YOLOv1网络
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLOv1网络相关的知识,希望对你有一定的参考价值。
参考技术AYOLO意思是You Only Look Once,创造性的将候选区和对象识别这两个阶段合二为一,看一眼图片(不用看两眼哦)就能知道有哪些对象以及它们的位置。其最大的特点是运行速度很快,可以用于实时系统。
实际上,YOLO并没有真正去掉候选区,而是采用了预定义的候选区(准确点说应该是预测区,因为并不是Faster RCNN所采用的Anchor)。也就是将图片划分为 7 * 7=49 个网格(grid),每个网格允许预测出2个边框(bounding box,包含某个对象的矩形框),总共 49 * 2=98 个bounding box。可以理解为98个候选区,它们很粗略的覆盖了图片的整个区域。
RCNN虽然会找到一些候选区,但毕竟只是候选,等真正识别出其中的对象以后,还要对候选区进行微调,使之更接近真实的bounding box。这个过程就是边框回归:将候选区bounding box调整到更接近真实的bounding box。
既然反正最后都是要调整的,干嘛还要先费劲去寻找候选区呢,大致有个区域范围就行了,所以YOLO就这么干了。
去掉候选区这个步骤以后,YOLO的结构非常简单,就是单纯的卷积、池化最后加了两层全连接。单看网络结构的话,和普通的CNN对象分类网络几乎没有本质的区别, 最大的差异是最后输出层用线性函数做激活函数,因为需要预测bounding box的位置(数值型),而不仅仅是对象的概率。 所以粗略来说,YOLO的整个结构就是输入图片经过神经网络的变换得到一个输出的张量,如下图所示。
因为只是一些常规的神经网络结构,所以,理解YOLO的设计的时候,重要的是理解输入和输出的映射关系。
输入就是原始图像,唯一的要求是缩放到448 * 448的大小。主要是因为YOLO的网络中,卷积层最后接了两个全连接层,全连接层是要求固定大小的向量作为输入,所以倒推回去也就要求原始图像有固定的尺寸。那么YOLO设计的尺寸就是448*448。
输出是一个 7 7 30 的张量(tensor)。
1) 7 * 7网格
根据YOLO的设计,输入图像被划分为 7 * 7 的网格(grid),输出张量中的 7 * 7 就对应着输入图像的 7 * 7 网格。或者我们把 7 * 7 * 30 的张量看作 7 * 7=49个30维的向量,也就是输入图像中的每个网格对应输出一个30维的向量。参考上图,比如输入图像左上角的网格对应到输出张量中左上角的向量。
要注意的是,并不是说仅仅网格内的信息被映射到一个30维向量。经过神经网络对输入图像信息的提取和变换,网格周边的信息也会被识别和整理,最后编码到那个30维向量中。
2)30维向量
具体来看每个网格对应的30维向量中包含了哪些信息。
因为YOLO支持识别20种不同的对象(人、鸟、猫、汽车、椅子等),所以这里有20个值表示该网格位置存在任一种对象的概率。可以记为 ,之所以写成条件概率,意思是如果该网格存在一个对象Object,那么它是 的概率是 。记不清条件概率的同学可以参考一下 理解贝叶斯定理 )
每个bounding box需要4个数值来表示其位置,(Center_x,Center_y,width,height),即(bounding box的中心点的x坐标,y坐标,bounding box的宽度,高度),2个bounding box共需要8个数值来表示其位置。
bounding box的置信度 = 该bounding box内存在对象的概率 * 该bounding box与该对象实际bounding box的IOU,用公式来表示就是
是bounding box内存在对象的概率,区别于上面的 , 并不管是哪个对象,它体现的是 有或没有 对象的概率;上面的 意思是假设已经有一个对象在网格中了,这个对象具体是哪一个。
是 bounding box 与 对象真实bounding box 的IOU(Intersection over Union,交并比)。要注意的是,现在讨论的30维向量中的bounding box是YOLO网络的输出,也就是预测的bounding box。所以 体现了预测的bounding box与真实bounding box的接近程度。
还要说明的是,虽然有时说"预测"的bounding box,但这个IOU是在训练阶段计算的。等到了测试阶段(Inference),这时并不知道真实对象在哪里,只能完全依赖于网络的输出,这时已经不需要(也无法)计算IOU了。
综合来说,一个bounding box的置信度Confidence意味着它 是否包含对象且位置准确的程度。置信度高表示这里存在一个对象且位置比较准确,置信度低表示可能没有对象 或者 即便有对象也存在较大的位置偏差。
