入秋,学习音视频视频和文字结合更配哦
Posted 初一十五啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了入秋,学习音视频视频和文字结合更配哦相关的知识,希望对你有一定的参考价值。
一丶视频区:
1.从零自己实现IJKPlayer万能播放器,深度实现万能格式播放(avi,rmvb,flv,rtm,http,mkv等)
2.手写微信视频通话,手把手带你从零打造H265版视频通话项目
3.视频通话之编码原理——带你击破关于音视频面试各个难点(抖音)
4.突破音视频通话SDK封锁,深入底层了解音视频通话编码原理
由于内容偏长,这里整理了一个关于音视频文档😆。

💡关注公众号 『初一十五a 』,不定期分享知识😺
二丶音视频是什么,视频为什么需要压缩
2.1.面试官😺: 音视频是什么,视频为什么需要压缩
心理分析😉:很多人对音视频的概念停留在 苍老师的小电影上,只能理解他是一个视频文件。面试官考的对视频文件下的封装格式,视频文件组成和音视频开发有没相关的概念
**求职者😊:**首先需要从视频文件组成开始讲解,慢慢深入到视频编码
WebRTC很强大,包含了很多功能,如:音视频采集、编解码、传输、增益、消噪等,还支持跨平台,我这里只用到WebRTC的消噪相关模块(点击这里下载),代码逻辑其实很简单,只用到4个函数
- 1.创建:
WebRtcNs_Create - 2.初始化:
WebRtcNs_Init - 3.设置消噪级别:
WebRtcNs_set_policy - 4.循环取10ms数据,进行消噪处理:
WebRtcNs_Process
具体代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "signal_processing_library.h"
#include "noise_suppression_x.h"
#include "noise_suppression.h"
#include "gain_control.h"
@interface AudioManager()
NsHandle *_nshandle;
@end
@implementation AudioManager
+ (instancetype)sharedInstance
static id instance = nil;
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^
instance = [[self alloc] init];
);
return instance;
/**
消噪
@param buffer PCM原始数据
@param length PCM数据长度
@param fs 采样率
@param quality 消噪质量(0,1,2,3),0质量最差,3质量最好
*/
+ (void)denoise:(unsigned char *)buffer length:(NSUInteger)length fs:(NSUInteger)fs quality:(int)quality
AudioManager *audio = [AudioManager sharedInstance];
NsHandle *nsHandle = NULL;
int level = quality < 0 ? 0 : (quality > 3 ? 3 :quality);
if (audio->_nshandle == NULL)
if (0 != WebRtcNs_Create(&nsHandle))
NSLog(@"WebRTC 创建失败");
return;
if (0 != WebRtcNs_Init(nsHandle, (uint32_t)fs))
NSLog(@"WebRTC 初始化失败");
return;
if (0 != WebRtcNs_set_policy(nsHandle, level))
NSLog(@"WebRTC 设置失败");
return;
