设备名称聚类:增加有设备分类号信息
Posted 卓晴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了设备名称聚类:增加有设备分类号信息相关的知识,希望对你有一定的参考价值。
简 介: 本文在设备名称聚类过程中,增加了设备分类信息。 通过实验可以看到,增加了设备分类信息之后,通过SOM聚类的效果有所提升。在SOM 聚类的基础上,对于聚类前9的子类设备所使用的时间进行分布分析,并给出了指数分布对应的参数以及这些参数随着年份的变化。对应的变化数据背后的物理解释还需要根据设备管理内容做进一步的解释和分析。对于聚类前9个子列的设备名称参见: 设备子类名称 .
关键词: 设备名称,使用时间,数据分布
§01 设备名称聚类
一、背景介绍
在 设备管理中设备名称聚类分析 对于 来自于 JYH 提供的 五年(2017 - 2021) 中的设备使用时间进行了初步统计,通过讨论,下面计划进行如下几点探究:
- 在聚类中,除了设备名称之外,增加设备的 “分类号” 信息;
- 对于聚类出现的使用时间分布,求取对应的指数分布参数;
- 探究这些参数在 五年变化中的情况。
使用的数据来源:
- 原始的EXCEL表格: 在 设备管理中数据聚类处理-预处理 中的 【1-2-1】中的EXCEL数据文件。
- 预处理后的DOP文档:在 设备管理中设备名称聚类分析 中最开始的插图稳健。

▲ 原始EXCEL表格

▲ 预处理DOP文件
二、数据预处理
1、设备分类号
下面给出了EXCEL表格中提取出来的主要属性字段,第二栏是设备的分类号。
[['12026444' '04060300' '三室真空定向炉 ' '0.0' '科研' 'ZGD-10BYF' '0']
['12005527' '03040404' '光电发射光谱仪' '0.0' '科研' 'PDA-7000' '0']
['07001233' '03040100' '高分辨率磁力显微镜' '0.0' '教学' 'HR-MFM' '0']
['10016800' '03060301' '超高真空电子束镀膜机' '0.0' '科研' 'SCTES-15CUHV' '0']
['12013022' '03060302' '高真空共溅镀仪' '0.0' '科研' 'LJ-103' '0']
['04004740' '03040100' '原子力显微镜' '0.0' '科研' 'MAC-picoplus' '0']
['00001133' '03030226' '热分析系统' '0.0' '公共服务' 'TGA2050' '0']
['02000177' '03052207' '高级扩展流变仪' '0.0' '公共服务' 'MCR300' '0']
['15031006' '04220304' '粉末烧结快速成形机' '0.0' '科研' 'HK S320' '0']
['08005388' '03040702' '场发射扫描电镜' '0.0' '公共服务' 'S-4500' '0']]
对照 《高等学校固定资产分类与代码》中关于设备标号,分析可知在 EXCEL 表格中的 设备分类号应该对于编号的 8 - 15 位。因此,将分类号前面 8 位,每两位形成一个数字,这样就形成 分类号的 四个属性。

▲ 图1.2.1 高等学校固定资产分类与代码
将上述分类属性加入原来的 150 维度的字典之后,形成最后的名称数据向量。
2、设备属性向量
设备属性向量长度为 154, 分成两段:
- 前 150 维 是名称的矢量,使用来自于名称分词之后,出现频次最高的前 150 个词语进行 one-hot 编码;
- 后 4 维 是来自于设备的分类号所形成的 4个维度。
from headm import *
cutname = tspload('namecut', 'cutname')
attrstr, alldata = tspload('alldata', 'attrstr', 'alldata')
wordall = tspload('word', 'wordall')
dictlen = 150
dictdim = [w[0] for w in wordall[:dictlen]]
namevect = []
matchnum = 0
for id,n in enumerate(cutname):
nn = [s for s in n.split('`') if len(s.strip(' ')) > 0]
classn = alldata[id][1]
nv = []
flag = 0
for d in dictdim:
if d in nn:
nv.append(1)
flag = 1
else:
nv.append(0)
if classn.isdigit() and len(classn) >= 8:
for i in range(4):
nv.append(int(classn[i*2:i*2+2]))
namevect.append(nv)
matchnum += flag
