关于Android性能监控Matrix那些事?你知道那些(中)?
Posted 初一十五啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于Android性能监控Matrix那些事?你知道那些(中)?相关的知识,希望对你有一定的参考价值。
昨天更新了关于Android性能监控Matrix那些事?你知道那些(上)?
说的的视频也更新了:微信Matrix卡顿监控实战,函数自动埋点监控方案


今天我们接着聊下文:
4.
Hprof文件分析
5.卡顿监控
6.卡顿监控源码解析
7.插桩
8.资源优化
9.I/O监控及原理解析
四丶Hprof 文件分析
4.1.Hprof文件格式
Hprof 文件使用的基本数据类型为:u1、u2、u4、u8,分别表示 1 byte、2 byte、4 byte、8 byte 的
内容,由文件头和文件内容两部分组成。
其中,文件头包含以下信息:
文件内容由一系列 records 组成,每一个 record 包含如下信息:

查看 hprof.cc 可知,Hprof 文件定义的 TAG 有:
enum HprofTag
HPROF_TAG_STRING = 0x01, // 字符串
HPROF_TAG_LOAD_CLASS = 0x02, // 类
HPROF_TAG_UNLOAD_CLASS = 0x03,
HPROF_TAG_STACK_FRAME = 0x04, // 栈帧
HPROF_TAG_STACK_TRACE = 0x05, // 堆栈
HPROF_TAG_ALLOC_SITES = 0x06,
HPROF_TAG_HEAP_SUMMARY = 0x07,
HPROF_TAG_START_THREAD = 0x0A,
HPROF_TAG_END_THREAD = 0x0B,
HPROF_TAG_HEAP_DUMP = 0x0C, // 堆
HPROF_TAG_HEAP_DUMP_SEGMENT = 0x1C,
HPROF_TAG_HEAP_DUMP_END = 0x2C,
HPROF_TAG_CPU_SAMPLES = 0x0D,
HPROF_TAG_CONTROL_SETTINGS = 0x0E,
;
需要重点关注的主要是三类信息:
- 字符串信息:保存着所有的字符串,在解析时可通过索引 id 引用
- 类的结构信息:包括类内部的变量布局,父类的信息等等
- 堆信息:内存占用与对象引用的详细信息
如果是堆信息,即 TAG 为 HEAP_DUMP 或 HEAP_DUMP_SEGMENT 时,那么其 BODY 由一系列子record 组成,这些子 record 同样使用 TAG 来区分:
enum HprofHeapTag
// Traditional.
HPROF_ROOT_UNKNOWN = 0xFF,
HPROF_ROOT_JNI_GLOBAL = 0x01, // native 变量
HPROF_ROOT_JNI_LOCAL = 0x02,
HPROF_ROOT_JAVA_FRAME = 0x03,
HPROF_ROOT_NATIVE_STACK = 0x04,
HPROF_ROOT_STICKY_CLASS = 0x05,
HPROF_ROOT_THREAD_BLOCK = 0x06,
HPROF_ROOT_MONITOR_USED = 0x07,
HPROF_ROOT_THREAD_OBJECT = 0x08,
HPROF_CLASS_DUMP = 0x20, // 类
HPROF_INSTANCE_DUMP = 0x21, // 实例对象
HPROF_OBJECT_ARRAY_DUMP = 0x22, // 对象数组
HPROF_PRIMITIVE_ARRAY_DUMP = 0x23, // 基础类型数组
// android.
HPROF_HEAP_DUMP_INFO = 0xfe,
HPROF_ROOT_INTERNED_STRING = 0x89,
HPROF_ROOT_FINALIZING = 0x8a, // Obsolete.
HPROF_ROOT_DEBUGGER = 0x8b,
HPROF_ROOT_REFERENCE_CLEANUP = 0x8c, // Obsolete.
HPROF_ROOT_VM_INTERNAL = 0x8d,
HPROF_ROOT_JNI_MONITOR = 0x8e,
HPROF_UNREACHABLE = 0x90, // Obsolete.
HPROF_PRIMITIVE_ARRAY_NODATA_DUMP = 0xc3, // Obsolete.