audio->_nshandle = nsHandle;
else
nsHandle = audio->_nshandle;
NSLog(@"消噪级别=%d", level);
//我们的PCM音频数据为16位,采样率8000Hz,而WebRTC每次只处理10ms的数据,经计算:sizeof(short)*fs/100,即为2*80=160个字节
for (int i = 0; i < length; i+=sizeof(short)*fs/100)
short inP[80] = 0;
short outP[80] = 0;
memcpy(inP, buffer+i, 80*sizeof(short));
if (0 != WebRtcNs_Process(nsHandle, inP, NULL, outP, NULL))
NSLog(@"消噪失败:%d", i);
memcpy(buffer+i, outP, 80*sizeof(short));
2.2.视频的构成
个完整的视频文件是由音频和视频两部分组成封装格式和编码格式
外壳类似于"苍老师.mp4"文件,外壳的核心还有一层编码文件,编码文件经过封装后,才成为我们现在看到的.mp4 .avi等视频。
苍老师的激战的画面内容被编码成了H264或mpeg-4,我们把H264视频编码格式,
苍老师的销魂声音编码成MP3、AAC, 我们把MP3称为音频编码格式。
**例如:**将一个H.264视频编码文件和一个MP3视频编码文件按MP4封装标准封装以后,就得到一个MP4后缀的视频文件,这个就是我们常见的AVI视频文件了。
部分技术先进的容器还可以同时封装多个视频、音频编码文件,甚至同时封装进字幕,如MKV封装格式。MKV文件可以做到一个文件包括多语种发音、多语种字幕,适合不同人的需要。
2.3.封装格式
(1)封装格式(也叫容器)就是将已经编码压缩好的视频轨和音频轨按照一定的格式放到一个文件中,也就是说仅仅是一个外壳,可以把它当成一个放视频轨和音频轨的文件夹也可以。
(2)通俗点说视频轨相当于饭,而音频轨相当于菜,封装格式就是一个碗,或者一个锅,用来盛放饭菜的容器。
(3)封装格式和专利是有关系的,关系到推出封装格式的公司的盈利。
(4)有了封装格式,才能把字幕,配音,音频和视频组合起来。
(5)常见的AVI、RMVB、MKV、ASF、WMV、MP4、3GP、FLV等文件都指的是一种封装格式。
2.4.视频为什么需要压缩
- 未经压缩的数字视频的数据量巨大
- 存储困难:一张
DVD只能存储几秒钟的未压缩数字视频。 - 传输困难 1兆的带宽传输一秒的数字电视视频需要大约4分钟。
三丶视频压缩压缩的是什么信息? 帧内压缩与帧间压缩原理
3.1.面试官😺: 视频压缩压缩的是什么信息? 帧内压缩与帧间压缩原理
心理分析😉:视频压缩在音视频领域是一个恒久不变的话题,有压缩也就意味有解压操作,我们把压缩与解压称为编解码。它们是成对出现的,做音视频最难的就在音视频编解码。如何提高音视频播放效率,在不牺牲视频质量下 做高度压缩就显得格外重要了。面试官想问的问题并不是压缩了什么,而是编码中对视频帧做了什么
**求职者😊:**需要求职者对视频编码有所了解,接下来我们从帧内压缩,与帧间压缩讲起
3.2.视频中哪些信息可以被省略 甚至可以去掉的?**
1 某一帧中大块大块的相同颜色,每一个颜色都是一个像素,像素是一个int,大块的相同像素意味着有很多歌相同的int值
2 如果一个视频帧率为30FPS(每秒帧数)意味着视频的一秒播放等于30帧 这30帧每一帧的像素值并不会发生很大 ,甚至30帧完全是静止图像
3.3.视频压缩分为帧内压缩与帧间压缩
压缩的常用技术是调整大小或降低分辨率。这是因为视频的分辨率越高,每帧中包含的信息就越多。例如,1280×720视频在每帧中有921,600像素的可能性,假设它是一个i帧(稍微多一点)。相比之下,640×360视频每帧可能有230,400像素。
这种调整会牺牲视频的质量,虽然视频每一帧大小降低了,同时用户的体验也降低了。用户是愿意看2k的电视,还是看8k呢?