if id % 100 == 0: printf('%d:%d'%(id, matchnum))
printf(matchnum, len(namevect))
tspsave('namevect154', namevect=namevect)
printf(wordall[:100])
输出的数据文件存储在: namevect154.npz
三、设备聚类分析
1、设备聚类
仍然使用 SOM(自组织特征映射) 网络对于设备名称进行聚类,聚类的结果存储在 prediction.npz中。
#!/usr/local/bin/python
# -*- coding: gbk -*-
#============================================================
# NAMECLUST.PY -- by Dr. ZhuoQing 2022-08-13
#
# Note:
#============================================================
from headm import *
from sklearn_som.som import SOM
namevect = tspload('namevect154', 'namevect')
SOM_SIDE = 10
VECT_LEN = shape(namevect)[1]
name_som = SOM(m=SOM_SIDE,n=SOM_SIDE,dim=VECT_LEN)
name_som.fit(namevect)
predictions = name_som.predict(namevect)
tspsave('prediction', pred=predictions)
printf('\\a')
printf(predictions)
#------------------------------------------------------------
# END OF FILE : NAMECLUST.PY
#============================================================
2、聚类结果分析
聚类的结果数值为:
190 023 101 123 108 161 071 157 044 564
086 043 038 086 125 058 021 092 004 155
172 064 081 029 037 017 082 275 159 284
101 121 098 075 017 229 088 057 381 023
045 269 228 210 052 178 258 326 022 264
117 149 081 032 071 055 040 092 254 177
010 082 099 035 100 126 055 025 083 222
198 048 060 024 027 000 156 071 134 075
182 170 091 024 290 024 060 057 036 148
191 145 087 045 107 073 086 074 095 356

▲ SOM聚类结果命中频率分布
下面给出聚类结果每个子类别命中频次排列,可以相比于只使用设备名称,增加有设备分类号之后的聚类结果,各个子类频次分布更加的均匀了。
[564, 381, 356, 326, 290, 284, 275, 269, 264, 258, 254, 229, 228, 222, 210, 198, 191, 190, 182, 178, 177, 172, 170, 161, 159, 157, 156, 155, 149, 148, 145, 134, 126, 125, 123, 121, 117, 108, 107, 101, 101, 100, 99, 98, 95, 92, 92, 91, 88, 87, 86, 86, 86, 83, 82, 82, 81, 81, 75, 75, 74, 73, 71, 71, 71, 64, 60, 60, 58, 57, 57, 55, 55, 52, 48, 45, 45, 44, 43, 40, 38, 37, 36, 35, 32, 29, 27, 25, 24, 24, 24, 23, 23, 22, 21, 17, 17, 10, 4, 0]
下面给出了聚类之后,每个子类对应的分布直方图:
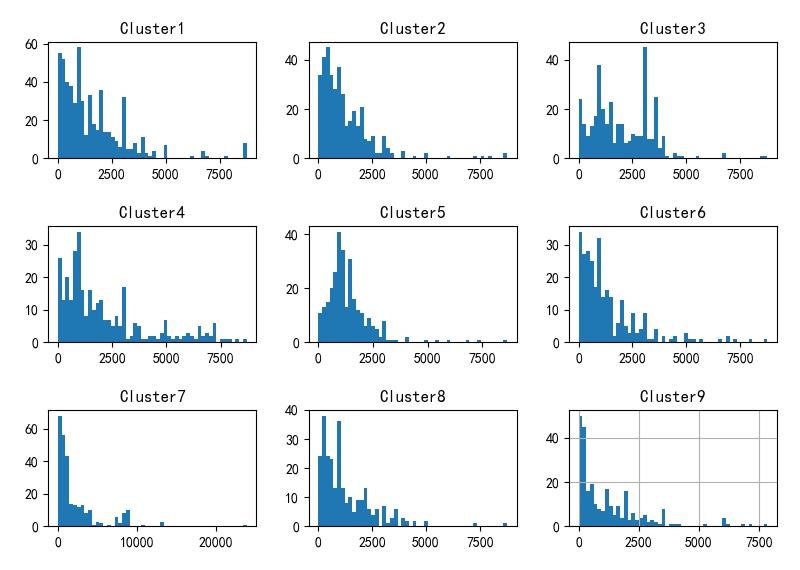
▲ 聚类前10个子类使用时间直方图
通过对比,可以看到通过增加设备的分类号属性,自类对应的分布直方图发生了比较大的改变。特别是有些子类的分布已经明显不在属于 指数分布 的情况。
对于每个聚类子类所包含的设备名称可以参见: 增加设备分类号之后,设备名称SOM聚类前九个子类 中给出的结果。
3、指数分布参数
根据 统计数据背后的指数分布模型 中分析所使用的方法, 对于前面每个子类的直方图进行指数分布拟合,从数值上对比它们的分布与整体设备使用时间分布参数之间的差异。
