万人场景下传输挑战和演进实践
Posted LiveVideoStack_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了万人场景下传输挑战和演进实践相关的知识,希望对你有一定的参考价值。
编者按: 随着网络和移动设备的普及,从两人通话到多人开麦、再到千人万人大课堂,音视频领域得到了迅速的发展。在如今万人场景下,音视频传输面临哪些挑战呢?传输过程又经历了怎样的演进实践?LiveVideoStackCon2022音视频技术大会上海站邀请到了火山引擎的汪俊老师,为我们分享万人场景下的传输挑战和演进实践。
文/汪俊
整理/LiveVideoStack

大家下午好,我是来自火山引擎的汪俊。大家也知道,火山引擎的RTC已经在很多业务场景落地。今天很高兴能够给大家带来从0到万人场景演进过程中经验的分享。
1、场景介绍和挑战
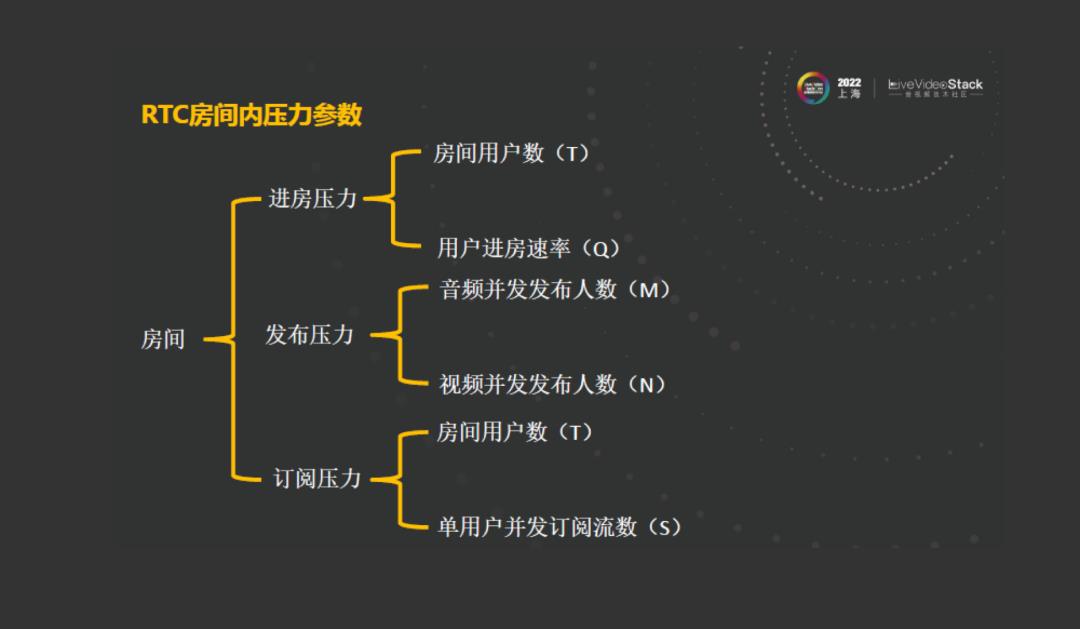
首先来看一下场景介绍和挑战。RTC的每一场音视频通话都是在房间中进行的,其中最值得注意的是房间的压力。房间的压力主要由进房压力、发布压力和订阅压力组成。首先,进房压力和房间用户数、用户进房速率有关;发布压力和音频并发发布人数、视频并发发布人数有关;订阅压力与房间用户数和单用户订阅流数有关。场景的不同,其复杂性不同,其压力也是不同的。
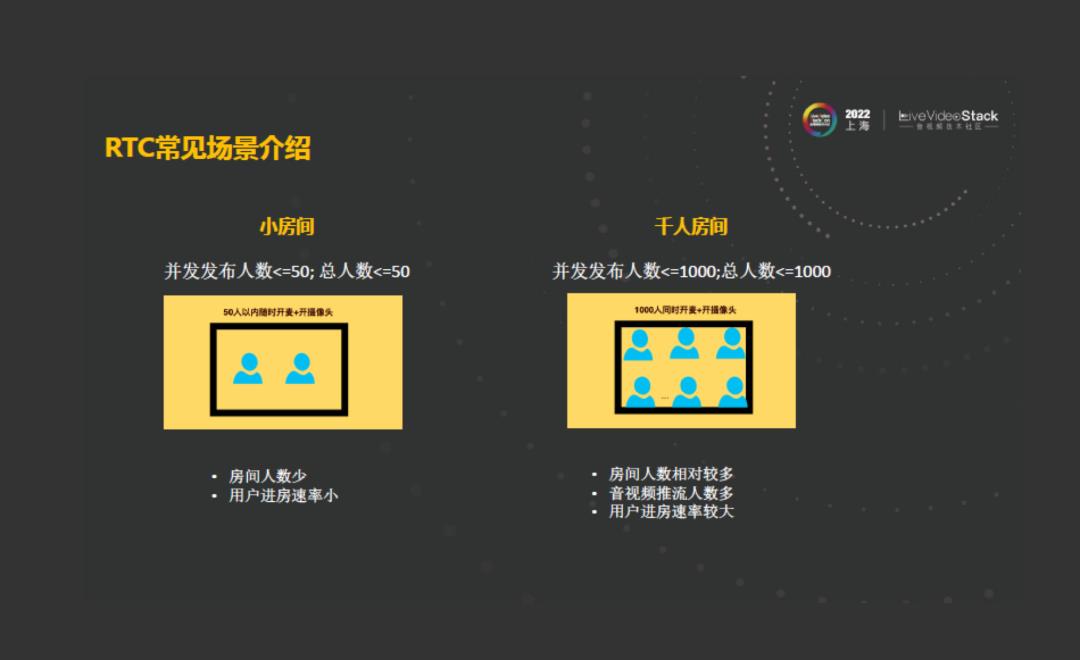
在整个演进的过程中,遇到了很多种类型的房间,他们都有各自不同的特点。第一种叫小房间,这种房间并发发布人数小于等于50,总人数小于等于50,这种房间的特点是人数少,用户进房速率小。第二种叫作千人房间,这种房间并发发布数最大可达到1000,总人数可达到1000。可以理解为在这种房间下,所有人都可以把音频和视频打开。这种房间相对于小房间较多,音视频推流人数多,用户进房速率较大。
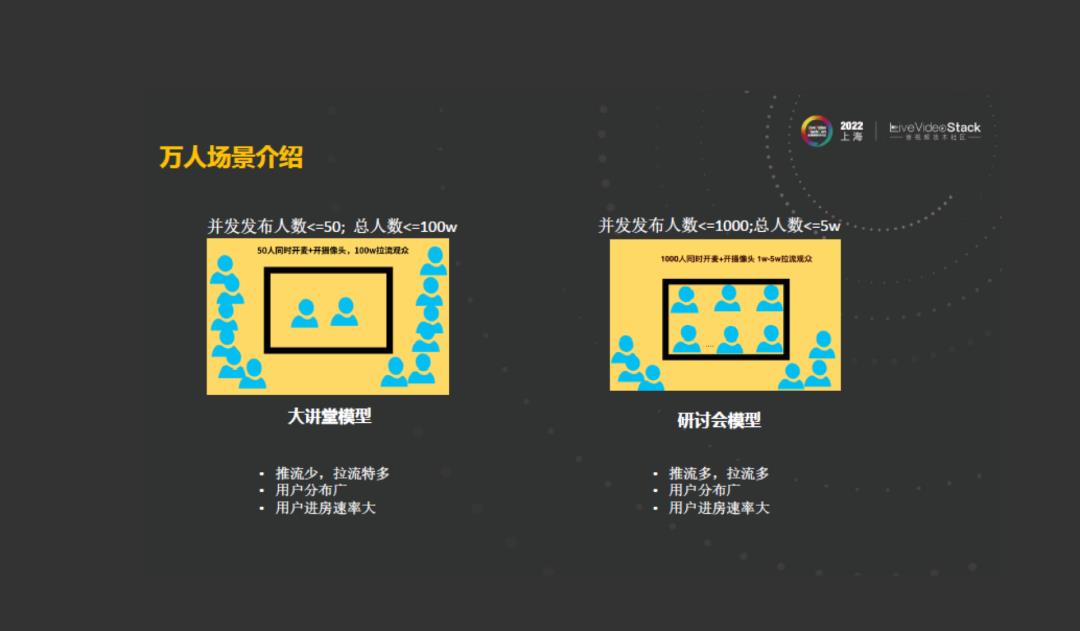
第三种房间叫做万人房间,这是一种超大规模的房间,主要有两种模型,一种叫做大讲堂模型,第二个模型叫做研讨会模型,在大讲堂模型中,它的并发的发布人数是小于等于50,但是它的推流的规模可以多达百万,压力是非常大的。这种房间的特点是它的推流人数是比较少,它的拉流人数特别多,在这种模型下,拉流的用户会分布非常广,可以来自于各地。这时候,进房的用户的进房速率也是非常的高。第二种模型是现在非常流行的一个模型,叫研讨会模型,这种情况下它的并发发布人数是小于等于1000,可以理解为有1000个人可以并发的开着自己的视频和音频,这种模型下他的参会的总人数可以多达5万,在这种场景下,它的推流人数是非常的多,那拉流人数也是较多,相对于前面的几种来看,它的用户参与地区也是非常广,在跨国会议中用户遍布各地,用户的进场速率也是非常高的。