3.4 帧内压缩
一种可能未被广泛实现的视频压缩技术是帧间帧。这是一个逐帧减少“冗余”信息的过程。例如,具有30的FPS(每秒帧数)的视频意味着视频的一秒等于30帧或静止图像。
分块(MacroBlocking)
将图片划分成多个宏块(macro blocks),典型的宏块由一个 16×16 的亮度像素(luma pixel)块和两个 8×8 的色度像素(chroma pixel)块组成。分块越小,预测越准,需要记录的信息也越多。一般来说,细节越丰富的地方,分块越细,即使用 4×4 分块预测。细节相对不丰富的地方使用 16×16 分块。(这一过程相当于 JPEG 编码中的色彩空间转换)
帧内预测
WebP 有损压缩使用了帧内预测编码,这一技术也被用于 VP8 视频编码中的关键帧压缩。VP8 有四种常见的帧内预测模型。
H_PRED(horizontal prediction)
像素块中每一行使用其左边一列(col L)的数据填充(如图3.2Horizontal)V_PRED(vertical prediction)
像素块中每一列使用其上边一行(row A)的数据填充(如图3.2Vertical)DC_PRED(DC prediction)
像素块中每个单元使用row A和col L的所有像素的平均值填充(如图3.2Average)TM_PRED(TrueMotion prediction)
一种我还没搞清楚的预测模式,比较接近真实数据
3.5 帧间压缩( I帧,P帧,B帧和GOP)
我们来看一下例子,下面是捕获的一组运动的台球的视频帧,台球从右上角滚到了左下角。
对于视频数据主要有两类数据冗余,一类是时间上的数据冗余,另一类是空间上的数据冗余。其中时间上的数据冗余是最大的。下面我们就先来说说视频数据时间上的冗余问题。
为什么说时间上的冗余是最大的呢?假设摄像头每秒抓取30帧,这30帧的数据大部分情况下都是相关联的。也有可能不止30帧的的数据,可能几十帧,上百帧的数据都是关联特别密切的。对于这些关联特别密切的帧,其实我们只需要保存一帧的数据,其它帧都可以通过这一帧再按某种规则预测出来,所以说视频数据在时间上的冗余是最多的。
H264编码器会按顺序,每次取出两幅相邻的帧进行宏块比较,计算两帧的相似度。
通过宏块扫描与宏块搜索可以发现这两个帧的关联度是非常高的。进而发现这一组帧的关联度都是非常高的。因此,上面这几帧就可以划分为一组。其算法是:在相邻几幅图像画面中,一般有差别的像素只有10%以内的点,亮度差值变化不超过2%,而色度差值的变化只有1%以内,我们认为这样的图可以分到一组。在这样一组帧中,经过编码后,我们只保留第一帖的完整数据,其它帧都通过参考上一帧计算出来。我们称第一帧为IDR/I帧,其它帧我们称为P/B帧,这样编码后的数据帧组我们称为GOP。
- I帧:关键帧,采用帧内压缩技术。
- P帧:向前参考帧,在压缩时,只参考前面已经处理的帧。采用帧音压缩技术。
- B帧:双向参考帧,在压缩时,它即参考前而的帧,又参考它后面的帧。采用帧间压缩技术。
- GOP:两个I帧之间是一个图像序列,在一个图像序列中只有一个I帧。
四丶音视频同步原理,音频和视频能绝对同步吗
面试官😺: 谈下音视频同步原理,音频和视频能绝对同步吗
心理分析😉:音视频同步本身比较难,一般使用
ijkplayer第三方做音视频同步。不排除有视频直播 视频通话需要用音视频同步,可以从三种 音频为准 视频为准 自定义时钟为准三种方式实现音视频同步
求职者😊: 如果被问到 放正心态,能回答多少是多少。如果你看了这篇文章肯定是可以回答上的。
音视频的直播系统是一个复杂的工程系统,要做到非常低延迟的直播,需要复杂的系统工程优化和对各组件非常熟悉的掌握。下面整理几个简单常用的调优技巧:
以fflay来看音视频同步流程
ffplay中将视频同步到音频的主要方案是,如果视频播放过快,则重复播放上一帧,以等待音频;如果视频播放过慢,则丢帧追赶音频。
这一部分的逻辑实现在视频输出函数video_refresh中
在这个流程中,“计算上一帧显示时长”这一步骤至关重要。先来看下代码:
static void video_refresh(void *opaque, double *remaining_time)
//……
//lastvp上一帧,vp当前帧 ,nextvp下一帧
last_duration = vp_duration(is, lastvp, vp);//计算上一帧的持续时长
delay = compute_target_delay(last_duration, is);//参考audio clock计算上一帧真正的持续时长
