KELM分类基于matlab鲸鱼算法优化KELM分类含Matlab源码 2033期
Posted 海神之光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KELM分类基于matlab鲸鱼算法优化KELM分类含Matlab源码 2033期相关的知识,希望对你有一定的参考价值。
一、鲸鱼算法简介
1 鲸鱼优化算法(Whale Optimization Algorithm,WOA)简介
鲸鱼优化算法(WOA),该算法模拟了座头鲸的社会行为,并引入了气泡网狩猎策略。
1.1 灵感
鲸鱼被认为是世界上最大的哺乳动物。一头成年鲸可以长达 30 米,重 180 吨。这种巨型哺乳动物有 7 种不同的主要物种,如虎鲸,小须鲸,鳁鲸,座头鲸,露脊鲸,长须鲸和蓝鲸等。鲸通常被认为是食肉动物,它们从不睡觉,因为它们必须到海洋表面进行呼吸,但事实上,鲸鱼有一半的大脑都处于睡眠状态。
鲸鱼在大脑的某些区域有与人类相似的细胞,这些细胞被称为纺锤形细胞(spindle cells)。这些细胞负责人类的判断、情感和社会行为。换句话说,纺锤形细胞使我们人类有别于其他生物。鲸鱼的这些细胞数量是成年人的两倍,这是它们具有高度智慧和更富情感的主要原因。已经证明,鲸鱼可以像人类一样思考、学习、判断、交流,甚至变得情绪化,但显然,这都只是在一个很低的智能水平上。据观察,鲸鱼(主要是虎鲸)也能发展自己的方言。
另一个有趣的点是关于鲸鱼的社会行为,它们可独居也可群居,但我们观察到的大多数仍然是群居。它们中的一些物种(例如虎鲸)可以在整个生命周期中生活在一个家族中。最大的须鲸之一是座头鲸,一头成年座头鲸几乎和一辆校车一样大。它们最喜欢的猎物是磷虾和小鱼群。图1显示的就是这种哺乳动物。
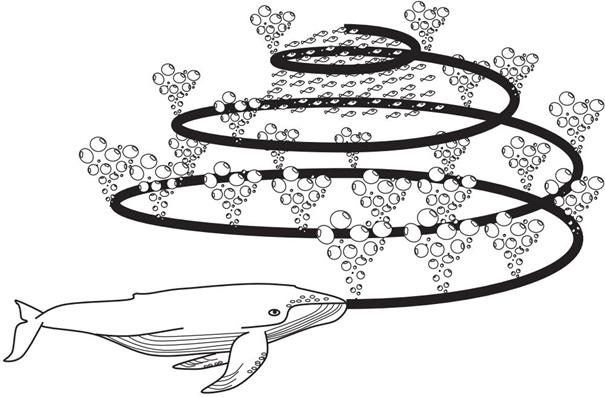
图1 座头鲸的气泡网进食行为
关于座头鲸最有趣的事情是它们特殊的捕猎方法了。这种觅食行为被称为气泡网觅食法(bubble-net feeding method)。座头鲸喜欢在接近海面的地方捕食磷虾或小鱼。据观察,这种觅食是通过在圆形或类似数字“9”形路径上制造独特的气泡来完成的,如图 1 所示。在 2011 年之前,这一行为仅仅是基于海面观测的。然而,有研究者利用标签传感器研究了这种行为。他们捕获了9头座头鲸身上300个由标签得到的气泡网进食事件。他们发现了两种与气泡有关的策略,并将它们命名为上升螺旋(upward-spirals)和双螺旋(doubleloops)。在前一种策略中,座头鲸会潜到水下 12 米左右,然后开始在猎物周围制造一个螺旋形的泡泡,并游向水面;后一种策略包括三个不同的阶段:珊瑚循环,用尾叶拍打水面以及捕获循环。这里不展开详细描述。
但是气泡网捕食是只有座头鲸独有的一种特殊行为,而鲸鱼优化算法就是模拟了螺旋气泡网进食策略达到优化的目的。
1.2 数学建模和优化算法
1.2.1 包围捕食(Encircling prey)
