调整拥塞控制的性能
Posted vector6_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了调整拥塞控制的性能相关的知识,希望对你有一定的参考价值。
调整拥塞控制的性能
我们都知道经典的拥塞控制算法会经过慢启动、拥塞避免、快速重传、快速恢复等流程,那拥塞控制的性能受哪些因素的影响呢?
慢启动阶段
理论上,对于TCP流量控制,只要接收方的读缓冲区足够大,就可以通过报文中的接收窗口,要求对方更快地发送数据。网络的传输速度是有限的,它会直接丢弃超过其处理能力的报文。如果网络中的每个连接都按照接收窗口尽可能地发送更多的报文时,就会形成恶性循环,最终超高的网络丢包率会使得每个连接都无法发送数据。所以需要另一种对网络传输速率进行控制的机制,即拥塞控制。
首先TCP连接刚建立时,由于不知道网络的传输能力,为了避免发送超过网络负载的报文,TCP只能先调低发送窗口,减少报文的发送速度。
让发送速度变慢是通过引入拥塞窗口实现。如果不考虑网络拥塞,发送窗口就等于对方的接收窗口,而考虑了网络拥塞后,发送窗口则应当是拥塞窗口与对方接收窗口的最小值。
s
w
n
d
=
m
i
n
(
c
w
n
d
,
r
w
n
d
)
swnd = min(cwnd, rwnd)
swnd=min(cwnd,rwnd)
有了拥塞窗口发送速度就综合考虑了接收方和网络的处理能力。
虽然窗口的计量单位是字节,但为了方便理解,通常我们用 MSS (TCP 报文的最大长度)作为描述窗口大小的单位。如果初始拥塞窗口只有 1 个 MSS,当 MSS 是 1KB,而 RTT 时延是 100ms 时,发送速度只有 10KB/s。所以,当没有发生拥塞时,拥塞窗口必须快速扩大,才能提高互联网的传输速度。因此,慢启动阶段会以指数级扩大拥塞窗口。
虽然指数级提升发送速度很快,但互联网中的很多资源体积并不大,多数场景下,在传输速度没有达到最大时,资源就已经下载完了。即当 MSS 是 1KB 时,多数 HTTP 请求至少包含 10 个报文,即使以指数级增加拥塞窗口,也需要至少 4 个 RTT 才能传输完,因此,我们可以提高初始拥塞控制窗口的大小,以提升开始传输的速率。2013 年 TCP 的初始拥塞窗口调整到了 10 个 MSS(RFC6928),这样1个RTT内就可以传输10KB的请求。然而,如果你需要传输的对象体积更大,BDP 带宽时延积很大时,完全可以继续提高初始拥塞窗口的大小。
因此,你可以根据网络状况和传输对象的大小,调整初始拥塞窗口的大小。调整前,先要清楚你的服务器现在的初始拥塞窗口是多大。你可以通过 ss 命令查看当前拥塞窗口:
# ss -nli|fgrep cwnd
再通过 ip route change 命令修改初始拥塞窗口 init_cwnd:
# ip route | while read r; do
ip route change $r initcwnd 10;
done
当然,若初始拥塞窗口过大,以及指数级的提速,连接很快就会遭遇网络拥塞,从而导致慢启动阶段的结束
拥塞避免阶段
导致慢启动阶段结束的场景有:
- 通过定时器明确探测到了丢包;在规定时间内没有收到 ACK 报文,这说明报文丢失了,网络出现了严重的拥塞,必须先降低发送速度,再进入拥塞避免阶段。
