FlinkFlink 新一代流计算和容错 Unaligned Checkpoint快速Checkpoint更小的Checkpoint
Posted 九师兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FlinkFlink 新一代流计算和容错 Unaligned Checkpoint快速Checkpoint更小的Checkpoint相关的知识,希望对你有一定的参考价值。

1.概述
本文转载:Flink 新一代流计算和容错——阶段总结和展望仅供自我学习,里面的三个检查点相关的,我觉得很重要很清晰,记录一下,防止找不到了。
摘要:本文整理自 Apache Flink 引擎架构师、阿里巴巴存储引擎团队负责人梅源在 Flink Forward Asia 2021 核心技术专场的演讲。本次演讲内容围绕 Flink 的高可用性探讨 Flink 新一代流计算的核心问题和技术选型,包括:
Flink 高可用流计算的关键路径
容错 (Fault Tolerance) 2.0 及关键问题
数据恢复过程
稳定快速高效的 Checkpointing
云原生下容错和弹性扩缩容
2.高可用流计算的关键路径

上图的双向轴线是大数据应用随时间延迟的图谱,越往右边时间延迟要求越短,越往左延迟要求没那么高。Flink 诞生之初大概是在上图中间,可以理解为往右对应的是流式计算,而往左边对应的是批式计算。过去一两年,Flink 的应用图谱向左边有了很大的扩展,也就是我们常说的流批一体;与此同时我们也从来没有停止过把图谱向更实时的方向推进。
Flink 是以流式计算起家,那么向更实时的方向推进到底是指什么?什么是更实时更极致的流式计算?
在正常处理的情况下,Flink 引擎框架本身除了定期去做 Checkpoint 的快照,几乎没有其他额外的开销,而且 Checkpoint 快照很大一部分是异步的,所以正常处理下 Flink 是非常高效的,端到端的延迟在 100 毫秒左右。正因为要支持高效的处理,Flink 在做容错恢复和 Rescale 的时候代价都会比较大:需要把整个作业停掉,然后从过去的快照检查点整体恢复,这个过程大概需要几秒钟,在作业状态比较大的情况下会达到分钟级。如果需要预热或启动其他服务进程,时间就更长了。
所以,Flink 极致流计算的关键点在容错恢复部分。这里说的极致的流计算是指对延迟性、稳定性和一致性都有一定要求的场景,比如风控安全。这也是 Fault Tolerance 2.0 要解决的问题。
3.容错 (Fault Tolerance) 2.0 及关键问题

容错恢复是一个全链路的问题,包括 failure detect、job cancel、新的资源申请调度、状态恢复和重建等。同时,如果想从已有的状态恢复,就必须在正常处理过程中做 Checkpoint,并且将它做得足够轻量化才不会影响正常处理。
容错也是多维度的问题,不同的用户、不同的场景对容错都有不同需求,主要包括以下几个方面:
数据一致性 (Data Consistency),有些应用比如在线机器学习是可以容忍部分数据丢失;延迟 (Latency),某些场景对端到端的延迟要求没那么高,所以可以将正常处理和容错恢复的时候要做的工作综合平均一下;恢复时的行为表现 (Recovery Behavior),比如大屏或者报表实时更新的场景下,可能并不需要迅速全量恢复,更重要的在于迅速恢复第一条数据;代价 (Cost),用户根据自己的需求,愿意为容错付出的代价也不一样。
综上,我们需要从不同的角度去考虑这个问题。
另外,容错也不仅仅是 Flink 引擎侧的问题。Flink 和云原生的结合是 Flink 未来的重要方向,我们对于云原生的依赖方式也决定了容错的设计和走向。我们期望通过非常简单的弱依赖来利用云原生带来的便利,比如 across region durability,最终能够将有状态的 Flink 的应用像原生的无状态应用一样弹性部署。
基于以上考虑,我们在 Flink 容错 2.0 工作也有不同的侧重点和方向。
第一,从调度的角度来考虑,每次错误恢复的时候,不会把和全局快照相对应的所有 task 节点都回滚,而是只恢复失败的单个或者部分节点,这个对需要预热或单个节点初始化时间很长的场景是很有必要的,比如在线机器学习场景。与此相关的一些工作比如 Approximate Task-local Recovery 已在 VVP 上线;Exactly-once Task-local Recovery,我们也已经取得了一些成果。
接下来重点聊一下 Checkpoint 以及和云原生相关的部分。
4.Flink 中的数据恢复过程
那么,容错到底解决了什么?在我看来其本质是解决数据恢复的问题。

