图解分布式的两种单点问题(有状态服务和无状态服务)
Posted 流楚丶格念
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图解分布式的两种单点问题(有状态服务和无状态服务)相关的知识,希望对你有一定的参考价值。
文章目录
前言:在分布式系统中,单点问题是一个比较常见的问题,对于单点问题可以分为有状态服务的单点问题和无状态服务的单点问题。
无状态服务的单点问题
问题
对于无状态的服务,单点问题的解决比较简单,因为服务是无状态的,所以服务节点很容易进行平行扩展。比如,在分布式系统中,为了降低各进程通信的网络结构的复杂度,我们会增加一个代理节点,专门做消息的转发,其他的业务进行直接和代理节点进行通信,类似一个星型的网络结构。
如下图中proxy是一个消息转发代理,业务进程中的消息都会经过该代理,这也是比较场景的一个架构。在上图中,只有一个proxy,如果该节点挂了,那么所有的业务进程之间都无法进行通信。

解决方案
方案一:设置多代理节点
由于proxy是无状态的服务,所以很容易想到第二个图中(如下)的解决方案,增加一个proxy节点,两个proxy节点是对等的。
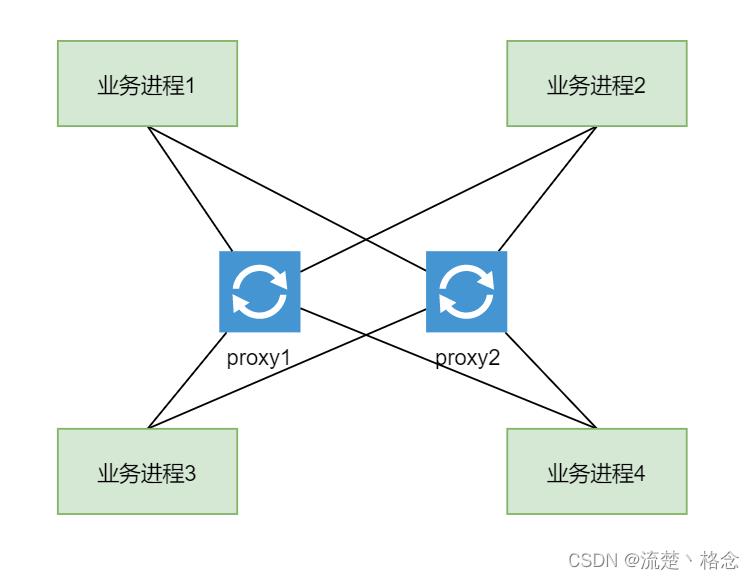
增加新节点后,业务进程需要与两个Proxy之间增加一个心跳的机制,业务进程在发送消息的时候根据proxy的状态,选择一个可用的proxy进行消息的传递。从负载均衡的角度来看,如果两个proxy都是存活状态的话,业务进程应当随机选择一个proxy
方案一:指定发送节点
那么该解决方案中会存在什么问题呢?
主要存在的问题是消息的顺序性问题。一般来说,业务的消息都是发送、应答,再发送、再应答这样的顺序进行的,在业务中可以保证消息的顺序性。
但是,在实际的应用中,会出现这样一个情况:在业务进程1中,有个业务需要给业务进程3发送消息A和消息B,根据业务的特性,消息A必须要在消息B之前到达。如果业务进程1在发送消息A的时候选择了proxy1,在发送消息B的时候选择了proxy2,那么在分布式环境中,我们并不能确保先发送的消息A一定就能比后发送的消息B先到达业务进程3。
那么怎么解决这个问题?