简单解释一下IOU。下图来自Andrew Ng的深度学习课程,IOU=交集部分面积/并集部分面积,2个box完全重合时IOU=1,不相交时IOU=0。
总的来说,30维向量 = 20个对象的概率 + 2个bounding box * 4个坐标 + 2个bounding box的置信度。
3)讨论
每个30维向量中只有一组(20个)对象分类的概率,也就只能预测出一个对象。所以输出的 7 * 7=49个 30维向量,最多表示出49个对象。
每个30维向量中有2组bounding box,所以总共是98个候选区。
Faster RCNN等一些算法采用每个grid中手工设置n个Anchor(先验框,预先设置好位置的bounding box)的设计,每个Anchor有不同的大小和宽高比。YOLO的bounding box看起来很像一个grid中2个Anchor,但它们不是。YOLO并没有预先设置2个bounding box的大小和形状,也没有对每个bounding box分别输出一个对象的预测。它的意思仅仅是对一个对象预测出2个bounding box,选择预测得相对比较准的那个。
这里采用2个bounding box,有点不完全算监督算法,而是像进化算法。如果是监督算法,我们需要事先根据样本就能给出一个正确的bounding box作为回归的目标。但YOLO的2个bounding box事先并不知道会在什么位置,只有经过前向计算,网络会输出2个bounding box,这两个bounding box与样本中对象实际的bounding box计算IOU。这时才能确定,IOU值大的那个bounding box,作为负责预测该对象的bounding box。
训练开始阶段,网络预测的bounding box可能都是乱来的,但总是选择IOU相对好一些的那个,随着训练的进行,每个bounding box会逐渐擅长对某些情况的预测(可能是对象大小、宽高比、不同类型的对象等)。所以,这是一种进化或者非监督学习的思想。
另外论文中经常提到responsible。比如:Our system divides the input image into an S*S grid. If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object. 这个 responsible 有点让人疑惑,对预测"负责"是啥意思。其实没啥特别意思,就是一个Object只由一个grid来进行预测,不要多个grid都抢着预测同一个Object。更具体一点说,就是在设置训练样本的时候,样本中的每个Object归属到且仅归属到一个grid,即便有时Object跨越了几个grid,也仅指定其中一个。具体就是计算出该Object的bounding box的中心位置,这个中心位置落在哪个grid,该grid对应的输出向量中该对象的类别概率是1(该gird负责预测该对象),所有其它grid对该Object的预测概率设为0(不负责预测该对象)。
还有:YOLO predicts multiple bounding boxes per grid cell. At training time we only want one bounding box predictor to be responsible for each object. 同样,虽然一个grid中会产生2个bounding box,但我们会选择其中一个作为预测结果,另一个会被忽略。下面构造训练样本的部分会看的更清楚。
7 * 7网格,每个网格2个bounding box,对448 * 448输入图像来说覆盖粒度有点粗。我们也可以设置更多的网格以及更多的bounding box。设网格数量为 S * S,每个网格产生B个边框,网络支持识别C个不同的对象。这时,输出的向量长度为: ,整个输出的tensor就是: 。
YOLO选择的参数是 7 7网格,2个bounding box,20种对象,因此 输出向量长度 = 20 + 2 * (4+1) = 30。整个输出的tensor就是 7 7*30。
因为网格和bounding box设置的比较稀疏,所以这个版本的YOLO训练出来后预测的准确率和召回率都不是很理想,后续的v2、v3版本还会改进。当然,因为其速度能够满足实时处理的要求,所以对工业界还是挺有吸引力的。
作为监督学习,我们需要先构造好训练样本,才能让模型从中学习。
对于一张输入图片,其对应输出的7 7 30张量(也就是通常监督学习所说的标签y或者label)应该填写什么数据呢。
首先,输出的 7 7维度 对应于输入的 7 7 网格。 然后具体看下30维向量的填写(请对照上面图6)。