;
每一个 TAG 及其对应的内容可参考 HPROF Agent,比如,String record 的格式如下:

因此,在读取 Hprof 文件时,如果 TAG 为 0x01,那么,当前 record 就是字符串,第一部分信息是字符串 ID,第二部分就是字符串的内容。
4.2.Hprof 文件裁剪
Matrix 的 Hprof 文件裁剪功能的目标是将 Bitmap 和 String 之外的所有对象的基础类型数组的值移除,因为 Hprof 文件的分析功能只需要用到字符串数组和 Bitmap 的 buffer 数组。另一方面,如果存在不同的 Bitmap 对象其 buffer 数组值相同的情况,则可以将它们指向同一个 buffer,以进一步减小文件尺寸。裁剪后的 Hprof 文件通常比源文件小 1/10 以上。
代码结构和 ASM 很像,主要由 HprofReader、HprofVisitor、HprofWriter 组成,分别对应 ASM 中的ClassReader、ClassVisitor、ClassWriter。HprofReader 用于读取 Hprof 文件中的数据,每读取到一种类型(使用 TAG 区分)的数据,就交给一系列 HprofVisitor 处理,最后由 HprofWriter 输出裁剪后的文件(HprofWriter 继承自HprofVisitor)。
裁剪流程如下:
// 裁剪
public void shrink(File hprofIn, File hprofOut) throws IOException
// 读取文件
final HprofReader reader = new HprofReader(new BufferedInputStream(is));
// 第一遍读取
reader.accept(new HprofInfoCollectVisitor());
// 第二遍读取
is.getChannel().position(0);
reader.accept(new HprofKeptBufferCollectVisitor());
// 第三遍读取,输出裁剪后的 Hprof 文件
is.getChannel().position(0);
reader.accept(new HprofBufferShrinkVisitor(new HprofWriter(os)));
可以看到,Matrix 为了完成裁剪功能,需要对输入的 hprof 文件重复读取三次,每次都由一个对应的Visitor 处理。
4.2.1.读取HProf文件
HprofReader 的源码很简单,先读取文件头,再读取 record,根据 TAG 区分 record 的类型,接着按照 HPROF Agent 给出的格式依次读取各种信息即可,读取完成后交给 HprofVisitor 处理。
读取文件头:
// 读取文件头
private void acceptHeader(HprofVisitor hv) throws IOException
final String text = IOUtil.readNullTerminatedString(mStreamIn); // 连续读取数 据,直到读取到 null
mIdSize = IOUtil.readBEInt(mStreamIn); // int 是 4 字节
final long timestamp = IOUtil.readBELong(mStreamIn); // long 是 8 字节
hv.visitHeader(text, idSize, timestamp); // 通知 Visitor
读取 record(以字符串为例):
// 读取文件内容
private void acceptRecord(HprofVisitor hv) throws IOException
while (true)
final int tag = mStreamIn.read(); // TAG 区分类型
final int timestamp = IOUtil.readBEInt(mStreamIn); // 时间戳
final long length = IOUtil.readBEInt(mStreamIn) & 0x00000000FFFFFFFFL; // Body 字节长
switch (tag)
case HprofConstants.RECORD_TAG_STRING: // 字符串
acceptStringRecord(timestamp, length, hv);
break;
... // 其它类型
// 读取 String record
private void acceptStringRecord(int timestamp, long length, HprofVisitor hv)
throws IOException
final ID id = IOUtil.readID(mStreamIn, mIdSize); // IdSize 在读取文件头时确定
final String text = IOUtil.readString(mStreamIn, length - mIdSize); // Body 字节长减去 IdSize 剩下的就是字符串内容
hv.visitStringRecord(id, text, timestamp, length);
4.2.2.记录 Bitmap 和 String 类信息
为了完成上述裁剪目标,首先需要找到 Bitmap 及 String类,及其内部的 mBuffer、value 字段,这也是裁剪流程中的第一个 Visitor 的作用:记录 Bitmap 和 String 类信息。
包括字符串 ID:
// 找到 Bitmap、String 类及其内部字段的字符串 ID
public void visitStringRecord(ID id, String text, int timestamp, long length)
if (mBitmapClassNameStringId == null && "android.graphics.Bitmap".equals(text))
mBitmapClassNameStringId = id;
else if (mMBufferFieldNameStringId == null && "mBuffer".equals(text))
mMBufferFieldNameStringId = id;
else if (mMRecycledFieldNameStringId == null && "mRecycled".equals(text))
mMRecycledFieldNameStringId = id;
else if (mStringClassNameStringId == null && "java.lang.String".equals(text))
mStringClassNameStringId = id;
else if (mValueFieldNameStringId == null && "value".equals(text))
mValueFieldNameStringId = id;
Class ID:
// 找到 Bitmap 和 String 的 Class ID
public void visitLoadClassRecord(int serialNumber, ID classObjectId, int
stackTraceSerial, ID classNameStringId, int timestamp, long length)
if (mBmpClassId == null && mBitmapClassNameStringId != null && mBitmapClassNameStringId.equals(classNameStringId))
mBmpClassId = classObjectId;
