r语言lasso回归变量怎么筛选
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了r语言lasso回归变量怎么筛选相关的知识,希望对你有一定的参考价值。
你可以用EXCEL中的“自动筛选”功能。选中数据第一行,按工具栏中的“数据-筛选-自动筛选”,就会在数据第一行出现下拉框,点中它,从下拉框中选“自定义”,会出现一个对话框,在这个对话框的左边框中选“包含”,右边框中填上“公园”(不要引号),确定后就把所有含有“公园”的数据筛选出来了,其他的会自动隐藏。同理,在“包含”的右边框中填上“门店”,就会把所有含有“门店”的数据筛选出来。 参考技术A ## find the optimal model via cross-validationcv.model <- cv.glmnet(tmp.x, tmp.y, family="gaussian", nlambda=50, alpha=1, standardize=True)
plot(cv.model)
cv.model$lambda.min
coef(cv.model, s=cv.model$lambda.min)
R语言-岭回归及lasso算法
前文我们讲到线性回归建模会有共线性的问题,岭回归和lasso算法都能一定程度上消除共线性问题。
岭回归
> #########正则化方法消除共线性 > ###岭回归 > ###glmnet只能处理矩阵 > library(glmnet) > library(mice) > creditcard_exp<-creditcard_exp[complete.cases(creditcard_exp),] > x<-as.matrix(creditcard_exp[,c(6,7,10,11)]) > y<-as.matrix(creditcard_exp[,3]) > #看一下岭脊图 > r1<-glmnet(x=x,y=y,family = "gaussian",alpha = 0)#alpha = 0表示岭回归,x,y不能有缺失值 > plot(r1,xvar="lambda")
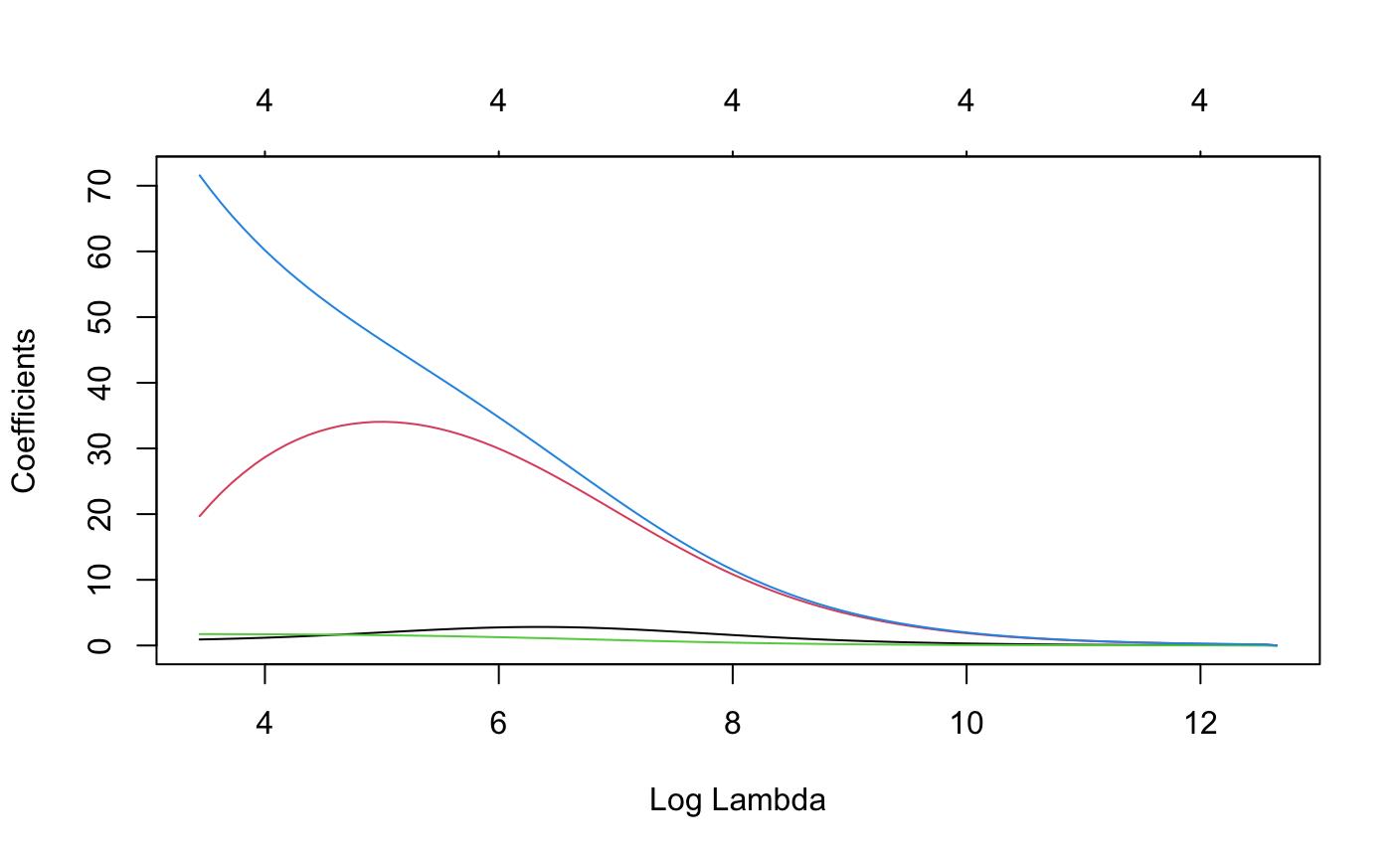
> r1cv<-cv.glmnet(x=x,y=y,family="gaussian",alpha=0,nfolds = 10)#用交叉验证得到lambda > plot(r1cv)
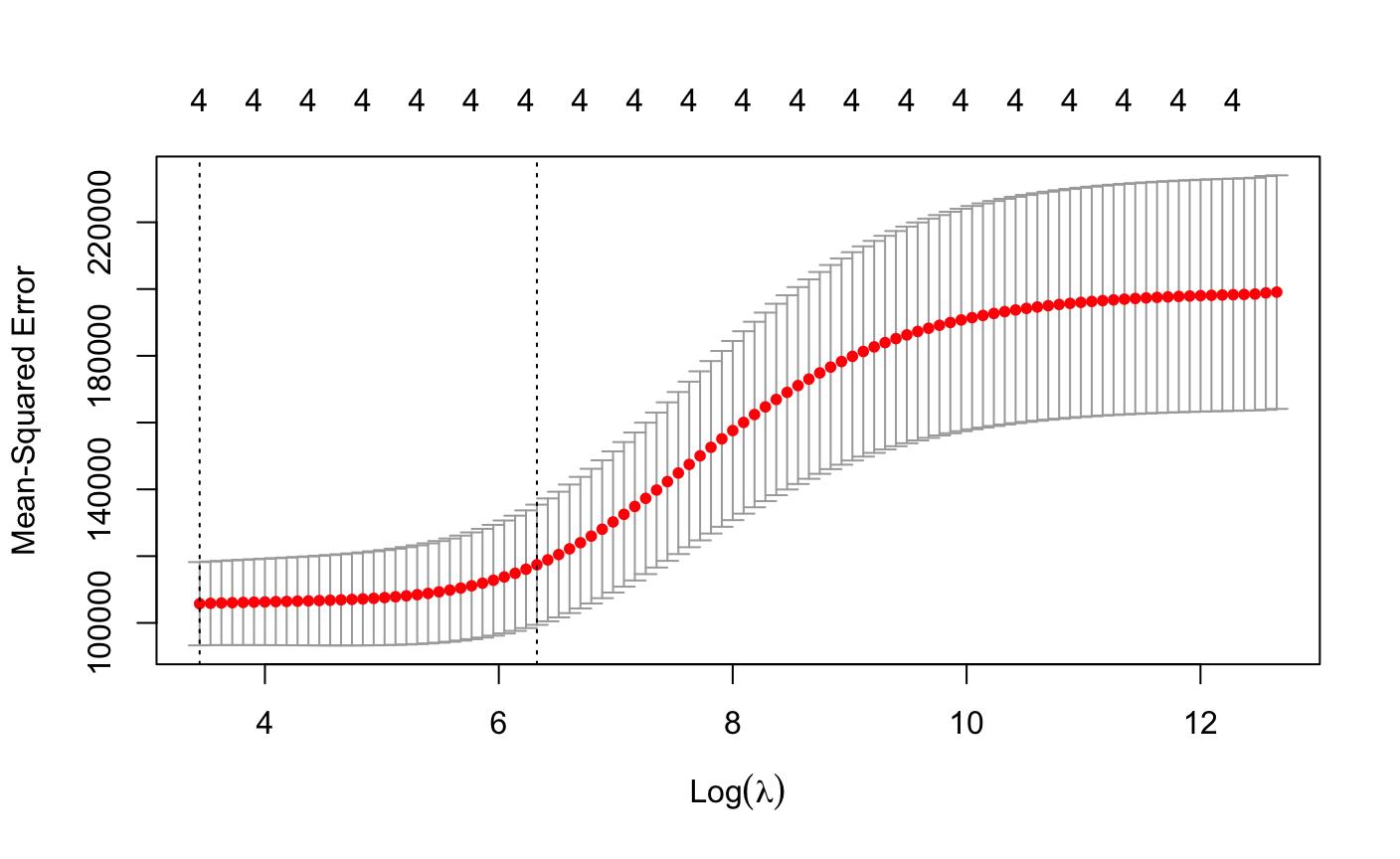
> rimin<-glmnet(x=x,y=y,family = "gaussian",alpha = 0,lambda = r1cv$lambda.min)#取误差平方和最小时的λ > coef(rimin) 5 x 1 sparse Matrix