Flink 的数据可以粗略分为以下三类
- 第一种是元信息,相当于一个 Flink 作业运行起来所需要的最小信息集合,包括比如 Checkpoint 地址、Job Manager、Dispatcher、Resource Manager 等等,这些信息的容错是由 Kubernetes/Zookeeper 等系统的高可用性来保障的,不在我们讨论的容错范围内。
- Flink 作业运行起来以后,会从数据源读取数据写到 Sink 里,中间流过的数据称为处理的中间数据 Inflight Data (第二类
- 对于有状态的算子比如聚合算子,处理完输入数据会产生算子状态数据 (第三类)。
Flink 会周期性地对所有算子的状态数据做快照,上传到持久稳定的海量存储中 (Durable Bulk Store),这个过程就是做 Checkpoint。Flink 作业发生错误时,会回滚到过去的一个快照检查点 Checkpoint 恢复。
我们当前有非常多的工作是针对提升 Checkpointing 效率来做的,因为在实际工作中,引擎层大部分 Oncall 或工单问题基本上都与 Checkpoint 相关,各种原因会造成 Checkpointing 超时。
下面简单回顾一下 Checkpointing 的流程,对这部分内容比较熟悉的同学可以直接跳过。Checkpointing 的流程分为以下几步:
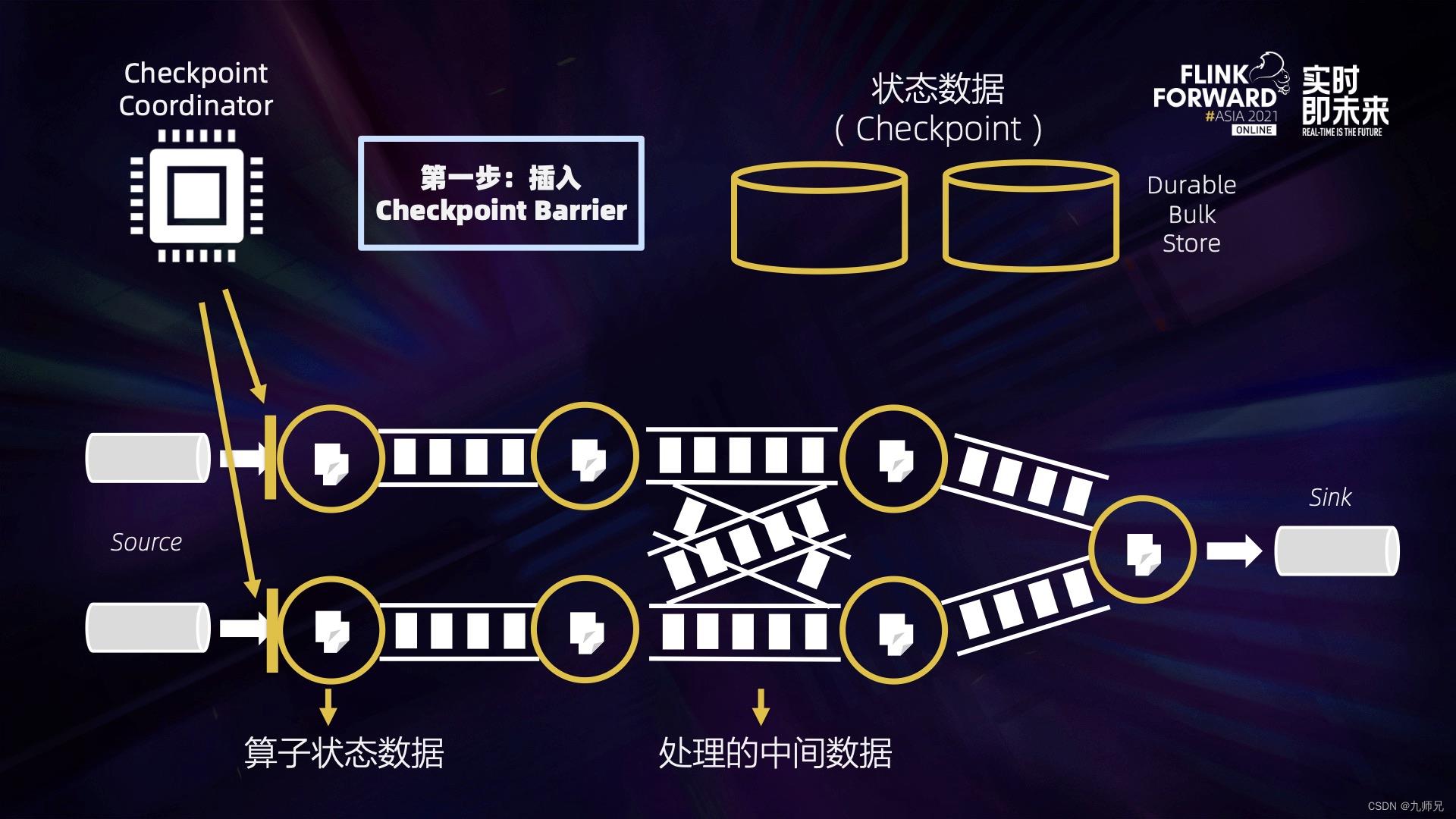
第一步:Checkpoint Coordinate 从 Source 端插入 Checkpoint Barrier (上图黄色的竖条)。

