rollup与cube函数
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了rollup与cube函数相关的知识,希望对你有一定的参考价值。
请问:
1、为什么oracle 9i中使用rollup得到的结果中总计那个值在最开始的一条记录,cube得到的结果中总计那个值在最后一条记录?这个有什么规律么?
2、另外,我用group by与grouping sets得到的结果好像一样啊?
谢谢!
ROLLUP和CUBE 用法
Oracle的GROUP BY语句除了最基本的语法外,还支持ROLLUP和CUBE语句。如果是Group by ROLLUP(A, B, C)的话,首先会对(A、B、C)进行GROUP BY,然后对(A、B)进行GROUP BY,然后是(A)进行GROUP BY,最后对全表进行GROUP BY操作。
如果是GROUP BY CUBE(A, B, C),则首先会对(A、B、C)进行GROUP BY,然后依次是(A、B),(A、C),(A),(B、C),(B),(C),最后对全表进行GROUP BY操作。 grouping_id()可以美化效果。除了使用GROUPING函数,还可以使用GROUPING_ID来标识GROUP BY的结果。
也可以 Group by Rollup(A,(B,C)) ,Group by A Rollup(B,C),…… 这样任意按自己想要的形式结合统计数据,非常方便。
Rollup():分组函数可以理解为group by的精简模式,具体分组模式如下:
Rollup(a,b,c): (a,b,c),(a,b),(a),(全表)
Cube():分组函数也是以group by为基础,具体分组模式如下:
cube(a,b,c):(a,b,c),(a,b),(a,c),(b,c),(a),(b),(c),(全表)
下面准备数据比较一下两个函数的不同:
1、准备数据:
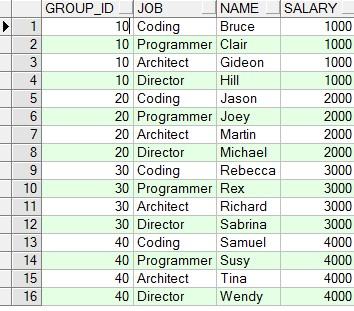
2、使用rollup函数查询
select group_id,job,name,sum(salary) from GROUP_TEST group by rollup(group_id,job,name);
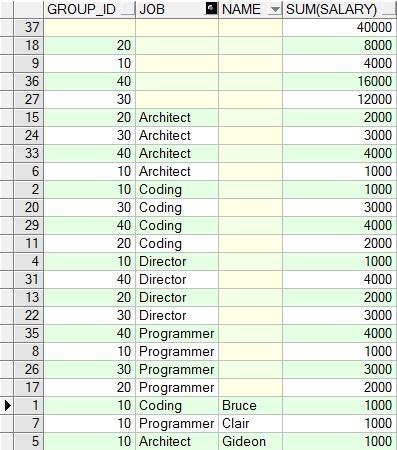

3、使用cube函数:
select group_id,job,name,sum(salary) from GROUP_TEST group by cube(group_id,job,name)




4、对比:从最后查询出来的数据条数就差了好多,下面看一下将两个函数从转化成对应的group函数语句:
rollup函数:
select group_id,job,name,sum(salary) from GROUP_TEST group by rollup(group_id,job,name);
等价于:
select group_id,job,name,sum(salary) from GROUP_TEST group by group_id,job,name
union all
select group_id,job,null,sum(salary) from GROUP_TEST group by group_id,job
union all
select group_id,null,null,sum(salary) from GROUP_TEST group by group_id
union all
select null,null,null,sum(salary) from GROUP_TEST
cube函数:
select group_id,job,name,sum(salary) from GROUP_TEST group by cube(group_id,job,name) ;
等价于:
select group_id,job,name,sum(salary) from GROUP_TEST group by group_id,job,name
union all
select group_id,job,null,sum(salary) from GROUP_TEST group by group_id,job
union all
select group_id,null,name,sum(salary) from GROUP_TEST group by group_id,name
union all
select group_id,null,null,sum(salary) from GROUP_TEST group by group_id
union all
select null,job,name,sum(salary) from GROUP_TEST group by job,name
union all
select null,job,null,sum(salary) from GROUP_TEST group by job
union all
select null,null,name,sum(salary) from GROUP_TEST group by name
union all
select null,null,null,sum(salary) from GROUP_TEST
5、由此可见两个函数对于汇总统计来说要比普通函数好用的多,另外还有一个配套使用的函数
grouping(**):当**字段为null的时候值为1,当字段**非null的时候值为0;
select grouping(group_id),job,name,sum(salary) from GROUP_TEST group by rollup(group_id,job,name);
6、添加一列用来直观的显示所有的汇总字段:
select group_id,job,name,
case when name is null and nvl(group_id,0)=0 and job is null then '全表聚合'
when name is null and nvl(group_id,0)=0 and job is not null then 'JOB聚合'
when name is null and grouping(group_id)=0 and job is null then 'GROUPID聚合'
when name is not null and nvl(group_id,0)=0 and job is null then 'Name聚合'
when name is not null and grouping(group_id)=0 and job is null then 'GROPName聚合'
when name is not null and grouping(group_id)=1 and job is not null then 'JOBName聚合'
when name is null and grouping(group_id)=0 and job is not null then 'GROUPJOB聚合'
else
'三列汇总' end ,
sum(salary) from GROUP_TEST group by cube(group_id,job,name) ;
2 用GROUP BY GROUPING SETS来代替GROUP BY CUBE。你可以应用来指定你感兴趣的总数组合。因为它不必计算它不需要集合(也不会产生太多结果),所以对SQL引擎来说更为高效。
其格式为:
GROUP BY GROUPING SETS ((list), (list) ... )
这里(list)是圆括号中的一个列序列,这个组合生成一个总数。要增加一个总和,必须增加一个(NUlL)分组集。本回答被提问者采纳
SQL Server WITH ROLLUPWITH CUBEGROUPING语句的应用
CUBE:CUBE 生成的结果集显示了所选列中值的所有组合的聚合。
ROLLUP:ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合。
GROUPING:当行由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 1;当行不由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 0。
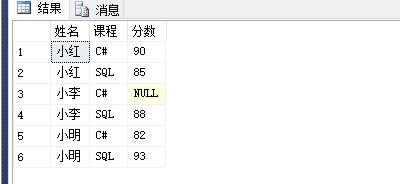
先创建一个临时表:

1 create table #temp 2 ( 3 姓名 varchar(50) not null, 4 课程 varchar(50) null, 5 分数 int null 6 ) 7 8 insert into #temp 9 select \'小红\',\'SQL\',\'85\' union 10 select \'小红\',\'C#\',\'90\' union 11 select \'小明\',\'SQL\',\'93\' union 12 select \'小明\',\'C#\',\'82\' union 13 select \'小李\',\'SQL\',\'88\' union 14 select \'小李\',\'C#\',null 15 16 select * from #temp
WITH CUBE:
1 select 姓名,课程,sum(分数) 2 from #temp 3 group by 姓名,课程 4 with cube
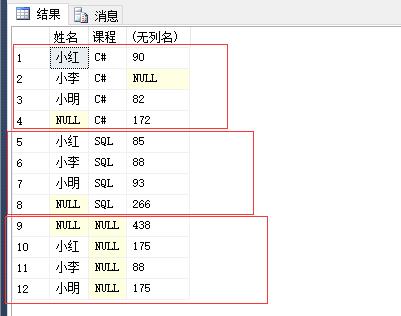
先以姓名分组和课程组合,再以姓名和课程分组进行组合。
PS:分类依据并不是根据select 中的顺序,而是根据group by中的顺序。
下面换个顺序看看结果:
1 select 姓名,课程,sum(分数) 2 from #temp 3 group by 课程,姓名 4 with cube
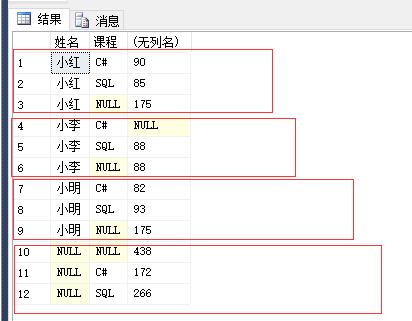
先以课程分组和姓名组合,再以课程和姓名分组进行组合。
CUBE 生成的结果集显示了所选列中值的所有组合的聚合。
WITH ROLLUP:
1 select 姓名,课程,sum(分数) 2 from #temp 3 group by 姓名,课程 4 with rollup

1 select 姓名,课程,sum(分数) 2 from #temp 3 group by 课程,姓名 4 with rollup

ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合。
那么这个某一层次结构是什么呢?看一下上面的数据,当以姓名先分组时,分成了三组(不计最后一行合计),当以课程先分组时,分成了两组(不计最后一行合计)。
这个某一层次结构我猜想应该跟 group by 的分组顺序有关。
GROUPING:
grouping 与 with rollup 的结合(与with cube的结合是一样的)
1 select 姓名,课程,sum(分数),GROUPING(姓名) 2 from #temp 3 group by 姓名,课程 4 with rollup
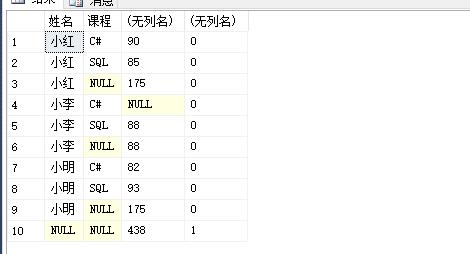
当 grouping 指定列为【姓名】时,只有最后一行是 with rollup 所添加的。
1 select 姓名,课程,sum(分数),GROUPING(课程) 2 from #temp 3 group by 姓名,课程 4 with rollup
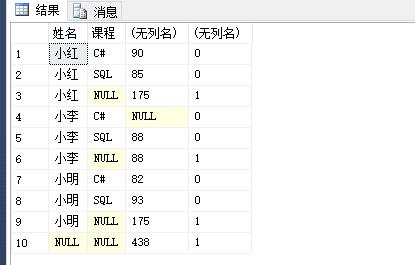
当 grouping 指定列为【课程】时,第三行、第六行、第九行和最后一行是 with rollup 所添加的。
当行由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 1;当行不由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 0。
1 select 姓名, 2 case when GROUPING(姓名)=1 3 then \'总计\' 4 else 5 case when GROUPING(课程)=1 6 then \'小计\' 7 else 课程 end 8 end 课程, 9 sum(分数) 10 from #temp 11 group by 姓名,课程 12 with rollup

以上是关于rollup与cube函数的主要内容,如果未能解决你的问题,请参考以下文章