对于输入图像中的每个对象,先找到其中心点。比如上图中的自行车,其中心点在黄色圆点位置,中心点落在黄色网格内,所以这个黄色网格对应的30维向量中,自行车的概率是1,其它对象的概率是0。所有其它48个网格的30维向量中,该自行车的概率都是0。这就是所谓的"中心点所在的网格对预测该对象负责"。狗和汽车的分类概率也是同样的方法填写。
训练样本的bounding box位置应该填写对象实际的bounding box,但一个对象对应了2个bounding box,该填哪一个呢?上面讨论过,需要根据网络输出的bounding box与对象实际bounding box的IOU来选择,所以要在训练过程中动态决定到底填哪一个bounding box。
上面讨论过置信度公式 , 可以直接计算出来,就是用网络输出的2个bounding box与对象真实bounding box一起计算出IOU。
然后看2个bounding box的IOU,哪个比较大(更接近对象实际的bounding box),就由哪个bounding box来负责预测该对象是否存在,即该bounding box的 ,同时对象真实bounding box的位置也就填入该bounding box。另一个不负责预测的bounding box的 。
总的来说就是,与对象实际bounding box最接近的那个bounding box,其 ,该网格的其它bounding box的 。
举个例子,比如上图中自行车的中心点位于4行3列网格中,所以输出tensor中4行3列位置的30维向量如下图所示。
翻译成人话就是:4行3列网格位置有一辆自行车,它的中心点在这个网格内,它的位置边框是bounding box1所填写的自行车实际边框。
注意,图中将自行车的位置放在bounding box1,但实际上是在训练过程中等网络输出以后,比较两个bounding box与自行车实际位置的IOU,自行车的位置(实际bounding box)放置在IOU比较大的那个bounding box(图中假设是bounding box1),且该bounding box的置信度设为1。
损失就是网络实际输出值与样本标签值之间的偏差。
YOLO给出的损失函数如下:
其中,
是指网格i存在对象;
是指网格i的第j个bounding box中存在对象;
是指网格i的第j个bounding box中不存在对象。
总的来说,就是用网络输出与样本标签的各项内容的误差平方和作为一个样本的整体误差。 损失函数中的几个项是与输出的30维向量中的内容相对应的。
公式第5行,注意 意味着存在对象的网格才计入误差。
公式第1行和第2行。
a) 都带有 意味着只有"负责"(IOU比较大)预测的那个bounding box的数据才会计入误差;
b) 第2行宽度和高度先取了平方根,因为如果直接取差值的话,大的对象对差值的敏感度较低,小的对象对差值的敏感度较高,所以取平方根可以降低这种敏感度的差异,使得较大的对象和较小的对象在尺寸误差上有相似的权重。
c) 乘以 调节bounding box位置误差的权重(相对分类误差和置信度误差)。YOLO设置 ,即调高位置误差的权重。
公式第3行和第4行。
a) 第3行是存在对象的bounding box的置信度误差。带有 意味着只有"负责"(IOU比较大)预测的那个bounding box的置信度才会计入误差。
b) 第4行是不存在对象的bounding box的置信度误差。因为不存在对象的bounding box应该老老实实的说"我这里没有对象",也就是输出尽量低的置信度。如果它不恰当的输出较高的置信度,会与真正"负责"该对象预测的那个bounding box产生混淆。其实就像对象分类一样,正确的对象概率最好是1,所有其它对象的概率最好是0。
c) 第4行乘以 调节不存在对象的bounding box 的置信度的权重(相对其他误差)。YOLO设置 ,即调低不存在对象的bounding box的置信度误差的权重。
YOLO先使用ImageNet数据集对前20层卷积网络进行预训练,然后使用完整的网络,在PASCAL VOC数据集上进行对象识别和定位的训练和预测。YOLO的网络结构如下图所示:
YOLO的最后一层采用线性激活函数,其它层都是Leaky ReLU。训练中采用了dropout和数据增强(data augmentation)来防止过拟合。更多细节请参考原论文。
训练好的YOLO网络,输入一张图片,将输出一个 7 7 30 的张量(tensor)来表示图片中所有网格包含的对象(概率)以及该对象可能的2个位置(bounding box)和可信程度(置信度)。 为了从中提取出最有可能的那些对象和位置,YOLO采用NMS(Non-maximal suppression,非极大值抑制)算法。
NMS方法并不复杂,其核心思想是:选择得分最高的作为输出,与该输出重叠的去掉,不断重复这一过程直到所有备选处理完。
YOLO的NMS计算方法如下。
