数据分析中如何清洗数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析中如何清洗数据相关的知识,希望对你有一定的参考价值。
参考技术A数据分析中数据集通常包含大量数据,这些数据可能以不易于使用的格式存储。因此,数据分析师首先需要确保数据格式正确并符合规则集。
此外,合并来自不同来源的数据可能很棘手,数据分析师的另一项工作是确保所得到的信息合并有意义。
数据稀疏和格式不一致是最大的挑战–这就是数据清理的全部内容。数据清理是一项任务,用于识别不正确,不完整,不准确或不相关的数据,修复问题,并确保将来会自动修复所有此类问题,数据分析师需要花费60%的时间去组织和清理数据!
数据分析中数据清理有哪些步骤?
以下是经验丰富的开发团队会采用的一些最常见的数据清理步骤和方法:
处理丢失的数据
标准化流程
验证数据准确性
删除重复数据
处理结构错误
摆脱不必要的观察
扩展阅读:
让我们深入研究三种选定的方法:
处理丢失的数据——忽略数据集中的丢失值,是一个巨大的错误,因为大多数算法根本不接受它们。一些公司通过其他观察值推算缺失值或完全丢弃具有缺失值的观察值来解决此问题。但是这些策略会导致信息丢失(请注意,“无价值”也会告诉我们一些信息。如果公司错过了分类数据,则可以将其标记为“缺失”。缺失的数字数据应标记为0,以进行算法估计)在这种情况下的最佳常数。
结构性错误——这些是在测量,传输数据期间出现的错误,以及由于数据管理不善而引起的其他问题。标点符号不一致,错别字和标签错误是这里最常见的问题。这样的错误很好地说明了数据清理的重要性。
不需要的观察——处理数据分析的公司经常在数据集中遇到不需要的观察。这些可以是重复的观察,也可以是与他们要解决的特定问题无关的观察。检查不相关的观察结果是简化工程功能流程的好策略-开发团队将可以更轻松地建立模型。这就是为什么数据清理如此重要的原因。
对于依赖数据维护其运营的企业而言,数据的质量至关重要。举个例子,企业需要确保将正确的发票通过电子邮件发送给合适的客户。为了充分利用客户数据并提高品牌价值,企业需要关注数据质量。
避免代价高昂的错误:
数据清理是避免企业在忙于处理错误,更正错误的数据或进行故障排除时增加的成本的最佳解决方案。
促进客户获取:
保持数据库状态良好的企业可以使用准确和更新的数据来开发潜在客户列表。结果,他们提高了客户获取效率并降低了成本。
跨不同渠道理解数据:
数据分析师们在进行数据清理的过程中清除了无缝管理多渠道客户数据的方式,使企业能够找到成功开展营销活动的机会,并找到达到目标受众的新方法。
改善决策过程:
像干净的数据一样,无助于促进决策过程。准确和更新的数据支持分析和商业智能,从而为企业提供了更好的决策和执行资源。
提高员工生产力:
干净且维护良好的数据库可确保员工的高生产率,他们可以从客户获取到资源规划的广泛领域中利用这些信息。积极提高数据一致性和准确性的企业还可以提高响应速度并增加收入。
R与数据可视化系列如何使用dplyr进行数据清洗和变换
预告:应广大粉丝的要求,“R与数据可视化”专题除了继续沿着“你离R语言大神只有七步之遥”一文中提到的成长路线图前进外,会挑选一些科研论文中的Figure进行解读,并动手用R/Graphpad一步步重现。
如果你有好的论文中的Figure推荐,请在后台给我们留言哦!
另文末有福利哦,快去领取吧!
01