第二步:Barrier 会随着中间数据处理向下游流动,流过算子的时候,系统会给算子的当前状态做一个同步快照,并将这个快照数据异步上传到远端存储。这样一来,Barrier 之前所有的输入数据对算子的影响都已反映在算子的状态中了。如果算子状态很大,会影响完成 Checkpointing 的时间。

第三步:当一个算子有多个输入的时候,需要算子拿到所有输入的 Barrier 之后才能开始做快照,也就是上图蓝色框的部分。可以看到,如果在对齐过程中有反压,造成中间处理数据流动缓慢,没有反压的那些线路也会被堵住,Checkpoint 会做得很慢,甚至做不出来。

第四步:所有算子的中间状态数据都成功上传到远端稳定存储之后, 一个完整的 Checkpoint 才算真正完成。
从这 4 个步骤中可以看到,影响快速稳定地做 Checkpoint 的因素主要有 2 个,一个是处理的中间数据流动缓慢,另一个是算子状态数据过大,造成上传缓慢,下面来讲一讲如何来解决这两个因素。
5.稳定快速高效的 Checkpointing
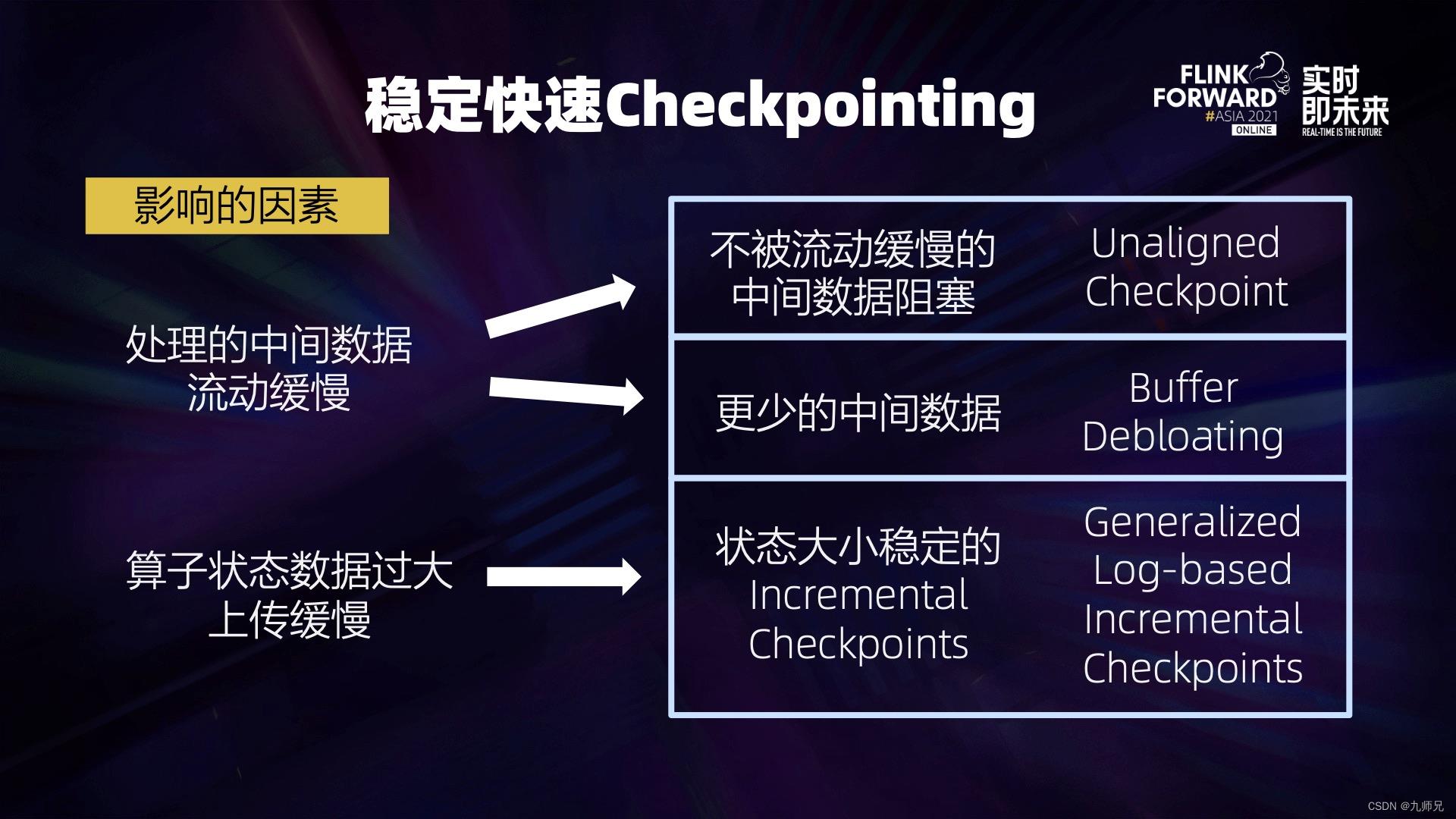
针对中间数据流动缓慢,可以:
- 想办法不被中间数据堵塞:Unaligned Checkpoint——直接跳过阻塞的中间数据;
- 或者让中间的数据变得足够少: Buffer Debloating。
- 针对状态数据过大,我们需要将每次做 Checkpoint 时上传的数据状态变得足够小:Generalized Log-Based Incremental Checkpoint。
下面来具体展开阐述每一种解决方法。
6.Unaligned Checkpoint