else if (mStringClassId == null && mStringClassNameStringId != null && mStringClassNameStringId.equals(classNameStringId))
mStringClassId = classObjectId;
以及它们拥有的字段:
// 记录 Bitmap 和 String 类的字段信息
public void visitHeapDumpClass(ID id, int stackSerialNumber, ID superClassId, ID
classLoaderId, int instanceSize, Field[] staticFields, Field[] instanceFields)
if (mBmpClassInstanceFields == null && mBmpClassId != null && mBmpClassId.equals(id))
mBmpClassInstanceFields = instanceFields;
else if (mStringClassInstanceFields == null && mStringClassId != null && mStringClassId.equals(id))
mStringClassInstanceFields = instanceFields;
第二个 Visitor 用于记录所有 String 对象的 value ID:
// 如果是 String 对象,则添加其内部字段 "value" 的 ID
public void visitHeapDumpInstance(ID id, int stackId, ID typeId, byte[] instanceData)
if (mStringClassId != null && mStringClassId.equals(typeId))
if(mValueFieldNameStringId.equals(fieldNameStringId))
strValueId = (ID) IOUtil.readValue(bais, fieldType, mIdSize);
mStringValueIds.add(strValueId);
以及 Bitmap 对象的 Buffer ID 与其对应的数组本身:
// 如果是 Bitmap 对象,则添加其内部字段 "mBuffer" 的 ID
public void visitHeapDumpInstance(ID id, int stackId, ID typeId, byte[] instanceData)
if (mBmpClassId != null && mBmpClassId.equals(typeId))
if (mMBufferFieldNameStringId.equals(fieldNameStringId))
bufferId = (ID) IOUtil.readValue(bais, fieldType, mIdSize);
mBmpBufferIds.add(bufferId);
// 保存 Bitmap 对象的 mBuffer ID 及数组的映射关系
public void visitHeapDumpPrimitiveArray(int tag, ID id, int stackId, int numElements, int typeId, byte[] elements)
mBufferIdToElementDataMap.put(id, elements);
接着分析所有 Bitmap 对象的 buffer 数组,如果其 MD5 相等,说明是同一张图片,就将这些重复的buffer ID 映射起来,以便之后将它们指向同一个 buffer 数组,删除其它重复的数组:
final String buffMd5 = DigestUtil.getMD5String(elementData);
final ID mergedBufferId = duplicateBufferFilterMap.get(buffMd5); // 根据该 MD5 值 对应的 buffer id
if (mergedBufferId == null) // 如果 buffer id 为空,说明是一张新的图片
duplicateBufferFilterMap.put(buffMd5, bufferId);
else // 否则是相同的图片,将当前的 Bitmap buffer 指向之前保存的 buffer id,以便之后删 除重复的图片数据
mBmpBufferIdToDeduplicatedIdMap.put(mergedBufferId, mergedBufferId);
mBmpBufferIdToDeduplicatedIdMap.put(bufferId, mergedBufferId);
4.2.3.裁剪 Hprof 文件数据
将上述数据收集完成之后,就可以输出裁剪后的文件了,裁剪后的 Hprof 文件的写入功能由HprofWriter 完成,代码很简单,HprofReader 读取到数据之后就由 HprofWriter 原封不动地输出到新的文件即可,唯二需要注意的就是 Bitmap 和基础类型数组。
先看 Bitmap,在输出 Bitmap 对象时,需要将相同的 Bitmap 数组指向同一个 buffer ID,以便接下来剔除重复的 buffer 数据:
// 将相同的 Bitmap 数组指向同一个 buffer ID
public void visitHeapDumpInstance(ID id, int stackId, ID typeId, byte[] instanceData)
if (typeId.equals(mBmpClassId))
ID bufferId = (ID) IOUtil.readValue(bais, fieldType, mIdSize);
// 找到共同的 buffer id
final ID deduplicatedId = mBmpBufferIdToDeduplicatedIdMap.get(bufferId);
if (deduplicatedId != null && !bufferId.equals(deduplicatedId) && !bufferId.equals(mNullBufferId))
modifyIdInBuffer(instanceData, bufferIdPos, deduplicatedId);
// 修改完毕后再写入到新文件中
super.visitHeapDumpInstance(id, stackId, typeId, instanceData);
// 修改成对应的 buffer id
private void modifyIdInBuffer(byte[] buf, int off, ID newId)
final ByteBuffer bBuf = ByteBuffer.wrap(buf);
bBuf.position(off);
bBuf.put(newId.getBytes());
对于基础类型数组,如果不是 Bitmap 中的 mBuffer 字段或者 String 中的 value 字段,则不写入到新
文件中:
public void visitHeapDumpPrimitiveArray(int tag, ID id, int stackId, int numElements, int typeId, byte[] elements)
final ID deduplicatedID = mBmpBufferIdToDeduplicatedIdMap.get(id);
// 如果既不是 Bitmap 中的 mBuffer 字段, 也不是 String 中的 value 字段,则舍弃该数据