面对场景的不同,其复杂度不同,其压力也不同,但是要针对以下的一些业务核心指标,需要去对齐到用户体验。所以对此来说,对我们来说压力也特别大,也有很大的挑战。
2、万人演进路线
接下来看完的产品介绍,来看一下万人演进的路线。
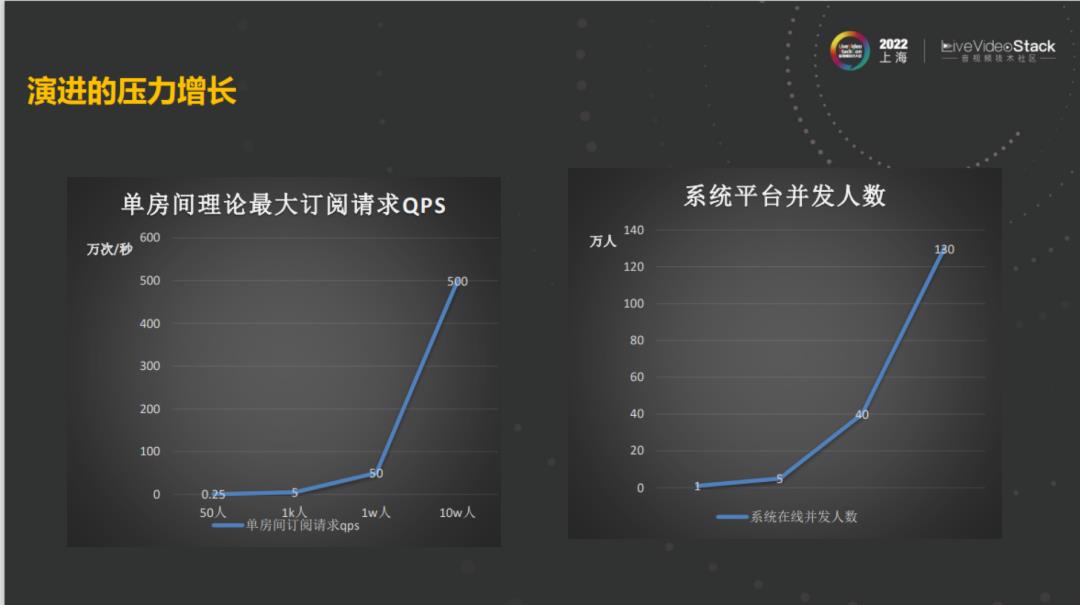
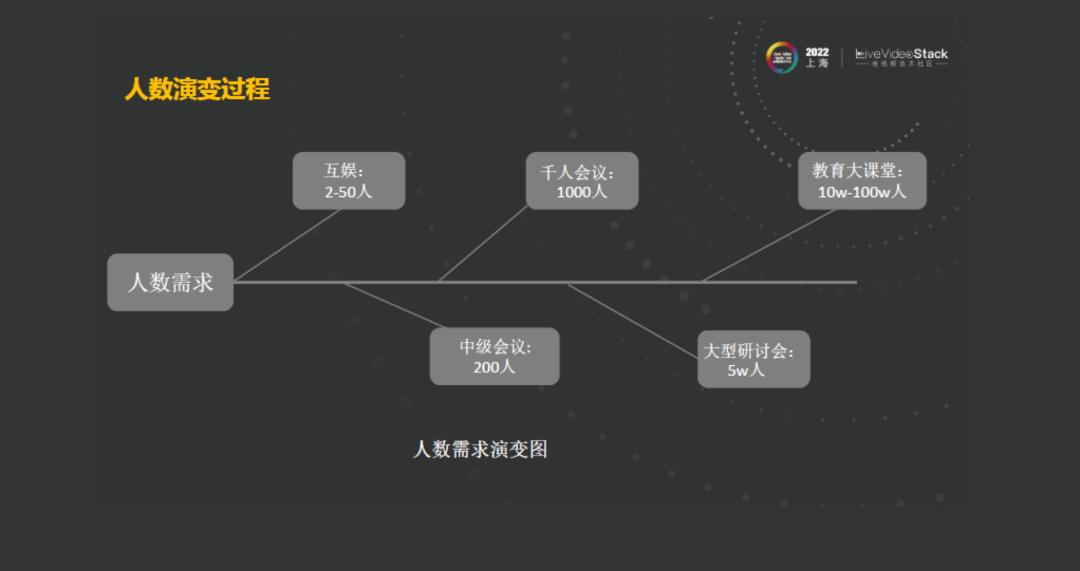
早期业务的需求的快速发展,对火山引擎的要求也一直在增加,从早期的两人的抖音音视频社交场景,到多人的抖音音视频社交场景,从200人的飞书中级会议,到千人音视频双开的飞书会议,从单房间五万人的网络研讨会,到暑期的时候单房间多达百万人的教育大班课,这是整个过程中业务对火山引擎所提出的挑战。随着业务复杂度的增加、房间人数的增加、单房间人数的增加和整个系统平台并发房间数的增加,整个系统的压力和系统并发请求数的过大,对系统架构,音频和视频的传输架构都带来了很大的挑战。

面对这些复杂的场景和高并发的压力,我从以下几个方面来描述一下整个演进的路线,第一部分是讲述一下在面对这么大压力的时候,整个分布式的系统架构的演进,主要核心点是广域网多中心的架构和多地域分布式信令。第二个是在面对这种大房间场景越来越多的人进行开麦,在这种情景下,会面临的一个最大的难题就是音频传输。第二个演进的路线是音频传输架构的演进,在过程中核心点是将音视频分离、自动订阅。第三个是在这种超大规模的分发下面临的第三个难题,就是视频的传输,这里面核心的点就是在分发边缘进行聚合,采取树形分发的结构。

接下来就进入演进实践的环节。挑战一:分布式架构的演进,多中心架构和分布式信令。早期单中心架构,其主要由分布在基础设施比较完善的中心机房的控制面服务和分布在基础设施比较简单的边缘机房的数据面服务所组成。其中控制面服务主要由接入服务、信令服务、调度服务和其他一些辅助服务所组成。数据面服务,主要由分布在各地的媒体服务器所组成。边缘的媒体服务器会三秒钟一次向中心周期性进行上报,上报它的转节点状态和房间内的一些数据。分布在各地的用户,通过信令传输通道,直接连到接入中心机房,用户的音视频传输通道直接连到就近的边缘节点。
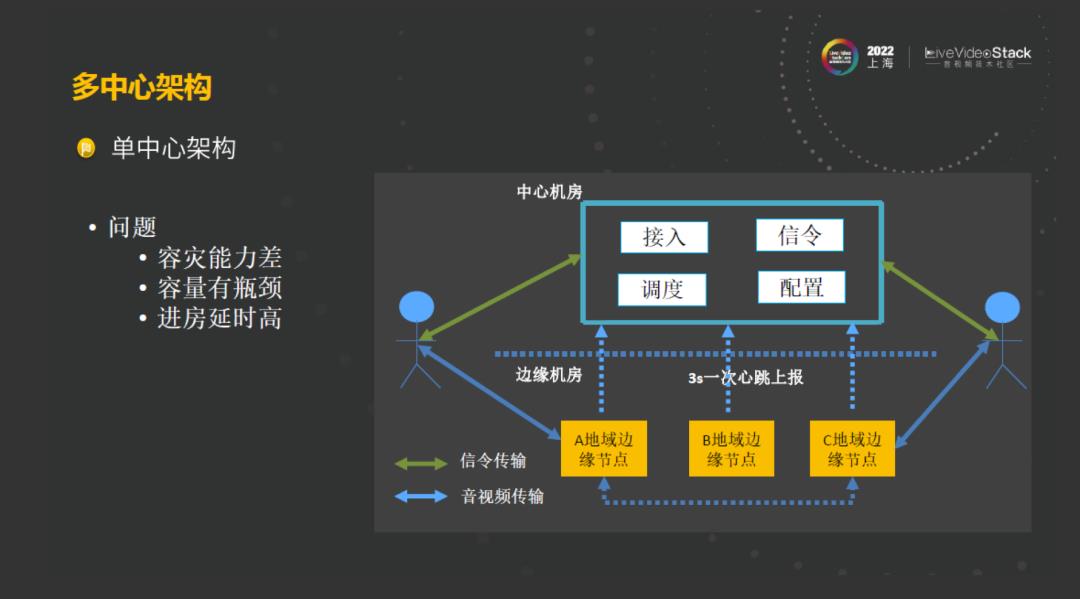
虽然多地域分布的边缘节点是天然是分布式的,但是这种单中心的架构有很多的很显而易见的缺点。在中心机房出现故障的时候,它的容灾能力是比较差的,随着整个业务日益的饱和就会面临着容量不足的瓶颈。各地域的用户,都是通过单一的中心机房的信令接入进房,在这个架构下,进房延迟很高。所以要考虑先对现状的业务进行分析,业务提出的诉求是需要具有全球实时音视频的通信能力,需要能跨地域低延时,在整个的系统中,主要关心的数据是各地用户边缘节点数据和房间数据,房间的数据主要包含流的数据和用户的数据。