Unaligned Checkpoint 的原理是将从 Source 插入的 Barrier 跳过中间数据瞬时推到 Sink,跳过的数据一起放在快照里。所以对于 Unaligned Checkpoint 来说,它的状态数据不仅包括算子的状态数据,还包括处理的中间数据,可以理解成给整个 Flink Pipeline 做了一个完整的瞬时快照,如上图黄色框所示。虽然 Unaligned Checkpoint 可以非常快速地做 Checkpoint,但它需要存储额外的 Pipeline Channel 的中间数据,所以需要存储的状态会更大。Unaligned Checkpoint 在去年 Flink-1.11 版本就已经发布,Flink-1.12 和 1.13 版本支持 Unaligned Checkpoint 的 Rescaling 和动态由 Aligned Checkpoint 到 Unaligned Checkpoint 的切换。
7.Buffer Debloating
Buffer Debloating 的原理是在不影响吞吐和延迟的前提下,缩减上下游缓存的数据。经过观察,我们发现算子并不需要很大的 input/output buffer。缓存太多数据除了让作业在数据流动缓慢时把整个 pipeline 填满,让作业内存超用 OOM 以外,没有太大的帮助。

这里可以做个简单的估算,对于每个 task,无论是输出还是输入,我们总的 buffer 数目大概是每个 channel 对应的 exclusive buffer 数乘以 channel 的个数再加上公用的 floating buffer 数。这个 buffer 总数再乘以每个 buffer 的 size,得到的结果就是总的 local buffer pool 的 size。然后我们可以把系统默认值代进去算一下,就会发现并发稍微大一点再多几次数据 shuffle,整个作业中间的流动数据很容易就会达到几个 Gigabytes。