其实方案也比较简单,对于这类对消息顺序有要求的业务,我们可以指定对应的proxy进行发送,比如消息A和消息B都是使用proxy1进行发送,这样就可以保证消息A比消息B先到达业务进程3。
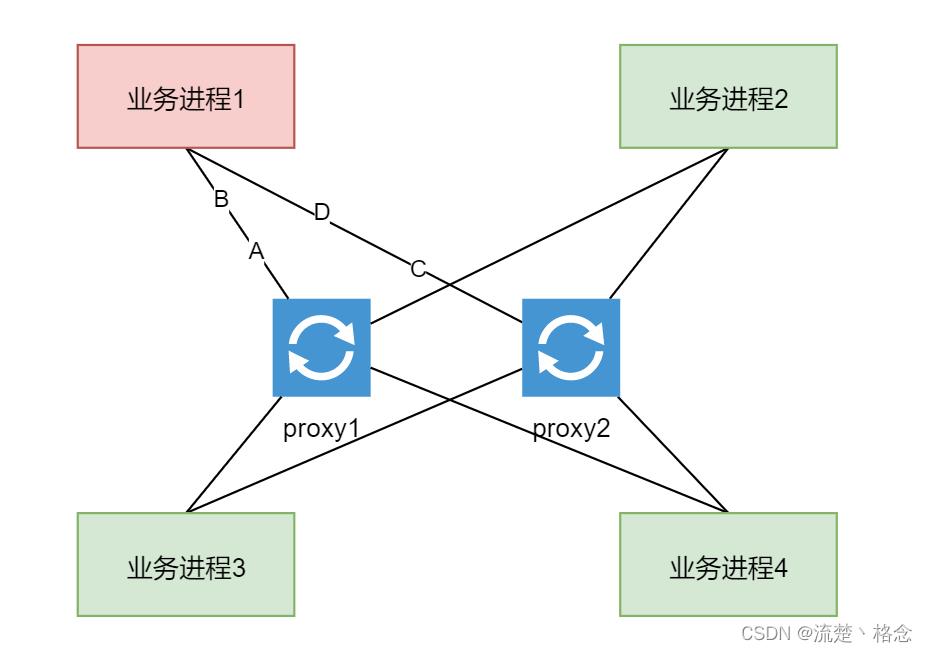
整体来说,对于无状态的服务的单点问题的解决方案还是比较简单的,只要增加对应的服务节点即可。
有状态服务的单点问题
问题
相对无状态服务的单点问题,有状态服务的单点问题就复杂多了。如果在架构中,有个节点是单点的,并且该节点是有状态的服务,那么首先要考虑的是该节点是否可以去状态,如果可以,则优先选择去除状态的方案(比如说把状态存储到后端的可靠DB中,可能存在性能的损耗),然后就退化成了一个无状态服务的单点问题了,这就可以参考上一方案了。
但是,并不是所有的服务都是可以去状态的,比如说对于一些业务它只能在一个节点中进行处理,如果在不同的节点中处理的话可能会造成状态的不一致,这类型的业务是无法去除状态的。对于这种无法去除状态的单点的问题的解决方案也是有多种,但是越完善的方案实现起来就越复杂,不过整体的思路都是采用主备的方式。
解决
第一个方案就是就是增加一个备用节点,备用节点和业务进程也可以进行通信,但是所有的业务消息都发往Master节点进行处理。
Master节点和Slave节点之间采用ping的方式进行通信。Slave节点会定时发送ping包给Master节点,Master节点收到后会响应一个Ack包。当Slave节点发现Master节点没有响应的时候,就会认为Master节点挂了,然后把自己升级为Master节点,并且通知业务进程把消息转发给自己。该方案看起来也是挺完美的,好像不存在什么问题,Slave升级为Master后所有的业务消息都会发给它。

