评测指标(metrics)
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了评测指标(metrics)相关的知识,希望对你有一定的参考价值。
评测指标(metrics)
metric主要用来评测机器学习模型的好坏程度,不同的任务应该选择不同的评价指标, 分类,回归和排序问题应该选择不同的评价函数. 不同的问题应该不同对待,即使都是 分类问题也不应该唯评价函数论,不同问题不同分析.
回归(Regression)
- 均方误差(MSE)
(1) l ( y , y ^ ) = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 l(y, \\haty)=\\frac1n\\sum_i=1^n(y_i-\\haty_i)^2 \\tag1 l(y,y^)=n1i=1∑n(yi−y^i)2(1)
- 均方根误差(RMSE)
(2) l ( y , y ^ ) = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 l(y, \\haty)=\\sqrt\\frac1n\\sum_i=1^n(y_i-\\haty_i)^2 \\tag2 l(y,y^)=n1i=1∑n(yi−y^i)2(2)
- 平均绝对误差(MAE)
(3) l ( y , y ^ ) = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ l(y, \\haty)=\\frac1n\\sum_i=1^n|y_i-\\haty_i| \\tag3 l(y,y^)=n1i=1∑n∣yi−y^i∣(3)
- R Squared
(4) R 2 = 1 − ( ∑ i = 1 n ( y i − y ^ i ) 2 ) / n ( ∑ i = 1 n ( y i − y ˉ i ) 2 ) / n R^2=1-\\frac(\\sum_i=1^n(y_i-\\hatyi)^2)/n(\\sumi=1^n(y_i-\\bary_i)^2)/n \\tag4 R2=1−(∑i=1n(yi−yˉi)2)/n(∑i=1n(yi−y^i)2)/n(4)
其中: y ^ \\haty y^是预测值, y y y是真实值, n n n是样本个数, y ˉ \\bary yˉ是 y y y的平均值.
分类(Classification)
- 准确率和错误率
(5) a c c ( y , y ^ ) = 1 n ∑ i = 1 n y i = y i ^ acc(y,\\haty)=\\frac1n\\sum_i=1^ny_i=\\haty_i \\tag5 acc(y,y^)=n1i=1∑nyi=yi^(5)
(6) e r r o r ( y , y ^ ) = 1 − a c c ( y , y ^ ) error(y, \\haty)=1-acc(y,\\haty) \\tag6 error(y,y^)=1−acc(y,y^)(6)
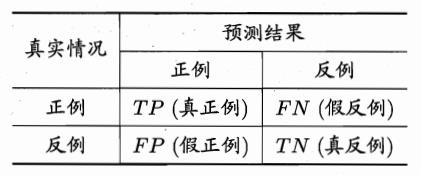
- 混淆矩阵,精准率和召回率
对于二分类问题,可将样例根据其真是类别与学习器预测类别的组合划分为真正例(true positive, TP),假正例(false positive, FP),真反例(ture negative, TN),假反例(false negative, FN), 则有:TP+FP+TN+FN=样例总数. 分类结果的混淆矩阵(confusion matrix)如下:
则有精准率P和召回率R定义如下: (7) P = T P T P + F P P=\\fracTPTP+FP \\tag7 P=TP+FPTP(7)
(8) R = T P T P + F N R=\\fracTPTP+FN \\tag8 R=TP+FNTP(8)
则F1值定义如下: (9) 1 F 1 = 1 2 ⋅ ( 1 P + 1 R ) \\frac1F_1=\\frac12 \\cdot (\\frac1P+\\frac1R) \\tag9 F11=21⋅(P1+R1)(9)
(10) F 1 = 2 P R P + R F_1=\\frac2PRP+R \\tag10 F1=以上是关于评测指标(metrics)的主要内容,如果未能解决你的问题,请参考以下文章