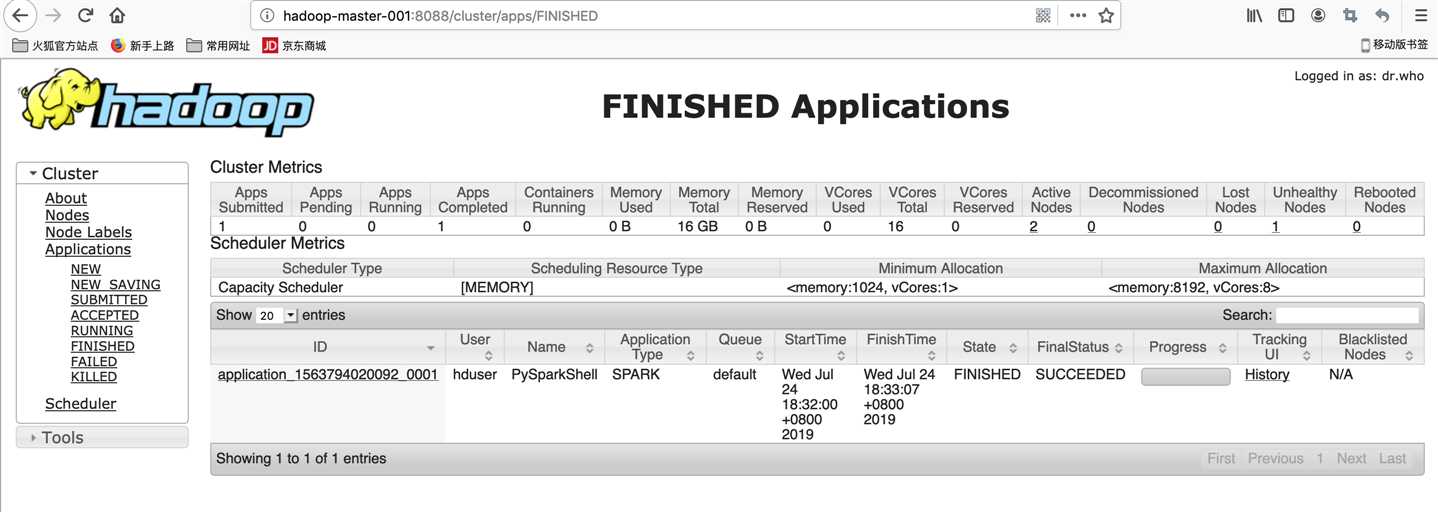
spark Standalone Cluster运行
编辑spark-env.sh #spark_home/conf
export SPARK_MASTER=hadoop-master-001 //设置master的ip或域名
export SPARK_WORKER_CORES=1 //设置每个worker使用的CPU核心
export SPARK_WORKER_MEMORY=512m //设置每个worker使用的内存
export SPARK_WORKER_INSTANCES=4 //设置实例数
将master环境中的spark目录打包并分别远程传输到所有slave节点中.
设置spark Standalone Cluster 服务器(master环境)
vim /usr/local/spark/conf/slaves 添加ip或域名
hadoop-data-001
hadoop-data-002
hadoop-data-003
启动与关闭
/usr/local/spark/sbin/start-all.sh
/usr/local/spark/sbin/stop-all.sh
pyspark --master spark://hadoop-master-001:7077 --num-executors 1 --total-executor-cores 3 --executor-memory 512m
textFile = sc.textFile("file:/usr/local/spark/README.md")
textFile.count()
注意 当在cluster模式下,如yarn-client或spark standalone 读取本地文件时,因为程序是分不到不同的服务器,所以必须确认所有机器都有该文件,否则会发生错误.