但是,如果在Master内部有一些自己的业务逻辑,比如说随机生成一些业务数据,并且定时存档。那么当Master和Slave之间的网络出现问题的时候,Slave会认为Master挂了,就会升级为Master,同样会执行Master的相应的业务逻辑,同样也会生成一些业务数据回写到DB。但是,其实Master是没有挂的,它同样也在运行对应的业务逻辑(即使业务进程的消息没有发给旧的Master了),这样就会出现两个Master进行写同一份数据了,造成数据的混乱。所以说,该方案并不是一个很好的方案。
那怎么解决可能会出现多个Master的问题?换个角度看,该问题其实就是怎么去裁决哪个节点是Master的问题。
方案一:引入第三方的服务进行裁决
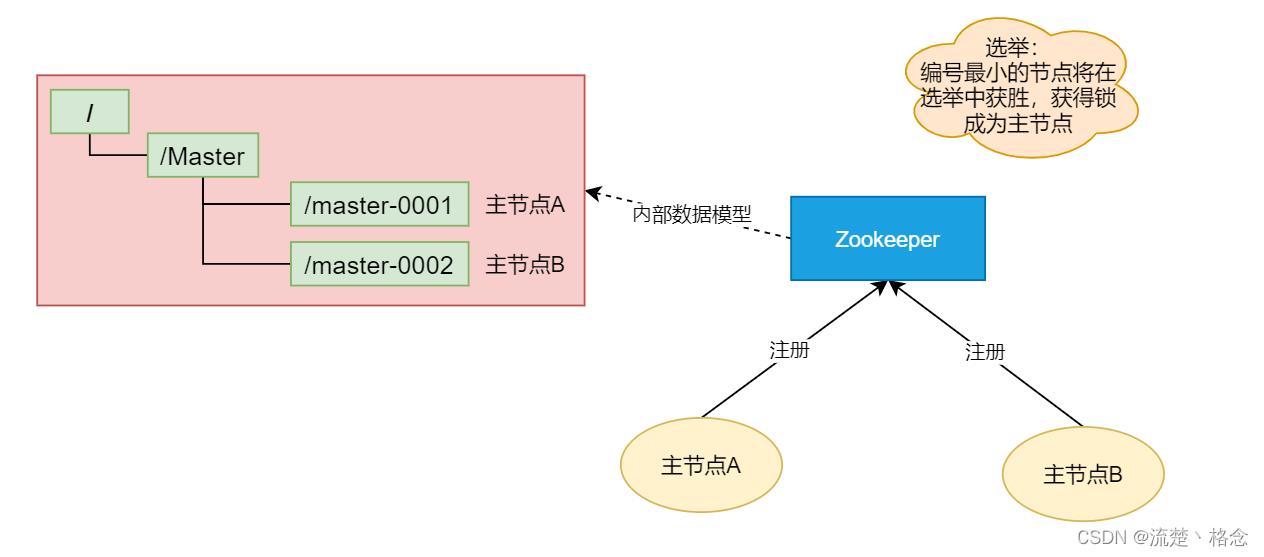
我们可以引入ZooKeeper,由ZooKeeper进行裁决。同样,我们启动两个主节点,“节点A”和节点B。它们启动之后向ZooKeeper去注册一个节点,假设节点A注册的节点为master001,节点B注册的节点为master002,注册完成后进行选举,编号小的节点为真正的主节点。那么,通过这种方式就完成了对两个Master进程的调度。
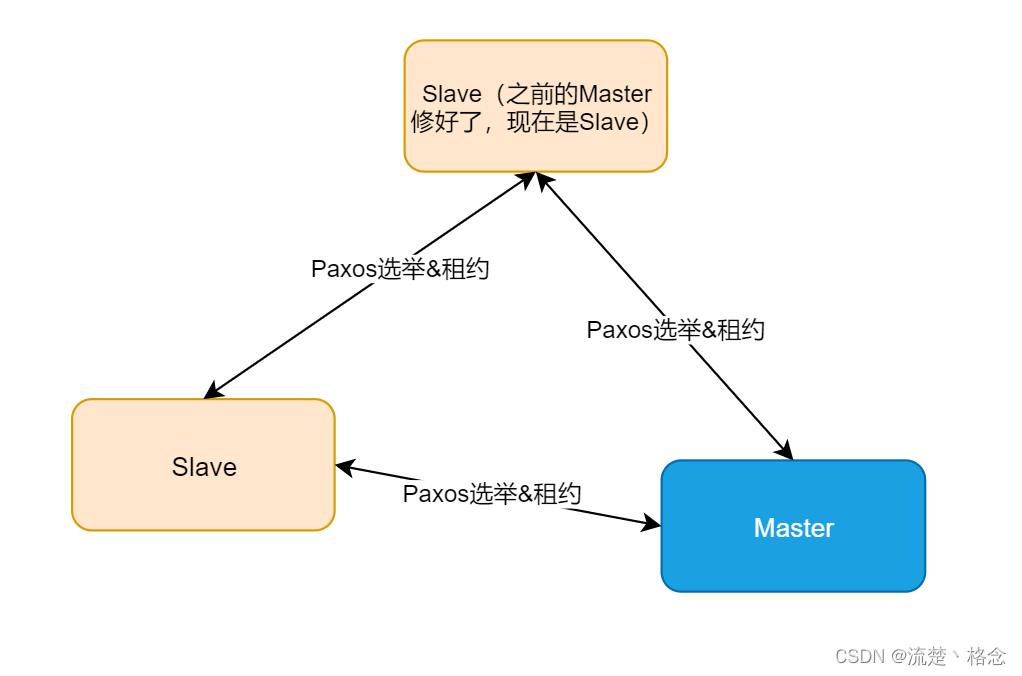
方案二: 通过选举算法和租约的方式实现Master的选举