// 如果当前 id 不等于 deduplicatedID,说明这是另一张重复的图片,它的图像数据不需要重复 输出
if (!id.equals(deduplicatedID) && !mStringValueIds.contains(id))
return; // 直接返回,不写入新文件中
super.visitHeapDumpPrimitiveArray(tag, id, stackId, numElements, typeId, elements);
4.3.总结
4.3.1Hprof 文件格式
Hprof 文件由文件头和文件内容两部分组成,文件内容由一系列 records 组成,record 的类型则通过TAG 来区分。
Hprof 文件格式示意图:

文件头:

record:

其中文件内容需要关注的主要是三类信息:
- 字符串信息:保存着所有的字符串,在解析时可通过索引 id 引用
- 类的结构信息:包括类内部的变量布局,父类的信息等等
- 堆信息:内存占用与对象引用的详细信息
4.3.2.Hprof 文件裁剪
Matrix 的 Hprof 文件裁剪功能的目标是将 Bitmap 和 String 之外的所有对象的基础类型数组的值移除,因为 Hprof 文件的分析功能只需要用到字符串数组和 Bitmap 的 buffer 数组。另一方面,如果存在不同的 Bitmap 对象其 buffer 数组值相同的情况,则可以将它们指向同一个 buffer,以进一步减小文件尺寸。裁剪后的 Hprof 文件通常比源文件小 1/10 以上。
Hprof 文件裁剪功能的代码结构和 ASM 很像,主要由 HprofReader、HprofVisitor、HprofWriter 组成,HprofReader 用于读取 Hprof 文件中的数据,每读取到一种类型(使用 TAG 区分)的数据(即record),就交给一系列 HprofVisitor 处理,最后由 HprofWriter 输出裁剪后的文件(HprofWriter 继承自 HprofVisitor)。
裁剪流程如下:
- 读取
Hprof文件 - 记录
Bitmap和String类信息 - 移除
Bitmap buffer和String value之外的基础类型数组 - 将同一张图片的
Bitmap buffer指向同一个buffer id,移除重复的Bitmap buffer - 其它数据原封不动地输出到新文件中需要注意的是,
Bitmap的mBuffer字段在 API 26 被移除了,因此Matrix无法分析 API 26 以上的设备的重复Bitmap。
五丶卡顿监控
5.1.使用
Matrix 中负责卡顿监控的组件是 TraceCanary,它是基于 ASM 插桩实现的,用于监控界面流畅性、启动耗时、页面切换耗时、慢函数及卡顿等问题。和 ResourceCanary 类似,使用前需要配置如下,主要包括帧率、耗时方法、ANR、启动等选项:
TraceConfig traceConfig = new TraceConfig.Builder()
.dynamicConfig(dynamicConfig)
.enableFPS(fpsEnable) // 帧率
.enableEvilMethodTrace(traceEnable) // 耗时方法
.enableAnrTrace(traceEnable) // ANR
.enableStartup(traceEnable) // 启动
.splashActivities("sample.tencent.matrix.SplashActivity;") // 可指定多个启 动页,使用分号 ";" 分割
.isDebug(true)
.isDevEnv(false)
.build();
TracePlugin tracePlugin = new TracePlugin(traceConfig);
接着在 Application / Activity 中启动即可:
tracePlugin.start();
除了以上配置之外,Trace Canary 还有如下自定义的配置选项:
enum ExptEnum
// trace
clicfg_matrix_trace_care_scene_set, // 闪屏页
clicfg_matrix_trace_fps_time_slice, // 如果同一 Activity 掉帧数 * 16.66ms > time_slice,就上报,默认为 10s
clicfg_matrix_trace_evil_method_threshold, // 慢方法的耗时阈值,默认为 700ms
clicfg_matrix_fps_dropped_normal, // 正常掉帧数,默认 [3, 9)
clicfg_matrix_fps_dropped_middle, // 中等掉帧数,默认 [9, 24)
clicfg_matrix_fps_dropped_high, // 高掉帧数,默认 [24, 42)
clicfg_matrix_fps_dropped_frozen, // 卡顿掉帧数,默认 [42, ~)
clicfg_matrix_trace_app_start_up_threshold, // 冷启动时间阈值,默认 10s
clicfg_matrix_trace_warm_app_start_up_threshold, // 暖启动时间阈值,默认 4s
####5.2. 报告
相比内存泄漏,卡顿监控报告的信息复杂了很多。
5.2.1.ANR
出现 ANR 时,Matrix 上报信息如下:
"tag": "Trace_EvilMethod",
"type": 0,
"process": "sample.tencent.matrix",
"time": 1590397340910,
"machine": "HIGH", // 设备等级
"cpu_app": 0.001405802921652454, // 应用占用的 CPU 时间比例,appTime/cpuTime * 100
"mem": 3030949888, // 设备总运行内存
"mem_free": 1695964, // 设备可用的运行内存,不绝对,可能有部分已经被系统内核使用
"detail": "ANR",
"cost": 5006, // 方法执行总耗时
"stackKey": "30|", // 关键方法
"scene": "sample.tencent.matrix.trace.TestTraceMainActivity", "stack": "0,1048574,1,5006\\n1,15,1,5004\\n2,30,1,5004\\n", // 方法执行关键路径
"threadStack": " \\nat android.os.SystemClock:sleep(120)\\nat
sample.tencent.matrix.trace.TestTraceMainActivity:testInnerSleep(234)\\nat
sample.tencent.matrix.trace.TestTraceMainActivity:testANR(135)\\nat
sample.tencent.matrix.trace.TestTraceMainActivity:testANR(135)\\nat
java.lang.reflect.Method:invoke(-2)\\nat
android.view.View$DeclaredOnClickListener:onClick(4461)\\nat android.view.View:performClick(5212)\\nat
android.view.View$PerformClick:run(21214)\\nat
android.os.Handler:handleCallback(739)\\nat
android.os.Handler:dispatchMessage(95)\\nat