在RTC音视频通话的过程中有个明显的特点,就是用户数据和用户会话数据和流的数据,是跟用户的生命周期是一致的。当我离开房间的时候,我的数据也就不需要存储了,也就可以消亡了。这个特点对整个多中心的架构的传输是有比较好的帮助的。针对前面提出的容灾容量一些需求,我们采取了这种多地域,对等机房的这种架构。
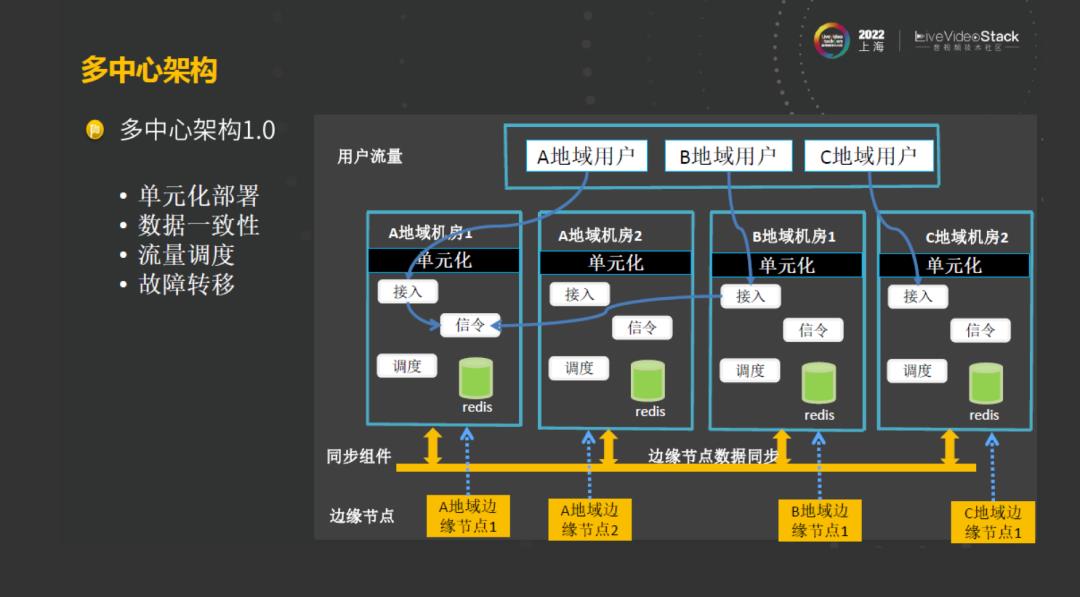
首先,面对容灾、容量和一些就近接入的一些需求,我们采用了多中心的架构,也是单元化部署的架构。面对边缘节点的数据,主要有两种数据,一种是静态节点数据,另外一种是周期性的上报的动态数据,这类数据是可以容忍短时间的不一致的。所以说在过程中,比较容易的实现了多中心机房的数据同步。第二类的数据,就是房间数据,做完单元化部署的架构之后,需要进行对数据进行分片。相同房间的数据都是会归属到其中的一个中心机房。此时,如果其中一个中心机房出现宕机,边缘接入的用户的流量和边缘媒体上报的流量会自动切到其他的机房,然后在其他中心机房中重新完成进房,从而达到了数据的重建,实现了故障转移。这种架构初步的满足了容灾容量的一些问题。

这种架构也是明显存在一些缺点的,比如随着单房间的用户数越来越多,那么房间里面一定会产生第一个问题就是大房间的消息的广播风暴。第二个问题是在目前中心机房宕机的时候,进行自动迁移的过程目前还不是很平滑,因为需要重新进房和房间数据的重建。第三类问题,在各地虽然拥有了部署的多中心机房,但是采取了这种按房间维度的数据分片,那么跨地域用户进房的时候,还需要进行一个跨机房的房间进房的数据操作。
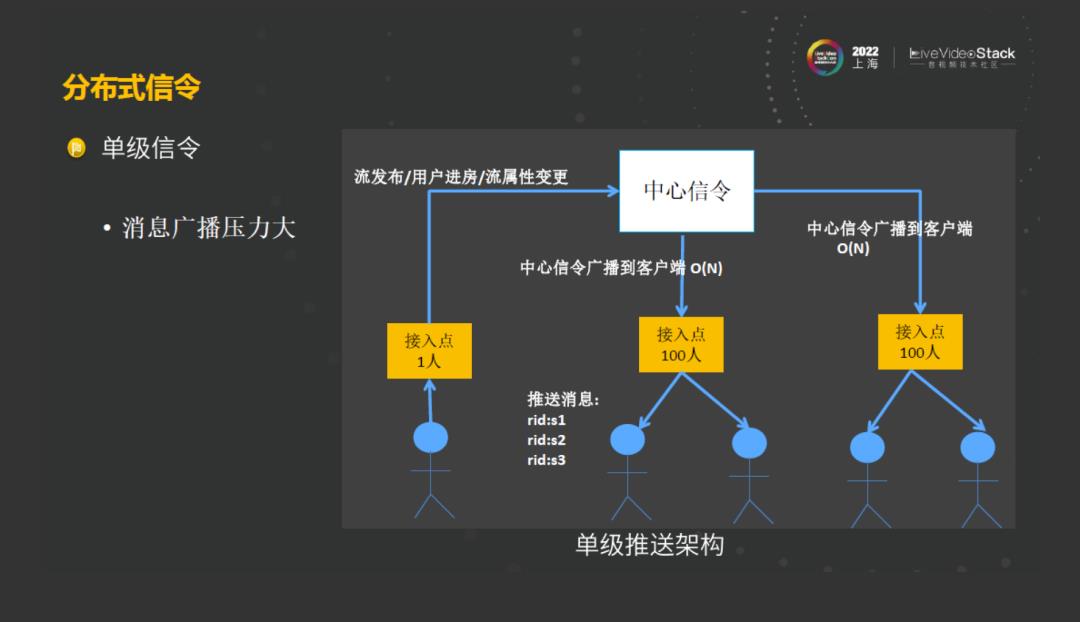
面对这三类的问题,我们继续往下演进,第一步我们采取分布式信令,在中心架构1.0中,采取的是用户从中心开始接入,这种单级信令的架构有明显的一个缺点,当房间里的人数较多的时候,其中有任何一个用户发出进房或者流变更的时候,中心信令会向其他的房间内的其他用户进行推流,此时中心信令面临的压力是非常大的。当房间里数人数越来越多的时候,中心信令就会面临可见的容量瓶颈。
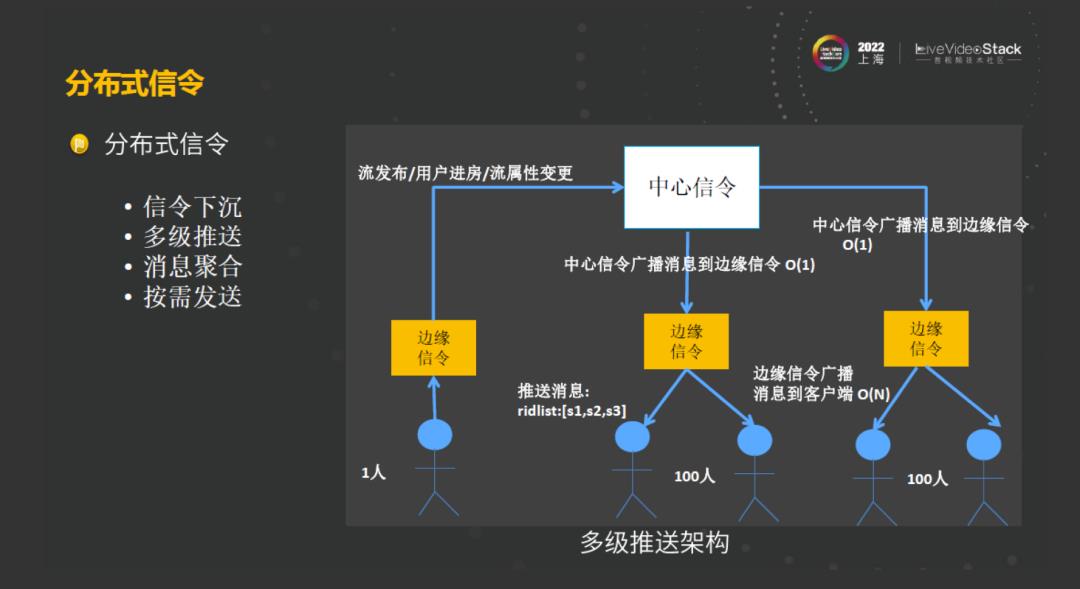
所以我们考虑采用多级的分布式架构,把信令下沉到边缘,形成多级推送架构。在这种情况下,与前面的多中心架构1.0中的用户接入不同的是,此时是由边缘接入信令通道。这时候,当其中任何一个用户发出消息广播的时候,中心信令相对于用户的广播,复杂度从O(N)降到了O(1),因为只需要将消息分布在边缘信令里。然后由边缘信令负责向其接入的用户广播这些消息,通过这种多级推送架构信令下沉,能解决消息在大房间里面广播的难题。
