org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 13
Posted 格格巫 MMQ!!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 13相关的知识,希望对你有一定的参考价值。
在使用spark的时候报错:
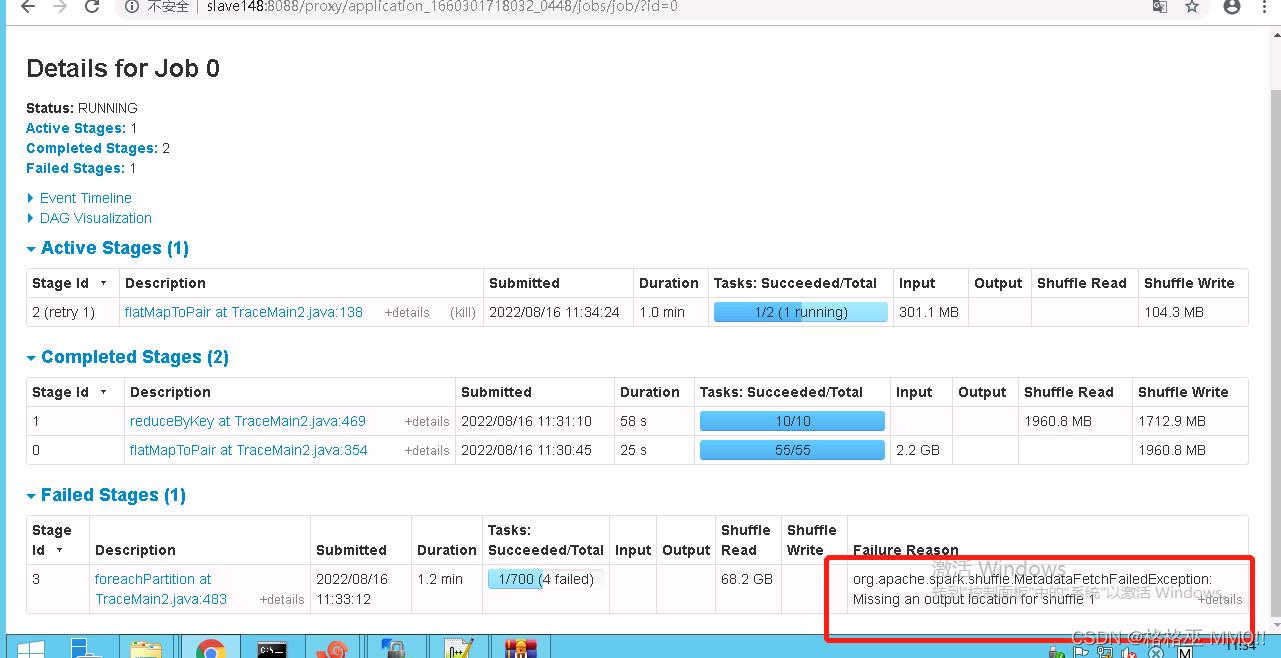
org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 6
at org.apache.spark.MapOutputTrackerKaTeX parse error: Can't use function '$' in math mode at position 8: anonfun$̲org$apache$spar…convertMapStatuses
2.
a
p
p
l
y
(
M
a
p
O
u
t
p
u
t
T
r
a
c
k
e
r
.
s
c
a
l
a
:
697
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
M
a
p
O
u
t
p
u
t
T
r
a
c
k
e
r
2.apply(MapOutputTracker.scala:697) at org.apache.spark.MapOutputTracker
2.apply(MapOutputTracker.scala:697)atorg.apache.spark.MapOutputTracker
a
n
o
n
f
u
n
anonfun
anonfunorg
a
p
a
c
h
e
apache
apachespark
M
a
p
O
u
t
p
u
t
T
r
a
c
k
e
r
MapOutputTracker
MapOutputTracker$convertMapStatuses
2.
a
p
p
l
y
(
M
a
p
O
u
t
p
u
t
T
r
a
c
k
e
r
.
s
c
a
l
a
:
693
)
a
t
s
c
a
l
a
.
c
o
l
l
e
c
t
i
o
n
.
T
r
a
v
e
r
s
a
b
l
e
L
i
k
e
2.apply(MapOutputTracker.scala:693) at scala.collection.TraversableLike
2.apply(MapOutputTracker.scala:693)atscala.collection.TraversableLikeWithFilterKaTeX parse error: Can't use function '$' in math mode at position 8: anonfun$̲foreach$1.apply…convertMapStatuses(MapOutputTracker.scala:693)
at org.apache.spark.MapOutputTracker.getMapSizesByExecutorId(MapOutputTracker.scala:147)
at org.apache.spark.shuffle.BlockStoreShuffleReader.read(BlockStoreShuffleReader.scala:49)
at org.apache.spark.sql.execution.ShuffledRowRDD.compute(ShuffledRowRDD.scala:165)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.ZippedPartitionsRDD2.compute(ZippedPartitionsRDD.scala:89)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:108)
at org.apache.spark.executor.Executor
T
a
s
k
R
u
n
n
e
r
.
r
u
n
(
E
x
e
c
u
t
o
r
.
s
c
a
l
a
:
338
)
a
t
j
a
v
a
.
u
t
i
l
.
c
o
n
c
u
r
r
e
n
t
.
T
h
r
e
a
d
P
o
o
l
E
x
e
c
u
t
o
r
.
r
u
n
W
o
r
k
e
r
(
T
h
r
e
a
d
P
o
o
l
E
x
e
c
u
t
o
r
.
j
a
v
a
:
1142
)
a
t
j
a
v
a
.
u
t
i
l
.
c
o
n
c
u
r
r
e
n
t
.