android.os.Looper:loop(148)\\nat
android.app.ActivityThread:main(5619)\\n", // 线程堆栈
"processPriority": 20, // 进程优先级
"processNice": 0, // 进程的 nice 值
"isProcessForeground": true, // 应用是否可见
"memory":
"dalvik_heap": 17898, // 虚拟机中已分配的 Java 堆内存,kb
"native_heap": 6796, // 已分配的本地内存,kb
"vm_size": 858132, // 虚拟内存大小,指进程总共可访问的地址空间,kb
其中,设备分级如下:
BEST,内存大于等于 4 GHIGH,内存大于等于 3G,或内存大于等于 2G 且 CPU 核心数大于等于 4 个MIDDLE,内存大于等于 2G 且 CPU 核心数大于等于 2 个,或内存大于等于 1G 且 CPU 核心数大
于等于 4 个LOW,内存大于等于 1GBAD,内存小于 1G
5.2.2.启动
正常启动情况下:
"tag": "Trace_StartUp",
"type": 0,
"process": "sample.tencent.matrix",
"time": 1590405971796,
"machine": "HIGH",
"cpu_app": 2.979125443261738E-4,
"mem": 3030949888,
"mem_free": 1666132,
"application_create": 35, // 应用启动耗时
"application_create_scene": 100, // 启动场景
"first_activity_create": 318, // 第一个 activity 启动耗时
"startup_duration": 2381, // 启动总耗时
"is_warm_start_up": false, // 是否是暖启动
其中,application_create、first_activity_create、startup_duration 分别对应 applicationCost、firstScreenCost、coldCost:

启动场景分为 4 种:
- 100,
Activity拉起的 - 114,
Service拉起的 - 113,
Receiver拉起的 - -100,未知,比如
ContentProvider
如果是启动过慢的情况:
"tag": "Trace_EvilMethod",
"type": 0,
"process": "sample.tencent.matrix",
"time": 1590407016547,
"machine": "HIGH",
"cpu_app": 3.616498950411638E-4,
"mem": 3030949888,
"mem_free": 1604416,
"detail": "STARTUP",
"cost": 2388,
"stack":
"0,2,1,43\\n1,121,1,0\\n1,1,8,0\\n2,99,1,0\\n0,1048574,1,0\\n0,1048574,1,176\\n1,15,1, 144\\n0,1048574,1,41\\n",
"stackKey": "2|",
"subType": 1 // 1 代表冷启动,2 代表暖启动
5.2.3.慢方法
"tag": "Trace_EvilMethod",
"type": 0,
"process": "sample.tencent.matrix",
"time": 1590407411286,
"machine": "HIGH",
"cpu_app": 8.439117339531338E-4,
"mem": 3030949888,
"mem_free": 1656536,
"detail": "NORMAL", "cost": 804, // 方法执行总耗时
"usage": "0.37%", // 在方法执行总时长中,当前线程占用的 CPU 时间比例
"scene": "sample.tencent.matrix.trace.TestTraceMainActivity",
"stack": "0,1048574,1,804\\n1,14,1,803\\n2,29,1,798\\n",
"stackKey": "29|"
5.2.4.帧率
在出现掉帧的情况时,Matrix 上报信息如下:
"tag": "Trace_FPS",
"type": 0,
"process": "sample.tencent.matrix",
"time": 1590408900258,
"machine": "HIGH",
"cpu_app": 0.0030701181354057853,
"mem": 3030949888,
"mem_free": 1642296,
"scene": "sample.tencent.matrix.trace.TestFpsActivity",
"dropLevel": // 不同级别的掉帧问题出现的次数
"DROPPED_FROZEN": 0,
"DROPPED_HIGH": 0,
"DROPPED_MIDDLE": 3,
"DROPPED_NORMAL": 14,
"DROPPED_BEST": 451
,
"dropSum": // 不同级别的掉帧问题对应的总掉帧数
"DROPPED_FROZEN": 0,
"DROPPED_HIGH": 0,
"DROPPED_MIDDLE": 41,
"DROPPED_NORMAL": 57,
"DROPPED_BEST": 57
,
"fps": 46.38715362548828, // 帧率
"dropTaskFrameSum": 0 // 意义不明,正常情况下值总是为 0
5.3.原理介绍
开头说到,Matrix 的卡顿监控是基于 ASM 插桩实现的,其原理是通过代理编译期间的任务transformClassesWithDexTask,将全局 class 文件作为输入,利用 ASM 工具对所有 class 文件进行扫描及插桩,插桩的意思是在每一个方法的开头处插入AppMethodBeat.i 方法,在方法的结尾处插入AppMethodBeat.o 方法,并记录时间戳,这样就能知道该方法的执行耗时。
插桩过程有几个关键点:
- 选择在编译任务执行时插桩,是因为
proguard操作是在该任务之前就完成的,意味着插桩时的class文件已经被混淆过的。而选择proguard之后去插桩,是因为如果提前插桩会造成部分方法不符合内联规则,没法在proguard时进行优化,最终导致程序方法数无法减少,从而引发方法数过大问题 - 为了减少插桩量及性能损耗,通过遍历
class方法指令集,判断扫描的函数是否只含有PUT/READ``FIELD等简单的指令,来过滤一些默认或匿名构造函数,以及get/set等简单不耗时函数。 - 针对界面启动耗时,因为要统计从
Activity#onCreate到Activity#onWindowFocusChange间的耗时,所以在插桩过程中需要收集应用内所有Activity的实现类,并覆盖onWindowFocusChange函数进行打点。 - 为了方便及高效记录函数执行过程,
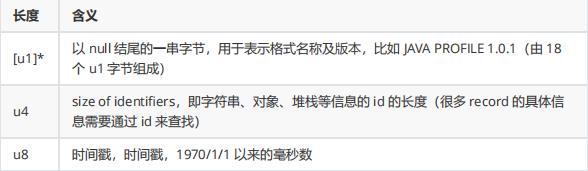
Matrix为每个插桩的函数分配一个独立 ID,在插桩过程中,记录插桩的函数签名及分配的 ID,在插桩完成后输出一份mapping,作为数据上报后的解析支持。为了优化内存使用,method id及时间戳是通过一个long数组记录的,格式如下:
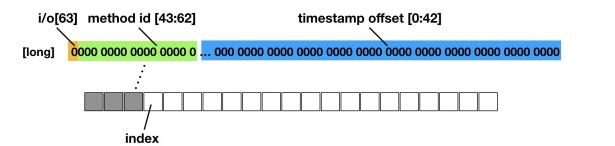
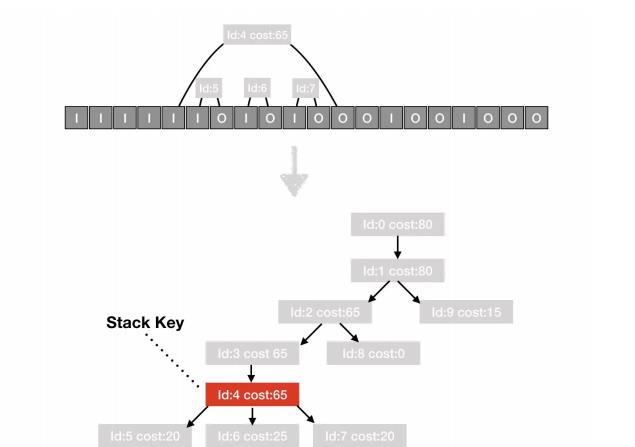