座头鲸可以识别猎物的位置并将其包围。由于最优设计在搜索空间中的位置不是先验已知的,WOA 算法假设当前的最佳候选解是目标猎物或接近最优解。在定义了最佳搜索代理之后,其他搜索代理将因此尝试向最佳搜索代理更新它们的位置。这种行为由下列方程表示:




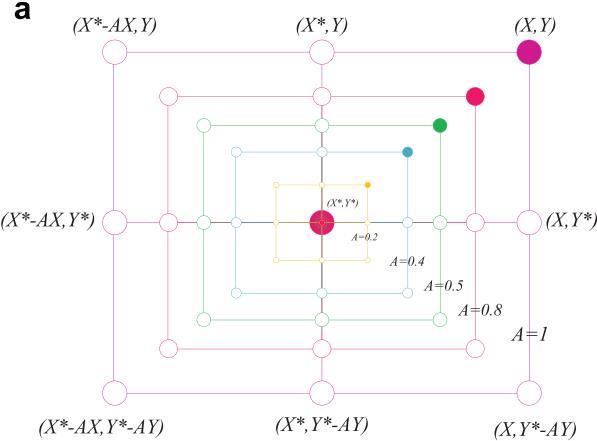
图 2a 描述了等式(2)针对2D问题的基本原理,搜索代理的位置( X , Y )可以根据当前最优解的位置( X ∗ , Y ∗ )进行更新,通过调整向量 A ⃗ 和C的值,可以找到相对于当前位置下一时刻最优代理附近的不同地方。在 3D 空间中搜索代理可能的更新位置如图 2b。通过定义随机向量 r ,可以到达图 2 中所示关键点之间的搜索空间内任何位置,因此等式(2)允许任何搜索代理在当前最优解的邻域内更新其位置,从而模拟了鲸鱼的包围捕食。相似的概念也可以扩展到 n 维搜索空间。注意图2中的两幅图均是在a=1和C=1情况下的。
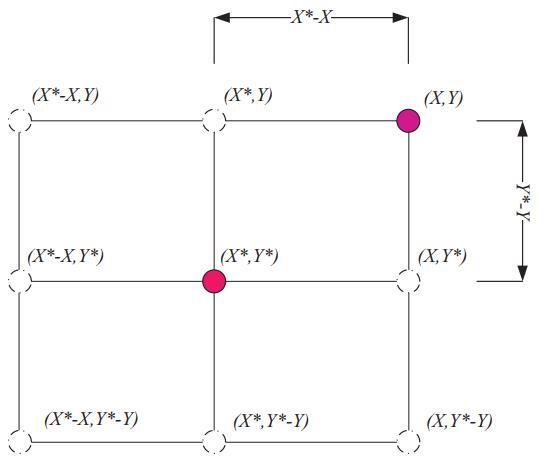
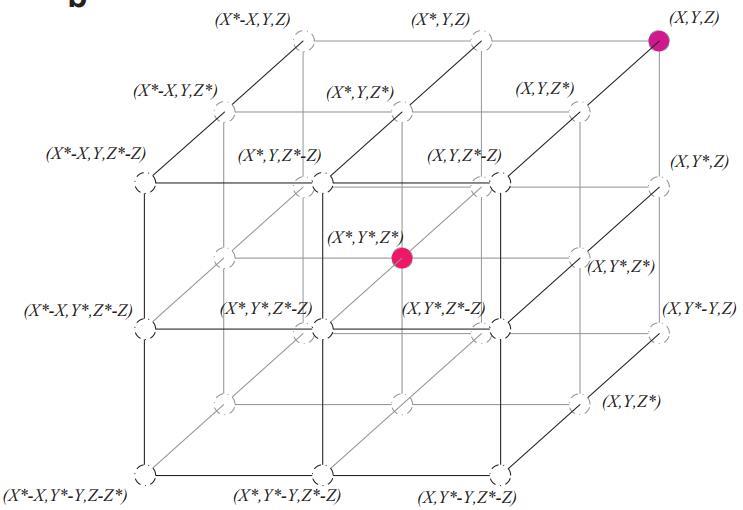
图2 2D和3D位置向量及其可能的下一个位置
1.2.2 气泡网攻击方式(Bubble-net attacking method)(利用阶段)
共设计了两种方法来对座头鲸的气泡网行为进行建模:
收缩包围机制:通过降低式(3)中 a 的值实现。注意 A的波动范围也通过 a降低,换句话说,A 是一个区间[-a,a]内的随机值,a 随着迭代进行从 2 降为 0。设置 A中的随机值在[-1,1]之间,搜索代理的新位置可以定义为代理原始位置与当前最优代理位置之间的任意位置。图 3a 显示了 2D 空间中当 0 ≤ A ≤ 1 0 时从 ( X , Y )靠近 ( X ∗ , Y ∗ ) 所有可能的位置。这种机制本质上就是包围捕食。
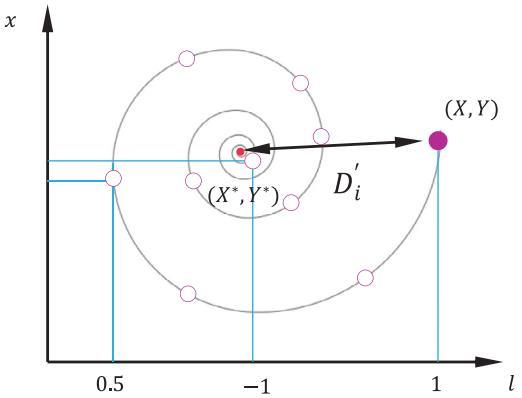
螺旋更新位置。如图 3b,该方法首先计算鲸鱼位置 ( X , Y ) 与猎物位置 ( X ∗ , Y ∗ ) 之间的距离,然后在鲸鱼与猎物位置之间创建一个螺旋等式,来模仿座头鲸的螺旋状移动:
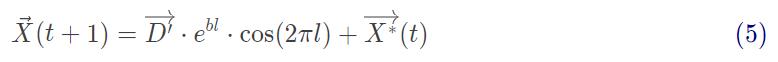

(a)收缩包围机制
(b)螺旋更新位置
图3 WOA中实现的气泡网搜索机制
值得注意的是,座头鲸在一个不断缩小的圆圈内绕着猎物游动,同时沿着螺旋形路径游动。为了对这种同时发生的行为进行建模,假设有 50%的可能性在收缩包围机制和螺旋模型之间进行选择,以便在优化过程中更新鲸鱼的位置,数学模型如下:
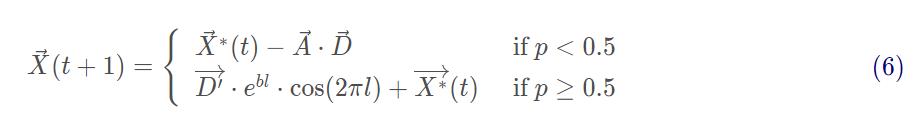
其中 p pp 为[0,1]之间的随机数。
1.2.3搜索猎物(Search for prey)(exploration phase)
