机器学习--数据预处理
Posted Struart_R
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习--数据预处理相关的知识,希望对你有一定的参考价值。
目录
一、无量纲化
1、无量纲化概述
在机器学习中,我们往往将不同规格的数据转换成同一规格相同分布的数据,称为“无量纲化”,在以梯度和矩阵为核心的算法中,如逻辑回归,向量机,神经网络,无量纲化可以加快求解速度;在距离类算法中,如K近邻,K-means聚类中,无量纲化可以用于提升模型精度,避免某一个取值过大的特征值对距离计算产生影响;而在决策树,随机森林,树的集成算法中,对决策树可以无需无量纲化,算法本身就可以处理好任意数据。
数据的无量纲化有线性和非线性的,包括中心化处理和缩放处理,下面将介绍其中重要的归一化和标准化。
2、归一化
数据归一化公式: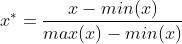
数据归一化后,数据服从正态分布,数据压缩至[0,1]。
2.1MinMaxScaler的重要参数和接口
sklearn中preprocessing.MinMaxScaler实现数据归一化。
重要参数:feature_range,数据归一化后数据的范围,默认为【0,1】。
接口:
| fit | MinMaxScaler的接口,建立模型,参数为用于归一化的数据 |
| fit_transform | MinMaxScaler的接口,输出归一化后数据,参数为用于归一化的数据 |
| transform | fit后的接口,输出归一化后数据,参数为用于归一化的数据 |
| inverse_transform | MinMaxScaler的接口,输出归一化前数据,参数为归一化后数据 |
2.2归一化代码演示
from sklearn.preprocessing import MinMaxScaler #数据归一化
data=[
[-1,2]
,[-0.5,6]
,[0,10]
,[1,18]
]
scaler=MinMaxScaler(feature_range=[5,10]) #实例化(feature_range为范围)
scaler_fit=scaler.fit(data) #模型,如果fit报错特征值过多无法计算可用partial_fit
result=scaler_fit.transform(data) #输出接口
print(result)
print(scaler.fit_transform(data)) #fit和transform的综合
print(scaler.inverse_transform(result)) #逆转归一化3、标准化
数据标准化公式: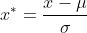
数据标准化后会服从均值为0,方差为1的正态分布。
sklearn中preprocessing.StandardScaler实现数据标准化,一般参数不添加,其接口和归一化相同,不予介绍。
3.1标准化代码演示
from sklearn.preprocessing import StandardScaler #标准化库
scaler_=StandardScaler()
result_=scaler_.fit_transform(data) #建立模型,并输出接口
print(result_)
print(scaler_.inverse_transform(result_)) #逆转标准化二、缺失值
由于机器学习中的数据不一定是完美的,存在缺失值现象,但又不能完全舍弃缺失值的数据,所以可以通过数据预处理处理缺失值。
下面案例利用泰坦尼克号幸存者数据集:
1、利用pandas补充缺失值
import pandas as pd #导入pandas
titanic = pd.read_csv('titanic.csv')
print(titanic.head()) #显示titanic数据集前五行
titanic.loc[:,'Age']=titanic.loc[:,'Age'].fillna(titanic.loc[:,'Age'].median()) #利用中位数,对Age列数据进行填补缺失值
print(titanic.loc[:,'Age'])
print(titanic.dropna(axis=0,inplace=False).info()) #inplace为False为生成新的副本进行dropna
print(titanic.info()) #显示数据概况2、利用sklearn补充缺失值
2.1impute.SimpleImputer重要参数
sklearn中impute.SimpleImputer实现补充缺失值。
| missing_values | 告诉数据缺失值的类型,默认为np.nan |
| strategy | 填补缺失值的策略,默认为均值; 输入“mean”为使用均值填补; 输入“median”为使用中位数填补; 输入“constant”为使用常数填补,参考参数fill_value的值; 输入“most_frequent”为使用众数填补,对字符型和数值型特征均可用 |
| fill_value | 当strategy参数为constant时,可输入字符串或数字表示要填充的值,常用为0 |
| copy | 是否创建特征矩阵的副本,默认为True |
impute.SimpleImputer中的重要接口与数据归一化类似,不予介绍
2.2填充缺失值代码演示
注意:填充缺失值,需使用二维矩阵类型,提取DataFrame类的某一列后,应加入.value.reshape(-1,1)进行升维操作。
from sklearn.impute import SimpleImputer #填补缺失值
titanic_=pd.read_csv('titanic.csv')
titanic_=titanic_.loc[:,'Age'].values.reshape(-1,1) #sklearn只能用二维特征矩阵,原数据提取loc后为Series类,values提取值列,reshape进行升维
print(titanic_.shape)
imp_mean=SimpleImputer() #SimpleImputer实例化,默认为用平均值填充
imp_mean=imp_mean.fit_transform(titanic_) #可以把数据的预处理当作一种建立模型,fit
print(imp_mean) #输出填充缺失值后的数据
imp_mid=SimpleImputer(strategy='median') #用中位数填充
imp_mid=imp_mid.fit_transform(titanic_)