堆栈聚类问题: 如果将收集的原始数据进行上报,数据量很大而且后台很难聚类有问题的堆栈,所以在上报之前需要对采集的数据进行简单的整合及裁剪,并分析出一个能代表卡顿堆栈的 key,方便后台聚合。具体的方法是通过遍历采集的 buffer ,相邻 i 与 o 为一次完整函数执行,计算出一个调用树及每个函数执行耗时,并对每一级中的一些相同执行函数做聚合,最后通过一个简单策略,分析出主要耗时的那一级函数,作为代表卡顿堆栈的key
帧率监控的方法是向 Choreographer 注册监听,在每一帧 doframe 回调时判断距离上一帧的时间差是否超出阈值(卡顿),如果超出阈值,则获取数组 index 前的所有数据(即两帧之间的所有函数执行信息)进行分析上报。
ANR 监控则更简单,在每一帧 doFrame 到来时,重置一个定时器,并往 buffer 数组里插入一个结点,如果 5s 内没有 cancel,则认为发生了 ANR,从之前插入的结点开始,到最后一个结点,收集中间执行过的方法数据,可以认为导致 ANR 的关键方法就在这里面,计算时间戳即可得到关键方法。
另外,考虑到每个方法执行前后都获取系统时间(System.nanoTime)会对性能影响比较大,而实际上,单个函数执行耗时小于 5ms 的情况,对卡顿来说不是主要原因,可以忽略不计,如果是多次调用的情况,则在它的父级方法中可以反映出来,所以为了减少对性能的影响,Matrix 创建了一条专门用于更新时间的线程,每 5ms 去更新一个时间变量,而每个方法执行前后只读取该变量来减少性能损耗。
六丶卡顿监控源码解析
6.1.监控主线程
TraceCanary 模块只能在 API 16 以上的设备运行,内部分为 ANR、帧率、慢方法、启动四个监测模块,核心接口是 LooperObserver。
LooperObserver 是一个抽象类,顾名思义,它是 Looper 的观察者,在 Looper 分发消息、刷新 UI 时回调,这几个回调方法也是 ANR、慢方法等模块的判断依据:
public abstract class LooperObserver
// 分发消息前
@CallSuper
public void dispatchBegin(long beginMs, long cpuBeginMs, long token)
// UI 刷新
public void doFrame(String focusedActivityName, long start, long end, long frameCostMs, long inputCostNs, long animationCostNs, long traversalCostNs)
// 分发消息后
@CallSuper
public void dispatchEnd(long beginMs, long cpuBeginMs, long endMs, long cpuEndMs, long token, boolean isBelongFrame)
6.1.1.Looper监控
Looper 的监控是由类 LooperMonitor 实现的,原理很简单,为主线程 Looper 设置一个 Printer 即可,但值得一提的是,LooperMonitor 不会直接设置 Printer,而是先获取旧对象,并创建代理对象,避免影响到其它用户设置的 Printer:
private synchronized void resetPrinter()
Printer originPrinter = ReflectUtils.get(looper.getClass(), "mLogging", looper);;
looper.setMessageLogging(printer = new LooperPrinter(originPrinter));
class LooperPrinter implements Printer
@Override
public void println(String x)
if (null != origin)
origin.println(x); // 保证原对象正常执行
dispatch(x.charAt(0) == '>', x); // 分发,通过第一个字符判断是开始分发,还是结 束分发
6.1.2.UI刷新监控
UI 刷新监控是基于 Choreographer 实现的,TracePlugin 初始化时,UIThreadMoniter 就会通过反射的方式往 Choreographer 添加回调:
public class UIThreadMonitor implements BeatLifecycle, Runnable
// Choreographer 中一个内部类的方法,用于添加回调
private static final String ADD_CALLBACK = "addCallbackLocked";
// 回调类型,分别为输入事件、动画、View 绘制三种
public static final int CALLBACK_INPUT = 0;
public static final int CALLBACK_ANIMATION = 1;
public static final int CALLBACK_TRAVERSAL = 2;
public void init(TraceConfig config)
choreographer = Choreographer.getInstance();
// 回调队列
callbackQueues = reflectObject(choreographer, "mCallbackQueues");
// 反射,找到在 Choreographer 上添加回调的方法
addInputQueue = reflectChoreographerMethod(callbackQueues[CALLBACK_INPUT], ADD_CALLBACK, long.class, Object.class, Object.class);
addAnimationQueue = reflectChoreographerMethod(callbackQueues[CALLBACK_ANIMATION], ADD_CALLBACK, long.class, Object.class, Object.class);
addTraversalQueue = reflectChoreographerMethod(callbackQueues[CALLBACK_TRAVERSAL], ADD_CALLBACK, long.class, Object.class, Object.class);
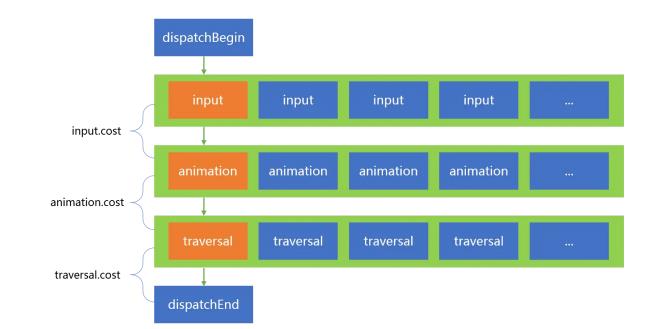
之所以通过反射的方式实现,而不是通过 postCallback,是为了把我们的 callback 放到头部,这样才能计算系统提交的输入事件、动画、View 绘制等事件的耗时。
这样,等 Choreographer 监听到 vsync 信号时,UIThreadMonitor 和系统添加的回调都会被执行(比如在绘制 View 的时候,系统会往Choreographer 添加一个 traversal callback):
public final class Choreographer
private final class FrameDisplayEventReceiver extends DisplayEventReceiver implements Runnable
@Override
public void run()
doFrame(mTimestampNanos, mFrame);
void doFrame(long frameTimeNanos, int frame)
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos); ...