T
h
r
e
a
d
P
o
o
l
E
x
e
c
u
t
o
r
TaskRunner.run(Executor.scala:338) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor
TaskRunner.run(Executor.scala:338)atjava.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)atjava.util.concurrent.ThreadPoolExecutorWorker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
)
org.apache.spark.shuffle.FetchFailedException: Failed to connect to hostname/xx.xx.xx.xx:26969 以上是关于org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 13的主要内容,如果未能解决你的问题,请参考以下文章
at org.apache.spark.storage.ShuffleBlockFetcherIterator.throwFetchFailedException(ShuffleBlockFetcherIterator.scala:513)
at org.apache.spark.storage.ShuffleBlockFetcherIterator.next(ShuffleBlockFetcherIterator.scala:444)
at org.apache.spark.storage.ShuffleBlockFetcherIterator.next(ShuffleBlockFetcherIterator.scala:61)
at scala.collection.IteratorKaTeX parse error: Can't use function '$' in math mode at position 5: anon$̲12.nextCur(Iter…anon
12.
h
a
s
N
e
x
t
(
I
t
e
r
a
t
o
r
.
s
c
a
l
a
:
440
)
a
t
s
c
a
l
a
.
c
o
l
l
e
c
t
i
o
n
.
I
t
e
r
a
t
o
r
12.hasNext(Iterator.scala:440) at scala.collection.Iterator
12.hasNext(Iterator.scala:440)atscala.collection.Iterator$anon
11.
h
a
s
N
e
x
t
(
I
t
e
r
a
t
o
r
.
s
c
a
l
a
:
408
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
u
t
i
l
.
C
o
m
p
l
e
t
i
o
n
I
t
e
r
a
t
o
r
.
h
a
s
N
e
x
t
(
C
o
m
p
l
e
t
i
o
n
I
t
e
r
a
t
o
r
.
s
c
a
l
a
:
32
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
I
n
t
e
r
r
u
p
t
i
b
l
e
I
t
e
r
a
t
o
r
.
h
a
s
N
e
x
t
(
I
n
t
e
r
r
u
p
t
i
b
l
e
I
t
e
r
a
t
o
r
.
s
c
a
l
a
:
37
)
a
t
s
c
a
l
a
.
c
o
l
l
e
c
t
i
o
n
.
I
t
e
r
a
t
o
r
11.hasNext(Iterator.scala:408) at org.apache.spark.util.CompletionIterator.hasNext(CompletionIterator.scala:32) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at scala.collection.Iterator
11.hasNext(Iterator.scala:408)atorg.apache.spark.util.CompletionIterator.hasNext(CompletionIterator.scala:32)atorg.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)atscala.collection.Iterator$anon
11.
h
a
s
N
e
x
t
(
I
t
e
r
a
t
o
r
.
s
c
a
l
a
:
408
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
c
a
t
a
l
y
s
t
.
e
x
p
r
e
s
s
i
o
n
s
.
G
e
n
e
r
a
t
e
d
C
l
a
s
s
11.hasNext(Iterator.scala:408) at org.apache.spark.sql.catalyst.expressions.GeneratedClass
11.hasNext(Iterator.scala:408)atorg.apache.spark.sql.catalyst.expressions.GeneratedClassGeneratedIterator.sort_addToSorter
(
U
n
k
n
o
w
n
S
o
u
r
c
e
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
c
a
t
a
l
y
s
t
.
e
x
p
r
e
s
s
i
o
n
s
.
G
e
n
e
r
a
t
e
d
C
l
a
s
s
(Unknown Source) at org.apache.spark.sql.catalyst.expressions.GeneratedClass
(UnknownSource)atorg.apache.spark.sql.catalyst.expressions.GeneratedClassGeneratedIterator.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExecKaTeX parse error: Can't use function '$' in math mode at position 8: anonfun$̲8anon
1.
h
a
s
N
e
x
t
(
W
h
o
l
e
S
t
a
g
e
C
o
d
e
g
e
n
E
x
e
c
.
s
c
a
l
a
:
395
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
e
x
e
c
u
t
i
o
n
.
R
o
w
I
t
e
r
a
t
o
r
F
r
o
m
S
c
a
l
a
.
a
d
v
a
n
c
e
N
e
x
t
(
R
o
w
I
t
e
r
a
t
o
r
.
s
c
a
l
a
:
83
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
e
x
e
c
u
t
i
o
n
.
j
o
i
n
s
.
S
o
r
t
M
e
r
g
e
J
o
i
n
S
c
a
n
n
e
r
.
a
d
v
a
n
c
e
d
S
t
r
e
a
m
e
d
(
S
o
r
t
M
e
r
g
e
J
o
i
n
E
x
e
c
.
s
c
a
l
a
:
776
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
e
x
e
c
u
t
i
o
n
.
j
o
i
n
s
.
S
o
r
t
M
e
r
g
e
J
o
i
n
S
c
a
n
n
e
r
.
f
i
n
d
N
e
x
t
O
u
t
e
r
J
o
i
n
R
o
w
s
(
S
o
r
t
M
e
r
g
e
J
o
i
n
E
x
e
c
.
s
c
a
l
a
:
737
)
a
t
o
r
g
.
a
p
a
c
h
e
.
s
p
a
r
k
.
s
q
l
.
e
x
e
c
u
t
i
o
n
.
j
o
i
n
s
.
O
n
e
S
i
d
e
O
u
t
e
r
I
t
e
r
a
t
o
r
.
a
d
v
a
n
c
e
S
t
r
e
a
m
(
S
o
r
t
M
e
r
g
e