除此之外,在之前的多中心1.0架构中,是对每条消息都进行进行广播的,我们在这过程中采取了一些优化,将消息进行聚合,还有一些消息可以按需发送,来减少广播量。这种架构完美的解决了大房间用户消息广播的难题,也优化了用户接入的延时。
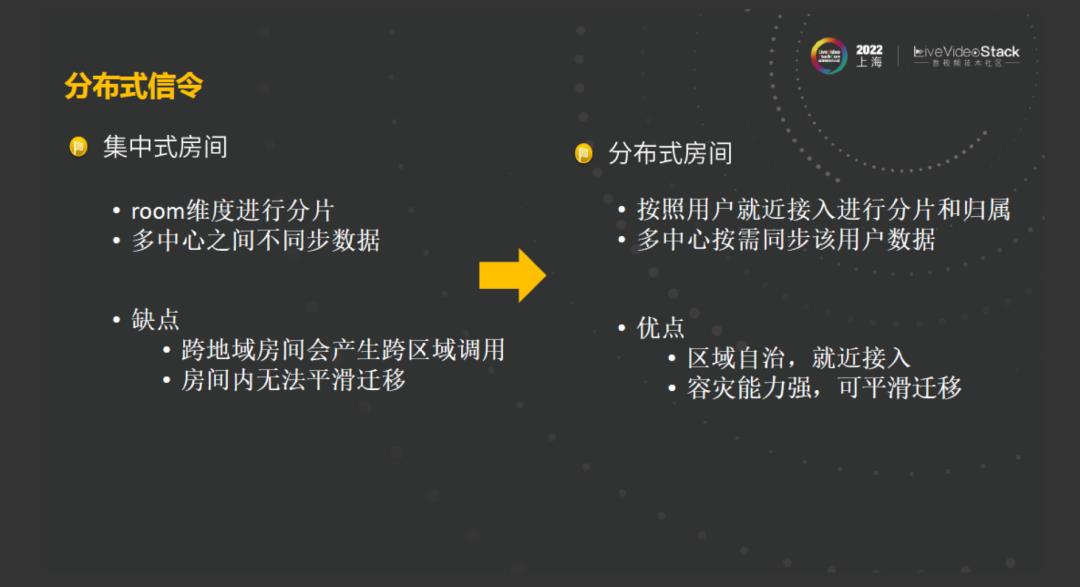
另外,还留下两个问题,一个是容灾的时候平滑迁移的问题,另外一个是跨机房进房延时较高的问题。在多中心1.0架构中,采取这种集中式的房间,以room维度进行数据分片归属。
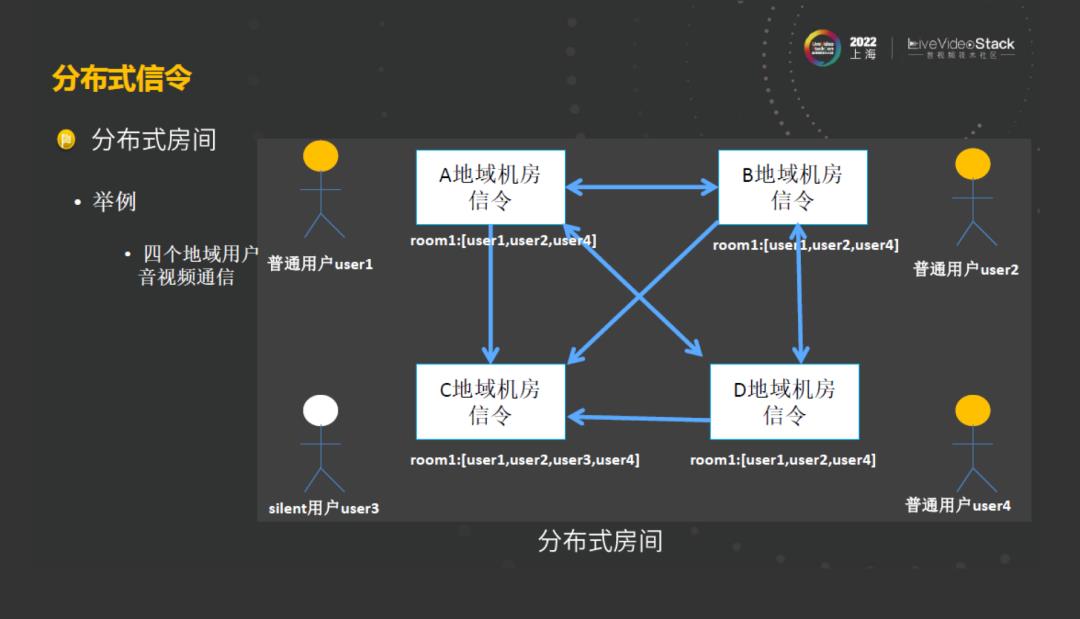
考虑到上面的两个问题,我们决定由集中式房间向分布式房间进行演进,按照用户的维度进行分片,将用户就近接入中心机房,该机房在进房的过程中,也不需要进行跨机房去其他区域进行读写操作了。在进房之后,这些消息也会按需进行多项的机房同步,在这种情况下,这种架构具有的优点就是时间可以趋于自制。就近接入可以解决容灾能力,它的容灾能力也比较强,在出现故障的时候也可以实现平滑迁移。
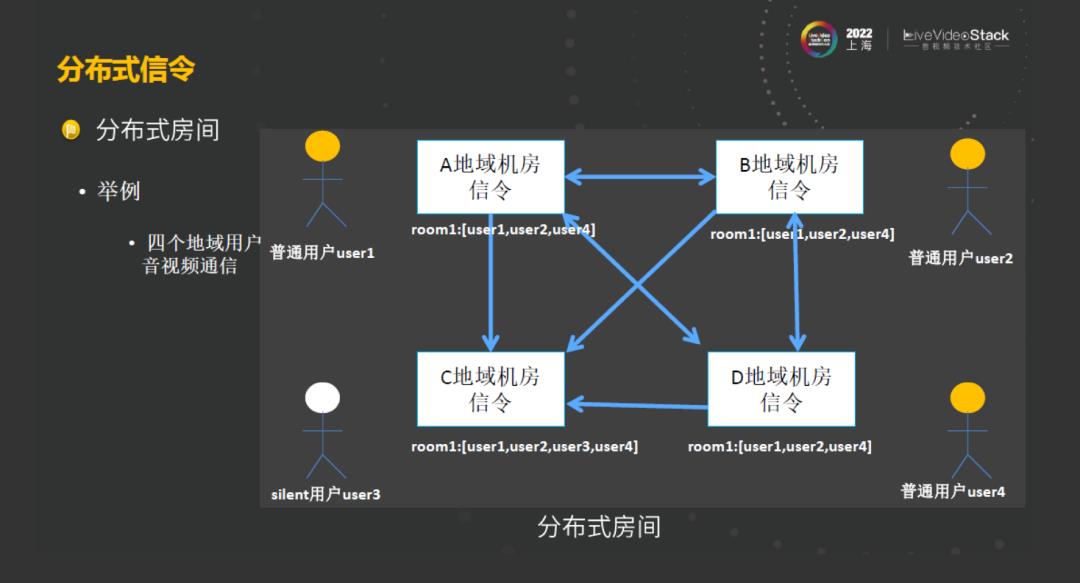
我们举例看一下整个分布式房间的架构是什么样子的?如图,在房间里面的普通用户是可以推流也可以拉流的,这类用户是就近接入最近的中心机房,他们的数据也归属在所在的机房。这时候通过机房之间的数据同步到其他机房去,让其他用户可以感受到该机房用户的一些数据信息。这里面有一个不同的点,其中的用户 3是一个silent user,他只是拉流,其所有用户行为不会对房间里面其他用户产生改变,这类信息不会将用户同步到其他的区域去。分布式房间的这种思想解决了在广域网多中心架构中的跨机房延时的问题,但是这种分布式房间也是有很多挑战的,因为在整个机房的数据同步的过程中,它会带来一些问题,比如丢包、乱序、重复。
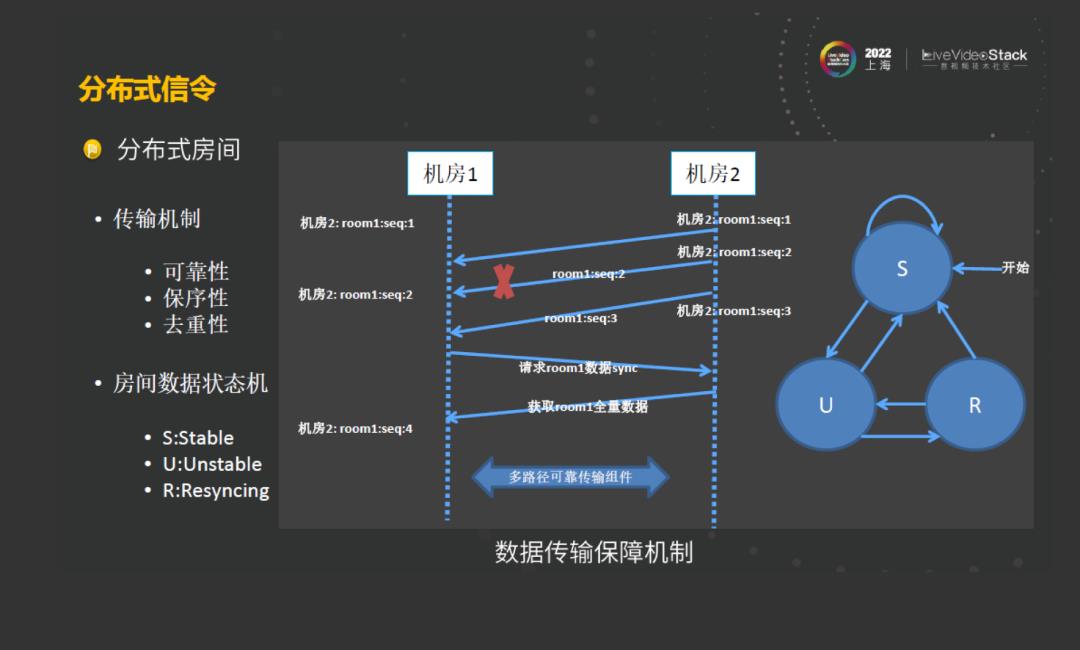
针对这些问题,首先在机房内部采取一个缓存对列的方式,来解决消息去重和保序的问题。在业务层面,因为在多个机房之间,用户信息有自己的所归属的机房,在向其他机房进行同步的时候,我们采取了这种消息序列号所确认的机制,当机房2里面的消息向机房1里面消息进行同步的时候,如果机房1里面所期望的序列号消息不符合预期,那么就会完成一次全量同步的请求。在采取了业务层面上可靠的请求重传的机制后,在房间中的数据序号不一致的时候,就会进入重传的状态,然后重新请求对端机房把数据状态同步过来,来保证整个房间的数据一致。房间里面的状态,始终是在stable,unstable和resyncing之间流转,通过这种房间状态的机制,能保证房间里面的用户数据和流数据的一致性。不仅如此,在上层的可靠传输机制之下,我们还自研了广域网跨机房之间多路性的传输组件。通过组件能保证两个机房之间数据的同步可达性。