网络输出的7 * 7 * 30的张量,在每一个网格中,对象 位于第j个bounding box的得分: ,它代表着某个对象 存在第j个bounding box的可能性。
每个网格有:20个对象的概率*2个bounding box的置信度,共40个得分(候选对象)。49个网格共1960个得分。Andrew Ng建议每种对象分别进行NMS,那么每种对象有 1960/20=98 个得分。
NMS步骤如下:
1)设置一个Score的阈值,低于该阈值的候选对象排除掉(将该Score设为0)
2)遍历每一个对象类别
2.1)遍历该对象的98个得分
2.1.1)找到Score最大的那个对象及其bounding box,添加到输出列表
2.1.2)对每个Score不为0的候选对象,计算其与上面2.1.1输出对象的bounding box的IOU
2.1.3)根据预先设置的IOU阈值,所有高于该阈值(重叠度较高)的候选对象排除掉(将Score设为0)
2.1.4)如果所有bounding box要么在输出列表中,要么Score=0,则该对象类别的NMS完成,返回步骤2处理下一种对象
3)输出列表即为预测的对象
YOLO以速度见长,处理速度可以达到45fps,其快速版本(网络较小)甚至可以达到155fps。这得益于其识别和定位合二为一的网络设计,而且这种统一的设计也使得训练和预测可以端到端的进行,非常简便。
不足之处是小对象检测效果不太好(尤其是一些聚集在一起的小对象),对边框的预测准确度不是很高,总体预测精度略低于Fast RCNN。主要是因为网格设置比较稀疏,而且每个网格只预测两个边框,另外Pooling层会丢失一些细节信息,对定位存在影响。
yolov5修改骨干网络-使用自己搭建的网络-以efficientnetv2为例
yolov5修改骨干网络–原网络说明
yolov5修改骨干网络-使用pytorch自带的网络-以Mobilenet和efficientnet为例
yolov5修改骨干网络-使用自己搭建的网络-以efficientnetv2为例
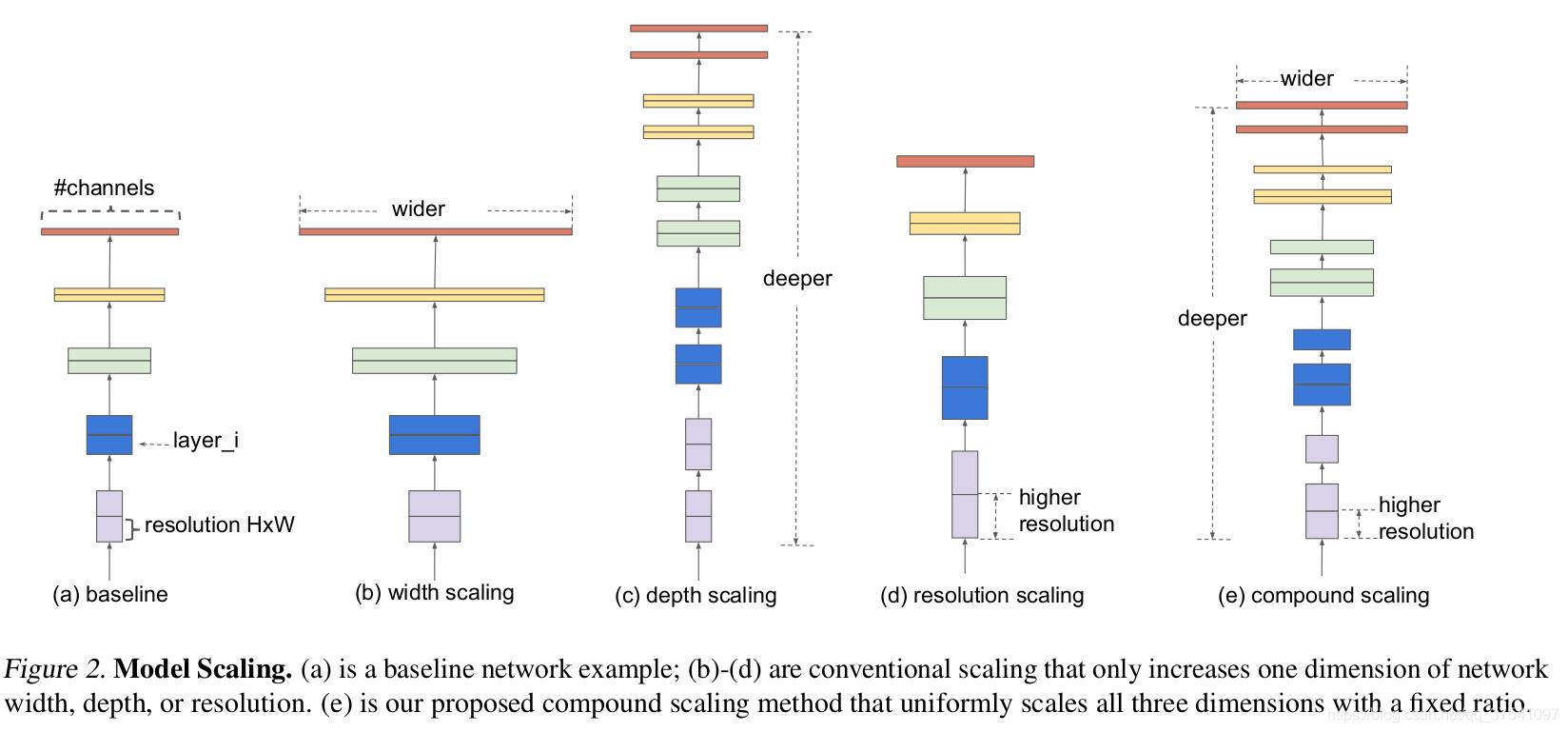
- 增加网络的深度depth能够得到更加丰富、复杂的特征并且能够很好的应用到其它任务中。但网络的深度过深会面临梯度消失,训练困难的问题。
- 增加网络的width能够获得更高细粒度的特征并且也更容易训练,但对于width很大而深度较浅的网络往往很难学习到更深层次的特征。
- 增加输入网络的图像分辨率能够潜在得获得更高细粒度的特征模板,但对于非常高的输入分辨率,准确率的增益也会减小。但大分辨率图像会增加计算量。
efficientnet则是通过NAS搜索,同时增加width、depth以及resolution,使网络结构达到最优。
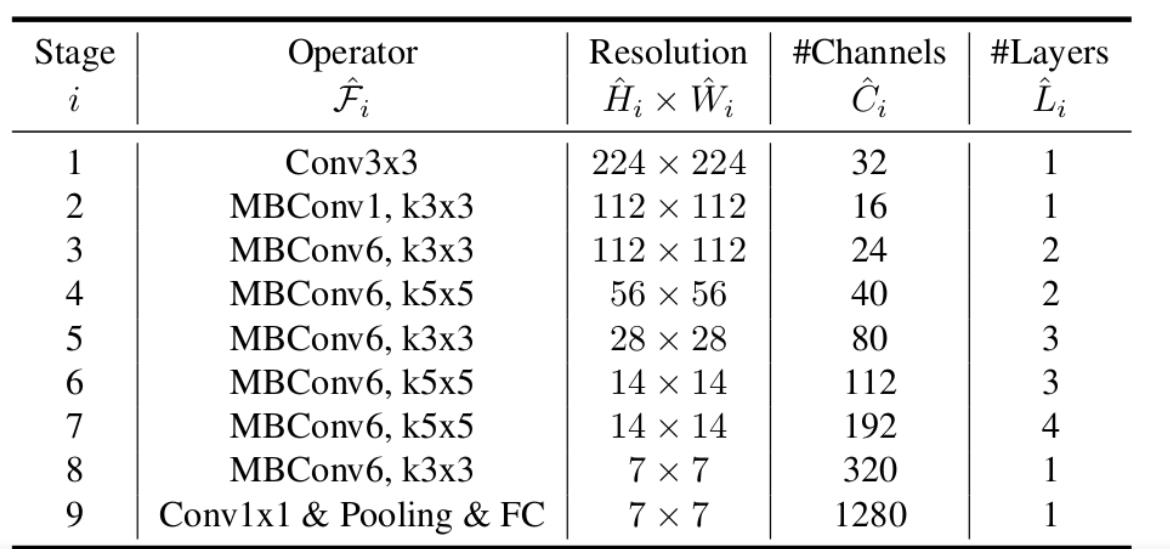
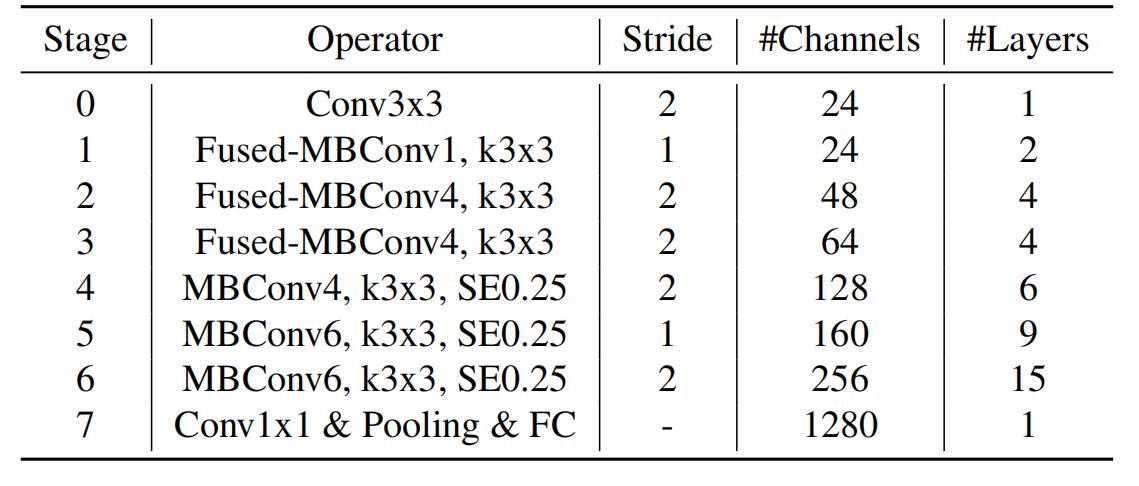
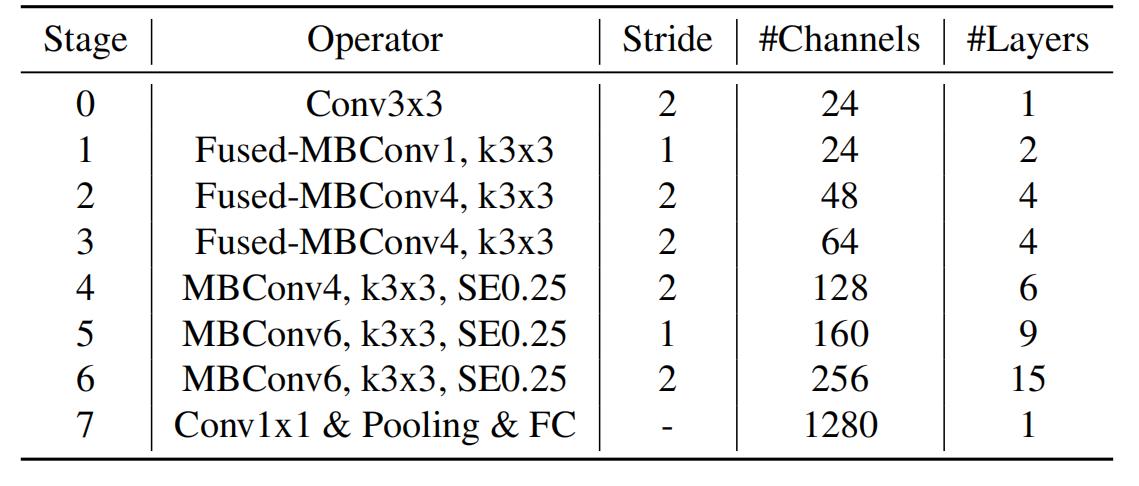
下表为EfficientNet-B0的网络框架(B1-B7就是在B0的基础上修改Resolution,Channels以及Layers),可以看出网络总共分成了9个Stage。
第一个Stage是一个卷积核大小为3x3,stride为2的普通卷积层(包含BN和Swish激活函数);
Stage2~Stage8都是在重复堆叠MBConv结构(Layers表示该Stage重复MBConv结构多少次),Stage9由一个普通的1x1的卷积层 + 平均池化层 + 全连接层组成。
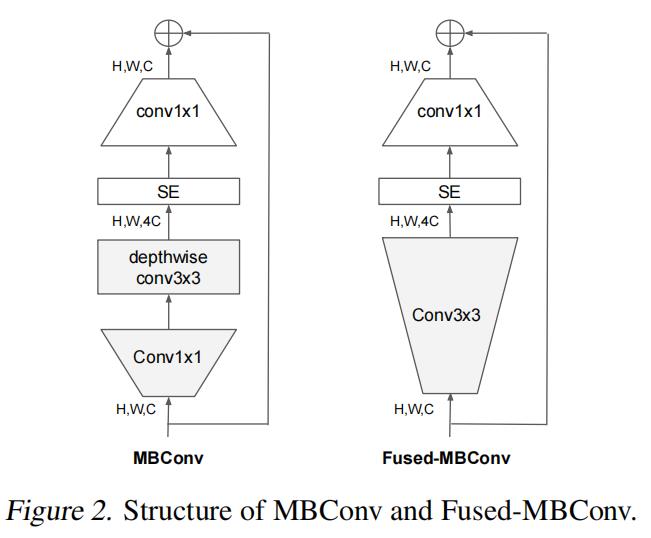
MBConv后的1或6就是倍率因子n,即MBConv中第一个1x1的卷积层会将输入特征矩阵的channels扩充为n倍,其中k3x3或k5x5表示MBConv中Depthwise Conv所采用的卷积核大小。Channels表示通过该Stage后输出特征矩阵的Channels。
MBConv结构如下:

MBConv主要由一个 1x1 的卷积进行升维 (它的卷积核个数是输入特征矩阵channel的n倍,
n
∈
1
,
6
n \\in \\left\\1, 6\\right\\
n∈1,6,当n=1时,不升维),一个kxk的Depthwise Conv卷积,k主要有3x3和5x5两种情况,一个SE模块,然后接一个1x1的普通卷积进行降维作用,再加一个Droupout,最后再进行特征图融合。
仅当输入MBConv结构的特征矩阵与输出的特征矩阵shape相同时shortcut连接才存在(代码中可通过stride== 1 and inputc_channels==output_channels条件来判断)
SE模块,由一个全局平均池化,两个全连接层组成。
