大数据ClickHouse进阶:ClickHouse使用场景和集群安装
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据ClickHouse进阶:ClickHouse使用场景和集群安装相关的知识,希望对你有一定的参考价值。

文章目录
ClickHouse使用场景和集群安装
一、使用场景
ClickHouse是一个开源的,用于联机分析(OLAP)的列式数据库管理系统(DBMS-database manager system), 它是面向列的,并允许使用SQL查询,实时生成分析报告。ClickHouse最初是一款名为Yandex.Metrica的产品,主要用于WEB流量分析。ClickHouse的全称是Click Stream,Data WareHouse,简称ClickHouse。
ClickHouse使用C++进行编写,具有很多优秀的特点,如在ClickHouse基础篇我们讲解的ClickHouse特性:完备的DBMS功能、列式存储、数据压缩、向量化执行、支持标准SQL、支持20多张表引擎、支持多线程与分布式、多主架构、交互式查询、数据分片与分布式查询等。ClickHouse官网地址由原来的https://ClickHouse.tech改变为https://ClickHouse.com。
ClickHouse适合OLAP数据分析类的场景,数据体量越大,ClickHouse的优势越大。ClickHouse不适合以下场景:
- ClickHouse 不支持事务,事务场景不适合
- 不适合根据主键进行行粒度查询或删除场景(支持但不建议)
二、ClickHouse分布式集群安装
在后期创建表演示ClickHouse高级操作时,必须使用到ClickHouse集群,由于ClickHouse发展非常迅速,几乎每个月都会更新ClickHouse几个版本,与之前的ClickHouse20.8版本相对比,新的ClickHouse版本安装与配置有部分不同, 这里我们选择使用ClickHouse 21.9.4.35版本来重新进行分布式集群搭建,采用rmp包的安装方式。
我们可以从官网给定的下载rpm包的地址下载最新的ClickHouse rpm安装包,地址如下:https://repo.yandex.ru/ClickHouse/rpm/stable/x86_64/
注意:这里从ClickHouse19.4版本之后,只需要下载3个rpm安装包即可,分别如下:
ClickHouse-common-static-21.9.4.35-2.x86_64.rpm
ClickHouse-server-21.9.4.35-2.noarch.rpm
ClickHouse-client-21.9.4.35-2.noarch.rpm1、分布式集群安装
ClickHouse分布式集群安装选择三台节点,分别为node1,node2,node3,详细安装步骤如下:
1.1、选择三台clicsskhouse节点,在每台节点上安装ClickHouse需要的安装包
这里选择node1、node2,node3三台节点,上传安装包,分别在每台节点上执行如下命令安装ClickHouse:
rpm -ivh ./ClickHouse-common-static-21.9.4.35-2.x86_64.rpm
#注意在安装以下rpm包时,让输入密码,可以直接回车跳过
rpm -ivh ./ClickHouse-server-21.9.4.35-2.noarch.rpm
rpm -ivh ClickHouse-client-21.9.4.35-2.noarch.rpm1.2、安装zookeeper集群并启动
搭建ClickHouse集群时,需要使用Zookeeper去实现集群副本之间的同步,所以这里需要zookeeper集群,zookeeper集群安装后可忽略此步骤。
1.3、配置外网可访问
在每台ClickHouse节点中配置/etc/ClickHouse-server/config.xml文件第164行<listen_host>,如下:
<listen_host>::1</listen_host>
#注意每台节点监听的host名称配置当前节点host
<listen_host>node1</listen_host>1.4、在每台节点创建metrika.xml文件,写入以下内容
在node1、node2、node3节点上/etc/ClickHouse-server/config.d路径下下配置metrika.xml文件,默认ClickHouse会在/etc路径下查找metrika.xml文件,但是必须要求metrika.xml上级目录拥有者权限为ClickHouse ,所以这里我们将metrika.xml创建在/etc/ClickHouse-server/config.d路径下,config.d目录的拥有者权限为ClickHouse。
在metrika.xml中我们配置后期使用的ClickHouse集群中创建分布式表时使用3个分片,每个分片有1个副本,配置如下:
vim /etc/ClickHouse-server/config.d/metrika.xml:
<yandex>
<remote_servers>
<ClickHouse_cluster_3shards_1replicas>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node1</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node2</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>node3</host>
<port>9000</port>
</replica>
</shard>
</ClickHouse_cluster_3shards_1replicas>
</remote_servers>
<zookeeper>
<node index="1">
<host>node3</host>
<port>2181</port>
</node>
<node index="2">
<host>node4</host>
<port>2181</port>
</node>
<node index="3">
<host>node5</host>
<port>2181</port>
</node>
</zookeeper>
<macros>
<shard>01</shard>
<replica>node1</replica>
</macros>
<networks>
<ip>::/0</ip>
