耗时几个月,终于找到了JVM停顿十几秒的原因
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了耗时几个月,终于找到了JVM停顿十几秒的原因相关的知识,希望对你有一定的参考价值。
参考技术A 最近我们系统出现了一些奇怪的现象,系统每隔几个星期会在大半夜重启一次,分析过程花费了很长时间,令人印象深刻,故在此记录一下。由于重启后,进程现场信息都丢失了,所以这个问题非常难以排查,像常规的jstack、jmap、arthas等都派不上用场,能用得上的只有机器监控数据与日志。
在看机器监控时,发现重启时间点的CPU、磁盘io使用都会升高,但很快我们就确认了这个信息无任何帮助,因为jvm启动会由于类加载、GIT编译等导致CPU、磁盘io升高,所以这个升高是重启本身导致的,并不是导致问题的原因。
然后就是分析业务日志、内核日志,经过一段时间分析,结论如下:
问题没有任何进一步的进展了,由于没有任何进程现场,为了排查问题,我开发了一个脚本,主要逻辑就是监控CPU、内存使用率,达到一个阈值后自动收集jstack、jmap信息,脚本部署之后就没继续排查了。
部署了脚本之后,过了几个小时,进程又重启了,但这次不是在大半夜,而是白天,又开始了排查的过程...
在这次排查过程中,我突然发现之前漏掉了对gc日志的检查,我赶紧打开gc日志看了起来,发现了下面这种输出:
啥,这代表什么意思,jvm暂停了18秒?但看上面那次gc只花了0.06秒呀!
不知道application threads were stopped: 18.9777012 seconds这个日志的具体含义,只好去网上搜索了,结论如下:
简单来说,就是JVM在做某些特殊操作时,必须要所有线程都暂停起来,所以设计了safepoint这个机制,当JVM做这些特殊操作时(如Full GC、jstack、jmap等),会让所有线程都进入安全点阻塞住,待这些操作执行完成后,线程才可恢复运行。
并且,jvm会在如下位置埋下safepoint,这是线程有机会停下来的地方:
经过一段时间的排查与思考,确认了这次STW是我自己开发的脚本导致的!因为随着jvm运行时间越来越长,老年代使用率会越来越高,但会在Full GC后降下来,而我的脚本直接检测老年代占用大于90%就jmap,导致触发了jvm的safepoint机制使所有线程需等待jmap完成,导致进程不响应请求,进而部署平台kill了进程。
其实脚本监控逻辑应该是在Full GC后,发现内存占用还是很高,才算内存异常case。
在了解到safepoint这个知识点后,在网上搜索了大量文章,主要提到了5组jvm参数,如下:
并且我发现网上有很多关于-XX:+UseCountedLoopSafepoints与-XX:-UseBiasedLocking导致长时间STW的问题案例,我当时几乎都觉得我加上这2个参数后,问题就解决了。
于是我并没有进一步去优化监控脚本,而是下掉了它,直接加上了这些jvm参数。
加入以上jvm参数后,立即查看safepoint日志,格式如下:
其中:
过了几个星期后,问题又出现了,接下来就是检查gc与safepoint日志了,一看日志发现,果然有很长时间的STW,且不是gc造成的,如下:
可以发现gc日志中STW是2021-04-02T00:00:16,而safepoint中是2021-04-02 00:00:00,刚好差了16s,时间差值刚好等于STW时间,这是由于gc日志记录的是STW发生之后的时间,而safepoint日志记录的是STW发生之前的时间,所以这两个日志时间点是吻合的,16s的STW正是由HeapWalkOperation导致的。
从名称看起来像是在执行堆内存遍历操作,类似jmap那种,但我的脚本已经下掉了呀,不可能还有jmap操作呀,机器上除了我的resin服务器进程,也没有其它的进程了呀!
到这里,已经找到了一部分原因,但不知道是怎么造成的,苦苦寻找根因中...
已经记不得是第几次排查了,反正问题又出现了好几次,但这次咱把根因给找到了,过程如下:
现象和之前一模一样,现在的关键还是不知道HeapWalkOperation是由什么原因导致的。
我竟意外发现,resin中有HeapDump相关的配置,好像是resin中的一些 健康 检查的机制。
经过一翻resin官网的学习,确认了resin有各种 健康 检查机制,比如,每个星期的0点,会生成一份pdf报告,这个报告的数据就来源于类似jstack、jmap这样的操作,只是它是通过调用jdk的某些方法实现的。
resin 健康 检查机制的介绍:www.caucho.com/resin-4.0/a…
此机制会在$RESIN_HOME/log目录下生成pdf报告,如下:
由于堆遍历这样的操作,耗时时间完全和当时jvm的内存占用情况有关,内存占用高遍历时间长,占用低则遍历时间短,因此有时暂停时间会触发部署平台kill进程的时间阈值,有时又不会,所以我们的重启现象也不是每周的0点,使得没有注意到0点的这个时间规律。
于是我直接找到resin的health.xml,将 健康 检查相关机制全关闭了,如下:
这样配置以后,过了2个月,再也没出现重启现象了,确认了问题已解决。
这次问题排查有一定的思路,但最后排查出根因的契机,还是有点像撞大运似的,自己随机grep了一把发现线索,但下次就不知道会不会碰到这种运气了。
2022年裸辞,失业7个月,面试40家公司,终于是上岸了·····
上半年裁员,下半年裸辞,有不少人高呼裸辞后躺平真的好快乐!但也有很多人,裸辞后的生活五味杂陈。
面试40次终于找到心仪工作
因为工作压力大、领导PUA等各种原因,去9月下旬我从一家互联网小厂裸辞,没想到这次的裸辞让我付出了失业5个月的代价,历经5个月、面试了40家公司,才终于接到了心仪的工作offer。
今年求职的大环境比疫情刚来那会还要差。2022年的时候,我换工作面试10家还能拿到一半offer;而今年面试34家,也就拿3个,中间一度面试了10家都零offer,陷入了深深的自我怀疑中,今年的大环境太差,岗位缩减,导致市场对于从业人员的要求也越来越高。我必须迅速提升自己的能力,摆脱初级测试的Title,于是我拿出20天提升了自动化测试技术,然后重整旗鼓继续面试,直到第29家、第30家,才连着收到offer。
虽然今年求职很容易遭受过量的挫败。但是面试机会还是有的,不过真的拼实力的时候也到了。
自动化测试如何学?
我前段时间认识了一位阿里在职测试开发的学长,他听到我的情况后是分享了 一份自己整理的自动化测试学习路线,我照着这个学习路线,算是没有走弯路,现在分享给大家,希望能帮助到大家。
1、Python 编程与测试开发技术
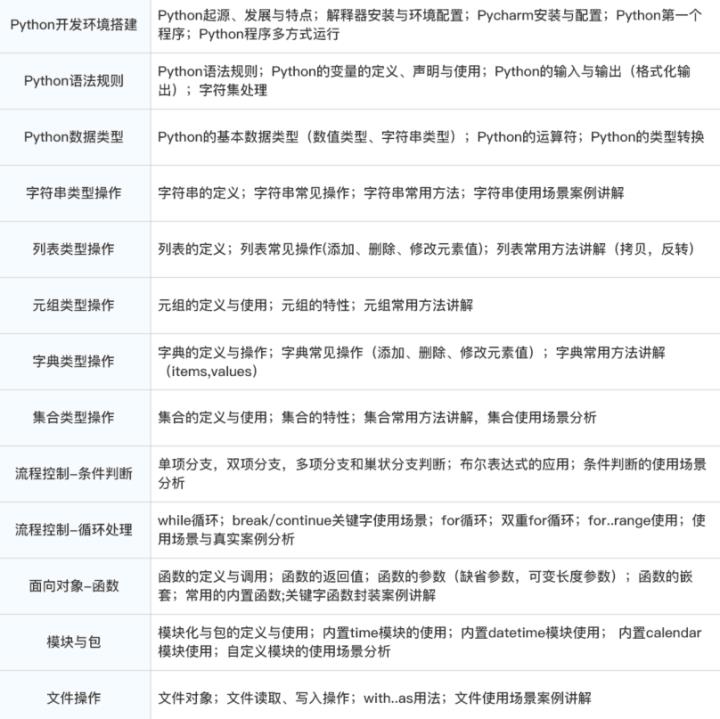
2、Web自动化测试基础