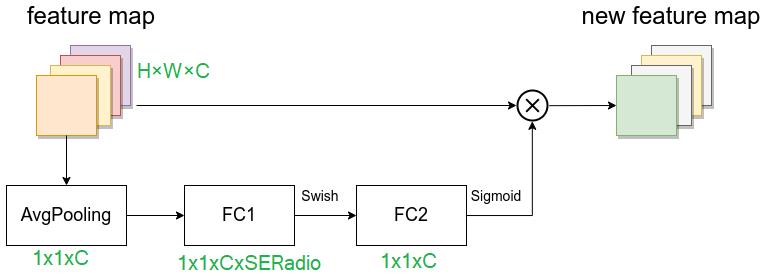
假设输入图像H×W×C,第一个全连接层的节点个数是输入该MBConv特征矩阵 channels 乘SERadio,一般SERadio为 0.25,所以channe为 C 4 \\fracC4 4C ,然后是Swish激活函数。
第二个全连接层的节点个数等于Depthwise Conv层输出的特征矩阵 channels,即 C C C,且使用Sigmoid激活函数,这样就拉伸成了1×1×C,然后再与原图像相乘,将每个通道赋予权重。这样就实现了注意力。
class SqueezeExcite_efficientv2(nn.Module):
def __init__(self, c1, c2, se_ratio=0.25, act_layer=nn.ReLU):
super().__init__()
self.gate_fn = nn.Sigmoid()
reduced_chs = int(c1 * se_ratio)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_reduce = nn.Conv2d(c1, reduced_chs, 1, bias=True)
self.act1 = act_layer(inplace=True)
self.conv_expand = nn.Conv2d(reduced_chs, c2, 1, bias=True)
def forward(self, x):
# 先全局平均池化
x_se = self.avg_pool(x)
# 再全连接(这里是用的1x1卷积,效果与全连接一样,但速度快)
x_se = self.conv_reduce(x_se)
# ReLU激活
x_se = self.act1(x_se)
# 再全连接
x_se = self.conv_expand(x_se)
# sigmoid激活
x_se = self.gate_fn(x_se)
# 将x_se 维度扩展为和x一样的维度
x = x * (x_se.expand_as(x))
return x
Dropout层在源码实现中只有使用shortcut的时候才有Dropout层。
EfficientNetV1在训练图像的尺寸很大时,训练速度非常慢,而且非常吃显存。
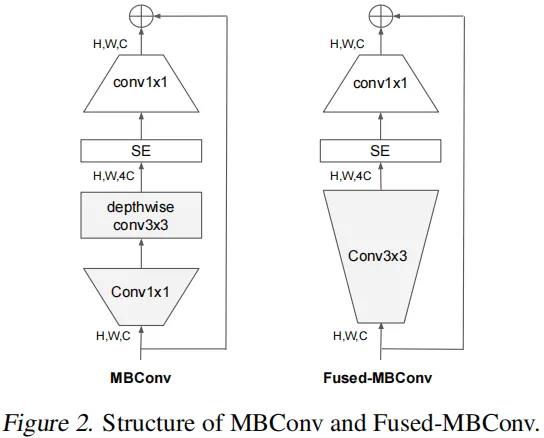
在网络浅层中使用Depthwise convolutions速度会很慢。虽然Depthwise convolutions结构相比普通卷积拥有更少的参数以及更小的FLOPs,但通常无法充分利用现有的一些加速器,于是有人提出了Fused-MBConv结构去更好的利用移动端或服务端的加速器。
Fused-MBConv结构也非常简单,即将原来的MBConv结构主分支中的 conv1x1和depthwise conv3x3替换成一个普通的conv3x3,如图所示。
EfficientNetV2网络框架相比与EfficientNetV1,主要有以下不同:
- EfficientNetV2中除了使用到MBConv模块外,还使用了Fused-MBConv模块(主要是在网络浅层中使用)。
- EfficientNetV2使用较小的expansion ratio(MBConv中第一个expand conv1x1或者Fused-MBConv中第一个expand conv3x3)比如4,在EfficientNetV1中基本都是6. 这样的好处是能够减少内存访问开销。
- EfficientNetV2中更偏向使用更小(3x3)的kernel_size,在EfficientNetV1中使用了很多5x5的kernel_size。通过下表可以看到使用的kernel_size全是3x3的,由于3x3的感受野是要比5x5小的,所以需要堆叠更多的层结构以增加感受野。
- 移除了EfficientNetV1中最后一个步距为1的stage,就是EfficientNetV1中的stage8,可能是因为它的参数数量过多并且内存访问开销过大。
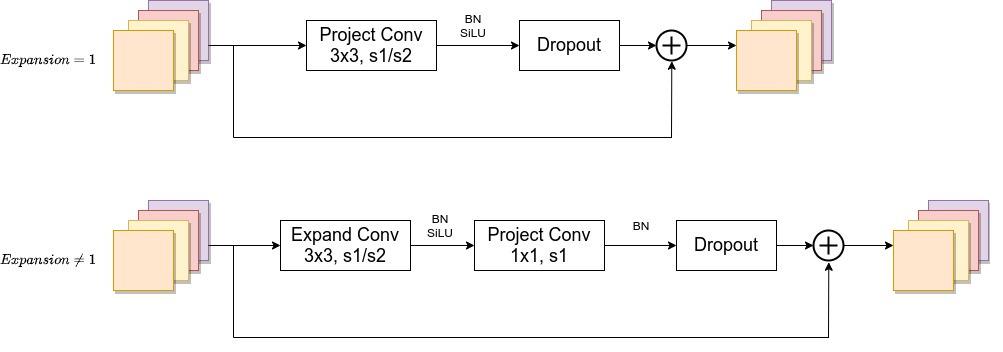
Conv3x3就是普通的3x3卷积 + 激活函数(SiLU)+ BN
Fused-MBConv 模块模块名称后跟的1,4表示expansion ratio,k3x3表示kenel_size为3x3,注意当expansion ratio等于1时是没有expand conv的,还有这里是没有使用到SE结构的(原论文图中有SE)。
当stride=1且输入输出channel相等时才有shortcut连接。