print(imp_mid)
imp_s=SimpleImputer(strategy='constant',fill_value=0) #用常数0填充
imp_s=imp_s.fit_transform(titanic_)
print(imp_s)三、编码与哑变量
1、编码概述
由于在机器学习中,逻辑回归,支持向量机,K近邻算法等都只能够处理数值型文字,其他大多数算法,都只能通过处理数组或者矩阵的方式来建立模型,而现实中大多数标签和特征都为文字表现,所以必须通过编码的方式,将文字型数据转化为数值型。
2、LabelEncoder
对不连续的数字或文字进行编码,处理标签专用。(不能同时处理几列数据,即数组形式不能用来处理)
LabelEncoder编码可以输入一维数据,而不用进行升维。
from sklearn.preprocessing import LabelEncoder #导入标签编码库
titanic_=pd.read_csv('titanic.csv')
lbl=LabelEncoder() #LabelEncoder类
data=titanic_.loc[:,'Sex'] #数据使用titanic中Sex一列
lbl=lbl.fit_transform(data) #建立模型并输出数据
print(lbl)3、OrdinalEncoder
多维特征或数组,矩阵用OrdinalEncoder编码
OrdinalEncoder编码可以输入DataFrame对象而无需.toarray()转换为矩阵。
其中,OrdinalEncoder( ).fit(data).categories_可以显示编码类别,也可以利用set的方式来显示。编码类别显示如下:
[array(['female', 'male'], dtype=object), array(['C', 'Q', 'S'], dtype=object)]
from sklearn.preprocessing import OrdinalEncoder #导入ordinal编码库
odl=OrdinalEncoder()
print(odl.fit(titanic_.loc[:,['Sex','Embarked']]).categories_) #显示编码类别
odl=odl.fit_transform(titanic_.loc[:,['Sex','Embarked']]) #建立模型并输出
print(odl)
4、OneHotEncoder
独热编码,创建哑变量,即创建二进制列稀疏矩阵。如性别列,利用独热编码创建为[0,1],[1,0]。利用OrdinalEncoder创建为[0],[1]。
独热编码类的参数主要使用categories,一般参数设为auto;
OnehotEncoder().fit(data).get_feature_names()等价于OrdinalEncoder中的categories_,返回编码列表。
独热编码训练后模型一定要利用.toarray()转换为矩阵类型,不然不能导入原数据中
from sklearn.preprocessing import OneHotEncoder #独热编码
data_x=pd.read_csv('titanic.csv')
x=data_x.iloc[:,2:4] #利用Sex,Embarked进行独热编码
print(x)
enc=OneHotEncoder(categories='auto')
result=enc.fit_transform(x).toarray() #训练模型后转化为矩阵类型
print(result)
print(enc.fit(x).get_feature_names()) #与ordinal编码中categories的作用相同,显示编码的分类类别
x=pd.concat([data_x,pd.DataFrame(result)],axis=1) #将编码后数据合并到原数据,并删除原文字数据
x=x.drop(columns=['Sex','Embarked'],axis=1,inplace=False)
print(x.head())
print()
x.columns=['Survived','Age','x0_female','x0_male','x1_C','x1_Q','x1_S'] #修改其列标签
print(x.head())四、分箱
分箱一般分为等宽分箱,等频分箱,聚类分箱三种方式。
等频分箱是指按总数据个数的频率来分箱,等宽分箱是指按总数据值得范围作为单位“1”,按频率进行分箱。
1、二分分箱
sklearn中,preprocessing.Binarizer可以实现二分分箱。
其主要参数为threshold,类型为整型或浮点型,表示二分分箱的分割线位置
from sklearn.preprocessing import Binarizer #导入二分分箱库
trans=Binarizer(threshold=30).fit_transform(imp_mid) #使用上文年龄列补充后的数据
x.loc[:,'Age']=trans #将分箱后的数据放回原数据,并显示前五行
print(x.head())2、K分箱
sklearn中,preprocessing.KBinsDiscretizer可以实现等频分箱。
2.1重要参数
| n_bins | 每个特征的分箱个数,默认为5,一次会被用于导入的所有特征 |
| encode | 编码方式,默认为“onehot” "onehot":哑变量编码,稀疏矩阵 "ordinal":ordinal编码,返回矩阵 "onehot-dense":哑变量编码,返回密集矩阵 |
| strategy | 定义箱宽的方式,默认为"quantile" "uniform":等宽分箱 "quantile":等位或等频分箱 "kmeans":聚类分箱,每个箱的值到最近的一维k均值聚类的簇心的距离相同 |
使用独热编码分箱后仍需要.toarray()转换为矩阵形式。
2.2代码演示
from sklearn.preprocessing import KBinsDiscretizer #导入分箱库
est=KBinsDiscretizer(n_bins=3,encode='onehot',strategy='uniform') #独热编码,等宽分箱,分箱数量3
print('imp_mid:\\n',imp_mid) #导入上文年龄补充缺失值后数据
est=est.fit_transform(imp_mid).toarray()
print(est)
以上是关于机器学习--数据预处理的主要内容,如果未能解决你的问题,请参考以下文章