Hive SQL语言: DDL建库建表
Posted 黑马程序员官方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive SQL语言: DDL建库建表相关的知识,希望对你有一定的参考价值。
Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。下面就带大家一起来开始学Spark!
▼往期内容汇总:
- 大数据导论
- Linux操作系统概述
- VMware Workstation虚拟机使用
- Linux常用基础命令、系统命令
- Apache Hadoop概述
- Apache Hadoop集群搭建
- HDFS分布式文件系统基础
- Hadoop技术之HDFS shell操作
- Hadoop技术之HDFS工作流程与机制
- Hadoop MapReduce介绍、官方示例及执行流程
一、 Hive SQL之数据库与建库
Hive数据模型总览

SQL中DDL语法的作用
数据定义语言 (Data Definition Language, DDL),是SQL语言集中对数据库内部的对象结构进行创建,删除,修改等的操作语言,这些数据库对象包括database、table等。
DDL核心语法由CREATE、ALTER与DROP三个所组成。 DDL并不涉及表内部数据的操作。

Hive中DDL语法的使用
- Hive SQL (HQL)与标准SQL的语法大同小异,基本相通;
- 基于Hive的设计、使用特点, HQL中create语法(尤其create table)将是学习掌握Hive DDL语法的重中之重。建表是否成功直接影响数据文件是否映射成功,进而影响后续是否可以基于SQL分析数据。通俗点说,没有表,表没有 数据, 你用Hive分析什么呢?
- 选择正确的方向,往往比盲目努力重要。
- 本课程主要讲解基础的建库与建表语法操作
数据库database
在Hive中, 默认的数据库叫做default,存储数据位置位于HDFS的/user/hive/warehouse下。
用户自己创建的数据库存储位置是/user/hive/warehouse/database_name.db下。
create database
- create database用于创建新的数据库
COMMENT: 数据库的注释说明语句
LOCATION:指定数据库在HDFS存储位置, 默认/user/hive/warehouse/dbname.db
WITH DBPROPERTIES:用于指定一些数据库的属性配置。

create database
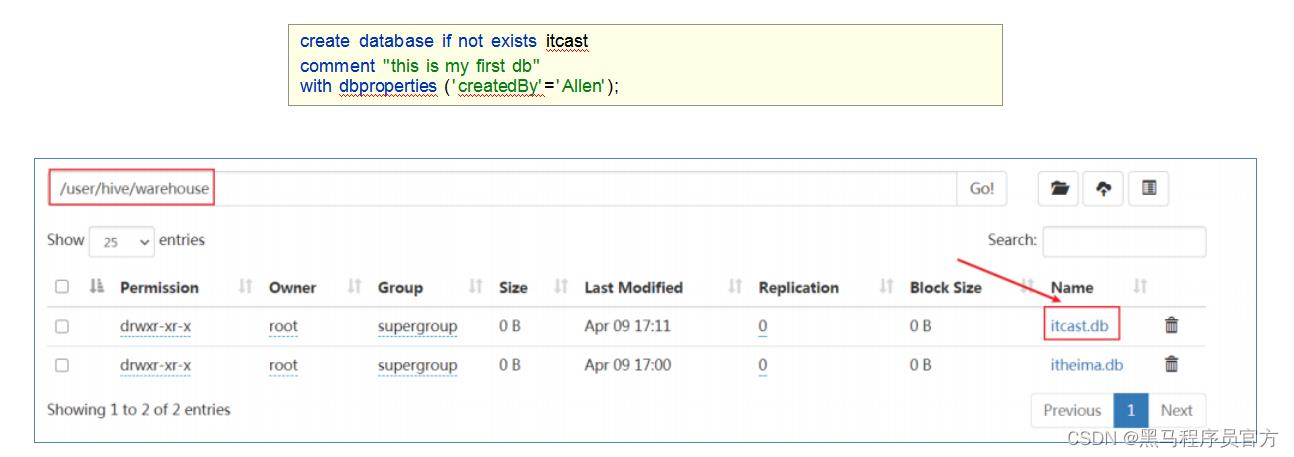
- 例子: 创建数据库itcast
注意: 如果需要使用location指定路径的时候, 最好指向的是一个新创建的空文件夹。
use database
- 选择特定的数据库
切换当前会话使用哪一个数据库进行操作

drop database
删除数据库
默认行为是RESTRICT,这意味着仅在数据库为空时才删除它。
要删除带有表的数据库(不为空的数据库), 我们可以使用CASCADE。

二、 Hive SQL之表与建表
Hive数据模型总览
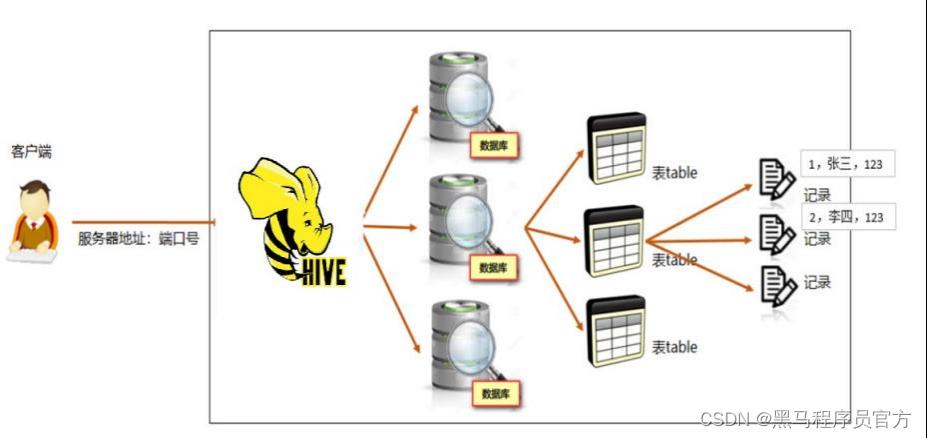
表Table
一个数据库通常包含一个或多个表。每个表由一个名字标识(例如“客户”或者“订单”) 。
表包含带有数据的记录(行)。