当有shortcut连接时才有Dropout层,而且这里的Dropout层是Stochastic Depth,即会随机丢掉整个block的主分支(只剩捷径分支,相当于直接跳过了这个block)也可以理解为减少了网络的深度。
MBConv模块和EfficientNetV1中是一样的,其中模块名称后跟的4,6表示expansion ratio,SE0.25表示使用了SE模块,0.25表示SE模块中第一个全连接层的节点个数是输入该MBConv模块特征矩阵channels的
1
4
\\frac14
41
注意当stride=1且输入输出Channels相等时才有shortcut连接。同样这里的Dropout层是Stochastic Depth。

Stride就是步距,注意每个Stage中会重复堆叠Operator模块多次,只有第一个Opertator模块的步距是按照表格中Stride来设置的,其他的默认都是1。 #Channels表示该Stage输出的特征矩阵的Channels,Layers表示该Stage重复堆叠Operator的次数。
网络代码
根据这个结构图进行代码编写,首先是一个步长为2的3x3矩阵,输出channel为24,后面当然也是有bn+激活的。这里先写一个base,通过修改yaml文件对其操作。
这一行的yaml参数应该如下:[-1, 1, stem, [24, 3, 2]],
class stem(nn.Module):
def __init__(self, c1, c2, kernel_size=3, stride=1, groups=1):
super().__init__()
# kernel_size为3时,padding 为1,kernel为1时,padding为0
padding = (kernel_size - 1) // 2
# 由于要加bn层,所以不加偏置
self.conv = nn.Conv2d(c1, c2, kernel_size, stride, padding=padding, groups=groups, bias=False)
self.bn = nn.BatchNorm2d(c2, eps=1e-3, momentum=0.1)
self.act = nn.SiLU(inplace=True)
def forward(self, x):
# print(x.shape)
x = self.conv(x)
x = self.bn(x)
x = self.act(x)
return x
然后是FusedMBConv,根据这个流程图编写:
注意,FusedMBConv是没有SE模块的,虽然上面画了SE。
Fused-MBConv1 后面这个1表示expansion=1,不升维;若不等于1,则升维到原维度的n倍;
后面layers=2表示使用两次这个bolck,所以第一个Fused-MBConv1, k3x3的yaml参数应为[-1, 2, FusedMBConv, [24, 3, 1, 1, 0]]
[24:out_channer, 3:kernel_size, 1:stride,1:expansion, 0:se_ration]
# Fused-MBConv 将 MBConv 中的 depthwise conv3×3 和扩展 conv1×1 替换为单个常规 conv3×3。
class FusedMBConv(nn.Module):
def __init__(self, c1, c2, k=3, s=1, expansion=1, se_ration=0, dropout_rate=0.2, drop_connect_rate=0.2):
super().__init__()
# 当stride=1且输入输出Channels相等时才有shortcut连接,只有使用shortcut时,才用dropout
self.has_shortcut = (s == 1 and c1 == c2) # 只要是步长为1并且输入输出特征图大小相等,就是True 就可以使用到残差结构连接
# expansion是为了先升维,再卷积,再降维,再残差
self.has_expansion = expansion != 1 # expansion==1 为false expansion不为1时,输出特征图维度就为expansion*c1,k倍的c1,扩展维度
expanded_c = c1 * expansion
if self.has_expansion:
self.expansion_conv = stem(c1, expanded_c, kernel_size=k, stride=s)
self.project_conv = stem(expanded_c, c2, kernel_size=1, stride=1)
else:
self.project_conv = stem(c1, c2, kernel_size=k, stride=s)