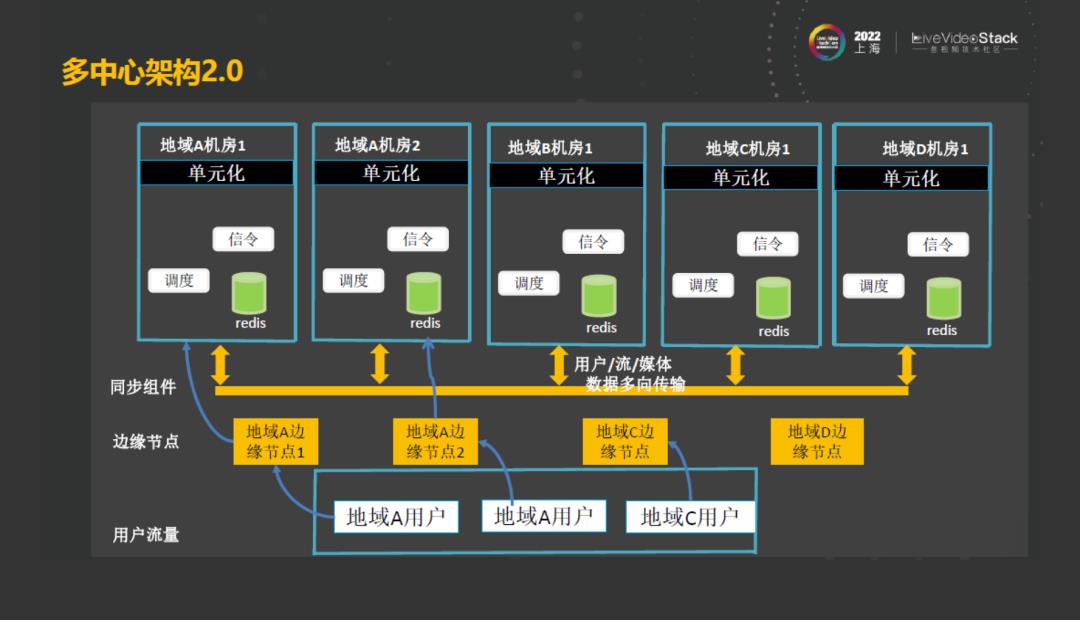
至此,整个多中心2.0的架构,各地的用户通过分布在广域网各地的边缘接点接入。在机房中,边缘节点通过流量控制,能进入到不同的中心机房,实现流量的调度。当中心机房出现了故障的时候,用户流量和边缘机的流量都可以从边缘直接切到其他的机房去。多机房之间的数据实时同步使得在其他的机房都有该房间的副本,当切过去的时候,用户再也不用重新进房了,因为在机房里面已经有全量的数据。所以相对于1.0架构中,用户是可以做到无感知的,也解决了之前系统架构中的容量、容灾问题和就近接入的问题,因为边缘节点的分布,就近程度肯定是比中心机房要离用户更近的。至此,面对用户数的快速增长,我们通过多中心架构2.0完美地解决了这些问题。

接下来,来看一下第二个的挑战-用户音视频传输架构演进:音视频分离和自动订阅。

音视频场景演进越来越复杂,越来越多的人会在音视频通话的过程中会开麦。站在客户端的角度思考一个问题:越来越多的人开麦之后,客户端能承受得住吗?那么我们来看一下这个问题是怎么演进的。
举个例子,在抖音短视频的社交场景中,用户连到最近的边缘节点,然后进行订阅。房间里面假如有N个人,这时候,客户端和边缘媒体服务器会把房间里面的所有的音视频流全部订阅,那么整个客户端的压力和客户端所接入的媒体的压力都是O(N)的。在房间中用户所接入的节点数目,假如是M,那这时候,在整个过程中,边缘节点需要把房间里面所有的音视频流都拉过来,那么所产生的级联规模是O(M*N)。
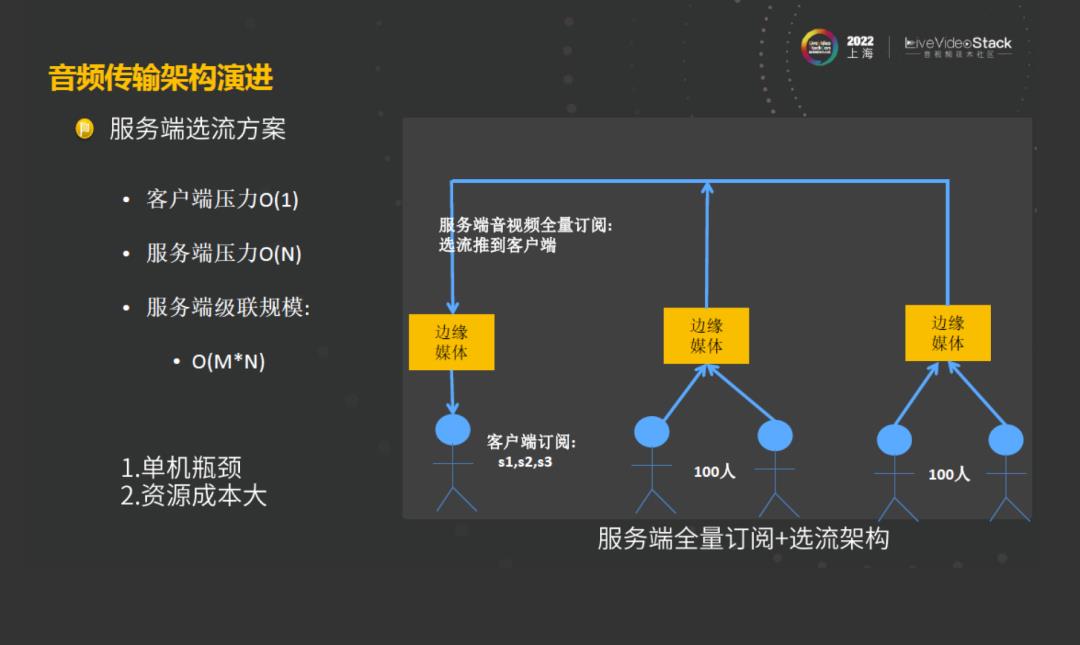
在五人的小房间中,压力是都能承受得住的,当产品越来越复杂,客户端肯定是无法承受。如果将客户端的压力转移到服务端呢?于是有了第二种架构的变化:服务端全量订阅+选流架构。这种架构与前面的架构不同,客户端所接入的边缘节点不再是把所有的音视频流推到客户端,而是按照音频的音量进行一次选流,选出最大的几路流推到客户端。这时候,客户端压力不是O(M*N)了,而是有限的几条流,可以认为是O(1)。在这种架构下,服务端的压力和服务端的规模还是没有改变。那么在这种场景下,当人数越来越多的时候,音频其实不需要把所有的音频都会都拉过来,于是我们对这种架构再次做了升级。
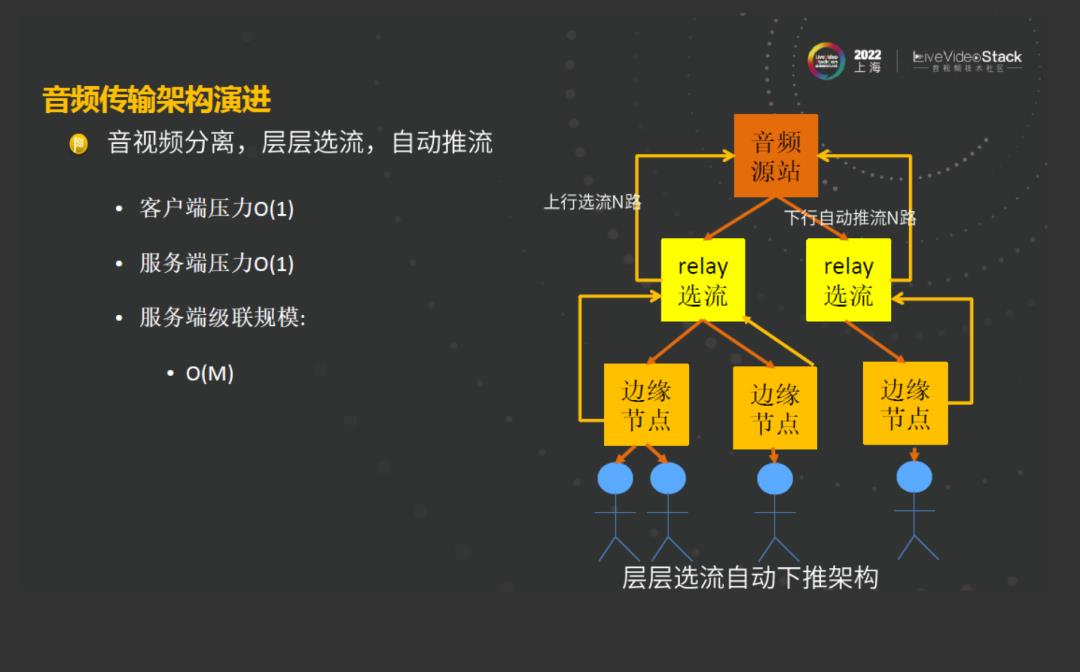