实际中我们并不需要缓存这么多数据,只需要足够量的数据保证算子不空转即可,这正是 Buffer Debloating 做的事情。Buffer Debloating 能够动态调整上下游总 buffer 的大小,在不影响性能的情况下最小化作业所需的 buffer size。目前的策略是上游会动态缓存下游大概一秒钟能够处理的数据。此外,Buffer Debloating 对 Unaligned Checkpoint 也是有好处的。因为 Buffer Debloating 减少了中间流动的数据,所以 Unaligned Checkpoint 在做快照的时候,需要额外存储的中间数据也会变少。
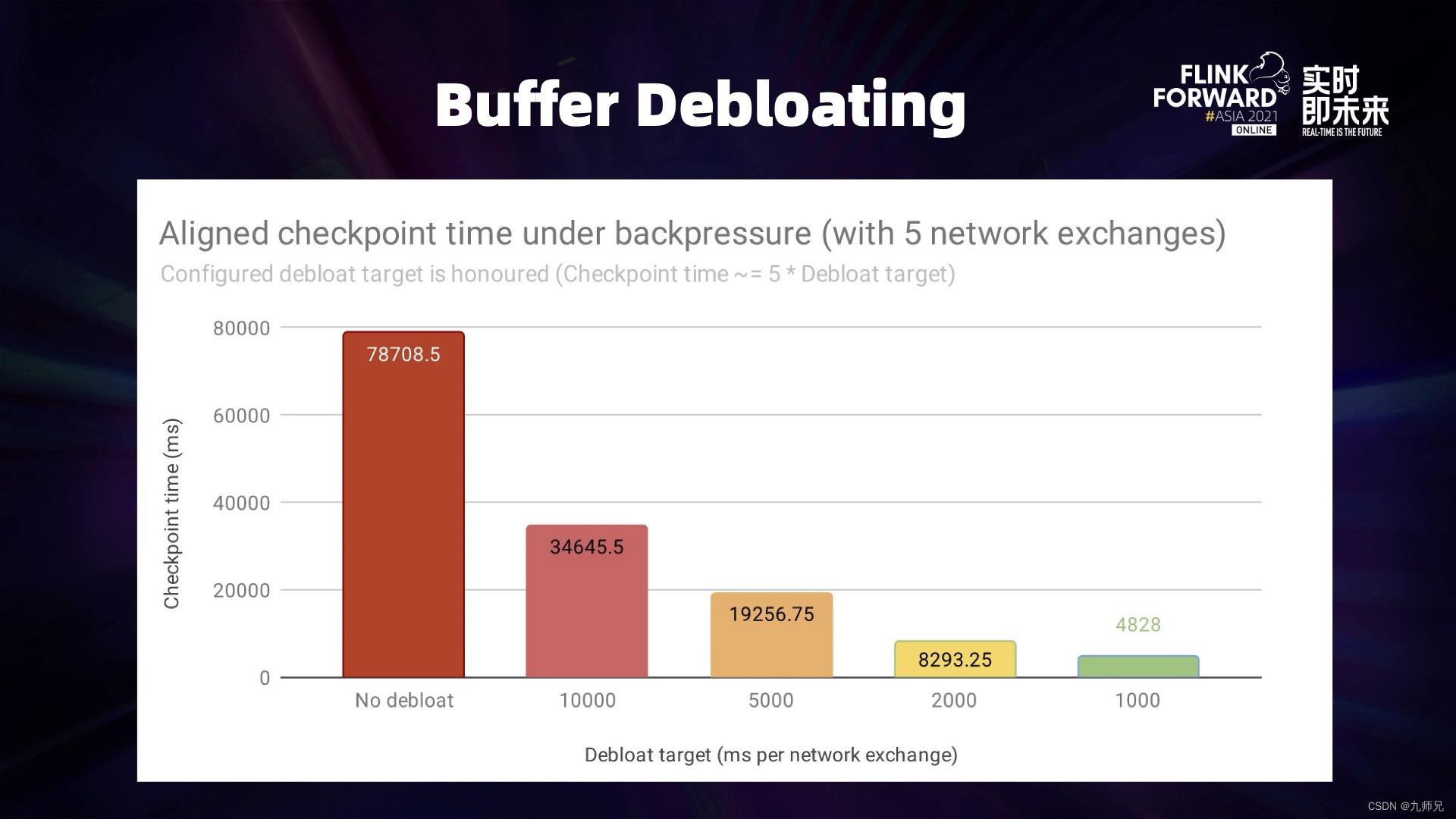
上图是对 Buffer Debloating 在反压的情况下,Checkpointing 时间随 Debloat Target 变化的时间对比图。Debloat Target 是指上游缓存 “预期时间” 内下游能处理的数据。这个实验中,Flink 作业共有 5 个 Network Exchange,所以总共 Checkpointing 所需的时间大约等于 5 倍的 Debloat Target,这与实验结果也基本一致。
8.Generalized Log-Based Incremental Checkpoint
前面提到状态大小也会影响完成 Checkpointing 的时间,这是因为 Flink 的 Checkpointing 过程由两个部分组成:同步的快照和异步上传。同步的过程通常很快,把内存中的状态数据刷到磁盘上就可以了。但是异步上传状态数据的部分和上传的数据量有关,因此我们引入了 Generalized Log-Based Incremental Checkpoint 来控制每次快照时需要上传的数据量。