除了泡泡网方法,座头鲸还会随机寻找猎物,同样基于可变 A向量,事实上,座头鲸会根据彼此的位置进行随机搜索,因此使用随机值大于1或小于-1的 A ⃗ 来迫使搜索代理远离参考鲸鱼。与利用阶段相反,这里将根据随机选择的搜索代理来更新搜索代理在探索阶段的位置,而不是根据目前为止最优的搜索代理。该机制和 ∣ A ⃗ ∣ > 1 强调了探索,并允许WOA算法执行全局搜索。数学模型如下:


其中 X → r a n d 为从当前种群中选择的随机位置向量(表示一头随机鲸鱼)。
特定解附近满足 A ⃗ > 1的一些可能解如图 4 所示。
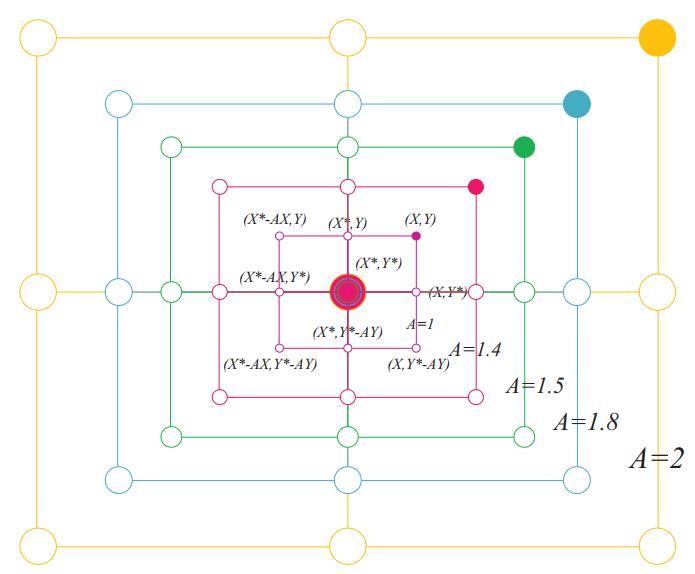
图4 WOA中的探索机制(X*是一个随机选择的搜索代理)
WOA算法首先随机初始化一组解,在每次迭代中,搜索代理根据随机选择的搜索代理或到目前为止获得的最优解更新它们的位置。将 a aa 参数由 2 随迭代次数降为 0,从而由探索逐步到利用。当 ∣ A ⃗ ∣ > 1 时选择随机搜索代理,∣ A ⃗ ∣ < 1 时选择最优解更新搜索代理位置。根据 p pp 的值,WOA可以在螺旋运动和圆环运动之间进行切换。最后,通过满足终止准则来终止WOA算法。WOA算法的伪代码如图5所示。

图5 WOA算法伪代码
1.3 代码分析
只要明白了原理的基本流程,其实代码就没有说明困难了,咱们主要介绍一下如何实现上述分析的几个重要原理,所要优化的问题的是三十个数的平方和最小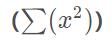
(1)参数初始化。初始时主要设置代理数量和最大迭代次数即可,其他算法相关的参数因为和当前迭代次数相关,需要在迭代中设置。
SearchAgents_no=30; % 搜索代理数量
Max_iteration=500; % 最大迭代次数
``
**(2) 种群初始化**。随机初始化所有代理各个维度上的位置值,需要保证在取值范围内。
```c
Positions=rand(SearchAgents_no,dim).*(ub-lb)+lb;
(3)种群评估。评估种群中每个代理的目标值,如有某个代理由于当前最优解,则将其设为最优解。
for i=1:size(Positions,1)
% 计算每个代理的目标值
fitness=fobj(Positions(i,:));
% 更新最优解
if fitness<Leader_score % 如果是最大化问题,这里就是">"
Leader_score=fitness;
Leader_pos=Positions(i,:);
end
end
(4)设置和迭代次数相关的算法参数。
a=2-t*((2)/Max_iter); % 等式(3)中a随迭代次数从2线性下降至0
%a2从-1线性下降至-2,计算l时会用到
a2=-1+t*((-1)/Max_iter);
(5)对每个代理的每一维度进行位置更新。
% Update the Position of search agents
for i=1:size(Positions,1)
r1=rand(); % r1为[0,1]之间的随机数
r2=rand(); % r2为[0,1]之间的随机数