对于方案一的缺点主要要多维护一套ZooKeeper的服务,如果原本业务上并没有部署该服务的话,要增加该服务的维护也是比较麻烦的事情。这个时候我们可以在业务进程中加入Master的选举方案。目前有比较成熟的选举算法,比如Paxos和Raft。然后再配合租约机制,就可以实现Master的选举,并且确保当前只有一个Master的方案。但是,这些选举算法理解起来并不是那么地容易,要实现一套完善的方案也是挺难的。所以不建议重复造轮子,业内有很多成熟的框架或者组件可以使用,比如微信的PhxPaxos。

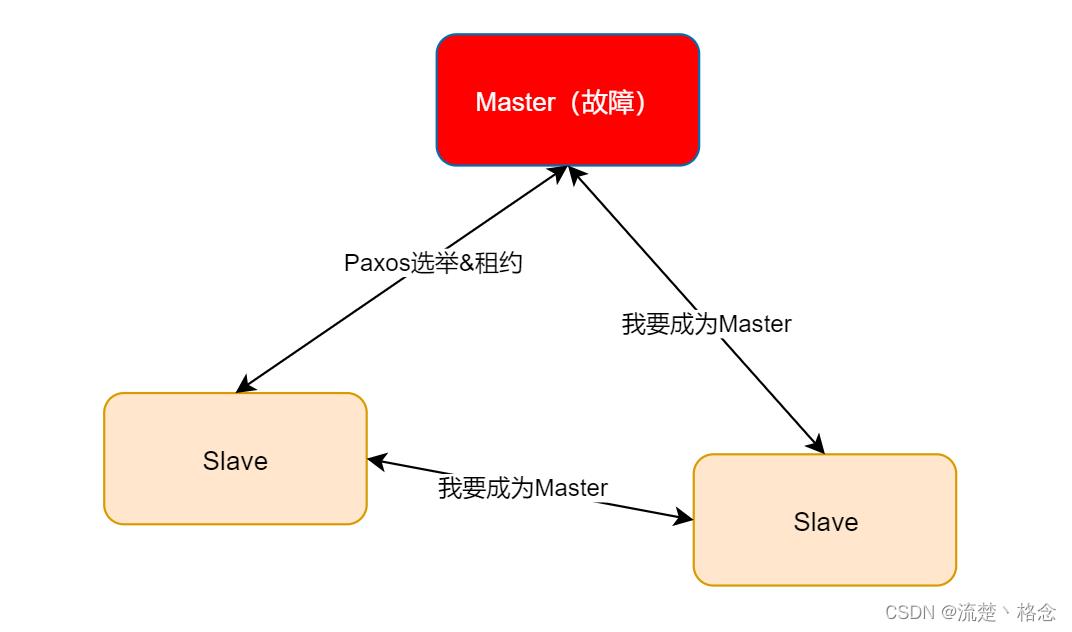
比如上图的方案中,三个节点其实都是对等的,通过选举算法确定一个Master。为了确保任何时候都只能存在一个Matster,需要加入租约的机制。一个节点成为Master后,Master和非Master节点都会进行计时,在超过租约时间后,三个节点后可以发起“我要成为Master”的请求,进行重新选举。
由于三个节点都是对等的,任意一个都可以成为Master,也就是说租期过后,有可能会出现Master切换的情况,所以为了避免Master的频繁切换,Master节点需要比另外两个节点先发起自己要成为Master的请求(续租),告诉其他两个节点我要继续成为Master,然后另外两个节点收到请求后会进行应答,正常情况下另外两个节点会同意该请求。关键点就是,在租约过期之前,非Master节点不能发起“我要成为Master”的请求,这样就可以解决Master频繁切换的问题
另外如果Master节点故障或者宕机,那么其他Slave节点也会发起“我要成为Master”的请求,告诉其他节点当前是Master了,继续进行业务:

以上是关于图解分布式的两种单点问题(有状态服务和无状态服务)的主要内容,如果未能解决你的问题,请参考以下文章