3、APP自动化测试基础

4、Postman测试工具专题

5、接口自动化测试基础

6、自动化框架封装

7、持续集成

8、Jmeter 性能测试

9、APP性能测试
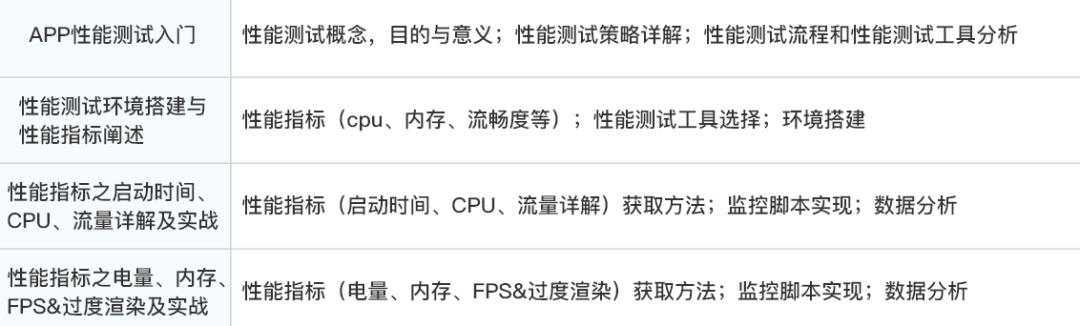
10、Fiddler 抓包工具的使用

11、TCP/IP协议详情

12、计算机操作系统

13、Linux 系统操作

14、MySQL 数据库

15、RobotFramework 自动化测试框架

16、跨平台的自动化测试框架

可以说,这个过程会让你痛不欲生,但只要你熬过去了。以后的生活就轻松很多。正所谓万事开头难,只要迈出了第一步,你就已经成功了一半,等到完成之后再回顾这一段路程的时候,你肯定会感慨良多。
如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助,朋友们如果需要可以自行免费领取 【保证100%免费】

软件测试面试题合集
我们进阶学习自动化测试必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

视频文档获取方式:
这份文档和视频资料,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!以上均可以分享,点下方小卡片即可自行领取。
以上是关于耗时几个月,终于找到了JVM停顿十几秒的原因的主要内容,如果未能解决你的问题,请参考以下文章