- 拥塞窗口的增长到达了慢启动阈值 ssthresh,虽然还没有发生丢包,但发送方已经达到了曾经发生网络拥塞的速度(拥塞窗口达到了慢启动阈值),接下来发生拥塞的概率很高,所以进入拥塞避免阶段,此时拥塞窗口不能再以指数方式增长,而是要以线性方式增长。
- 接收到重复的 ACK 报文,可能存在丢包。这种场景下TCP为了缩短重发时间,会使用快速重传机制。当连续收到3个重复ACK时,发送方便得到了网络发生拥塞的的明确信号,通过重复 ACK报文的序号,我们知道丢失了哪个报文,这样,不等待定时器的触发,立刻重发丢失的报文,可以让发送速度下降得慢一些。
Linux 上提供了更改拥塞控制算法的配置,可以通过 tcp_available_congestion_control 配置内核支持的算法:
net.ipv4.tcp_congestion_control = cubic
快速重传和快速恢复
快速重传和快速恢复是一起工作的,它们是为了应对丢包这种行为而做的优化,在这种情况下,由于网络并没有出现拥塞,所以拥塞窗口不必恢复到初始值。判断丢包的依据就是收到 3 个相同的 ack。
除了快速重传外,还有一种重传机制是超时重传。不过,这是非常糟糕的一种情况。如果发送出去一个数据包,超过一段时间(RTO)都收不到它的 ack,那就认为是网络出现了拥塞。这个时候就需要将 cwnd 恢复为初始值,再次从慢启动开始调整 cwnd 的大小。RTO 一般发生在网络链路有拥塞的情况下,如果某一个连接数据量太大,就可能会导致其他连接的数据包排队,从而出现较大的延迟。
由上可知,如果 RTO 过大的话,那么业务就可能要阻塞很久,所以在 3.1 版本的内核里引入了一种改进来将 RTO 的初始值从3s调整为1s,这可以显著节省业务的阻塞时间。
对于阻塞式IO,有时网络拥塞可能会引起业务阻塞很久,对于这种情况,我们可以在创建TCP连接时,使用SO_SNDTIMEO 来设置发送超时时间,以防止应用在发送数据的时候阻塞在发送端太久,即:
ret = setsockopt(sockfd, SOL_SOCKET, SO_SNDTIMEO, &timeout, len);
当业务发现该 TCP 连接超时后,就会主动断开该连接,然后尝试去使用其他的连接。
基于测量的拥塞控制算法
上面分析的是传统的基于丢包的拥塞控制算法,然而,网络刚出现拥塞时并不会丢包,而真的出现丢包时,拥塞已经是非常严重了。一般网络层都会有缓冲队列应对突发的、超越处理能力的流量。
当缓冲队列为空时,传输速度最快。一旦队列开始积压,每个报文的传输时间需要增加排队时间,网速就变慢了。而当队列溢出时,才会出现丢包,基于丢包的拥塞控制算法在这个时间点进入拥塞避免阶段,显然太晚了。
进行拥塞控制的最佳时间点,是缓冲队列刚出现积压的时刻,此时网络时延会增高,但带宽维持不变,这两个数值的变化可以给出明确的拥塞信号。
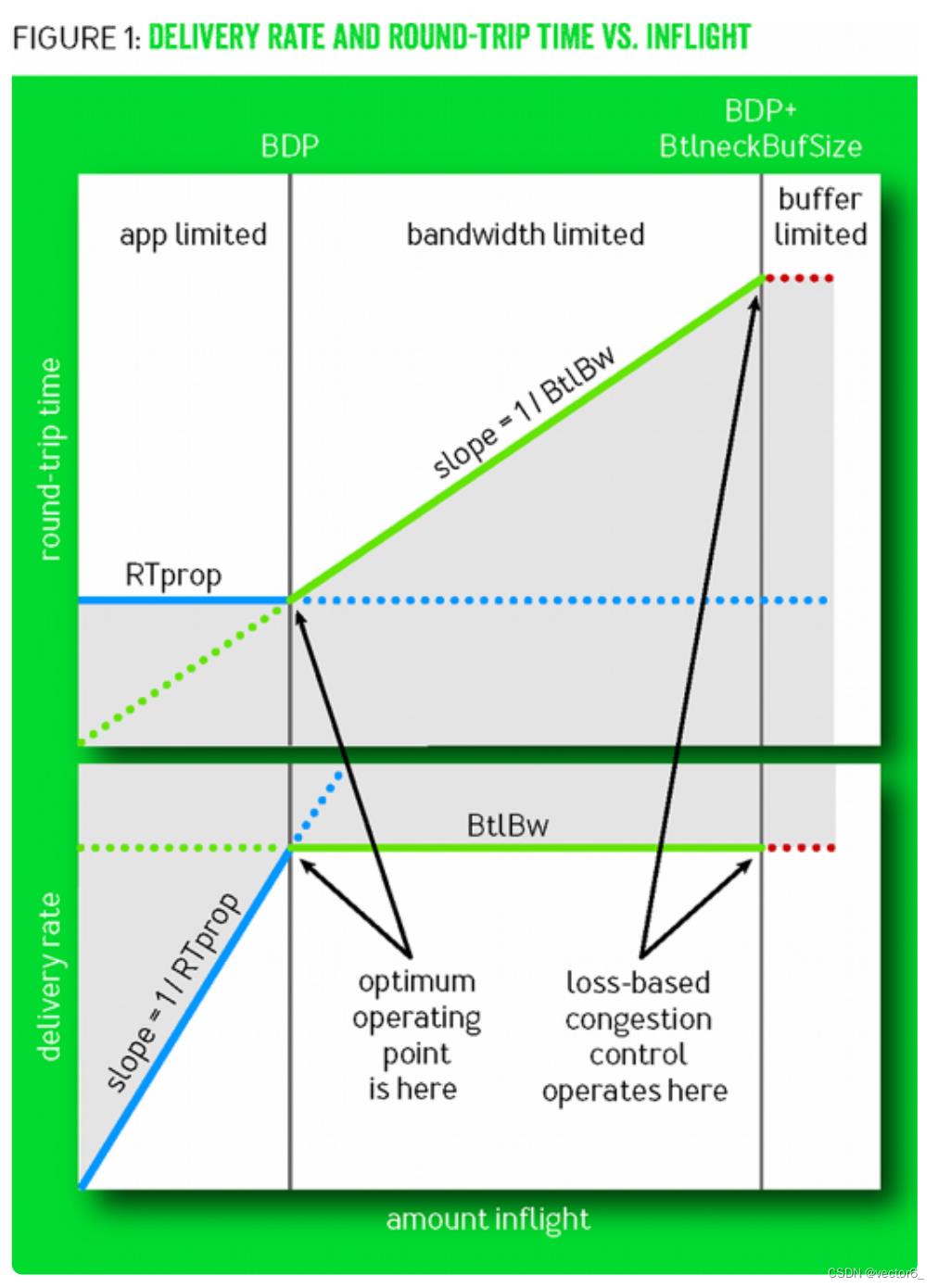
这种以测量带宽、时延来确定拥塞的方法,在丢包率较高的网络中应用效果尤其好。Google推出的BBR算法就是测量驱动的拥塞控制算法。目前在Linux4.9版本之后都支持了BBR算法
以上是关于调整拥塞控制的性能的主要内容,如果未能解决你的问题,请参考以下文章