time= av_gettime_relative()/1000000.0;//取系统时刻
if (time < is->frame_timer + delay) //如果上一帧显示时长未满,重复显示上一帧
*remaining_time = FFMIN(is->frame_timer + delay - time, *remaining_time);
goto display;
is->frame_timer += delay;//frame_timer更新为上一帧结束时刻,也是当前帧开始时刻
if (delay > 0 && time - is->frame_timer > AV_SYNC_THRESHOLD_MAX)
is->frame_timer = time;//如果与系统时间的偏离太大,则修正为系统时间
//更新video clock
//视频同步音频时没作用
SDL_LockMutex(is->pictq.mutex);
if (!isnan(vp->pts))
update_video_pts(is, vp->pts, vp->pos, vp->serial);
SDL_UnlockMutex(is->pictq.mutex);
//……
//丢帧逻辑
if (frame_queue_nb_remaining(&is->pictq) > 1)
Frame *nextvp = frame_queue_peek_next(&is->pictq);
duration = vp_duration(is, vp, nextvp);//当前帧显示时长
if(time > is->frame_timer + duration)//如果系统时间已经大于当前帧,则丢弃当前帧
is->frame_drops_late++;
frame_queue_next(&is->pictq);
goto retry;//回到函数开始位置,继续重试(这里不能直接while丢帧,因为很可能audio clock重新对时了,这样delay值需要重新计算)
代码只保留了同步相关的部分,完整的代码可以参考ffmpeg源码,或阅读这篇分析:https://zhuanlan.zhihu.com/p/44122324
这段代码的逻辑在上述流程图中有包含。主要思路就是一开始提到的如果视频播放过快,则重复播放上一帧,以等待音频;如果视频播放过慢,则丢帧追赶音频。实现的方式是,参考audio clock,计算上一帧(在屏幕上的那个画面)还应显示多久(含帧本身时长),然后与系统时刻对比,是否该显示下一帧了。
这里与系统时刻的对比,引入了另一个概念——frame_timer。可以理解为帧显示时刻,如更新前,是上一帧的显示时刻;对于更新后(is->frame_timer += delay),则为当前帧显示时刻。
上一帧显示时刻加上delay(还应显示多久(含帧本身时长))即为上一帧应结束显示的时刻。具体原理看如下示意图:
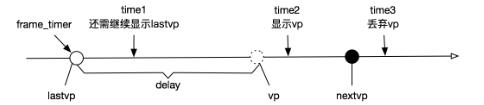
这里给出了3种情况的示意图:
- time1:系统时刻小于
lastvp结束显示的时刻(frame_timer+dealy),即虚线圆圈位置。此时应该继续显示lastvp - time2:系统时刻大于
lastvp的结束显示时刻,但小于vp的结束显示时刻(vp的显示时间开始于虚线圆圈,结束于黑色圆圈)。此时既不重复显示lastvp,也不丢弃vp,即应显示vp - time3:系统时刻大于vp结束显示时刻(黑色圆圈位置,也是
nextvp预计的开始显示时刻)。此时应该丢弃vp。
delay的计算
那么接下来就要看最关键的lastvp的显示时长delay是如何计算的。
这在函数compute_target_delay中实现:
static double compute_target_delay(double delay, VideoState *is)
double sync_threshold, diff = 0;
/* update delay to follow master synchronisation source */
if (get_master_sync_type(is) != AV_SYNC_VIDEO_MASTER)
/* if video is slave, we try to correct big delays by
duplicating or deleting a frame */
diff = get_clock(&is->vidclk) - get_master_clock(is);