of class "dgCMatrix" s0 (Intercept) 106.5467017 Age 0.9156047 Income 19.6903291 dist_home_val 1.7357213 dist_avg_income 71.5765458
我们可以看到这次模型的收入和支出是正相关了。
lasso算法
#####Lasson算法:有变量筛选功效 r1l<-cv.glmnet(x=x,y=y,family="gaussian",alpha=1,nfolds = 10) plot(r1l)
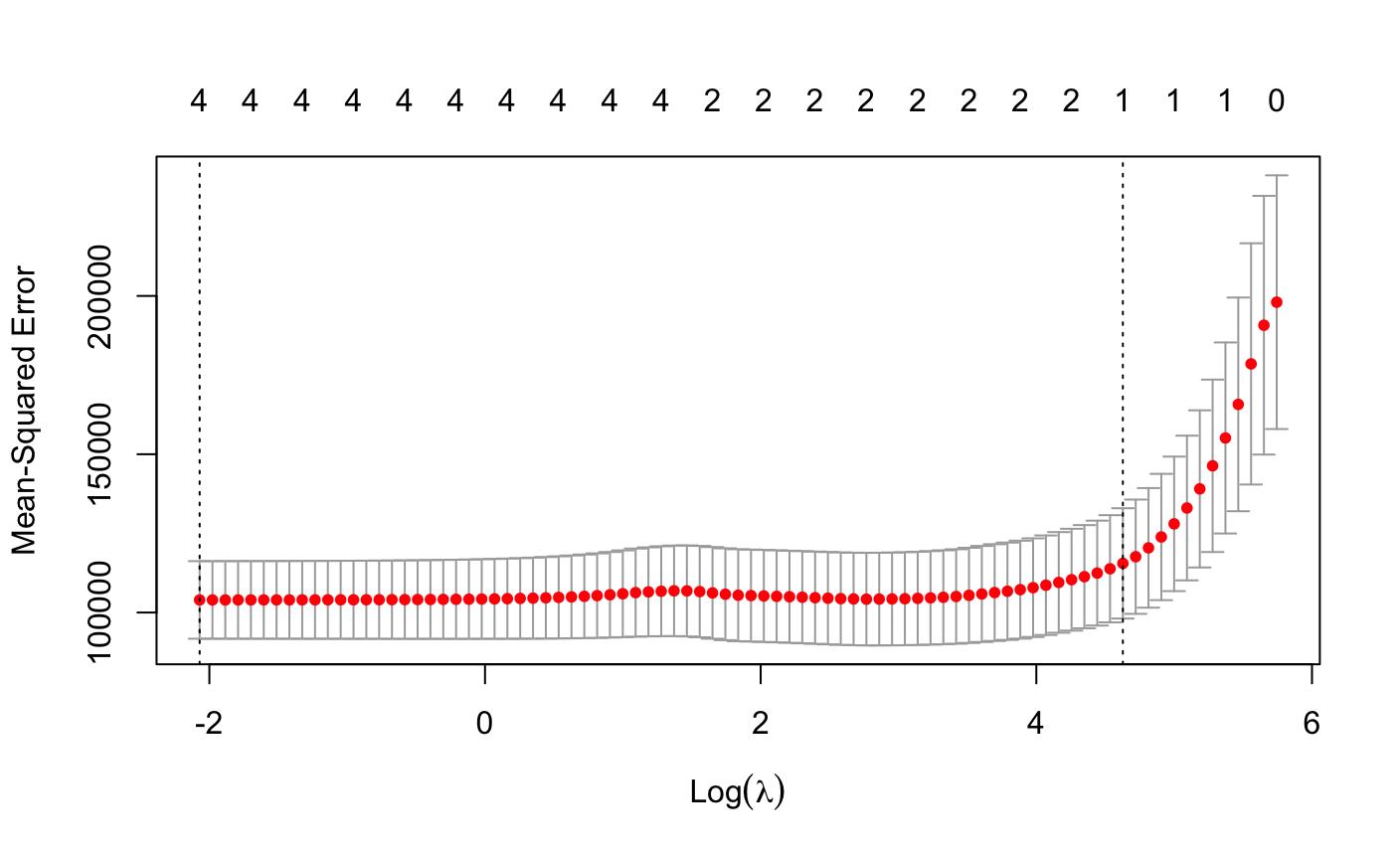
> r1l1<-glmnet(x=x,y=y,family = "gaussian",alpha = 1,lambda = r1l$lambda.min)#取λ最小值看建模情况 > coef(r1l1) 5 x 1 sparse Matrix of class "dgCMatrix" s0 (Intercept) -27.169039 Age 1.314711 Income -160.195837 dist_home_val 1.538823 dist_avg_income 255.395751
看模型数据,我们得知并没有解决income为负相关的情况,而且并没有筛选变量,那么我们尝试取lambda.1se*0.5的值
> r1l2<-glmnet(x=x,y=y,family = "gaussian",alpha = 1,lambda = r1l$lambda.1se*0.5)#0.5倍标准误差的λ > coef(r1l2) 5 x 1 sparse Matrix of class "dgCMatrix" s0 (Intercept) 267.0510318 Age . Income . dist_home_val 0.6249539 dist_avg_income 83.6952253
看结果,可知把一些变量删去了,消除共线性的问题,接下来我们看看lambda.1se的值
1 > r1l3<-glmnet(x=x,y=y,alpha = 1,family = "gaussian",lambda = r1l$lambda.1se) 2 > coef(r1l3) 3 5 x 1 sparse Matrix of class "dgCMatrix" 4 s0 5 (Intercept) 432.00684 6 Age . 7 Income . 8 dist_home_val . 9 dist_avg_income 68.90894
这次结果只留了一个变量,由此可知当lambda越大,变量保留的越少,一般我们在误差最小和一倍标准差内选择合适的λ。
以上是关于r语言lasso回归变量怎么筛选的主要内容,如果未能解决你的问题,请参考以下文章