...
因为 UIThreadMonitor 添加的回调在队列头部,可用于记录开始时间,而其它系统方法,比如 View 的postOnAnimation 添加的回调在后面,因此所有同类型回调执行完毕后,就可以计算对应的事件(输入事件、动画、View 绘制等)的耗时。
6.2.ANR监控
ANR 监控原理:在 Looper 分发消息时,往后台线程插入一个延时(5s 后执行)任务,Looper 消息分发完毕后就删除,如果过了 5s,该任务未被删除,就认为出现了 ANR。
public class AnrTracer extends Tracer
// onAlive 时初始化,onDead 时退出
private Handler anrHandler;
private volatile AnrHandleTask anrTask;
public void dispatchBegin(long beginMs, long cpuBeginMs, long token)
// 插入方法结点,如果出现了 ANR,就从该结点开始收集方法执行记录
anrTask = new
AnrHandleTask(AppMethodBeat.getInstance().maskIndex("AnrTracer#dispatchBegin"), token);
// 5 秒后执行
// token 和 beginMs 相等,因此后一个减式用于减去回调该方法过程中所消耗的时间
anrHandler.postDelayed(anrTask, Constants.DEFAULT_ANR - (SystemClock.uptimeMillis() - token));
@Override
public void dispatchEnd(long beginMs, long cpuBeginMs, long endMs, long cpuEndMs, long token, boolean isBelongFrame)
if (null != anrTask)
anrTask.getBeginRecord().release();
anrHandler.removeCallbacks(anrTask);
如果 5s 后该任务未被删除,那么 AnrTracer 就会开始收集进程、线程、内存、堆栈等信息,并上报。
6.3.启动监控
应用的启动监控以第一个执行的方法为起点:
public class AppMethodBeat implements BeatLifecycle
private static volatile int status = STATUS_DEFAULT;
// 该方法会被插入到每一个方法的开头执行
public static void i(int methodId)
if (status == STATUS_DEFAULT) // 如果是默认状态,则说明是第一个方法
realExecute();
status = STATUS_READY;
private static void realExecute()
// 记录时间戳
ActivityThreadHacker.hackSysHandlerCallback();
// 开始监控主线程 Looper
LooperMonitor.register(looperMonitorListener);
记录了第一个方法开始执行时的时间戳后,Matrix 还会通过反射的方式,接管 ActivityThread 的Handler 的 Callback:
public class ActivityThreadHacker
public static void hackSysHandlerCallback()
// 记录时间戳,作为应用启用的开始时间
sApplicationCreateBeginTime = SystemClock.uptimeMillis();
// 反射 ActivityThread,接管 Handler
Class<?> forName = Class.forName("android.app.ActivityThread");
...
这样就能知道第一个 Activity 或 Service 或 Receiver 启动的具体时间了,这个时间戳可以作为Application 启动的结束时间:
private final static class HackCallback implements Handler.Callback
private static final int LAUNCH_ACTIVITY = 100;
private static final int CREATE_SERVICE = 114;
private static final int RECEIVER = 113;
private static boolean isCreated = false;
@Override
public boolean handleMessage(Message msg)
boolean isLaunchActivity = isLaunchActivity(msg);
// 如果是第一个启动的 Activity 或 Service 或 Receiver,则以该时间戳作为 Application 启动的结束时间
if (!isCreated)
if (isLaunchActivity || msg.what == CREATE_SERVICE || msg.what == RECEIVER) // todo for provider
ActivityThreadHacker.sApplicationCreateEndTime = SystemClock.uptimeMillis();
ActivityThreadHacker.sApplicationCreateScene = msg.what;
isCreated = true;
最后以主 Activity(闪屏页之后的第一个 Activity)的onWindowFocusChange 方法作为终点,记录时间戳——Activity 的启动耗时可以通过 onWindowFocusChange 方法回调时的时间戳减去其启动时的时间戳。收集到上述信息之后即可统计启动耗时:

如果冷启动/暖启动耗时超过某个阈值(可通过 IDynamicConfig 设置,默认分别为 10s、4s),那么就会从 AppMethodBeat 收集启动过程中的方法执行记录并上报,否则只会简单地上报耗时信息。
6.3.1.慢方法监控
慢方法监测的原理是在 Looper 分发消息时,计算分发耗时(endMs - beginMs),如果大于阈值(可通过 IDynamicConfig 设置,默认为 700ms),就收集信息并上报。
ublic class EvilMethodTracer extends Tracer
@Override
public void dispatchBegin(long beginMs, long cpuBeginMs, long token)
super.dispatchBegin(beginMs, cpuBeginMs, token);
// 插入方法结点,如果出现了方法执行过慢的问题,就从该结点开始收集方法执行记录
indexRecord = AppMethodBeat.getInstance().maskIndex("EvilMethodTracer#dispatchBegin");
@Override
public void dispatchEnd(long beginMs, long cpuBeginMs, long endMs, long cpuEndMs, long token, boolean isBelongFrame)
long dispatchCost = endMs - beginMs;
// 耗时大于慢方法阈值
if (dispatchCost >= evilThresholdMs)
long[] data = AppMethodBeat.getInstance().copyData(indexRecord);
MatrixHandlerThread.getDefaultHandler().post(new AnalyseTask(...);
private class AnalyseTask implements Runnable
void analyse()
// 收集进程与 CPU 信息
int[] processStat = Utils.getProcessPriority(Process.myPid());
String usage = Utils.calculateCpuUsage(cpuCost, cost);
// 从插入结点开始收集并整理方法执行记录
TraceDataUtils.structuredDataToStack(data, stack, true, endMs);
TraceDataUtils.trimStack(stack, Constants.TARGET_EVIL_METHOD_STACK,
new TraceDataUtils.IStructuredDataFilter() ...