/* skip or repeat frame. We take into account the
delay to compute the threshold. I still don't know
if it is the best guess */
sync_threshold = FFMAX(AV_SYNC_THRESHOLD_MIN, FFMIN(AV_SYNC_THRESHOLD_MAX, delay));
if (!isnan(diff) && fabs(diff) < is->max_frame_duration)
if (diff <= -sync_threshold)
delay = FFMAX(0, delay + diff);
else if (diff >= sync_threshold && delay > AV_SYNC_FRAMEDUP_THRESHOLD)
delay = delay + diff;
else if (diff >= sync_threshold)
delay = 2 * delay;
av_log(NULL, AV_LOG_TRACE, "video: delay=%0.3f A-V=%f\\n",
delay, -diff);
return delay;
上面代码中的注释全部是源码的注释,代码不长,注释占了快一半,可见这段代码重要性。
这段代码中最难理解的是sync_threshold,画个图帮助理解:

图中坐标轴是diff值大小,diff为0表示video clock与audio clock完全相同,完美同步。图纸下方色块,表示要返回的值,色块值的delay指传入参数,结合上一节代码,即lastvp的显示时长。
从图上可以看出来sync_threshold是建立一块区域,在这块区域内无需调整lastvp的显示时长,直接返回delay即可。也就是在这块区域内认为是准同步的。
如果小于-sync_threshold,那就是视频播放较慢,需要适当丢帧。具体是返回一个最大为0的值。根据前面frame_timer的图,至少应更新画面为vp。
如果大于sync_threshold,那么视频播放太快,需要适当重复显示lastvp。具体是返回2倍的delay,也就是2倍的lastvp显示时长,也就是让lastvp再显示一帧。
如果不仅大于sync_threshold,而且超过了AV_SYNC_FRAMEDUP_THRESHOLD,那么返回delay+diff,由具体diff决定还要显示多久(这里不是很明白代码意图,按我理解,统一处理为返回2*delay,或者delay+diff即可,没有区分的必要)
至此,基本上分析完了视频同步音频的过程,简单总结下:
- 基本策略是:如果视频播放过快,则重复播放上一帧,以等待音频;
- 如果视频播放过慢,则丢帧追赶音频。
- 这一策略的实现方式是:引入
frame_timer概念,标记帧的显示时刻和应结束显示的时刻,再与系统时刻对比,决定重复还是丢帧。 lastvp的应结束显示的时刻,除了考虑这一帧本身的显示时长,还应考虑了video clock与audio clock的差值。- 并不是每时每刻都在同步,而是有一个“准同步”的差值区域。
五丶直播中 网速比较差的条件下,如何使画面保证流畅的效果
5.1.面试官😺: 直播中 网速比较差的条件下,如何使画面保证流畅的效果
心理分析😉:“ 网速比较差的条件下,如何使画面保证流畅的效果” 该问题可以转换成一个优化问题。直播技术最难的是优化,接下来我们从五个方面来进行直播优化
**求职者😊: ** 遇到优化问题 一定要淡定,一步一步 调理清晰。面试官也不会完全记得有几种优化,他只是试探你 看你了不了解。如果遇到该问题 说话卡顿 结巴,面试官可以下定决定 你没弄过。
音视频的直播系统是一个复杂的工程系统,要做到非常低延迟的直播,需要复杂的系统工程优化和对各组件非常熟悉的掌握。下面整理几个简单常用的调优技巧:
5.2 编码优化
-
确保
Codec开启了最低延迟的设置。Codec一般都会有低延迟优化的开关,对于H264来说其效果尤其明显。很多人可能不知道H264的解码器正常情况下会在显示之前缓存一定的视频帧,对于QCIF分辨率大小的视频(176 × 144)一般会缓存 16 帧,对于 720P 的视频则缓存 5 帧。对于第一帧的读取来说,这是一个很大的延迟。如果你的视频不是使用 H264 来编码压缩的,确保没有使用到 B 帧,它对延迟也会有较大的影响,因为视频中 B 帧的解码依赖于前后的视频帧,会增加延迟。 -
编码器一般都会有码控造成的延迟,一般也叫做初始化延迟或者视频缓存检验器