建议 最好在cluster读取hdfs文件,这样不会出现文件
text2=sc.textFile("hdfs://hadoop-master-001:9000/wordcount/input/LICENSE.txt")
text2.count()

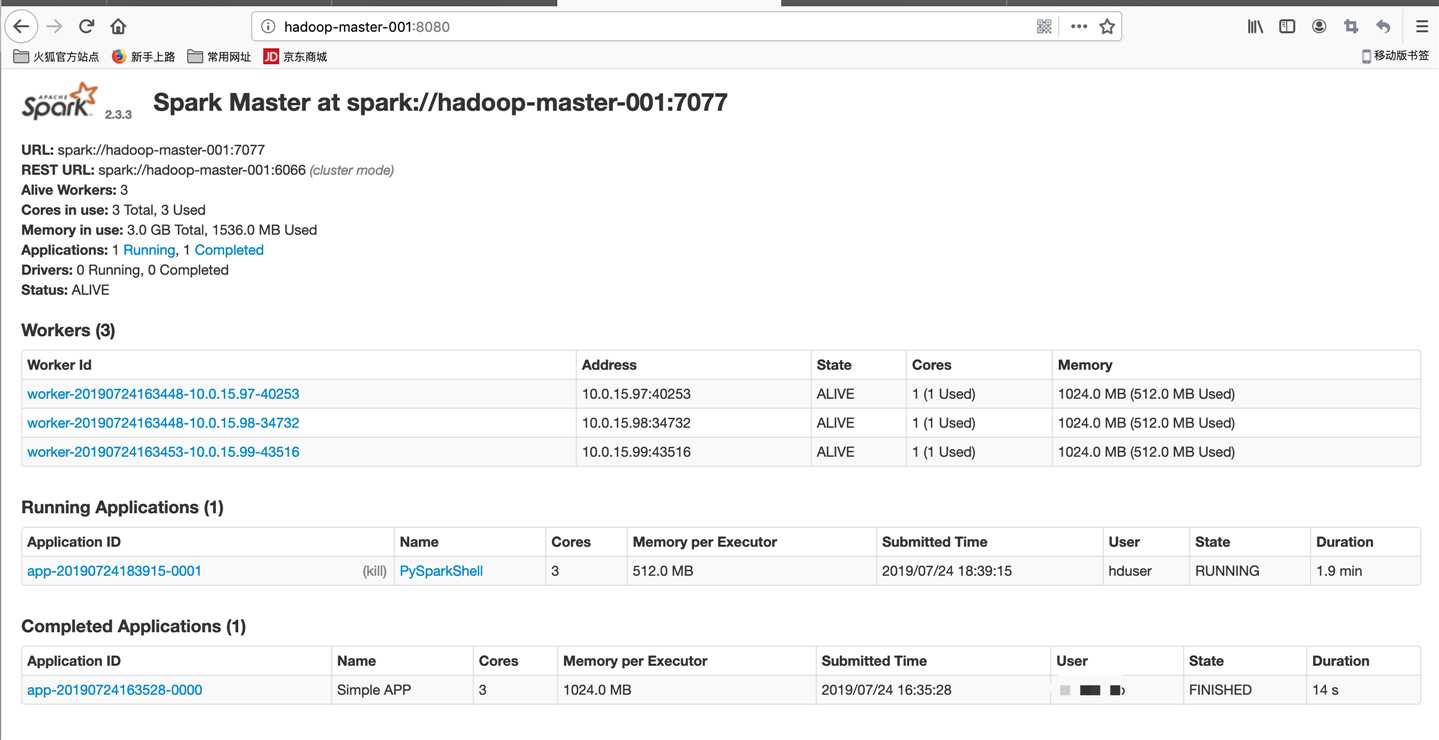
spark web ui
异常处理
hadoop yarn运行pyspark时异常信息:
ERROR SparkContext: Error initializing SparkContext. org.apache.spark.SparkException: Yarn application has already ended! It might have been killed or unable to launch application master
解决方式
查看http://hadoop-master-001:8088/cluster/app/ 最新任务点击history 查看信息
"Diagnostics: Container [pid=29708,containerID=container_1563435447194_0007_02_000001] is running beyond virtual memory limits. Current usage: 55.6 MB of 1 GB physical memory used; 2.2 GB of 2.1 GB virtual memory used. Killing container."
修改所有节点的yarn-site.xml,添加如下
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
主节点执行stop-yarn.sh, start-yarn.sh 重启所有节点yarn
以上是关于Hadoop与Spark的关系,Spark集群必须依赖Hadoop吗?的主要内容,如果未能解决你的问题,请参考以下文章