A=2*a*r1-a; % 等式(3)
C=2*r2; % 等式(4)
b=1; % 等式(5)中的常数b
l=(a2-1)*rand+1; % 等式(5)中的随机数l
p = rand(); % 等式(6)中的概率p
for j=1:size(Positions,2)
if p<0.5
if abs(A)>=1
rand_leader_index = floor(SearchAgents_no*rand()+1);
X_rand = Positions(rand_leader_index, :);
D_X_rand=abs(C*X_rand(j)-Positions(i,j)); % 等式(7)
Positions(i,j)=X_rand(j)-A*D_X_rand; % 等式(8)
elseif abs(A)<1
D_Leader=abs(C*Leader_pos(j)-Positions(i,j)); % 等式(1)
Positions(i,j)=Leader_pos(j)-A*D_Leader; % 等式(2)
end
elseif p>=0.5
distance2Leader=abs(Leader_pos(j)-Positions(i,j));
% 等式(5)
Positions(i,j)=distance2Leader*exp(b.*l).*cos(l.*2*pi)+Leader_pos(j);
end
end
end
二、部分代码
clear;close all;clc;format compact;
%%
load DTCWPT_WPT
train_data=[];
test_data=[];
train_label=[];
test_label=[];
for i=1:10
data0=WP_all_alldatai;
n=randperm(50);
train_data=[train_data;data0(n(1:20)😅];
train_label=[train_label;iones(20,1)];
test_data=[test_data;data0(n(21:end)😅];
test_label=[test_label;iones(30,1)];
end
P_train=train_data;
P_test=test_data;
clear WP_all_alldata data0 n i
% 将标签转换为one-hot编码
T_train=zeros(200,10);
T_test=zeros(300,10);
for i=1:200
T_train(i,train_label(i))=1;
end
for i=1:300
T_test(i,test_label(i))=1;
end
clear i train_label test_label
%%
kernel=‘RBF_kernel’;
% [pop,trace]=woaforkelm(kernel,P_train,T_train,P_test,T_test);%鲸鱼算法