</networks>
<ClickHouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</ClickHouse_compression>
</yandex>对以上配置文件中配置项的解释如下:
- remote_servers:
ClickHouse集群配置标签,固定写法。注意:这里与之前版本不同,之前要求必须以ClickHouse开头,新版本不再需要。
- ClickHouse_cluster_3shards_1replicas:
配置ClickHouse的集群名称,可自由定义名称,注意集群名称中不能包含点号。这里代表集群中有3个分片,每个分片有1个副本。
分片是指包含部分数据的服务器,要读取所有的数据,必须访问所有的分片。
副本是指存储分片备份数据的服务器,要读取所有的数据,访问任意副本上的数据即可。
- shard:
分片,一个ClickHouse集群可以分多个分片,每个分片可以存储数据,这里分片可以理解为ClickHouse机器中的每个节点,1个分片只能对应1服务节点。这里可以配置一个或者任意多个分片,在每个分片中可以配置一个或任意多个副本,不同分片可配置不同数量的副本。如果只是配置一个分片,这种情况下查询操作应该称为远程查询,而不是分布式查询。
- replica:
每个分片的副本,默认每个分片配置了一个副本。也可以配置多个,副本的数量上限是由ClickHouse节点的数量决定的。如果配置了副本,读取操作可以从每个分片里选择一个可用的副本。如果副本不可用,会依次选择下个副本进行连接。该机制利于系统的可用性。
- internal_replication:
默认为false,写数据操作会将数据写入所有的副本,设置为true,写操作只会选择一个正常的副本写入数据,数据的同步在后台自动进行。
- zookeeper:
配置的zookeeper集群,注意:与之前版本不同,之前版本是“zookeeper-servers”。
- macros:
区分每台ClickHouse节点的宏配置,macros中标签<shard>代表当前节点的分片号,标签<replica>代表当前节点的副本号,这两个名称可以随意取,后期在创建副本表时可以动态读取这两个宏变量。注意:每台ClickHouse节点需要配置不同名称。
- networks:
这里配置ip为“::/0”代表任意IP可以访问,包含IPv4和IPv6。
注意:允许外网访问还需配置/etc/ClickHouse-server/config.xml 参照第三步骤。
- ClickHouse_compression:
MergeTree引擎表的数据压缩设置,min_part_size:代表数据部分最小大小。min_part_size_ratio:数据部分大小与表大小的比率。method:数据压缩格式。
注意:需要在每台ClickHouse节点上配置metrika.xml文件,并且修改每个节点的 macros配置名称。
#node2节点修改metrika.xml中的宏变量如下:
<macros>
<shard>02</replica>
<replica>node2</replica>
</macros>
#node3节点修改metrika.xml中的宏变量如下:
<macros>
<shard>03</replica>
<replica>node3</replica>
</macros>1.5、在每台节点上启动/查看/重启/停止ClickHouse服务
首先启动zookeeper集群,然后分别在node1、node2、node3节点上启动ClickHouse服务,这里每台节点和单节点启动一样。启动之后,ClickHouse集群配置完成。
#每台节点启动Clickchouse服务
service ClickHouse-server start
#每台节点查看ClickHouse服务状态
service ClickHouse-server status
#每台节点重启ClickHouse服务
service ClickHouse-server restart
#每台节点关闭Clikchouse服务
service clickhose-server stop1.6、检查集群配置是否完成
在node1、node2、node3任意一台节点进入ClickHouse客户端,查询集群配置:
#选择三台ClickHouse任意一台节点,进入客户端
ClickHouse-client
#查询集群信息,看到下图所示即代表集群配置成功。
node1 :) select * from system.clusters;
#查询集群信息,也可以使用如下命令
node1 :) select cluster,host_name from system.clusters; 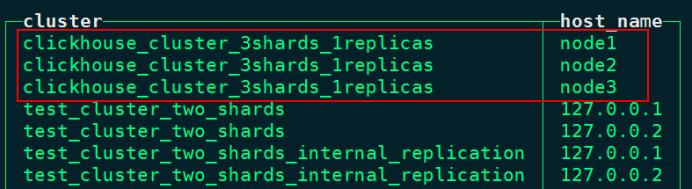
2、ClickHouse目录结构
ClickHouse集群安装完成之后会生成如下对应的目录,每个目录的介绍如下:
- /etc/ClickHouse-server :
服务端的配置文件目录,包括全局配置config.xml 和用户配置users.xml。
- /var/lib/ClickHouse :
默认的数据存储目录,通常会修改,将数据保存到大容量磁盘路径中,此路径可以通过/etc/ClickHouse-server/config.xml配置,配置标签<path>对应的数据。
- /var/log/cilckhouse-server :
默认保存日志的目录,通常会修改,将数据保存到大容量磁盘路径中,此路径可以通过/etc/ClickHouse-server/config.xml配置,配置标签<log>对应的数据。
在/usr/bin下会有可执行文件:
- ClickHouse:主程序可执行文件
- ClickHouse-server:一个指向ClickHouse可执行文件的软连接,供服务端启动使用
- ClickHouse-client:一个指向ClickHouse可执行文件的软连接,供客户端启动使用
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于大数据ClickHouse进阶:ClickHouse使用场景和集群安装的主要内容,如果未能解决你的问题,请参考以下文章
大数据ClickHouse进阶(二十三):ClickHouse用户配置
大数据ClickHouse进阶(二十四):ClickHouse权限管理
大数据ClickHouse进阶:ClickHouse 数据查询
大数据ClickHouse进阶:ClickHouse的with子句