self.drop_connect_rate = drop_connect_rate
if self.has_shortcut and drop_connect_rate > 0:
self.dropout = DropPath(drop_connect_rate)
def forward(self, x):
if self.has_expansion:
result = self.expansion_conv(x)
result = self.project_conv(result)
else:
result = self.project_conv(x)
if self.has_shortcut:
if self.drop_connect_rate > 0:
result = self.dropout(result)
result += x
return result
stage2: Fused-MBConv4, k3x3 2 48 4 表示用kernelsize=3的卷积核,先升维4倍,outchannel=48,重复四次,注意stride=2只有在第一次重复时才有,后面三次的stride都是1,所以yaml应该写为:
第一个的stride为2
[-1, 1, FusedMBConv, [48, 3, 2, 4, 0]]
后面三个的stride为1
[-1, 3, FusedMBConv, [48, 3, 1, 4, 0]]
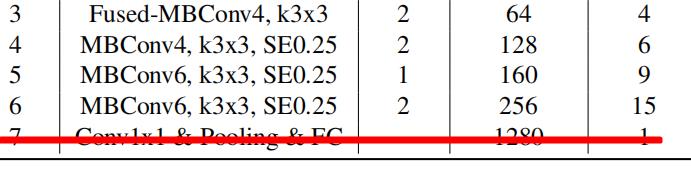
同理stage 3 Fused-MBConv4, k3x3 2 64 4
[-1, 1, FusedMBConv, [64, 3, 2, 4, 0]],
[-1, 3, FusedMBConv, [64, 3, 1, 4, 0]],
然后是stage 4 MBConv4, k3x3, SE0.25 2 128 6 表示6个MBConv模块,第一次用kernel size=3的卷积核升维四倍,SERadio为0.25,第一次的stride为2,后三次为1,输出channel为128。
yaml参数就应该为:
[-1, 1, MBConv, [128, 3, 2, 4, 0.25]], # 先用步长为2的卷积
[-1, 5, MBConv, [128, 3, 1, 4, 0.25]], # 后面5个block用步长为1的卷积
class MBConv(nn.Module):
def __init__(self, c1, c2, k=3, s=1, expansion=1, se_ration=0, dropout_rate=0.2, drop_connect_rate=0.2):
super().__init__()
self.has_shortcut = (s == 1 and c1 == c2)
expanded_c = c1 * expansion
self.expansion_conv = stem(c1, expanded_c, kernel_size=1, stride=1)
self.dw_conv = stem(expanded_c, expanded_c, kernel_size=k, stride=s, groups=expanded_c)
self.se = SqueezeExcite_efficientv2(expanded_c, expanded_c, se_ration) if se_ration > 0 else nn.Identity()
self.project_conv = stem(expanded_c, c2, kernel_size=1, stride=1)
self.drop_connect_rate = drop_connect_rate
if self.has_shortcut and drop_connect_rate > 0:
self.dropout = DropPath(drop_connect_rate)
def forward(self, x):
# 先用1x1的卷积增加升维
result = self.expansion_conv(x)
# 再用一般的卷积特征提取
result = self.dw_conv(result)
# 添加se模块
result = self.se(result)
# 再用1x1的卷积降维
result = self.project_conv(result)
# 如果使用shortcut连接,则加入dropout操作
if self.has_shortcut:
if self.drop_connect_rate > 0:
result = self.dropout(result)