[pop,trace]=vnwoaforkelm(kernel,P_train,T_train,P_test,T_test);%改进鲸鱼算法
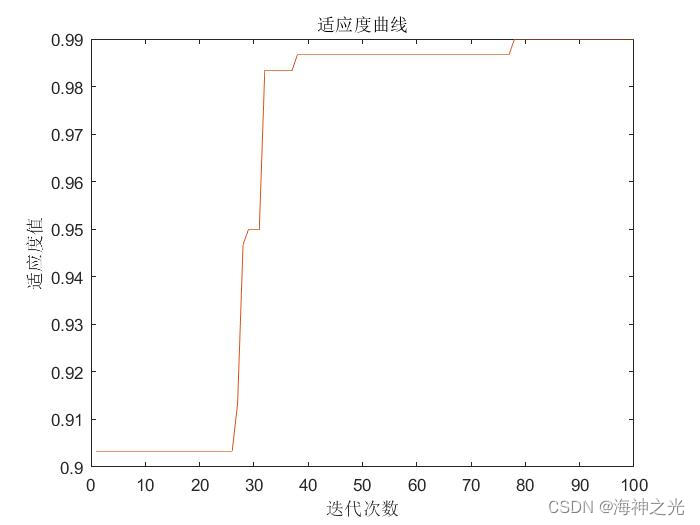
figure
plot(trace)
xlabel(‘迭代次数’)
ylabel(‘适应度值’)
title(‘适应度曲线’)
hold on
plot(trace)
%%
% 训练过程
n_sample=size(T_train,1);%样本数
Omega_train = kernel_matrix(P_train,kernel, pop(1));%隐含层输出
OutputWeight=((Omega_train+speye(n_sample)/pop(2))(T_train));
Y1=Omega_train * OutputWeight;
% 测试过程
Omega_test = kernel_matrix(P_train,kernel, pop(1),P_test)’;
Yt_hat=Omega_test * OutputWeight;%actual output
[~,J]=max(Yt_hat,[],2);
[~,J1]=max(T_test,[],2);
acc=sum(J==J1)/300
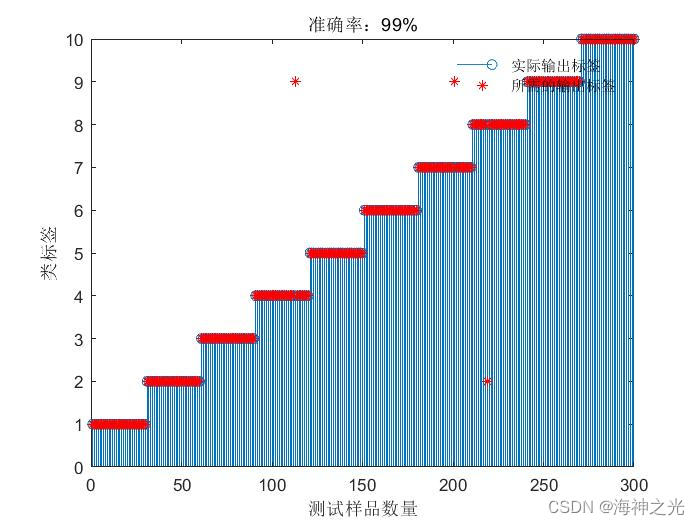
figure;
stem(J1);
hold on;
plot(J, ‘r*’);
% xlabel(‘样品编号’)
% ylabel(‘样本标签’)
% legend(‘真实标签’, ‘预测标签’);
% title([‘KELM分类精度为:’,num2str(acc100),’%’])
xlabel(‘测试样品数量’);
ylabel(‘类标签’);
legend(‘实际输出标签’,‘所需的输出标签’);
title([‘准确率:’,num2str(acc100),’%’]);
legend(‘boxoff’);
hold off;
三、运行结果
四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1] 包子阳,余继周,杨杉.智能优化算法及其MATLAB实例(第2版)[M].电子工业出版社,2016.
[2]张岩,吴水根.MATLAB优化算法源代码[M].清华大学出版社,2017.
3 备注
简介此部分摘自互联网,仅供参考,若侵权,联系删除
以上是关于KELM分类基于matlab鲸鱼算法优化KELM分类含Matlab源码 2033期的主要内容,如果未能解决你的问题,请参考以下文章
回归预测基于matlab鲸鱼算法WOA优化混合核极限学习机KELM回归预测含Matlab源码 JQ004期
KELM预测基于粒子群算法改进核极限学习机(KELM)分类算法 matlab源码
KELM预测基于粒子群算法改进核极限学习机(KELM)分类算法 matlab源码
回归预测基于matlab麻雀算法SSA优化混合核KELM回归预测含Matlab源码 1646期