如图是层层选流自动下推架构,这种架构的优点是,用户向边缘节点推流,边缘节点会选择最大的传输流,向上层选流节点进行推送,在上一层的节点中再进行一次选流,推到音频源站,音频源站对二层边缘节点进行选流,再进行层层下推,推到每一个用户所接入的边缘节点。这种架构解决了前面的一个问题,之前每个边缘节点都会把所有的流拉过来,那么单个用户的节点的压力是非常大的,单个节点的资源也是有限的,级联规模比较大,资源浪费比较严重。现在这种层层选流的架构就解决了这个问题,每个节点所承受的压力不再是房间里所有音频和视频的压力,而是用户所接入的音频和视频的压力。
至此,客户端的压力是O(1),服务端通过选流只会对接入的几条流进行计算,服务端压力也从O(N)降到了O(1)。再来看级联规模,级联规模早期是房间里全量流的压级联,现在的级联是每次选完流推到上级节点,有比较好的扩展性,在音频开麦方面解决了人数提升扩展性的难题。

第三个挑战视频传输架构的演进:边缘聚合&树形分发。
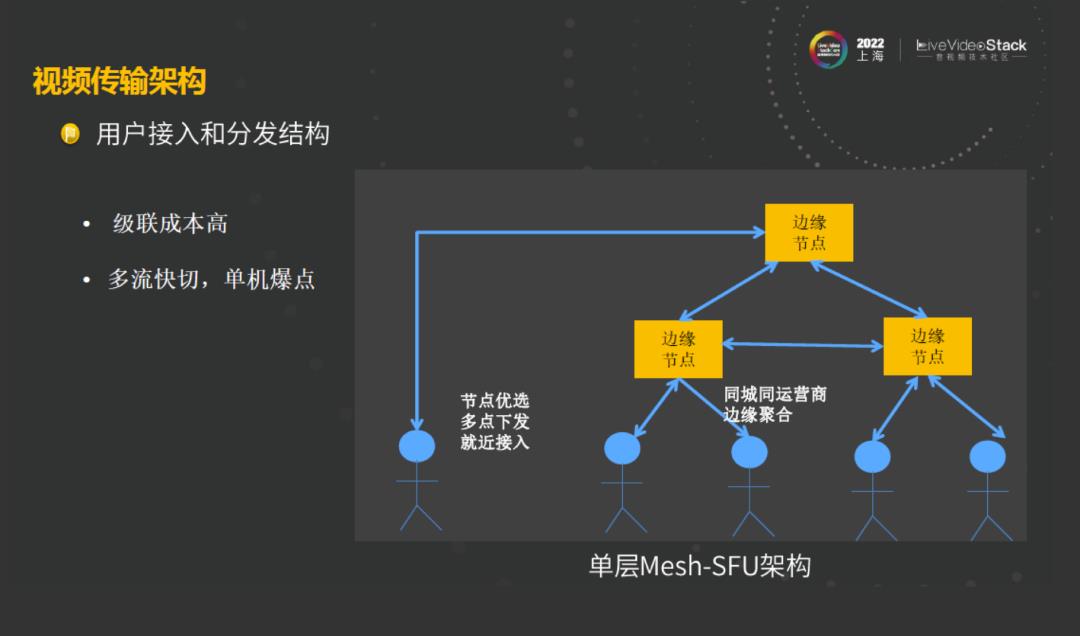
为了提升用户低功率接入的耗时,降低延时,我们在各地部署了海量的边缘节点,用户通过多点接入,多点进行实时探测,就近接入到边缘机房,然后边缘机房之间通过实时传输网来保证稳定传输。在小房间场景中,是可以达到平衡的。但随着视频的增多,例如飞书的千人会议中,所有人打开视频,这种情况下,如果每个用户都接入一个不同视频节点,这样级联视频流的压力是非常大的,成本非常高。如果我们把用户接入到少量节点,用户可能会切换视频的视图,如果切的很快会导致边缘节点压力很大,有可能产生单机爆点,会突然crash掉,这样就会影响用户的体验。为了解决这个问题,我们需要对用户开视频的场景进行边缘聚合。
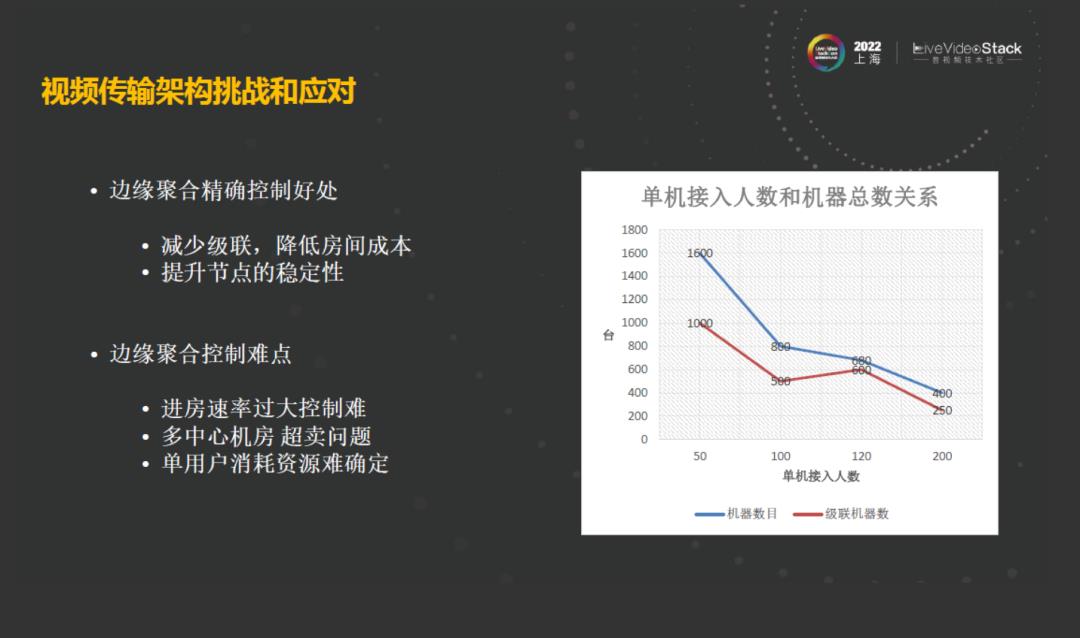
边缘聚合首先是可以减少级联,降低房间成本。第二能提升节点的稳定性。从右图可以看出,在一定范围内的人数的聚合所需要的机器是明显下降的。想要支撑一场千人大会、万人大会,机器成本是显著的降低。但是在整个边缘聚合控制的过程中也有很多难点,因为大房间它有支撑的特点,进房的速度很快,它的速率很大,所以说如果想在某一个节点上面分配100人,或者200、300人,难度是非常大的。第二在于之前采取的是这种多中心机房的架构,对于节点的这种分配会产生一些差别,小概率的会产生一些超卖的问题。第三个是由于对不同场景用户的资源消耗比较难确定的。

由于这三方面的原因,要想做好精确在某个机器上面聚合多少人、按需去聚合、降低房间内的成本,那么该如何解决呢?在前面的架构中,边缘节点和中心机房是实时的三秒钟一次周期性上报它的状态和一些基本数据。在过程中,我们采取了这种售票机制,采用了中心分段分布式锁来保证在单中心里面,对于单节点的售卖是可控的,但是在多中心的情况下,还会产生一些超卖的问题。这时候,会利用边缘节点和中心机房进行双向控制,如果说在售卖的过程中在边缘节点接入过多、导致负载过高的时候,会触发保护策略,拒绝这些用户来接入来保护自己。第三个是为了更好地优化整个售票机制的精准性,就需要对用户整体在线上使用、接入的时候,做一个容量的预估模型。利用过往会议数据中的一些压力数据、用户流的数据,做模型的预估来保障、提升和优化整个模型容量预估中的准确性,从而解决问题。