对于有状态的算子,它的内部状态发生改变后,这个更新会记录在 State Table 里,如上图所示。当 Checkpointing 发生的时候,以 RocksDB 为例,这个 State Table 会被刷到磁盘上,磁盘文件再异步上传到远端存储。根据 Checkpoint 的模式,上传的部分可以是完整的 Checkpoint 或 Checkpoint 增量部分。但无论是哪种模式,它上传文件的大小都是与 State Backend 存储实现强绑定的。例如 RocksDB 虽然也支持增量 Checkpoint,但是一旦触发多层 Compaction,就会生成很多新的文件,而这种情况下增量的部分甚至会比一个完整的 Checkpoint 更大,所以上传时间依然不可控。
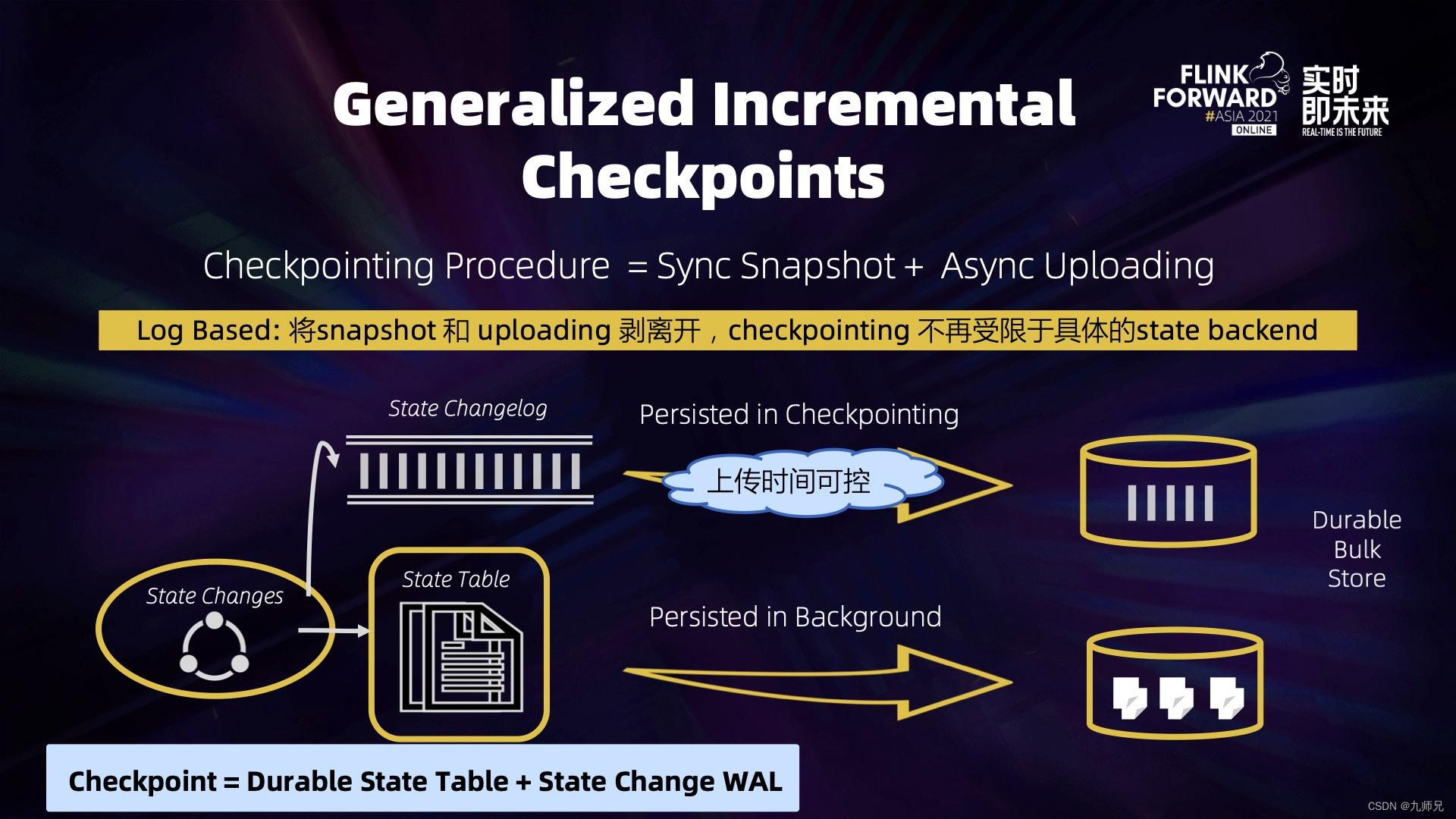
既然是上传过程导致 Checkpointing 超时,那么把上传过程从 Checkpointing 过程中剥离开来就能解决问题。这其实就是 Generalized Log-Based Incremental Checkpoint 想要做的事情:本质上就是将 Checkpointing 过程和 State Backend 存储 Compaction 完全剥离开。
具体实现方法如下:对于一个有状态的算子,我们除了将状态更新记录在 State Table 里面,还会再写一份增量到 State Changelog,并将它们都异步的刷到远端存储上。这样,Checkpoint 变成由两个部分组成,第一个部分是当前已经物化存在远端存储上的 State Table,第二个部分是还没有物化的增量部分。因此真正做 Checkpoint 的时候,需要上传的数据量就会变得少且稳定,不仅可以把 Checkpoint 做得更稳定,还可以做得更高频。可以极大缩短端到端的延迟。特别对于 Exactly Once Sink,因为需要完成完整的 Checkpoint 以后才能完成二阶段提交。
9.云原生下容错和弹性扩缩容
在云原生的大背景下,快速扩缩容是 Flink 的一大挑战,特别是 Flink-1.13 版本引入了 Re-active Scaling 模式后,Flink 作业需要频繁做 Scaling-In/Out,因此 Rescaling 已成为 Re-active 的主要瓶颈。Rescaling 和容错 (Failover) 要解决的问题在很大程度上是类似的:例如拿掉一台机器后,系统需要快速感知到,需要重新调度并且重新恢复状态等。当然也有不同点,Failover 的时候只需要恢复状态,将状态拉回到算子上即可;但 Rescaling 的时候,因为拓扑会导致并行度发生变化,需要重新分配状态。