VBV的缓存大小**,把它当成编码器和解码器比特流之间的缓存,在不影响视频质量的情况下可以将其设置得尽可能小也可以降低延迟。 -
如果是仅仅优化首开延迟,可以在视频帧间插入较多的关键帧,这样客户端收到视频流之后可以尽快解码。但如果需要优化传输过程中的累计延迟,尽可能少使用关键帧也就是 I 帧(
GOP变大),在保证同等视频质量的情况下,I 帧越多,码率越大,传输所需的网络带宽越多,也就意味着累计延迟可能越大。这个优化效果可能在秒级延迟的系统中不是很明显,但是在 100 ms 甚至更低延迟的系统中就会非常明显。同时,尽量使用ACC-LC Codec来编码音频,HE-ACC或者HE-ACC 2虽然编码效率高,但是编码所需时间更长,而产生更大体积的音频造成的传输延迟对于视频流的传输来说影响更小。 -
不要使用视频
MJPEG的视频压缩格式,至少使用不带 B 帧的MPEG4视频压缩格式(Simple profile),甚至最好使用H.264baseline profile(X264 还有一个「-tune zerolatency」的优化开关)。这样一个简单的优化可以降低延迟,因为它能够以更低的码率编码全帧率视频。 -
如果使用了
FFmpeg,降低「-probesize」和「 -analyze duration」参数的值,这两个值用于视频帧信息监测和用于监测的时长,这两个值越大对编码延迟的影响越大,在直播场景下对于视频流来说analyzeduration参数甚至没有必要设定。 -
固定码率编码
CBR可以一定程度上消除网络抖动影响,如果能够使用可变码率编码VBR可以节省一些不必要的网络带宽,降低一定的延迟。因此建议尽量使用VBR进行编码。
5.3.传输协议优化
- **在服务端节点和节点之间尽量使用
RTMP**而非基于HTTP的HLS协议进行传输,这样可以降低整体的传输延迟。这个主要针对终端用户使用HLS进行播放的情况。 - 如果终端用户使用
RTMP来播放,尽量在靠近推流端的收流节点进行转码,这样传输的视频流比原始视频流更小。 - 如果有必要,可以使用定制的
UDP协议来替换TCP协议,省去弱网环节下的丢包重传可以降低延迟。它的主要缺点在于,基于UDP协议进行定制的协议的视频流的传输和分发不够通用,CDN厂商支持的是标准的传输协议。另一个缺点在于可能出现丢包导致的花屏或者模糊(缺少关键帧的解码参考),这就要求协议定制方在UDP基础之上做好丢包控制。
5.4.传输网络优化
-
我们曾经介绍过实时流传输网络,它是一种新型的节点自组织的网状传输网络,既适合国内多运营商网络条件下的传输优化,也适合众多海外直播的需求。
-
在服务端节点中缓存当前
GOP,配合播放器端优化视频首开时间。 -
服务端实时记录每个视频流流向每个环节时的秒级帧率和码率,实时监控码率和帧率的波动。
-
客户端(推流和播放)通过查询服务端准实时获取当前最优节点(5 秒一次),准实时下线当前故障节点和线路。
5.5. 推流、播放优化
-
考察发送端系统自带的网络
buffer大小,系统可能在发送数据之前缓存数据,这个参数的调优也需要找到一个平衡点。 -
播放端缓存控制对于视频的首开延迟也有较大影响,如果仅优化首开延迟,可以在 0 缓存情况下在数据到达的时候立即解码。但如果在弱网环境下为了消除网络抖动造成的影响,设置一定的缓存也有必要,因此需要在直播的稳定性和首开延迟优化上找到平衡,调整优化缓冲区大小这个值。
-
播放端动态
buffer策略,这是上面播放端缓存控制的改进版本。如果只是做 0 缓存和固定大小的缓存之间进行选择找到平衡,最终还是会选择一个固定大小的缓存,这对亿级的移动互联网终端用户来说并不公平,他们不同的网络状况决定了这个固定大小的缓存并不完全合适。因此,我们可以考虑一种「动态 buffer 策略」,在播放器开启的时候采用非常小甚至 0 缓存的策略,通过对下载首片视频的耗时来决定下一个时间片的缓存大小,同时在播放过程中实时监测当前网络,实时调整播放过程中缓存的大小。这样即可做到极低的首开时间,又可能够尽量消除网络抖动造成的影响。 -
动态码率播放策略。除了动态调整
buffer大小的策略之外,也可以利用实时监测的网络信息来动态调整播放过程中的码率,在网络带宽不足的情况下降低码率进行播放,减少延迟。
以上,是低延迟优化方面的部分技巧。实际上我们优化低延迟的时候并不是只关注「低延迟」,而是在保证其它条件不影响用户体验的情况下尽量做到低延迟,因此它的内容涉及到更多广泛的话题。
💡关注公众号 『初一十五a 』,不定期分享知识😺
以上是关于入秋,学习音视频视频和文字结合更配哦的主要内容,如果未能解决你的问题,请参考以下文章