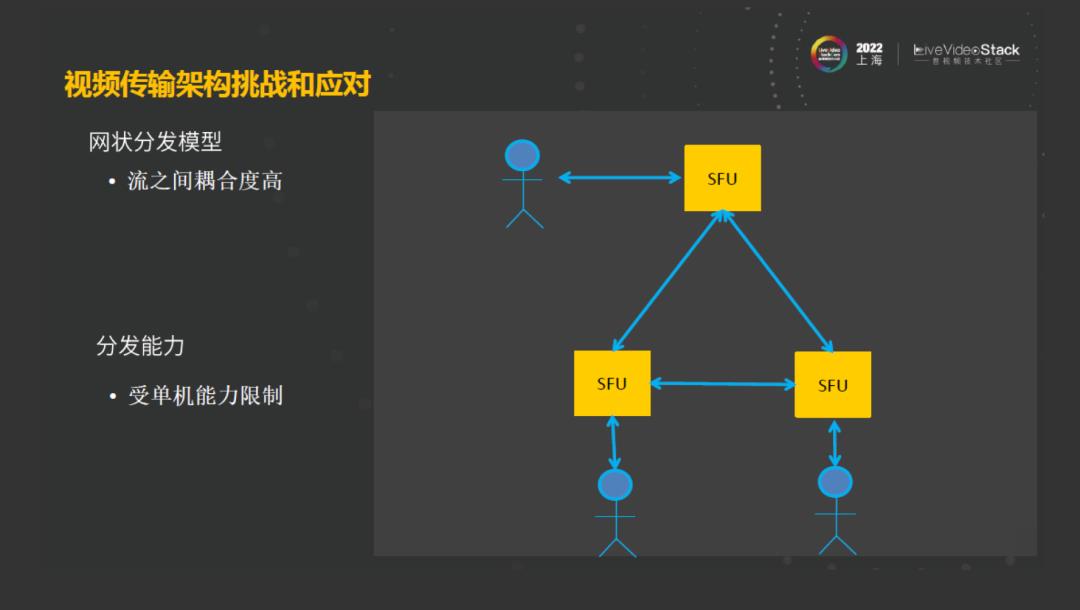
接下来再看,在视频分发过程中,主要用的是网状分发模型,这种模型有很明显的一个特点,因为用户接入到同一个边缘节点,流之间的耦合度是较高的,在千人会议的时候,也许这种模型还是能承受住,但是达到更多人的房间中,这种模型有可能单个SFU节点就已经不能支撑这些级联流的压力了。所以说网状分发结构的架构的分发能力是比较受限的。
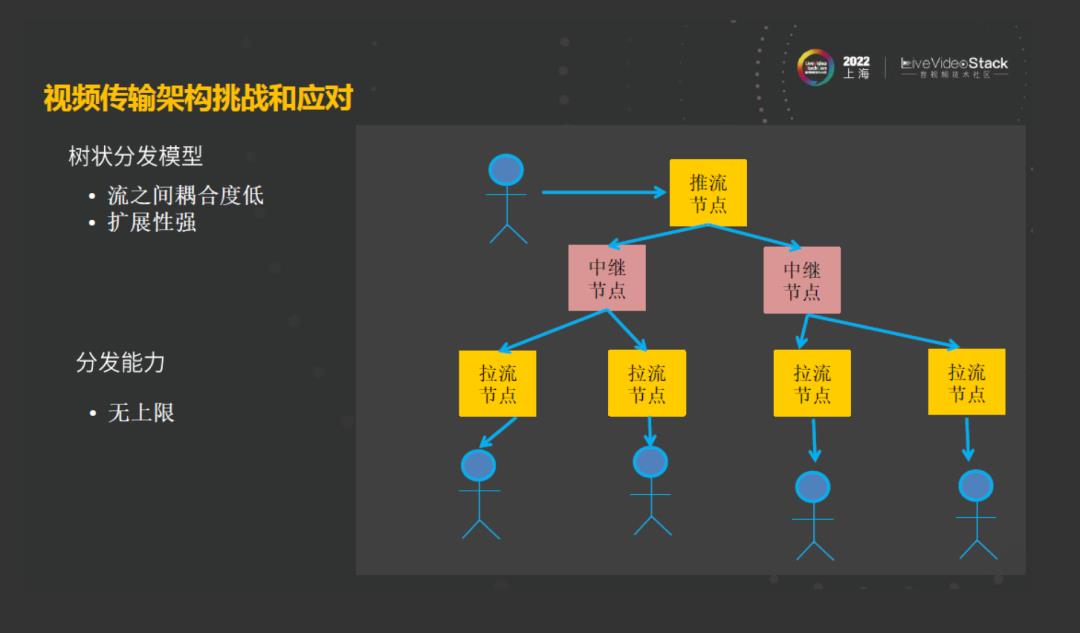
面对这些难题,就引入了树状分发模型,这种模型是针对每一条流,采用一棵分发树,把这些流之间的分发关系进行解耦,它明显相对于网状的架构来说,不会受单个节点的限制。它可以通过中间的节点来进行无限扩展,这种架构也解决了大房间下面无限扩展的能力。
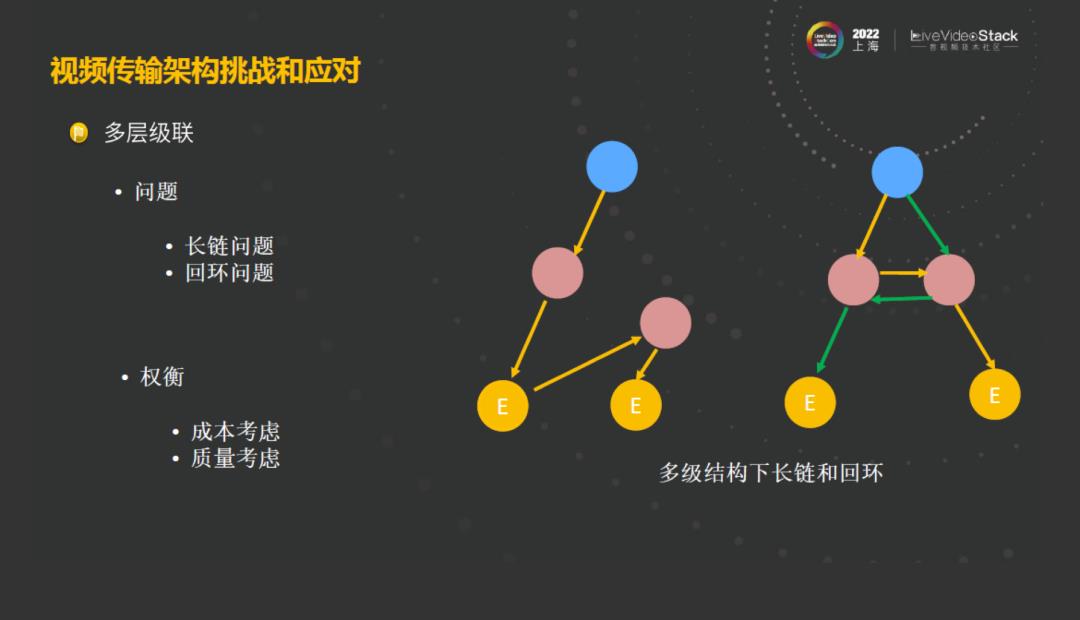
在前面网状的结构中,可能难遇到长链和回环的问题,因为网状之间只有一跳,中间的网络链路的传输主要是靠传输网的保证。在多层级联之后,就会遇到一个问题:从用户推流的地方到拉流有可能遇到长链的问题,就是路径很长;第二个问题,就是在拉流的过程中,有可能会遇上回环的问题。长链的缺点是会浪费带宽,也会影响用户的延迟,因为链路变长了,用户所感受到流的链路的传送延迟就变高了。回环问题会导致在订阅的过程中会出现死锁,看不见对方的情况。
这类问题像长链和回环问题,主要是因为在整个路径规划的过程中并发路径规划导致的,因为有并发存在,所以说这些问题完全是可能存在的。在整个路径规划中,我们不仅要解决长链问题、规划问题,还要考虑成本和质量。

为了规避长链和回环,首先我们将用户的接入节点和分发节点互斥,通过建立中心分发树,边缘节点的定时上报,定时来刷新。在这种机制下面,也许能解决百分之90%以上的长环。但是还有小概率的长环的情况,这时候,我们通过边缘全链路这种回环检测来解决问题,长链问题也是类似的。
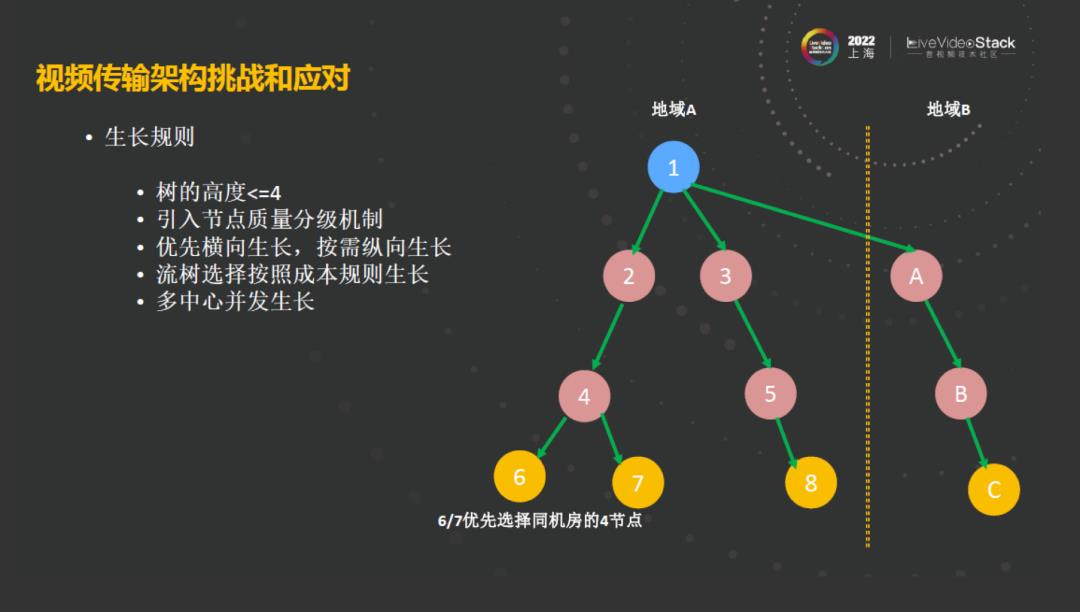
接下来看一下整个分发树在构建过程中生长的规则。我们要对同一颗生长树进行生长,为了保证整个树的成高,从推流点到拉流点,要小于等于4。生长的过程中,我们引入了质量分级的机制,将优质的节点作为分发节点,在生长的过程也会考虑到优先的横向生长,按需纵向生长。比如在节点6和7时,为什么不在5上面生长,而选择4,是因为4、6、7是同一个机房,在同一个机房中拉流时,成本可以降下来。面对这些问题,由于是多中心架构我们还需要考虑多中心并发的生长。