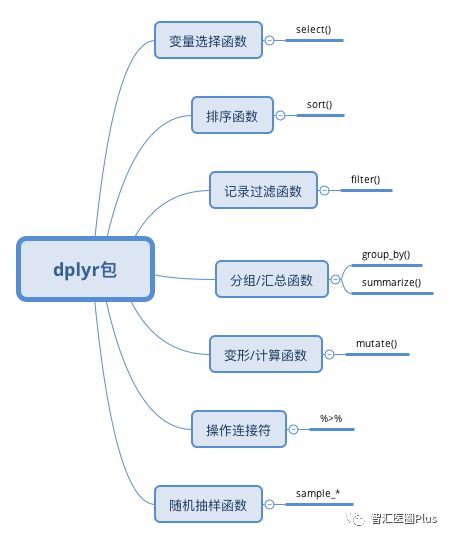
本系列上一期,我们讲了如何用R读入数据(详见文末链接),接下来,我们将介绍如何用dplyr帮助数据清洗和变换。在数据分析工作中,经常需要对原始的数据集进行清洗、整理以及变换。常用的数据整理与变换工作主要包括:选取特定变量、筛选满足条件的数据记录、排序选取的变量、加工处理原始变量并生成新的变量、分组汇总数据,比如计算各组的平均值等。
02
dplyr包是 R大神Hadley Wickham的杰作, 被称之为a grammar of data manipulation。Hadley将plyr 包中的ddply()等函数进一步强化,并以dataframe对象为媒介,大幅提高了数据处理效率和提供了更稳健的与其它数据库对象间交互的接口。
03
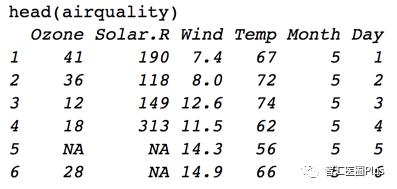
为了演示dplyr的数据处理,我们将使用一个公开数据集,来自于datasets R包中的airquality数据,其包含了纽约市1973年5月-1973年9月的空气质量数据。(后续,我们将陆续转用生物医学类论文中的真实数据进行演示,欢迎大家积极推荐)
04
05
filter函数主要实现数据记录的过滤,亦即返回满足用户指定条件的数据记录。例如:
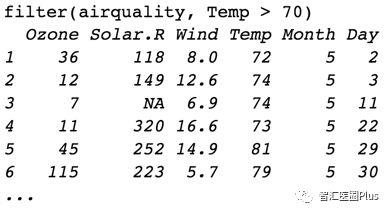
上图中R命令将返回温度大于70的数据记录行(尤其注意,此时数据的格式是列为我们期望操作的变量,而行则为一条条的数据记录)
接下来,我们再看一个多重条件的例子:
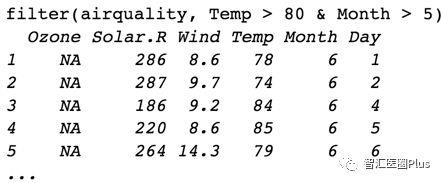
上图中R命令将返回温度大于80且月份大于5的数据记录行;是不是很简单呀?有了这个神器,之前我们需要自己写函数或者多步筛选的都可以一个函数轻松搞定呢!
06
mutate主要用于那些需要依据当前变量生成新变量的场景,是不是脑袋里立马闪现了以前痛苦的经历呀?这种需求还是很多的呢?经常有对数据做个单位转换呀,组合计算新值的需求,用这个就再合适不过了!废话不多说,让我们一起看看怎么用的吧!
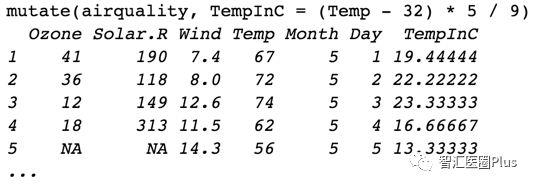
看到了吧,是不是很简单,直接引用列明,像写数学公式一样计算就Okay了,剩下的mutate都会帮你搞定哦!
07
相信,大家对汇总summarise这个函数可能有点陌生,但是对针对某一变量计算均值这类的场景肯定是记忆犹新的。这类需求有的时候是十分惹人烦闷的,各种各种转换格式变来换去之后才能计算个均值,如今在summarise手里轻松搞定!直接上图:

是不是很简洁?后边还有大招哦,让我们一起来看看分组汇总这类需求简单实现折腾的需求在dplyr手里是如何玩出花来的吧!
08
然而我如果想要按月份求出温度均值呢?该咋整?是不是在脑袋里盘算着怎么转换分组再来个循环/apply,通过mean函数计算呢?现在这些统统都不要哦,请看图:

如今只需要将需要分组的变量传给group_by函数,让其帮你分组,然后再结合summarise使用即可哦!简直是So easy,So Hisen!

结语与相关文章
往期精彩回顾


长按左侧二维码关注
智汇医圈
为您解读肿瘤前沿研究资讯和玩转数据的技能,努力传播靠谱的,拒绝卖弄
以上是关于数据分析中如何清洗数据的主要内容,如果未能解决你的问题,请参考以下文章