状态恢复的时候,我们首先需要将状态数据从远端存储读取到本地,然后根据读取的数据重新分配状态。如上图所示,整个这个过程在状态稍大的情况下,单个并发都会超过 30 分钟。并且在实际中,我们发现状态重新分配所需要的时间远远大于从远端存储读取状态数据的时间。

那么状态是如何重新分配的呢?Flink 的状态用 Key Group 作为最小单位来切分,可以理解成把状态的 Key Space 映射到一个从 0 开始的正整数集,这个正整数集就是 Key Group Range。这个 Key Group Range 和算子的所允许的最大并发度相关。如上图所示,当我们把算子并发度从 3 变成 4 的时候,重新分配的 Task1 的状态是分别由原先的两个 Task 状态的一部分拼接而成的,并且这个拼接状态是连续且没有交集的,所以我们可以利用这一特性做一些优化。

上图可以看到优化后,DB Rebuild 这部分优化效果还是非常明显的,但目前这部分工作还处于探索性阶段,有很多问题尚未解决,所以暂时还没有明确的社区计划。
最后简单回顾一下本文的内容。我们首先讨论了为什么要做容错,因为容错是 Flink 流计算的关键路径;然后分析了影响容错的因素,容错是一个全链路的问题,包括 Failure Detection、Job Canceling、新的资源申请调度、状态恢复和重建等,需要从多个维度去权衡思考这个问题;当前我们的重点主要是放在如何稳定快速做 Checkpoint 的部分,因为现在很多实际的问题都和做 Checkpoint 相关;最后我们讨论了如何将容错放在云原生的大背景下与弹性扩缩容相结合的一些探索性工作。
以上是关于FlinkFlink 新一代流计算和容错 Unaligned Checkpoint快速Checkpoint更小的Checkpoint的主要内容,如果未能解决你的问题,请参考以下文章
FlinkFlink 1.13 Flink SQL 新特性 性能优化 时区 时间 纠正