建表语法树(基础)

注意事项
- 蓝色字体是建表语法的关键字, 用于指定某些功能。
- [ ]中括号的语法表示可选。
- 建表语句中的语法顺序要和语法树中顺序保持一致。
- 最低限度必须包括的语法为:
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name (col_name data_type [COMMENT col_comment], ... ) [COMMENT table_comment]
[ROW FORMAT DELIMITED …];
CREATE TABLE table_name (col_name data_type);
( 1)数据类型
Hive数据类型指的是表中列的字段类型;
整体分为两类: 原生数据类型 (primitive data type)和复杂数据类型 (complex data type) 。
最常用的数据类型是字符串String和数字类型Int。

(2)分隔符指定语法
ROW FORMAT DELIMITED语法用于指定字段之间等相关的分隔符, 这样Hive才能正确的读取解析数据。
或者说只有分隔符指定正确,解析数据成功, 我们才能在表中看到数据。

(2)分隔符指定语法
LazySimpleSerDe是Hive默认的,包含4种子语法,分别用于指定字段之间、集合元素之间、 map映射 kv之间、换行的分隔符号。
在建表的时候可以根据数据的特点灵活搭配使用。

Hive默认分隔符
Hive建表时如果没有row format语法指定分隔符,则采用默认分隔符;
默认的分割符是'\\001',是一种特殊的字符,使用的是ASCII编码的值,键盘是打不出来的。

Hive默认分隔符
在vim编辑器中,连续按下Ctrl+v/Ctrl+a即可输入'\\001' ,显示^A

在一些文本编辑器中将以SOH的形式显示:

(1/3)数据文件
字段含义: id、 name (英雄名称) 、 hp_max (最大生命) 、 mp_max (最大法力)、 attack_max (最高物攻)、defense_max (最大物防)、 attack_range (攻击范围)、 role_main (主要定位)、 role_assist (次要定位)。
分析一下:字段都是基本类型, 字段的顺序需要注意一下。
字段之间的分隔符是制表符,需要使用row format语法进行指定。

(2/3) 建表语句

(2/3) 建表语句
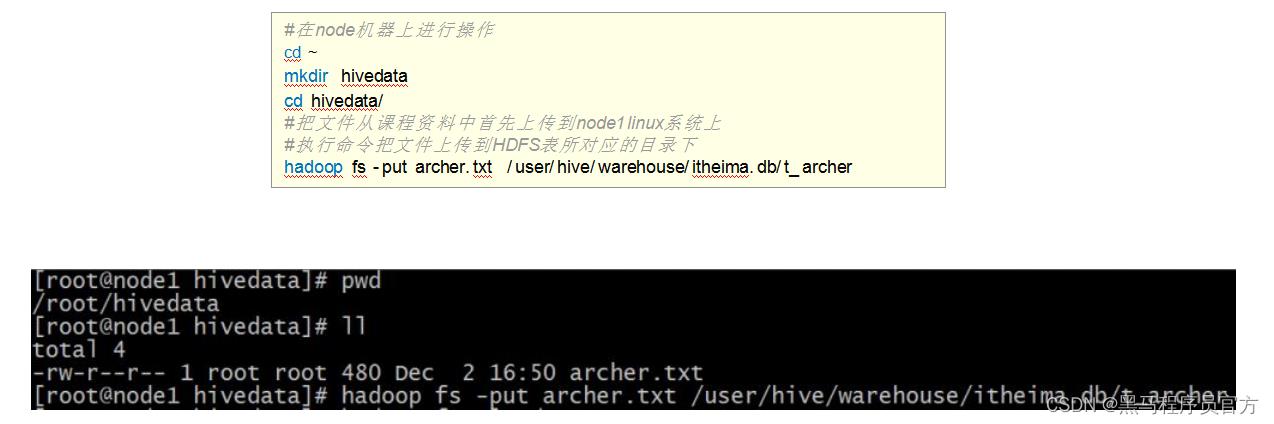
建表成功之后,在Hive的默认存储路径下就生成了表对应的文件夹;
把archer.txt文件上传到对应的表文件夹下。
(3/3)结果验证
执行查询操作,可以看出数据已经映射成功。
核心语法: row format delimited fields terminated by 指定字段之间的分隔符。

(1/3)数据文件
字段: id、team_name (战队名称)、 ace_player_name (王牌选手名字)
分析一下:数据都是原生数据类型,且字段之间分隔符是\\001,因此在建表的时候可以省去row format语句,因为hive默认的分隔符就是\\001。

(2/3) 建表语句

(2/3) 建表语句
建表成功后,把team_ace_player.txt文件上传到对应的表文件夹下。

(3/3)结果验证
执行查询操作,可以看出数据已经映射成功。
想一想: 字段以\\001分隔建表时很方便,那么采集、清洗数据时对数据格式追求有什么启发? 你青睐于什么分隔符?

以上是关于Hive SQL语言: DDL建库建表的主要内容,如果未能解决你的问题,请参考以下文章