指数分布的公式为如下,它包括两个参数: a , b a,b a,b 。
f B I N [ x ] = a ⋅ e − b x f_BIN \\left[ x \\right] = a \\cdot e^ - bx fBIN[x]=a⋅e−bx
使用曲线拟合之后,会得到拟合的协方差矩阵,选择矩阵的 [ 0 , 0 ] \\left[ 0,0 \\right] [0,0] 参数衡量拟合的方差。
所以每个拟合都会包括有三个参数: a,b,c。
(1)所有数据分布参数
下面给出了 11532 个 所有设备记录中指数拟合对应的参数。
- a=3058.687106,
- b=0.000628,
- c=2729.977329
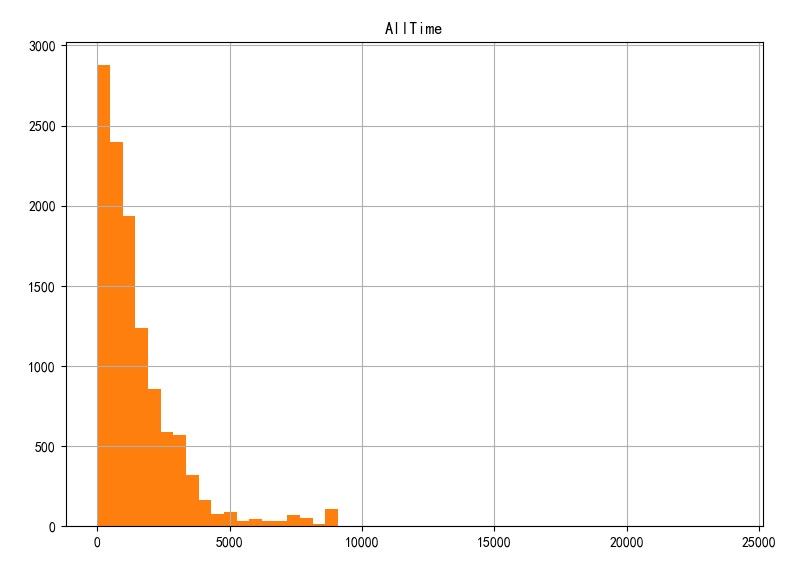
▲ 所有数据使用时间分布
(2)前面九个子类拟合参数
下面给出了聚类后九个子类设备使用时间指数分布的参数。其中参数 b b b 表明了指数衰减的速度。 可以看到,子类3,4,5,9 与前面所有设备使用时间指数分布参数(b=0.000628)相差比较大。 也说明了这些子类对应的分布出现较大的改变。
Class:1 : a=55.428724,b=0.000574,c=14.802819
Class:2 : a=46.119161,b=0.000693,c=5.414357
Class:3 : a=23.076774,b=0.000337,c=12.599779
Class:4 : a=24.558239,b=0.000443,c=4.880937
Class:5 : a=25.932349,b=0.000475,c=11.112023
Class:6 : a=34.804853,b=0.000741,c=3.695121
Class:7 : a=70.947851,b=0.000713,c=7.842925
Class:8 : a=32.410386,b=0.000712,c=5.933429
Class:9 : a=46.866055,b=0.001619,c=10.514767
from headm import *
from scipy.optimize import curve_fit
pred = tspload('prediction', 'pred')
cutname = tspload('namecut', 'cutname')
attrstr, alldata = tspload('alldata', 'attrstr', 'alldata')
alltime = array([float(a[3]) for a in alldata])
predlist = list(pred)
neuralcount = [predlist.count(i) for i in range(100)]
sortcount = sorted(zip(neuralcount, list(range(len(neuralcount)))), key=lambda x:x[0], reverse=True)
def linefun(x,a,b):
return a*exp(-b*x)
def histarg(times):
n,bins,patches = plt.hist(times, 50)
param = (1000, 1/2000)
param,conv = curve_fit(linefun, bins[:len(n)], n, p0=param)
return param, conv[0,0]
'''
for i in range(9):
namelist = cutname[pred==sortcount[i][1]]
namelist = list(set(namelist))
printf(' ')
printf("µÚ%dÀ࣬¸öÊý£º%d"%(i+1, len(namelist)))
for id,n in enumerate(namelist[:]):
printf("%d:%s"%(id+1, n.replace('`','')))
'''
startid = 0
for i in range(9):
timelist = alltime[pred==sortcount[i+startid][1]]
p,c = histarg(timelist)
printf('Class:%d : a=%f,b=%f,c=%f'%(i+1, p[0],p[1], c))
plt.subplot(3,3,i+1)
plt.hist(timelist, bins=50)
plt.title('Cluster%d'%(i+1+startid))
plt.grid(True)
plt.tight_layout()
plt.show()
4、五年参数变化
下面给出五个年份中,聚类前9类的分布参数变化。
(1)2017年
Class:1 : a=4.303712,b=0.000558,c=0.574744
Class:2 : a=5.646763,b=0.000576设备管理中设备名称聚类分析