# shortcut就是到残差结构,输入输入的channel大小相等,这样就能相加了
result += x
return result
同理stage5和stage6的参数分别为:
[-1, 1, MBConv, [160, 3, 2, 6, 0.25]],
[-1, 8, MBConv, [160, 3, 1, 6, 0.25]],
[-1, 1, MBConv, [256, 3, 2, 4, 0.25]],
[-1, 14, MBConv, [256, 3, 1, 4, 0.25]],
注意,我们不需要stage7,因为我们只需要进行特征提取,不需要进行分类
然后是修改concat连接的位置:
下面注释中很清晰的写了特征图大小变化,以及为什么要和那一层连接。默认输入图片尺寸为640*640
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
[[-1, 1, stem, [24, 3, 2]], # 0-P1/2 efficientnetv2 一开始是Stem = 普通的卷积+bn+激活 640*640*3 --> 320*320*24
# # [out_channel,kernel_size,stride,expansion,se_ration]
[-1, 2, FusedMBConv, [24, 3, 1, 1, 0]], # 1 2个FusedMBConv=3*3conv+se+1*1conv 320*320*24-->320*320*24
[-1, 1, FusedMBConv, [48, 3, 2, 4, 0]], # 2 这里strid2=2,特征图尺寸缩小一半,expansion=4输出特征图的深度变为原来的4倍 320*320*24-->160*160*48
[-1, 3, FusedMBConv, [48, 3, 1, 4, 0]], # 3 三个FusedMBConv
[-1, 1, FusedMBConv, [64, 3, 2, 4, 0]], # 4 160*160*48-->80*80*64
[-1, 3, FusedMBConv, [64, 3, 1, 4, 0]], # 5
[-1, 1, MBConv, [128, 3, 2, 4, 0.25]], # 6 这里strid2=2,特征图尺寸缩小一半, 40*40*128
[-1, 5, MBConv, [128, 3, 1, 4, 0.25]], # 7
[-1, 1, MBConv, [160, 3, 2, 6, 0.25]], # 8 这里 strid2=2,特征图尺寸缩小一半,20*20*160
[-1, 8, MBConv, [160, 3, 1, 6, 0.25]], # 9
[-1, 1, MBConv, [256, 3, 2, 4, 0.25]], # 10 这里strid2=2,特征图尺寸缩小一半,10*10*160
[-1, 14, MBConv, [256, 3, 1, 4, 0.25]], # 11
[-1, 1, SPPF, [1024, 5]], #12
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]], # 13 10*10
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 14 20*20
[[-1, 9], 1, Concat, [1]], # 15 cat backbone P4 15 这里特征图大小为20*20,所以应该和9号连接
[-1, 3, C3, [512, False]], # 16 20*20
[-1, 1, Conv, [256, 1, 1]], #17 20*20
[-1, 1, nn.Upsample, [None, 2, 'nearest']], #18 40*40
[[-1, 7], 1, Concat, [1]], # cat backbone P3 19 7号特征图大小也是40*40
[-1, 3, C3, [256, False]], # 20 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]], #21 卷积步长为2,所以特征图尺寸缩小,为 20*20
[[-1, 17], 1, Concat, [1]], # cat head P4 17层的特征图也是20*20
[-1, 3, C3, [512, False]], # 23 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]], # 24 10*10
[[-1, 13], 1, Concat, [1]], # cat head P5 13层的特征图大小就是10*10
[-1, 3, C3, [1024, False