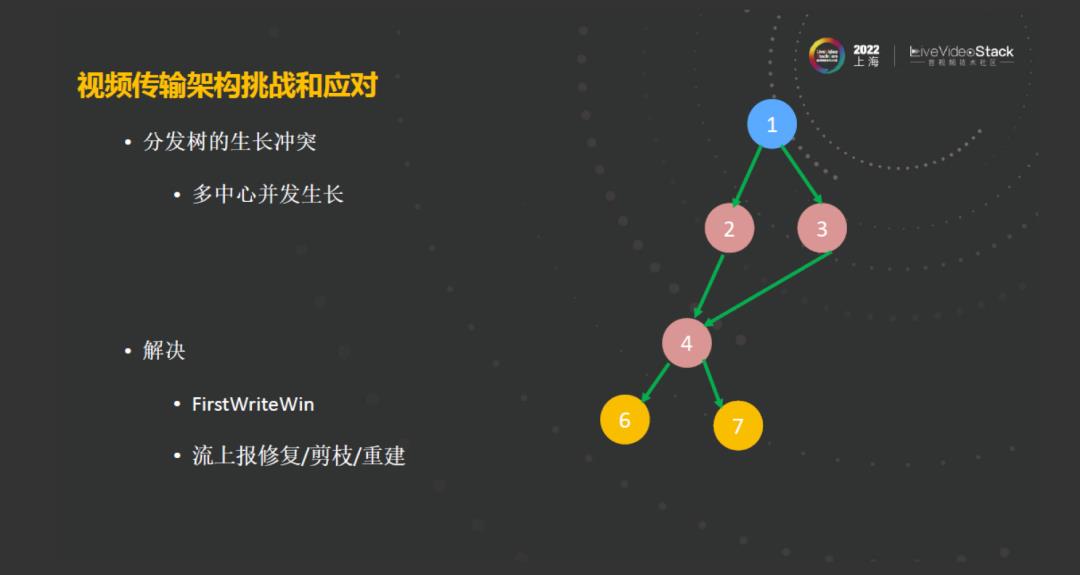
在多中心进行生长的过程中,常常会遇到一类问题,就是在多个中心的生长,比如在路径中有个机房规划的是124,有一个机房规划路径是134,那这时候到底树长成什么样子?这就带来了一些难题,这个问题需要从两个方面去解决,一个方面是采取这种FirstWriteWin的这种机制。第二方面,在这两条路径中,在媒体真正地做级联的时候,我们只会选择其中一条路径进行拉流,那么就解决了冲突的问题。但有时候多中心进行生长、同步的时候会和实际拉流的路径不一致,边缘流就会实时上报路径,定时来修复这棵树,进行修复剪枝和重建。我们这棵树是不需要全球实时同步的,可以容忍短时间内的不一致。
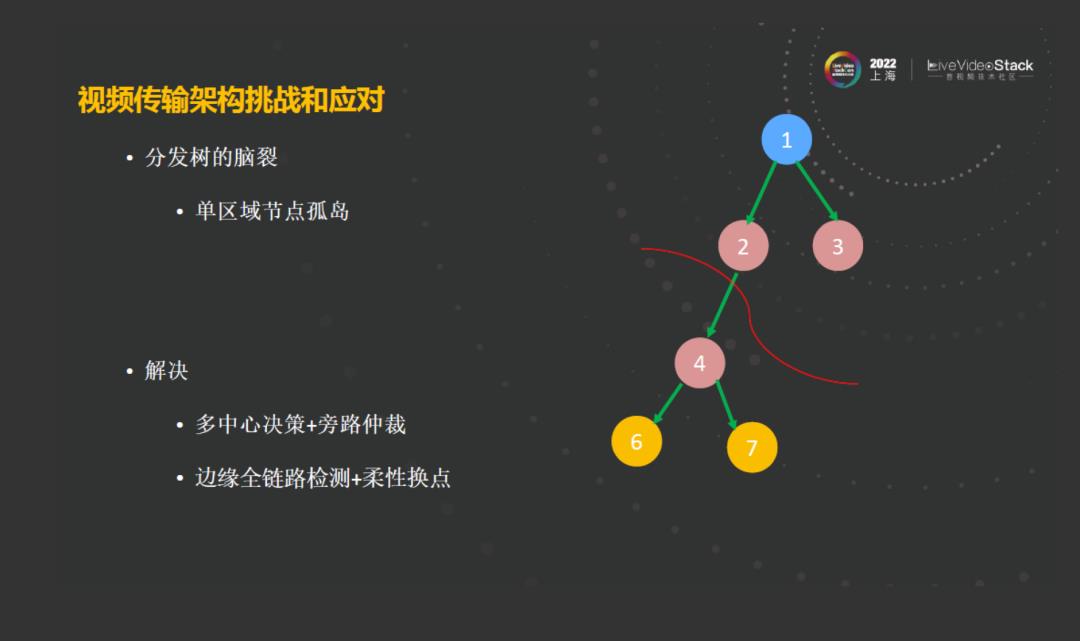
除了上面所说的问题,我们还遇到一个比较常见的问题,也是在整个实践的过程中遇到的一个问题,即出现脑裂。脑裂就是边缘节点467和123不通了。不通也分为两种情况,第一种是完全不通,它和自己的中心机房也不通,但与用户接入没有任何问题,这个边缘节点跟中心机房跟其他的边缘节点不能进行互联了。那这时候我们该怎么办?用户不就割裂了吗?我们在同一个房间里面,有的人在123上面进行,推拉音视频流,有的人在467上面进行推拉音视频流。为了解决这个问题,我们在边缘节点进行了实时的路径检测,当路径不通的时候,通过一个超时机制将用户踢出去,换点到其他区域的机房。
第二种是467与用户和中心机房连通,但是跟其他的边缘节点已经不能互通了,这时候,边缘信令会检测到这种情况,因为多中心机房对各地的边缘节点有实时的感知,知道哪一部分节点是有故障的,此时,有中心机房的信令来通知这个边缘信令,将这一片的区域的用户进行迁出,换到其他区域去,来实现这个房间的用户再次互动,解决这个脑裂问题。整个过程中,只需要十几秒就能恢复。
3、未来演进方向

以上是整个火山引擎RTC在实践过程中遇到的一些难题,也是非常直观的问题,也是各位如果想做万人场景所面临的一些问题,那么对于万人场景未来的演进方向还有哪些要去做的?
在各地的这么多边缘节点,我们未来希望边缘云原生弹性伸缩架构提升边缘节点的扩展能力,这是我们未来要着重做的一件事。
第二,在大房间的情况下,比如在网络研讨会,大讲堂模型房间,未来在哪一方面可以比较多的应用?比如万人语聊房、早期的clubhouse、暑期的超级在线大课堂,包括未来成人的课程、自习室、现在比较火的在线研讨会等,给很多企业,像教育,学术方面都能提供比较好的支撑。大房间的场景会在未来运用的越来越广。
以上是我本次的演讲内容,谢谢大家!


以上是关于万人场景下传输挑战和演进实践的主要内容,如果未能解决你的问题,请参考以下文章