// 上报问题
TracePlugin plugin = Matrix.with().getPluginByClass(TracePlugin.class);
plugin.onDetectIssue(issue);
6.3.2.帧率监控
帧率监测的原理是监听 Choreographer,在所有回调都执行完毕后计算当前总共花费的时间,从而计算掉帧数及掉帧程度,当同一个 Activity/Fragment 掉帧程度超过阈值时,就上报问题。关键源码如下:
private class FPSCollector extends IDoFrameListener
@Override
public void doFrameAsync(String visibleScene, long taskCost, long frameCostMs, int droppedFrames, boolean isContainsFrame)
// 使用 Map 保存同一 Activity/Fragment 的掉帧信息
FrameCollectItem item = map.get(visibleScene);
if (null == item)
item = new FrameCollectItem(visibleScene);
map.put(visibleScene, item);
// 累计
item.collect(droppedFrames, isContainsFrame);
// 如果掉帧程度超过一定阈值,就上报问题,并重新计算
// 总掉帧时间 sumFrameCost = 掉帧数 * 16.66ms
// 掉帧上报阈值 timeSliceMs 可通过 IDynamicConfig 设置,默认为 10s
if (item.sumFrameCost >= timeSliceMs) // report
map.remove(visibleScene);
item.report();
但这里存在一个问题,那就是 Matrix 计算 UI 刷新耗时时,每次都会在掉帧数的基础上加 1:
private class FrameCollectItem
void collect(int droppedFrames, boolean isContainsFrame)
// 即使掉帧数为 0,这个值也会不断增加
sumFrameCost += (droppedFrames + 1) * frameIntervalCost / Constants.TIME_MILLIS_TO_NANO;
而且,doFrame 方法不是只在 UI 刷新时回调,而是每次 Looper 分发消息完毕后都会回调,而Lopper 分发消息的频率可能远远大于帧率,这就导致即使实际上没有出现掉帧的情况,但由于 Looper不断分发消息的缘故,sumFrameCost 的值也会不断累加,很快就突破了上报的阈值,进而频繁地上报:
private void dispatchEnd()
...
synchronized (observers)
for (LooperObserver observer : observers)
if (observer.isDispatchBegin())
observer.doFrame(...);
解决方法是在 PluginListener 中手动过滤,或者修改源码。
6.4.总结
TraceCanary 分为慢方法、启动、ANR、帧率四个模块,每个模块的功能都是通过监听接口LooperObserver 实现的,LooperObserver 用于对主线程的 Looper 和 Choreographer 进行监控。
Looper 的监控是通过 Printer 实现的,每次事件分发都会回调 LooperObserver 的 dispatchBegin、dispatchEnd 方法,计算这两个方法的耗时可以检测慢方法和 ANR 等问题。
Choreographer 的监控则是通过添加 input、animation、traversal 等各个类型的回调到Choreographer 头部实现的,vsync 信号触发后,Choreographer中各个类型的回调会被执行,两种类型的回调的开始时间的间隔就相当于第一种类型的事件的耗时(即 input.cost = animation.begin - input.begiin),最后一种事件(traversal)执行完毕后,Looper 的 diaptchEnd 方法也会被执行,因此 traversal.cost = Looper.dispatchEnd -traversal.begin。
各个模块的实现原理如下:
-
ANR:在Looper开始分发消息时,往后台线程插入一个延时(5s 后执行)任务,Looper消息分发完毕后就删除,如果过了 5s,该任务未被删除,就认为出现了 ANR,收集信息,报告问题. -
慢方法:在
Looper分发消息时,计算分发耗时(endMs - beginMs),如果大于阈值(可通过IDynamicConfig设置,默认为 700ms),就收集信息并上报 -
启动:以第一个执行的方法为起点记录时间戳,接着记录第一个
Activity或Service或Receiver启动时的时间戳,作为Application启动的结束时间。最后以主Activity(闪屏页之后的第一个Activity)的onWindowFocusChange方法作为终点,记录时间戳。Activity的启动耗时可以通过
onWindowFocusChange方法回调时的时间戳减去其启动时的时间戳。收集到上述信息之后即可统计启动耗时。 -
掉帧:监听
Choreographer,doFrame回调时统计 UI 刷新耗时,计算掉帧数及掉帧程度,当同一个Activity/Fragment掉帧程度超过阈值时,就上报。但Matrix的计算方法存在问题,可能出现频繁上报的情况,需要自行手动过滤.
下一篇:
7.插桩
8.资源优化
9.I/O监控及原理解析
以上是关于关于Android性能监控Matrix那些事?你知道那些(中)?的主要内容,如果未能解决你的问题,请参考以下文章